所以我的問題類似于這樣 
期望的輸出示例
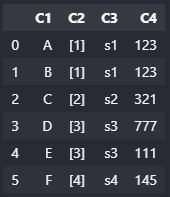
我一直在玩explode()、reset_index()、drop()等,但還不能得到任何正確的輸出。
我嘗試的一件事是這樣的
df = df.explode("C1").reset_index() .drop("index",1) 。 explode("C4").reset_index().drop("index",1)
但輸出是錯誤的
uj5u.com熱心網友回復:
看來,爆炸的列和非爆炸的列需要分開。由于我們不能像通常那樣將它們隱藏在索引中(鑒于C2),包含串列(不可哈希),我們必須分離DataFrame然后重新連接。
# Convert to single series to explode.
cols = ['C1'/span>, 'C4'/span>]
new_df = df[cols].stack().explode().to_frame()。
# Enumerate groups then unstack[/span].
new_df = new_df.set_index(
new_df.groupby(level=[0, 1] ).cumcount()。
append=True
).unstack(1).groupby(level=0).ffill()
# Join Back Unaffected columns
new_df = new_df.droplevel(0, axis=1).droplevel(1, axis=0).join(
df[df.columns.symmetric_difference(cols)] 。
)
# 重新排序列和重置索引。
new_df = new_df.reindex(df.columns, axis=1).reset_index(drop=True)
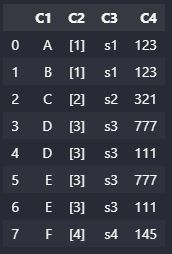
new_df:
C1 C2 C3 C4
0 A [1] s1 123
1 B [1] s1 123
2 C [2] S2 321
3 D [3] S3 777
4 E [3] S3 111
5 F [4] s4 145
我們stack將所有的值變成一個系列,然后explode一起轉換回to_frame
cols = ['C1'/span>, 'C4']
new_df = df[cols].stack().explode().to_frame()
new_df
0
0 C1 A
C1 B
C4 123
1 C1 C
C4 321
2 C1 D
C1 E
C4 777
C4111
3 C1 F
C4 145
我們可以通過groupby cumcount set_index和unstacking列舉組來創建一個新索引:
new_df = new_df.set_index(
new_df.groupby(level=[0, 1]).comcount()。
append=True
).unstack(1)
0
C1 C4
0 0 A 123
1 B NaN
1 0 C321
2 0 D 777
1 E111
3 0 F 145
然后我們可以在索引組內groupby ffill:
new_df = new_df.groupby(level=0).fill()
new_df:
0
C1 C4
0 0 A 123
1 B 123
1 0 C321
2 0 D 777
1 E111
3 0 F 145
然后我們可以join將未受影響的列回傳到DataFrame和reindex以重新排列它們最初出現的方式也droplevel來洗掉不需要的索引層,最后reset_index:
# Join Back Unaffected columns
new_df = new_df.droplevel(0, axis=1).droplevel(1, axis=0).join(
df[df.columns.symmetric_difference(cols)] 。
)
# 重新排序列和重置索引。
new_df = new_df.reindex(df.columns, axis=1).reset_index(drop=True)
new_df:
C1 C2 C3 C4
0 A [1] s1 123
1 B [1] s1 123
2 C [2] S2 321
3 D [3] S3 777
4 E [3] S3 111
5 F [4] s4 145
uj5u.com熱心網友回復:
df=df.explode('C4').assign(C1=df['C1'].str. join(',').str.split(',')).explode('C1')#explode來擴展資料框架。
m=df.diplicated(subset='C1', keep=False)#loc選擇重復的。
df.loc[m,'C4']=df.loc[m,'C4'].shift(1)#introduce nan
df.dropna().drop_duplicates(subset='C1', keep='last')#清理資料幀。
輸出
C1 C2 C3 C4
0 A [1] s1 123
0 B [1] s1 123
1 C [2] s2 321
2 D [3] S3 777
2 E [3] s3 111
3 F [4] S4 145
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/323854.html
標籤: