Kettle的安裝及簡單使用
目錄- Kettle的安裝及簡單使用
- 一、kettle概述
- 二、kettle安裝部署和使用
- Windows下安裝
- 案例1:MySQL to MySQL
- 案例2:使用作業執行上述轉換,并且額外在表stu2中添加一條資料
- 案例3:將hive表的資料輸出到hdfs
- 案例4:讀取hdfs檔案并將sal大于1000的資料保存到hbase中
- 三、創建資源庫
- 1、資料庫資源庫
- 2、檔案資源庫
- 四、 Linux下安裝使用
- 1、單機
- 2、 集群模式
- 案例:讀取hive中的emp表,根據id進行排序,并將結果輸出到hdfs上
- 五、調優
一、kettle概述
1、什么是kettle
Kettle是一款開源的ETL工具,純java撰寫,可以在Window、Linux、Unix上運行,綠色無需安裝,資料抽取高效穩定,
2、Kettle工程存盤方式
(1)以XML形式存盤
(2)以資源庫方式存盤(資料庫資源庫和檔案資源庫)
3、Kettle的兩種設計
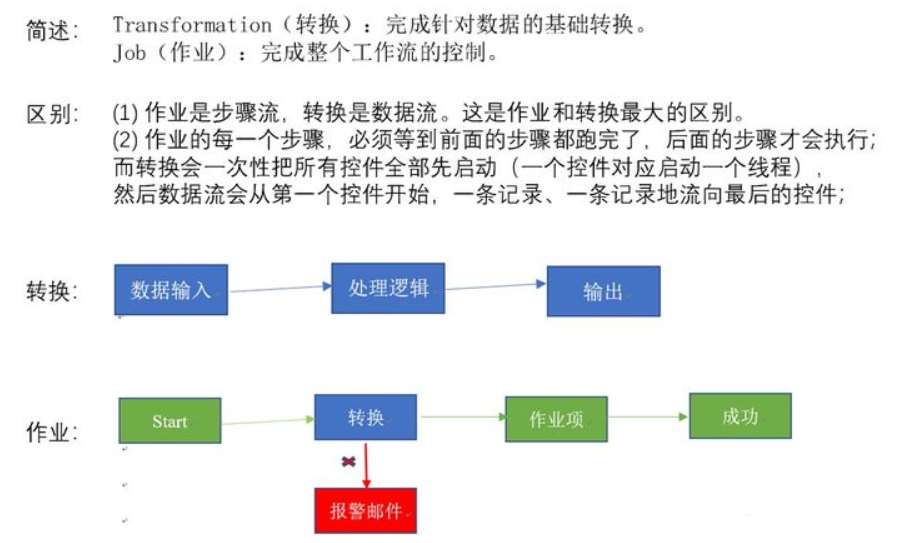
4、Kettle的組成

5、kettle特點

二、kettle安裝部署和使用
Windows下安裝
(1)概述
在實際企業開發中,都是在本地環境下進行kettle的job和Transformation開發的,可以在本地運行,也可以連接遠程機器運行
(2)安裝步驟
1、安裝jdk
2、下載kettle壓縮包,因kettle為綠色軟體,解壓縮到任意本地路徑即可
3、雙擊Spoon.bat,啟動圖形化界面工具,就可以直接使用了
案例1:MySQL to MySQL
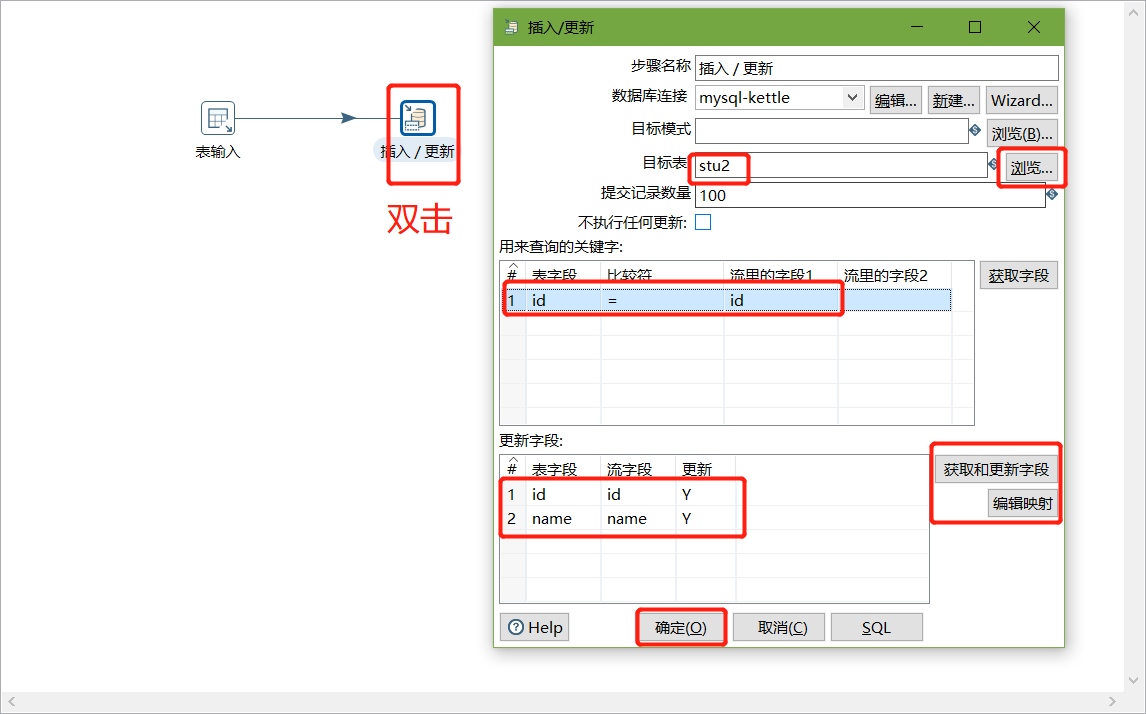
把stu1的資料按id同步到stu2,stu2有相同id則更新資料
1、在mysql中創建testkettle資料庫,并創建兩張表
create database testkettle;
use testkettle;
create table stu1(id int,name varchar(20),age int);
