一、Mysql的存盤原理
索引相關
本質
? 索引是幫助MySQL高效獲取資料的排好序的資料結構
? 建索引,提高資料檢索的效率,降低資料庫的IO成本; 通過索引列對資料進行排序,降低資料排序的成本,降低了 CPU的消耗,
索引分類
- 主鍵索引:主鍵自帶索引效果,性能很好
- 普通索引:為普通列創建的索引
-- 格式
create index 索引名稱 on 表名(列名);
-- 示例
create index idx_name on user(name);
- 唯一索引 : 索引列的值必須唯一,但允許有空值,比普通索引的性能要好
-- 格式
create unique index 索引名稱 on 表名(列名);
-- 示例
create unique index uniq_name on user(name);
-
聯合索引 ( 開發常用 ) :一次性的為表中的多個列創建索引 (建議一個聯合索引不超過5個欄位)
? (最左前綴法則:如何命中聯合索引中的索引列)
-- 格式
create index 索引名稱 on 表名(列名1,列名2);
-- 示例
create index idx_name_age_password on user(name,age,password);
-
全文索引:進行查詢時,資料源可能來自不同的欄位或者表
? MyISAM存盤引擎支持全文索引,在實際開發中并不會去使用而是使用搜索引擎中間件
總結
-- 創建索引
create [unique] index 索引名稱 on 表名(列名)
-- 洗掉索引
drop index [索引名稱] on 表名
-- 查看索引
show index from 表名\G
為資料表添加索引

索引的資料結構
- 二叉樹 (鏈表情況)
- 紅黑樹 (層次太多)
- Hash表
- 對索引的key進行一次hash計算就可以定位出資料存盤的位置
- 很多時候Hash索引要比B+樹索引更高效
- 僅能滿足“=”,“IN”,不支持范圍查詢
- hash沖突問題
- B Tree
- 葉節點具有相同的深度,葉節點的指標為空
- 所有索引元素不重復
- 節點中的資料索引從左到右遞增排列
- B+Tree (底層)
- 非葉子節點不存盤data,只存盤索引(冗余),可以放更多的索引
- 葉子節點包含所有索引欄位
- 葉子節點用指標連接,提高區間訪問的性能
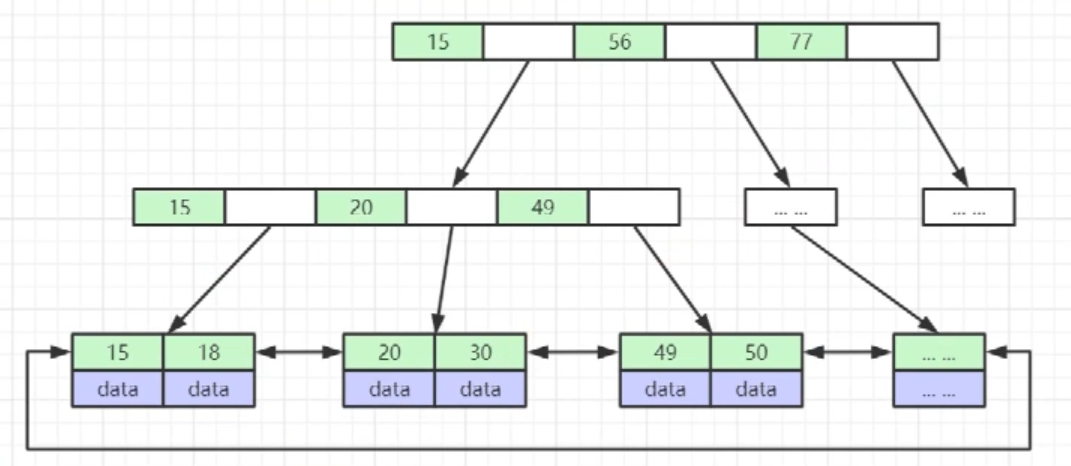
? 推薦一個外國的資料結構在線演示網站: Data Structure Visualization
INNODB與 MYISAM型別的區別
1、INNODB引擎----聚集索引
把索引和資料存放在一個檔案中,通過找到索引后就能直接在索引樹上的葉子結點中獲得完整的資料,可以實作行鎖/表鎖
2、MYISAM----非聚集索引
把索引和資料存放在兩個檔案中,查找到索引后還要去另一個檔案中找資料,性能會慢一些,除此之外,MylSAM天然支持表鎖,而且支持全文索引,
創建索引的情況
- 需要創建索引的情況:
1、主鍵自動建立唯一索引
2、頻繁作為查詢條件的欄位應該創建索引
3、查詢中與其他表關聯的欄位,外鍵關系建立索引
4、單鍵/組合索引的選擇問題 ?( 在高并發下傾向創建組合索引 )
5、查詢中排序的欄位,排序欄位通過索引去訪問將大大提高排序速度
6、查詢中統計或分組欄位
- 不需要創建索引的情況:
1、頻繁更新的欄位不適合創建索引
2、經常增刪改的表
3、where條件里用不到的欄位不創建索引
4、表記錄太少
5、如果某個資料列包含許多重復的內容,為他建立索引沒有太大的效果
? Tip: 一個索引的選擇性越接近1,這個索引的效率就越高!
聯合索引
使用一個索引來實作多個表中欄位的索引效果,
存盤方式:
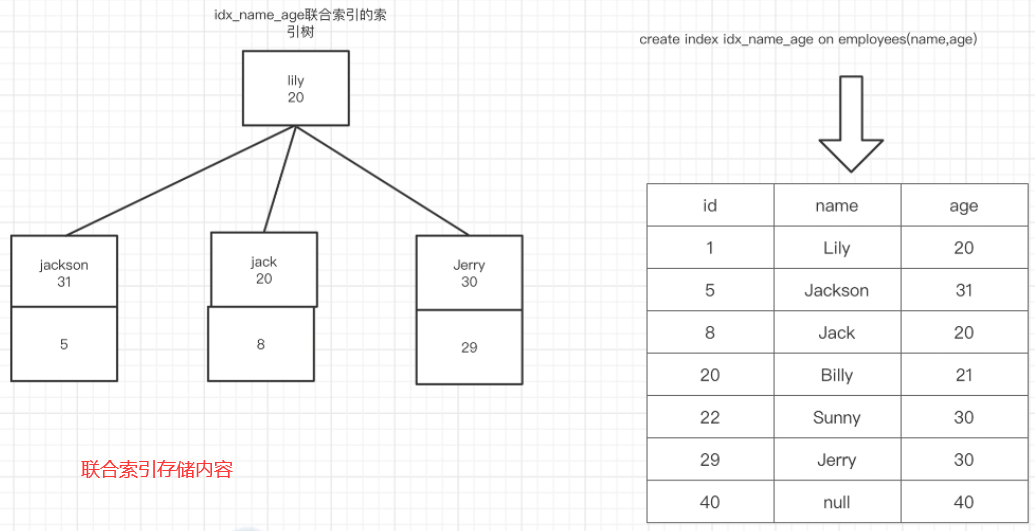
索引最左前綴原理
最左前綴法則是表示一條sql陳述句在聯合索引中有沒有走索引(命中索引/不會全表掃描)
聯合索引的底層存盤結構長什么樣?
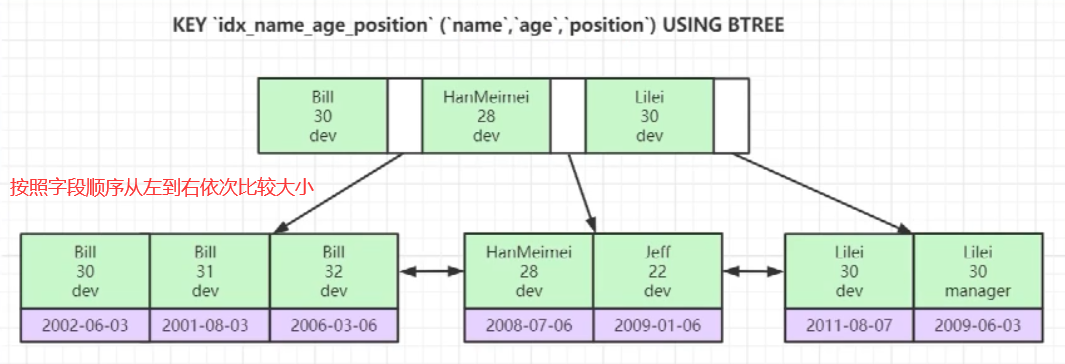
慢sql原因
- 查詢陳述句寫的不好
- 索引失效
- 關聯過多的 join (設計缺陷或不得已的需求)
- 服務器調優以及引數設定
二、Mysql性能查詢

SQL優化的目的是為了SQL陳述句能夠具備優秀的查詢性能,實作這樣的目的有很多的途徑:
- 工程優化如何實作︰資料庫標準、表的結構標準、欄位的標準、創建索引 阿里:MySQL資料庫規范
- SQL陳述句的優化:當前SQL陳述句有沒有命中索引,
explain
簡介
? 使用EXPLAIN關鍵字可以模擬優化器執行sQL查詢陳述句,從而知道MySQL是如何處理你的SQL陳述句的,分析你的查詢陳述句或是表結構的性能瓶頸
詳解
MySQL Explain詳解 explain
作用
表的讀取順序
資料讀取操作的操作型別
哪些索引可以使用
哪些索引被實際使用
表之間的參考
每張表有多少行被優化器查詢
使用格式:explain + sql陳述句
資訊
詳解
-
id列 :id越大越先被執行,如果id相同,上面的先執行
-
select_type列
| 型別 | 描述 |
|---|---|
| simple | 簡單查詢 |
| primary | 外部的主查詢 |
| devived | 在from后面的子查詢, 產生衍生表 |
| subquery | 在from的前面的子查詢 |
| union | 進行的聯合查詢 |
? 關閉對mysql對衍生表的合并優化(演示)
set session optimizer_switch = 'derived_merge=off';
-
table列 :表示這一串列示該sql正在訪問哪一張表,也可以看出正在訪問的衍生表
-
type列
type列可以直觀的判斷出當前的sql陳述句的性能,type里的取值和性能的優劣順序如下:
null > system > const > eq_ref > range > index > all
-- null
性能最好的,一般在使用了聚合函式操作索引列,結果直接從索引樹獲取即可
-- system
很少見 直接和一條記錄進行匹配
-- const
使用主鍵索引或者唯一索引和常量進行比較,性能也很好
-- eq_ref
在進行連接查詢時,連接查詢的條件中使用了本表的主鍵進行關聯
-- ref
-- 簡單查詢
使用普通列作為查詢條件
-- 復雜查詢
在進行連接查詢時,連接查詢的條件中使用了本表的普通索引列
-- range
在索引列上使用了范圍查找,性能是ok的
-- index
在查詢表中的所有的記錄,但是所有的記錄可以直接從索引樹上獲取,(表中欄位均加索引)
-- ALL
全表掃描,就是要從頭到尾對表中的資料掃描一遍,這種查詢性能是一定要做優化的,
-
possible_keys列
顯示這一次查詢可能會用到的索引,mysql優化器查詢時會進行判斷,那么內部優化器就會讓此次查詢進行全表掃描————我們可以通過trace工具進行查看
-
key列 :實際該sql陳述句使用的索引
-
rows列 : 該sql陳述句可能要查詢的資料條數
-
key_len列
通過查看這一列的數值,推斷出本sql命中了聯合索引中的哪幾列, key_len的計算規則

-
extra列
