我使用以下代碼計算了資料框中的缺失值:
per_B = df.isna().mean().round(4) * 100
并使用以下代碼繪制,頂部為 NaN 值計數,但最后兩個值計數位置錯位。
f, ax = plt.subplots(figsize=(20, 15))
for i,item in enumerate(zip(per_B.keys(), per_B.values)):
if (item[1] > 0):
ax.bar(item[0], item[1], label = item[0])
ax.text(i - 0.40, item[1] 0.5 , str(np.round(item[1],2)))
ax.set_xticklabels([])
ax.set_xticks([])
plt.title('NaN Value percentage in Training Set B')
plt.ylim(0,115)
plt.ylabel('Percentage')
plt.xlabel('Columns')
plt.legend(loc='upper left')
plt.show()
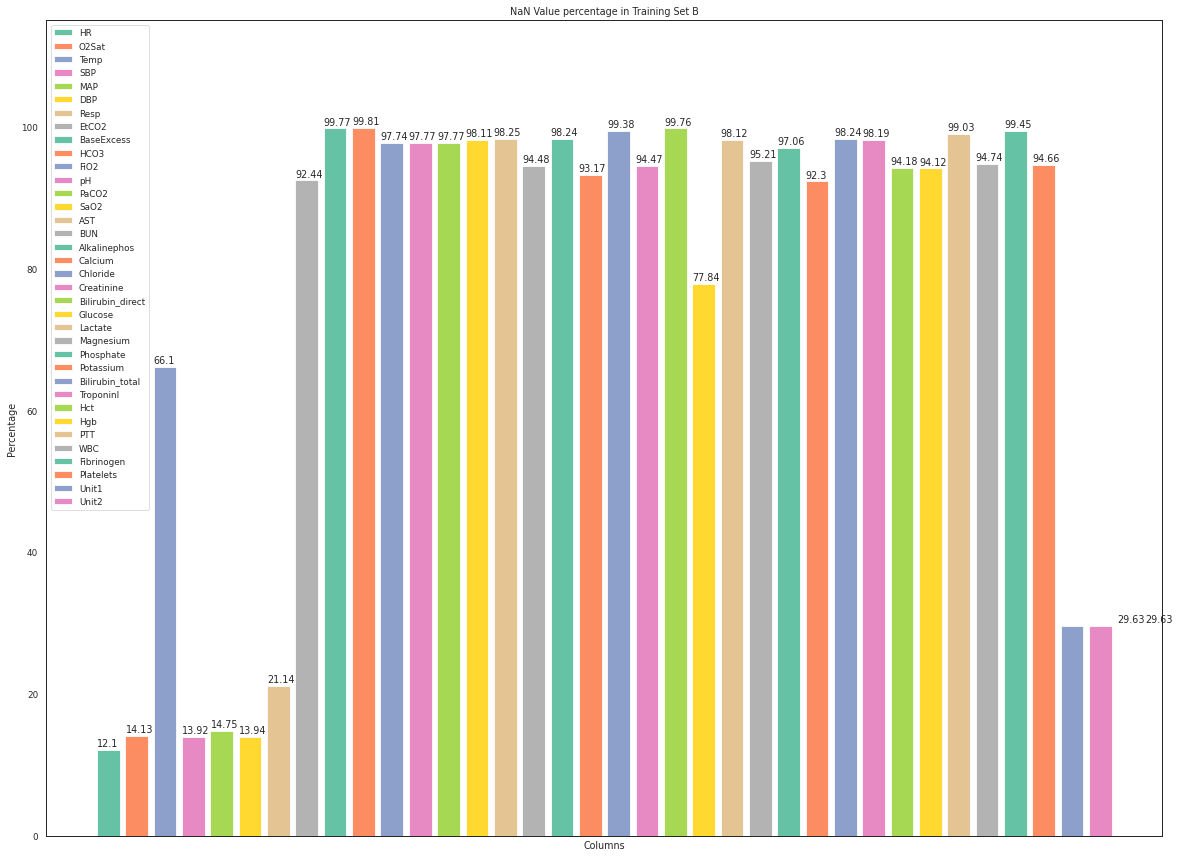
有人可以幫助我解決代碼中出現的問題,因為最后兩列值計數放錯了位置嗎?
uj5u.com熱心網友回復:
文本放錯位置的原因是,i即使您不繪制條形圖,也可以讓增量增加(似乎item[1] <= 0在結尾之前有兩個“專案” )。您可以通過將其放置i在外面for并僅在繪制條形圖時增加它來解決此問題。
所以,像這樣:
i = 0
for key, value in zip(per_B.keys(), per_B.values)):
if (value > 0):
ax.bar(key, value, label=key)
ax.text(i, value 0.5, str(np.round(value, 2)), ha='center')
i = i 1 # increment the counter
可以使用
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/324252.html
標籤:Python matplotlib 海生 南