create table stu2(id int,name varchar(20));
2、往兩張表中插入一些資料
insert into stu1 values(1001,'zhangsan',20),(1002,'lisi',18), (1003,'wangwu',23);
insert into stu2 values(1001,'wukong');
3、把pdi-ce-8.2.0.0-342.zip檔案拷貝到win環境中指定檔案目錄,解壓后雙擊Spoon.bat,啟動圖形化界面工具,就可以使用了
主界面:
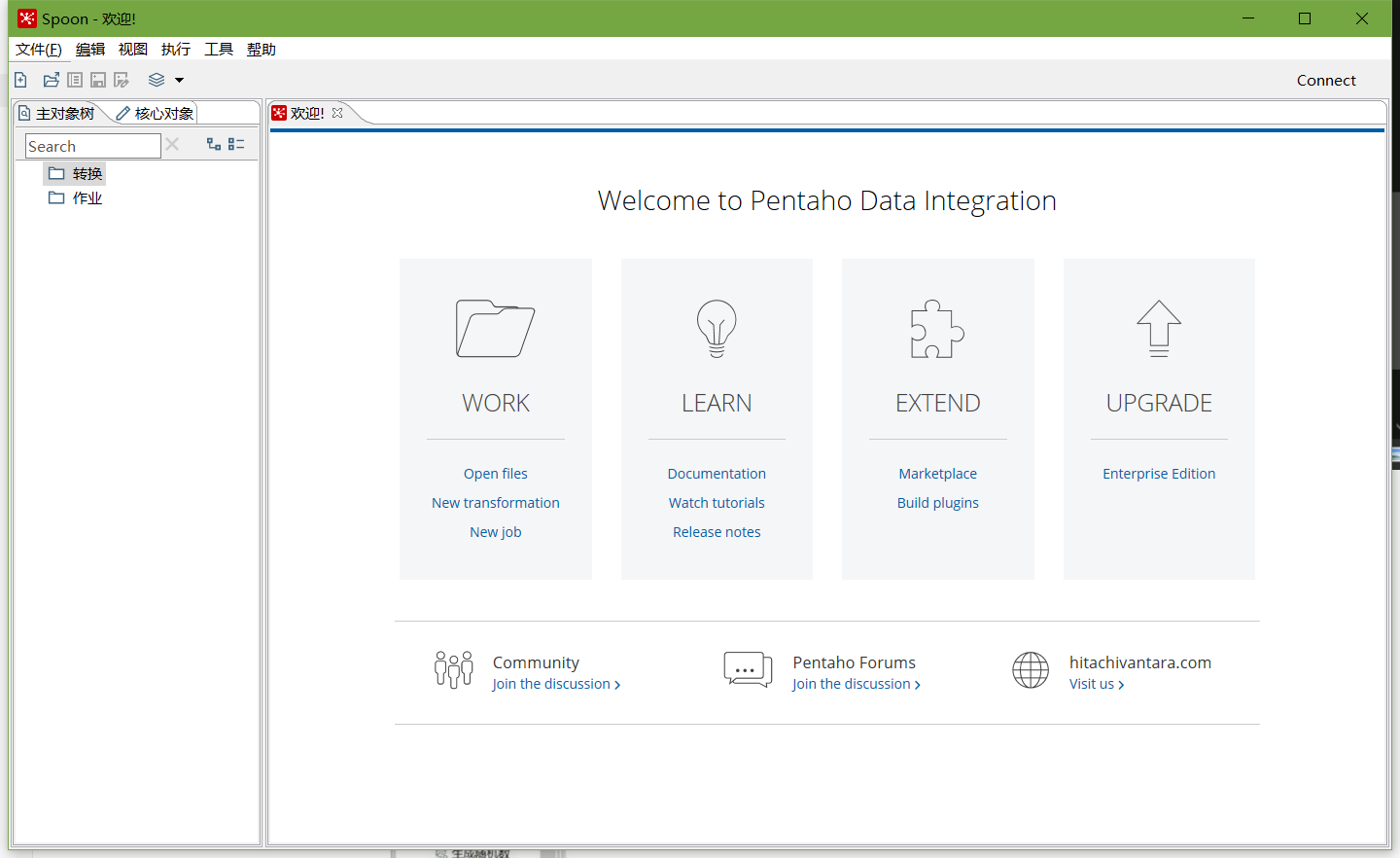
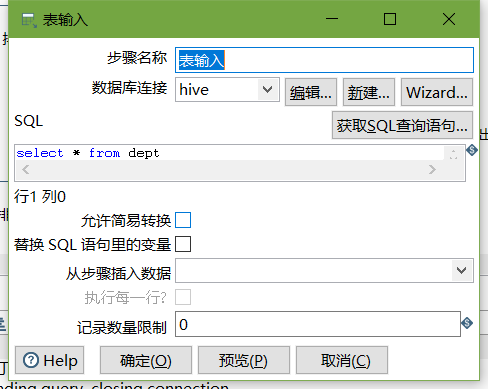
在kettle中新建轉換--->輸入--->表輸入-->表輸入雙擊
在data-integration\lib檔案下添加mysql驅動
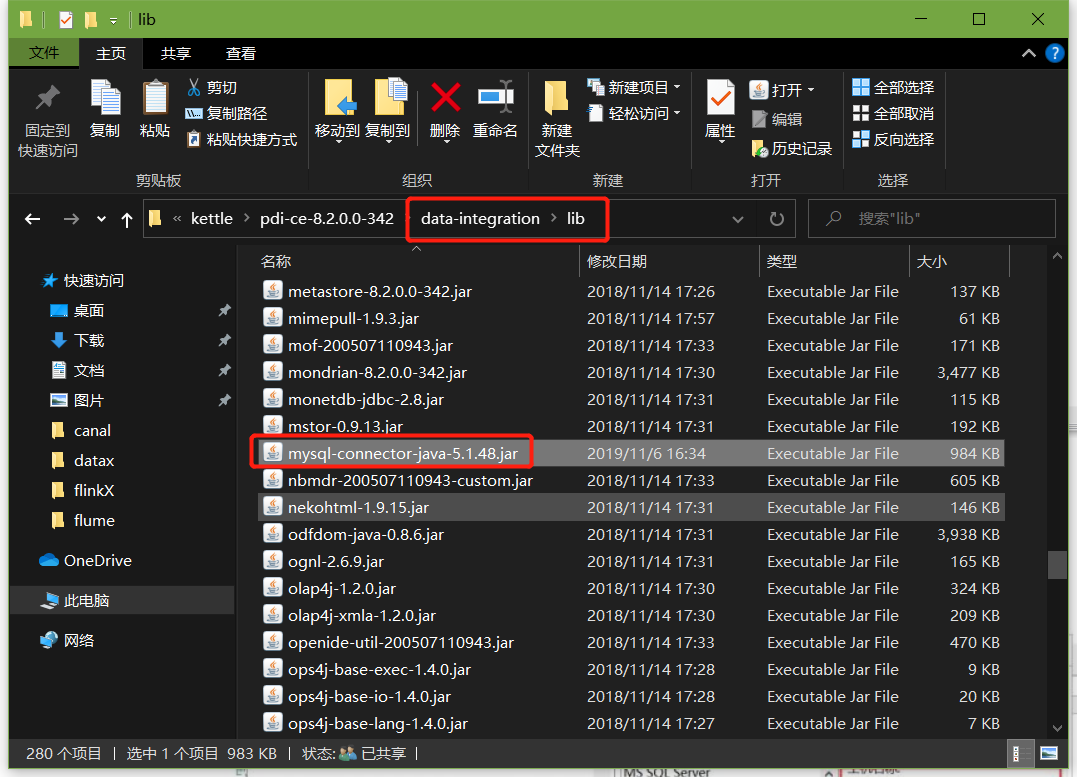
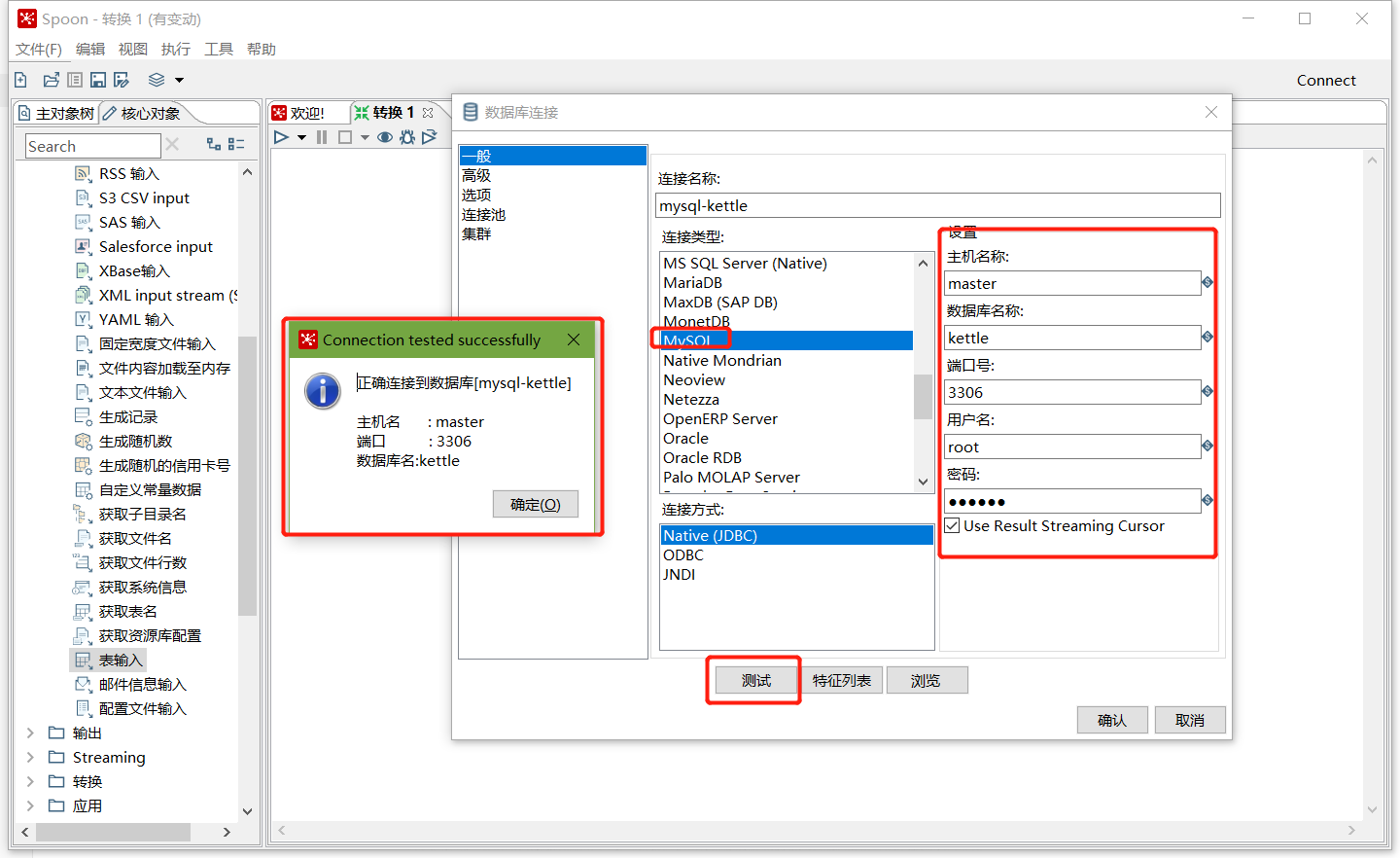