extra列提供了額外的資訊,是能夠幫助我們判斷當前sql的是否使用了覆寫索引、檔案排序、使用了索引進行查詢條件等等的資訊,
-- unsing index
使用了覆寫索引 (指的是當前查詢的所有資料欄位都是索引列,這就意味著可以直接從索引列中獲取資料,而不需要進行查表,使用覆寫索引進行性能優化這種手段是之后sql優化經常要用到的,)
-- using where
where的條件沒有使用索引列,這種性能是不ok的,我們如果條件允許可以給列設定索引,也同樣盡可能的使用覆寫索引,
-- using index condition
查詢的列沒有完全被索引覆寫,并且where條件中使用普通索引
-- using temporary
會創建臨時表來執行,比如在沒有索引的列上執行去重操作,就需要臨時表來實作,(這種情況可以通過給列加索引進行優化,)
-- using filesort
MySQL對資料進行排序,都會使用磁盤驤完成,可能會借助記憶體,涉及到兩個概念︰單路排序、雙路排序
-- Select tables optimized away
當直接在索引列上使用聚合函式,意味著不需要操作表
三、mysql優化細節
索引優化建議
命中索引建議:
-
對于SQL優化來說,要盡量保證type列的值是屬于range及以上級別,
-
不能在索引列上做計算、函式、型別轉換,會導致索引失效
-
對于日期時間的處理 轉換成范圍查找
-
盡量使用覆寫索引
-
使用不等于(!=或者<>)會導致全表掃描
-
使用is null、 is not null會導致全表掃描
-
使用like以通配符開頭('%xxx...")會導致全表掃描 (使用覆寫索引或者搜索引擎中間件)
-
字串不加單引號會導致全表掃描
-
少用or或in,MySQL內部優化器可能不使用索引 (使用多執行緒或者搜索引擎中間件)
-
范圍查詢優化 (范圍大的拆分查找)
Trace工具
在執行計劃中我們發現有的sql會走索引,有的sql即使明確使用了索引也不會走索引,mysql依據Trace工具的結論
-- 開啟trace 設定格式為JSON,設定trace的快取大小,避免因為容量大小而不能顯示完整的跟蹤程序,
set optimier_trace="enabled=on",end_markers_in_JSON=on;
-- 執行sql陳述句
-- 獲得trace分析結果
select *from information_schema.optimizer_trace \G
Order by優化
在Order by中,如果排序會造成檔案排序(在磁盤中完成排序,這樣的性能會比較差),那么就說明sql沒有命中索引,怎么解決? 可以使用最左前綴法則,讓排序遵循最左前綴法則,避免檔案排序,
優化手段:
- 如果排序的欄位創建了聯合索引,那么盡量在業務不沖突的情況下,遵循最左前綴法則來寫排序陳述句,
- 如果檔案排序沒辦法避免,那么盡量想辦法使用覆寫索引,all->index
對于Group by而言 :本質上是先排序后分組,所以排序優化參考order by優化,
分頁查詢優化
-- 原始
Explain select * from employees limit 10000,10
-- 對于主鍵連續的情況下進行優化:(少見)