在資料庫連接欄目點擊新建,填入mysql相關配置,并測驗連接
建立連接后,選擇剛剛建好的連接,填入SQL,并預覽資料:
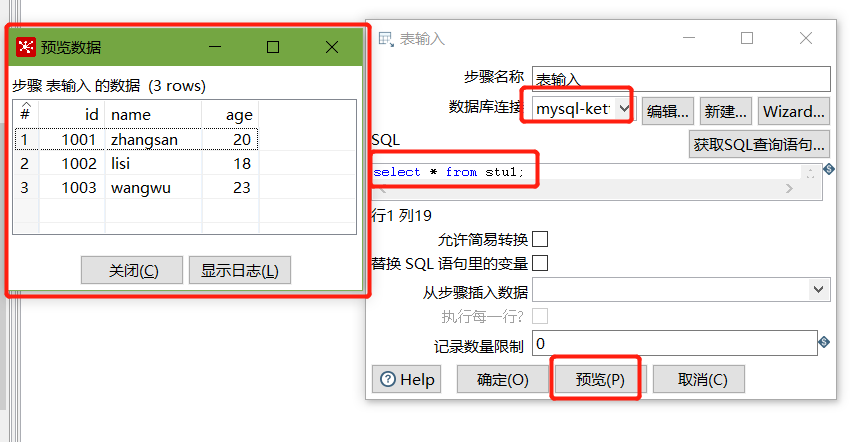
以上說明stu1的資料輸入ok的,現在我們需要把輸入stu1的資料同步到stu2輸出的資料
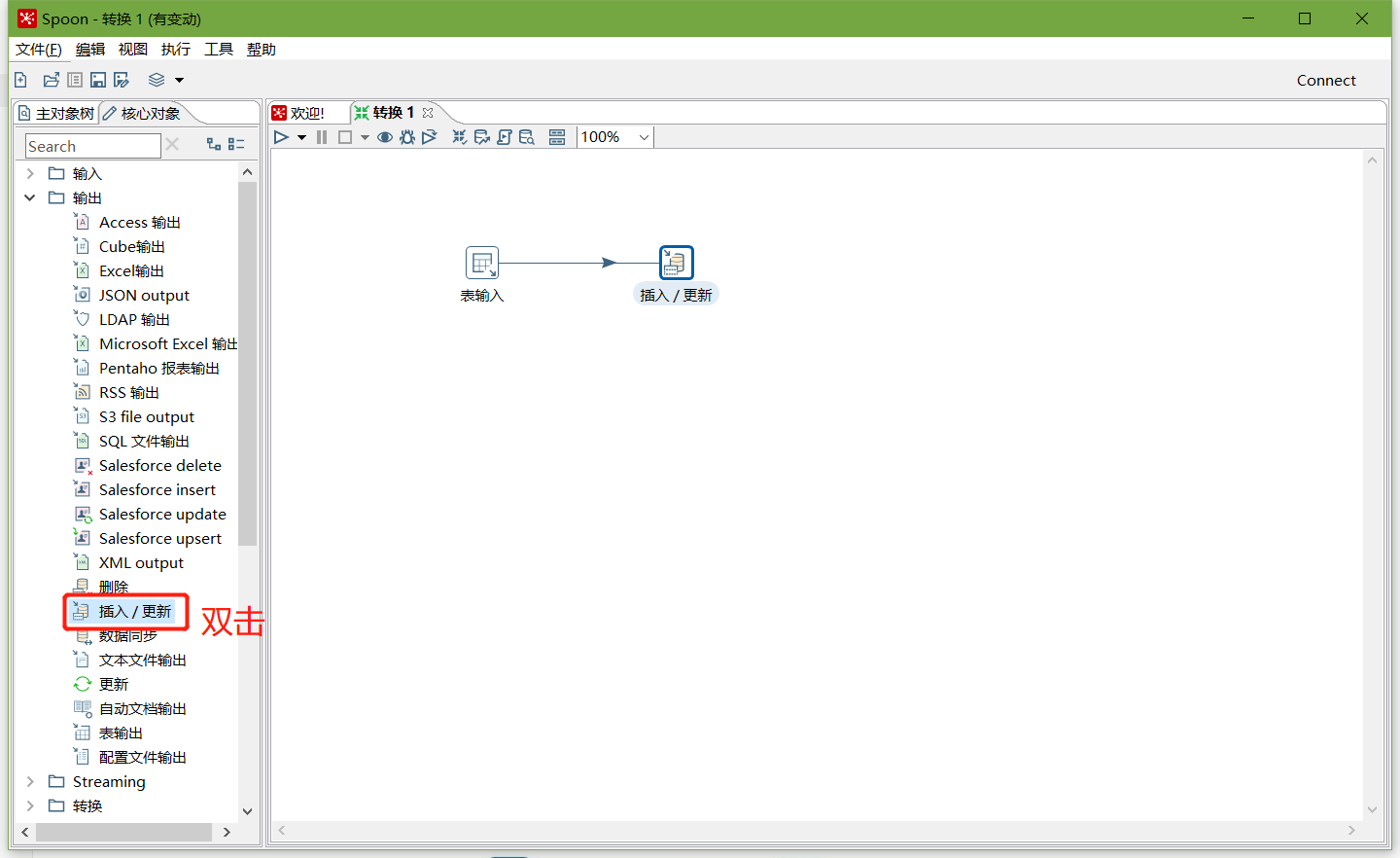
注意:拖出來的線條必須是深灰色才關聯成功,若是淺灰色表示關聯失敗
轉換之前,需要做保存
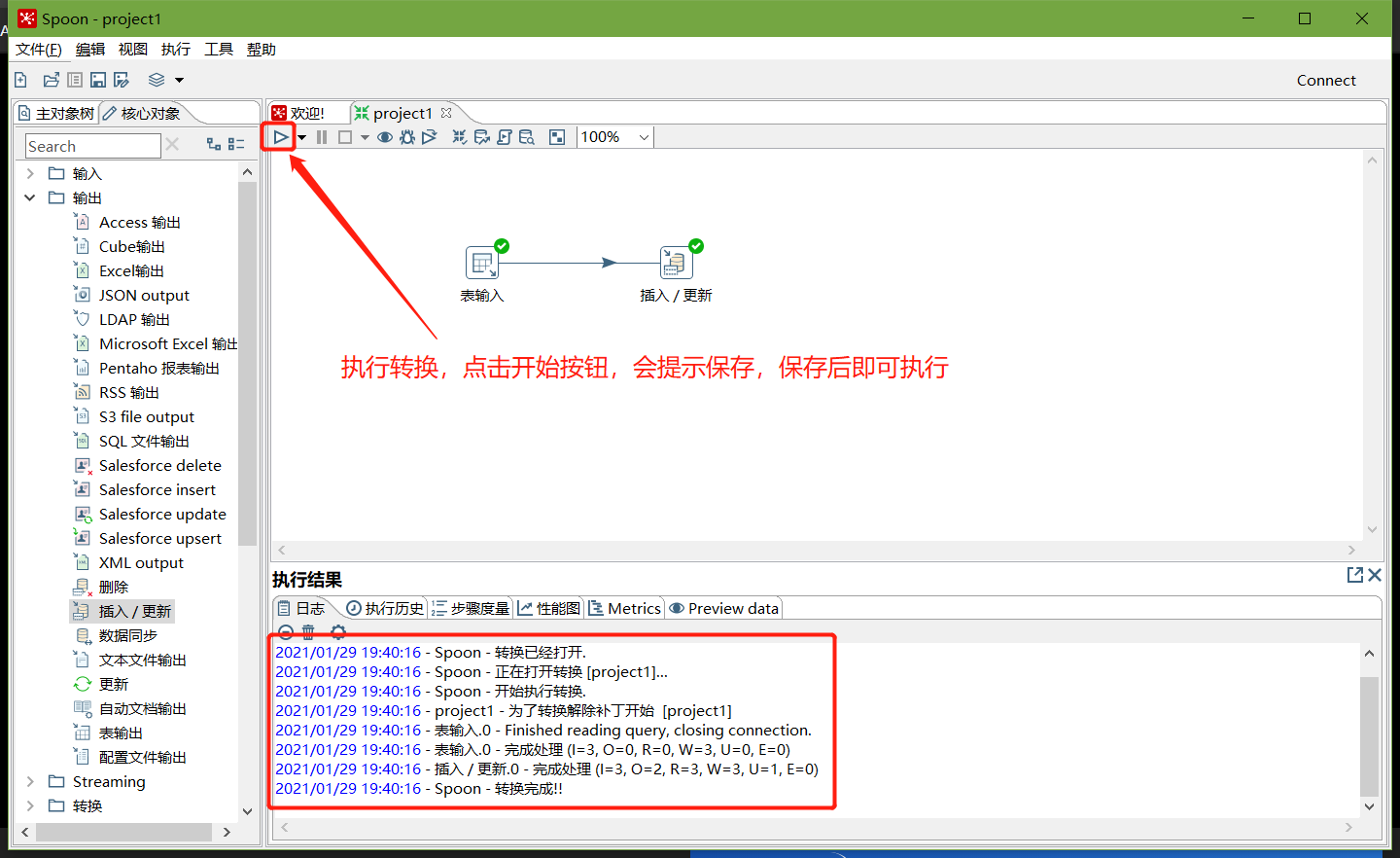
執行成功之后,可以在mysql查看,stu2的資料
mysql> select * from stu2;
+------+----------+
| id | name |
+------+----------+
| 1001 | zhangsan |
| 1002 | lisi |
| 1003 | wangwu |
+------+----------+
3 rows in set (0.00 sec)