Explain select * from employees where id>10000 limit 10
-- 通過先進行覆寫索引的查找,然后在使用join做連接查詢獲取所有資料,這樣比全表掃描要快
EXPLAIN select * from employees a inner join (select id from employees order by name limit 1000000,10) b on a.id = b.id;
join查詢優化

in、exstis優化
在sql中如果A表是大表,B表是小表,那么使用in會更加合適,反之應該使用exists,
count優化
對于count的優化應該是架構層面的優化,因為count的統計是在一個產品會經常出現,而且每個用戶訪問,所以對于訪問頻率過高的資料建議維護在快取中,
四、mysql的鎖機制
鎖的定義與分類
定義
鎖是用來解決多個任務(執行緒、行程)在并發訪問同一共享資源時帶來的資料安全問題,雖然使用鎖解決了資料安全問題,但是會帶來性能的影響,頻繁使用鎖的程式的性能是必然很差的,
對于資料管理軟體MySQL來說,必然會到任務的并發訪問,那么MySQL是怎么樣在資料安全和性能上做權衡的呢?——MVCC設計思想,
分類
-
從性能上劃分:
- 悲觀鎖:悲觀的認為當前并發非常嚴重,任何操作都是互斥,保證了執行緒的安全性,但降低了性能
- 樂觀鎖:樂觀的認為當前并發并不嚴重,讀的時候可以,對于寫的情況,在進行上鎖;以CAS自旋鎖為例,性能高,但頻繁自旋會消耗很大的資源
-
從資料的操作細粒度劃分:
- 行鎖:對表中的某一行上鎖
- 表鎖:對整張表上鎖(基本不用)
-
從資料庫的操作型別劃分 (悲觀鎖):
- 讀鎖:稱為共享鎖,對同樣資料進行讀來說 可以同時進行 但是不能執行寫操作
- 寫鎖:稱為排他鎖,上鎖之后與釋放鎖之前,在整個程序之中不能進行任何的并發操作(其他的任務讀與寫都無法進行)
MylSAM只支持表鎖,但不支持行鎖, InnoDB可以支持行鎖 在并發事務里,每個事務的增刪改的操作相當于是上了行鎖,
# 表鎖
-- 對表上讀鎖或者寫鎖格式
lock table 表名 read/write;
-- 釋放當前鎖
unlock tables
-- 查看表的上鎖情況
show open tables
# 行鎖
# MySQL 是默認開啟事務自動提交的
SET autocommit = 0; # 關閉
SET autocommit = 1; # 開啟 默認的
-- 開啟事務
begin;
-- 上行鎖 對id = 8 的這行資料上鎖
update `user` set name='前度' where id = 8;
-- 方式2
select * from `user` where id = 8 for update;
-- 釋放鎖
commint;
MVCC設計思想
? MVCC,即多版本并發控制,MVCC是一種并發控制的方法,一般在資料庫管理系統中,實作對資料庫的并發訪問,在編程語言中實作事務記憶體,
事務的特性
- 原子性:一個事務是一個最小的操作單位,要么都成功,要么都失敗
- 隔離性:資料庫為每個用戶開啟的事務,不能被其他事務影響
- 一致性:事務提交之前與回滾之后的資料一致
- 持久性:事務一旦提交不可逆 被持久化到資料庫中