案例2:使用作業執行上述轉換,并且額外在表stu2中添加一條資料
1、新建一個作業
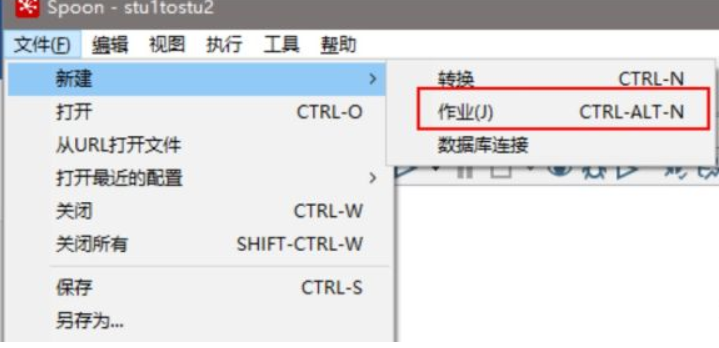
2、按圖示拉取組件
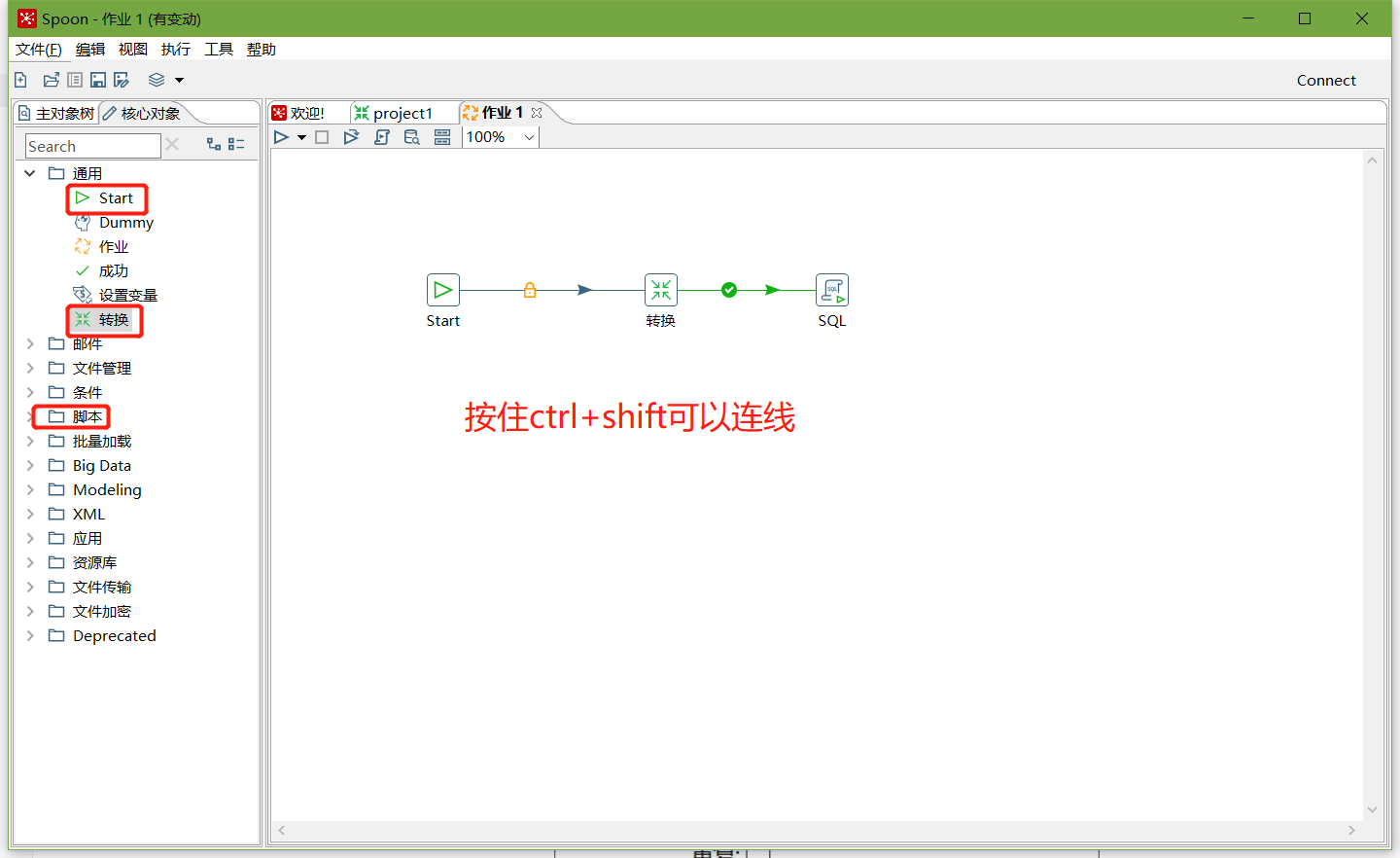
3、雙擊Start編輯Start
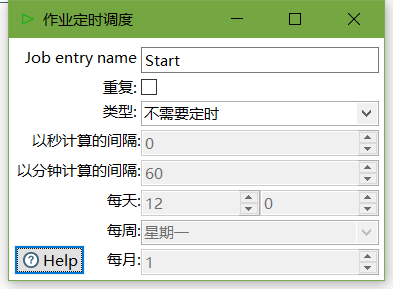
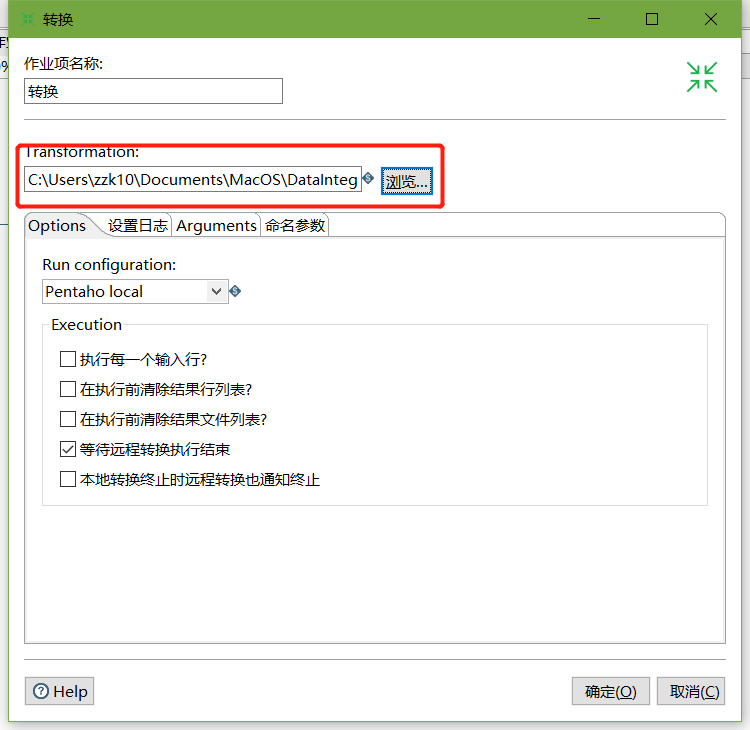
4、雙擊轉換,選擇案例1保存的檔案
5、在mysql的stu1中插入一條資料,并將stu2中id=1001的name改為wukong
mysql> insert into stu1 values(1004,'stu1',22);
Query OK, 1 row affected (0.01 sec)
mysql> update stu2 set name = 'wukong' where id = 1001;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