事務的隔離級別
read uncommitted(讀未提交) : 一個事務讀取了另一個事務還沒有提交的資料 會出現臟讀的情況read committed(讀已提交) : 已經解決了臟讀問題,在一個事務中只會讀取另一個事務已提交的資料,出現不可重復讀情況repeatable read(可重復讀): 默認級別 在一個事務中每次讀取的資料都是一致的.不會出現臟讀和不可重復讀的問題,但會與幻讀情況Serializable: 串行化的隔離界別直接不允許事務的并發發生,不存在任何的并發性,相當于鎖表,性能非常差,一般都不考慮 通過上行鎖來解決幻讀問題
-- 設定隔離級別
set session transaction isolation level 隔離級別;
隔離導致的一些問題
臟讀: 一個事務讀取了另外一個事務未提交的資料
不可重復讀:在一個事務內讀取表中的某一行資料,多次讀取結果不同
虛讀,幻讀:是指在一個事務內讀取了別的事務插入的資料,導致前后讀取不一致(一般是行影響,多了一行)
MySQL在讀和寫的操作中,對讀的性能做了并發性的保障,讓所有的讀都是快照讀,對于寫的時候,進行版本控制,如果真實資料的版本比快照版本要新,那么寫之前就要進行版本(快照〉更新,這樣就可以既能夠提高讀的并發性,又能夠保證寫的資料安全,
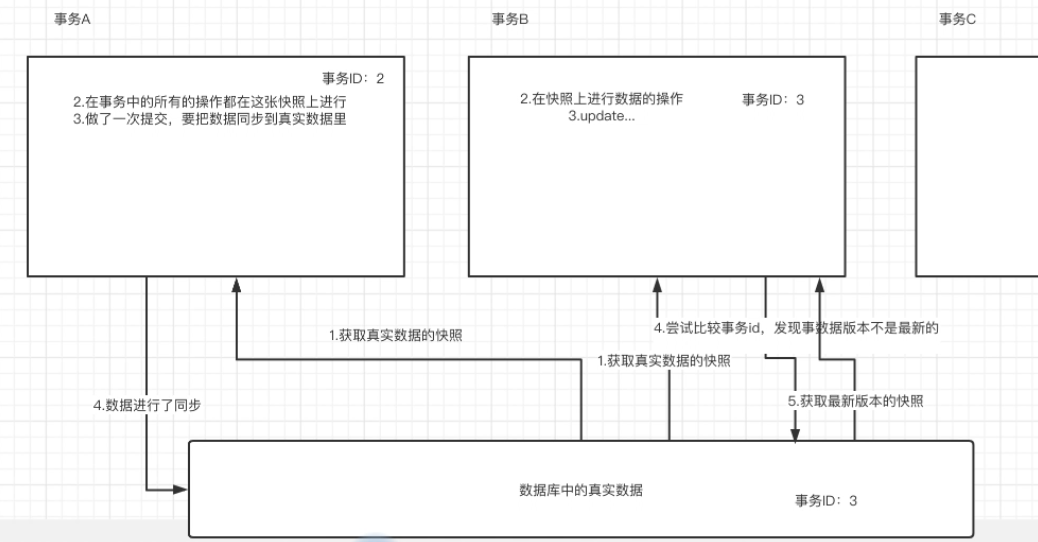
死鎖與間隙鎖
死鎖
? 所謂的死鎖,就是開啟的鎖沒有辦法關閉,導致資源的訪問因為無法獲得鎖而處于阻塞狀態
間隙鎖
? 行鎖只能對某一行上鎖,如果相對某一個范圍上鎖,就可以使用間隙鎖,間隙鎖給的條件where id>13 and id<19,會 對13和19所處的間隙進行上鎖,
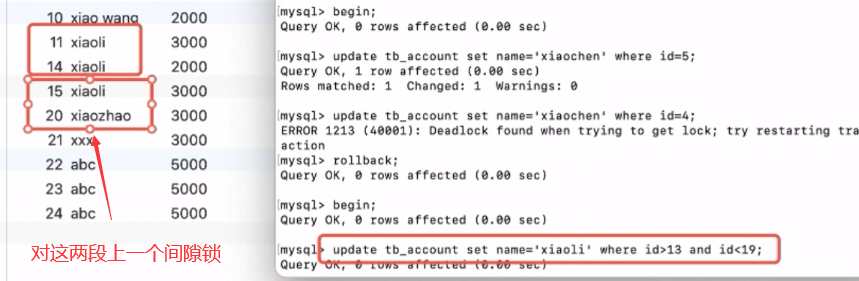
五、部分面試題
為什么非主鍵索引的葉子節點存放的資料是主鍵值?
? 如果普通索引中不存放主鍵,而存放完整資料,那么就會造成:
-
資料冗余,雖然提升了查詢性能,但是需要更多的空間來存放冗余的資料
-
維護麻煩:一個地方修改資料,需要在多棵索引樹上修改,
為什么建議InnoDB表必須建主鍵,并且推薦使用整型的自增主鍵?
? mysql 為什么建議 innodb 表要建一個主鍵?
-
如果有一個主鍵,可以直接使用主鍵建索引
-
如果沒有主鍵,會從第一列開始選擇一列所有值都不相同的,作為索引列
-
如果沒有選到唯一值的索引列,mysql 會建立一個隱藏列,維護一個唯一id,以此來組織索引
為什么推薦使用整形作為主鍵?
-
在索引中查找資料時,減少比較的性能,
-
使用整形作為主鍵相比字符型可以節省資料頁的空間,
-
構建索引 b+ 樹時,為了保證索引的有序性,使用整形可以避免頁分裂,
主鍵為什么要自增?
-
索引結構 b+ 樹,具有有序的特性,
-如果主鍵不是自增的,在進行增刪資料的時候,會判斷資料應該存放的位置,進行插入和洗掉,為了保持平衡,會對資料頁進行分裂等操作移動資料,嚴重影響性能,所以主鍵需要是自增的,插入時,插入在索引資料頁最后,
The End~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/304223.html
標籤:MySQL
上一篇:Hive語法及其進階(二)