6、雙擊SQL腳本編輯
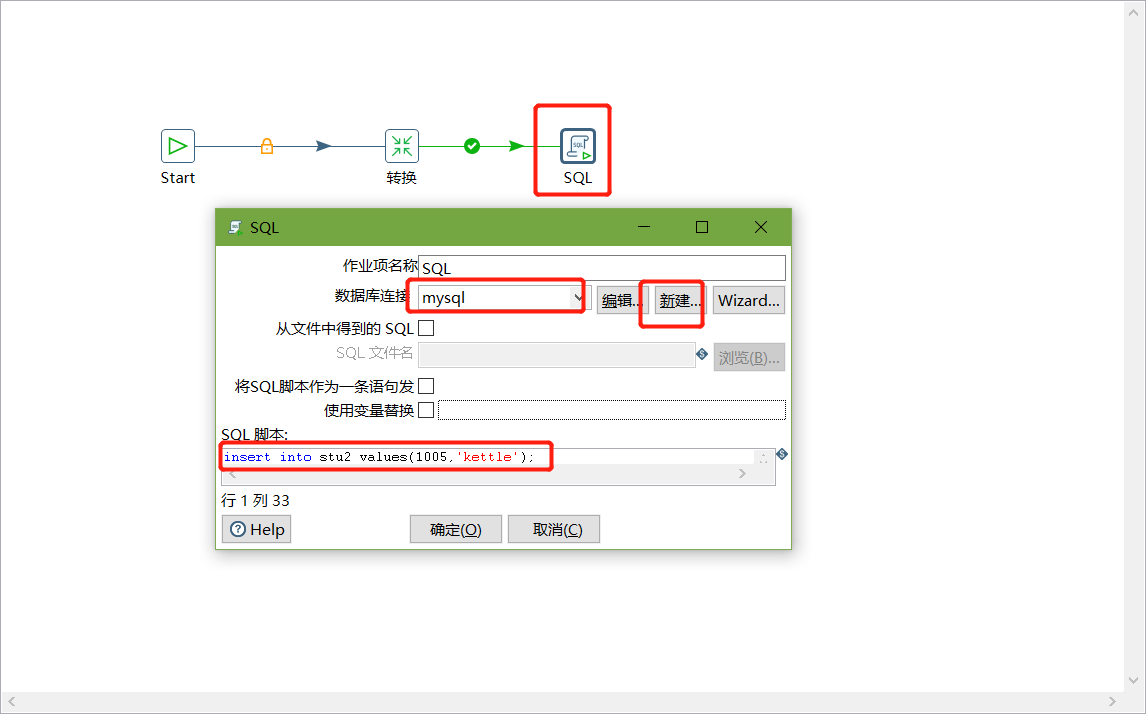
7、加上Dummy,如圖所示:
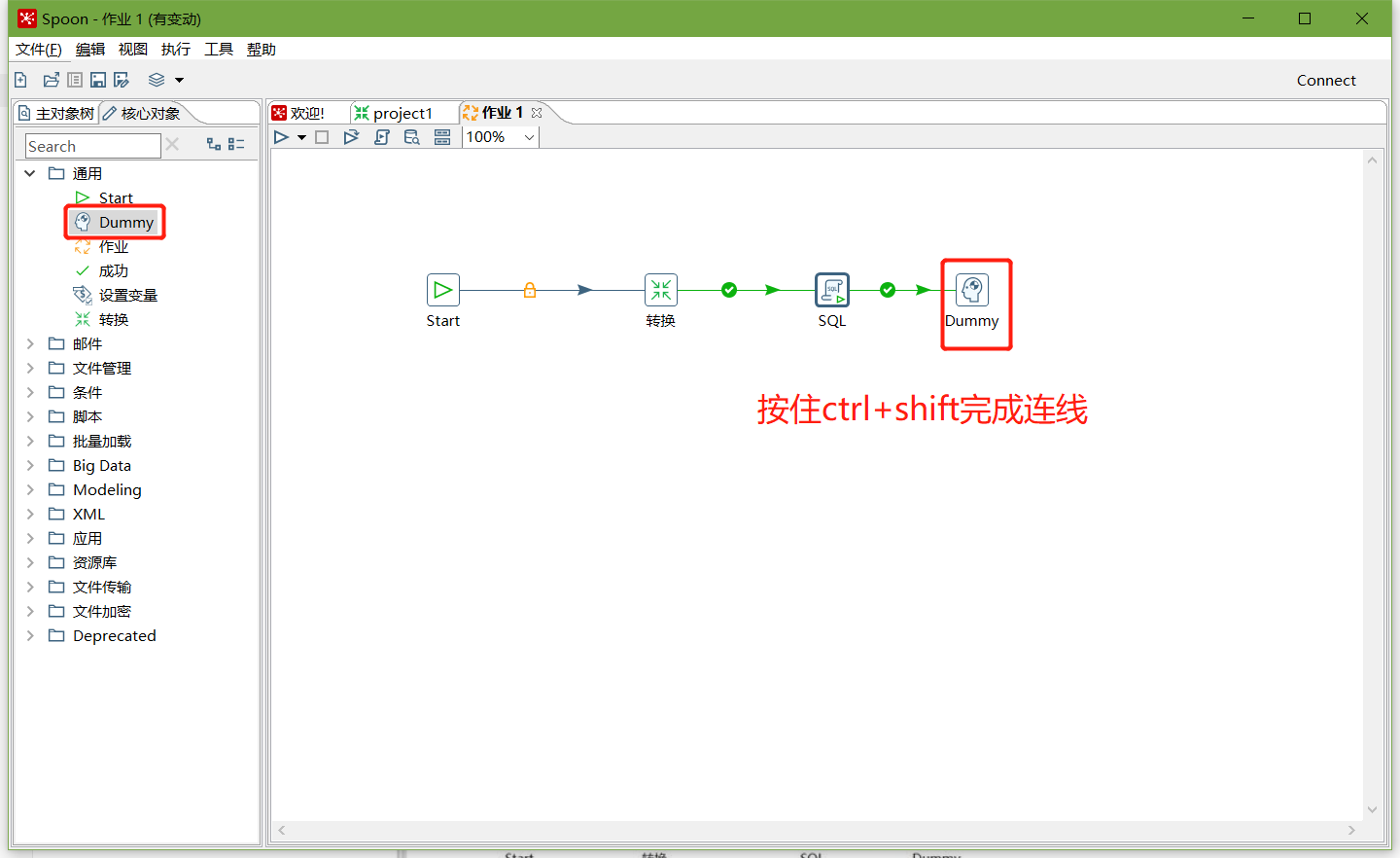
8、保存并執行
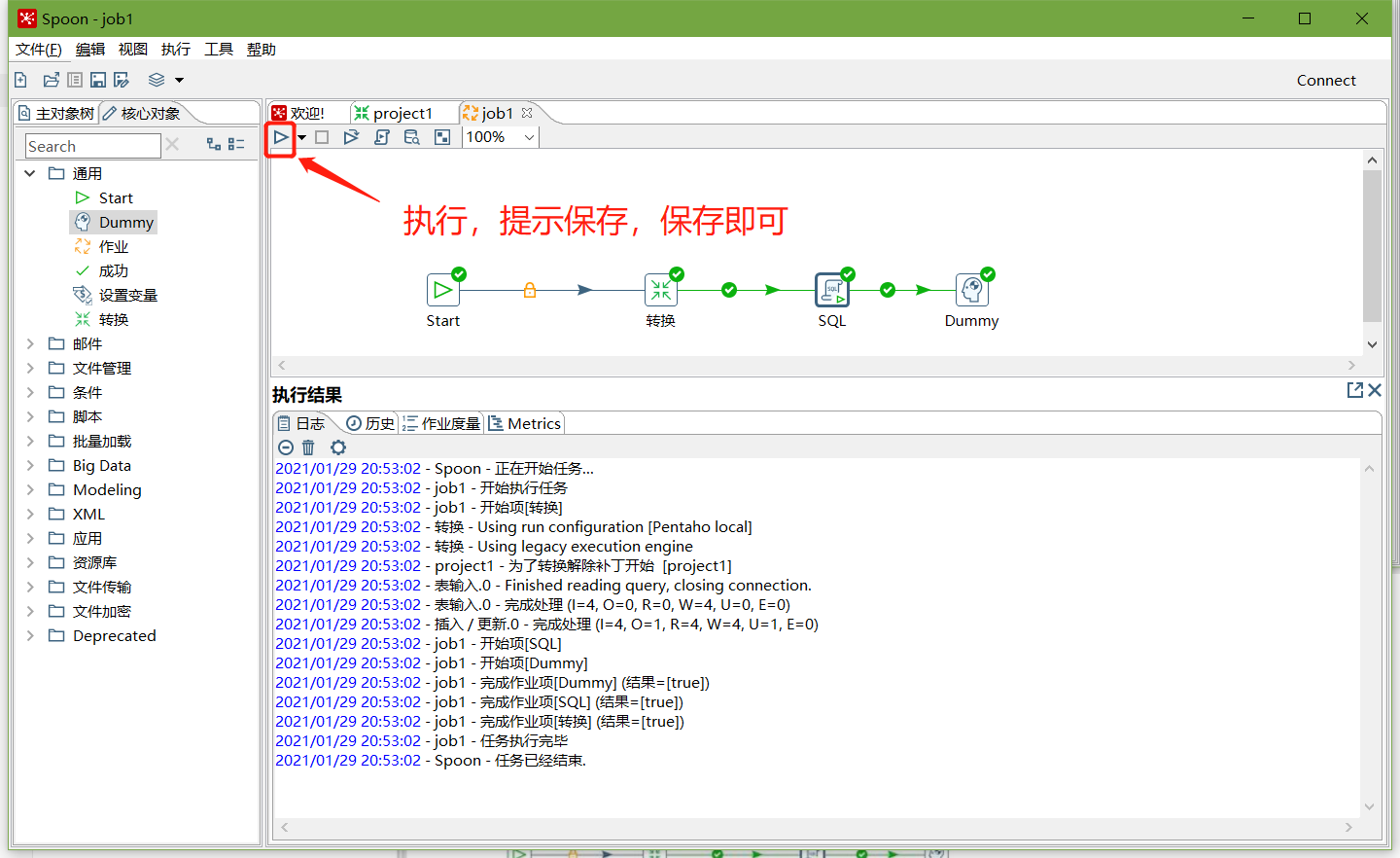
9、在mysql資料庫查看stu2表的資料
mysql> select * from stu2;
+------+----------+
| id | name |
+------+----------+
| 1001 | zhangsan |
| 1002 | lisi |
| 1003 | wangwu |
| 1004 | stu1 |
| 1005 | kettle |
+------+----------+
5 rows in set (0.00 sec)
案例3:將hive表的資料輸出到hdfs
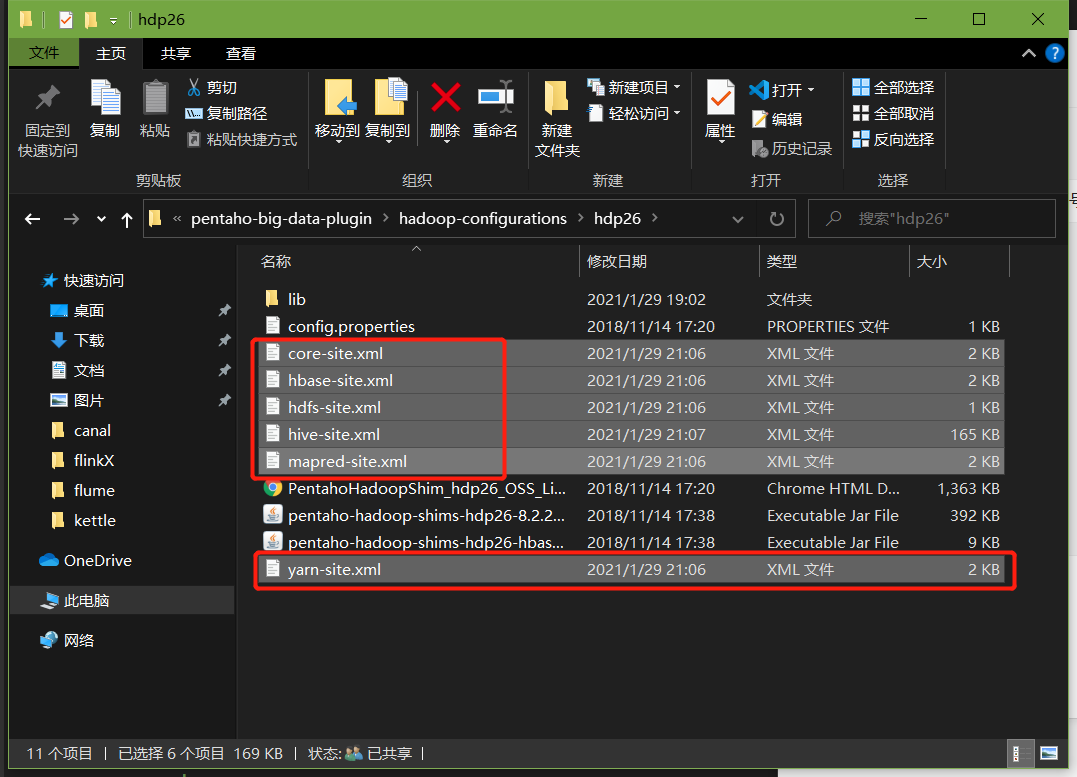
1、因為涉及到hive和hbase(后續案例)的讀寫,需要修改相關組態檔
修改解壓目錄下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,設定active.hadoop.configuration=hdp26,并將如下組態檔拷貝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下
2、啟動hadoop集群、hiveserver2服務
3、進入hive shell,創建kettle資料庫,并創建dept、emp表
create database kettle;
use kettle;
CREATE TABLE dept(
deptno int,
dname string,
loc string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm int,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
4、插入資料
insert into dept values(10,'accounting','NEW YORK'),(20,'RESEARCH','DALLAS'),(30,'SALES','CHICAGO'),(40,'OPERATIONS','BOSTON');
insert into emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20),(7499,'ALLEN','SALESMAN',7698,'1980-12-17',1600,300,30),(7521,'WARD','SALESMAN',7698,'1980-12-17',1250,500,30),(7566,'JONES','MANAGER',7839,'1980-12-17',2975,NULL,20);
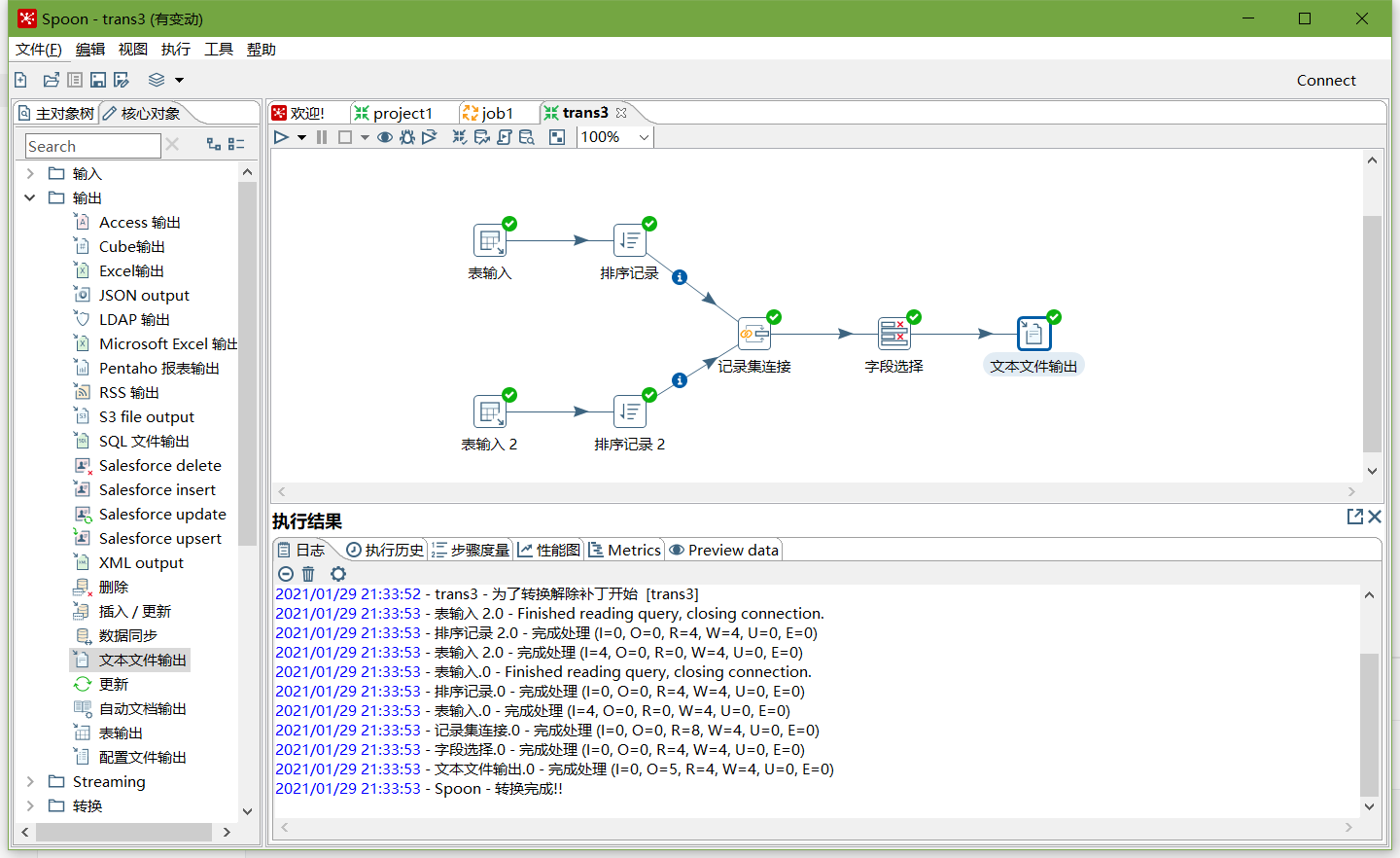
5、按下圖建立流程圖
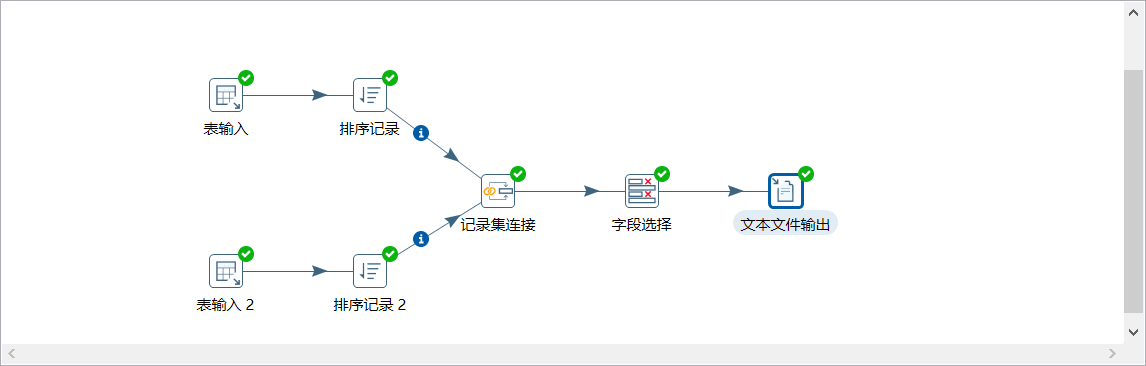
- 表輸入
- 表輸入2
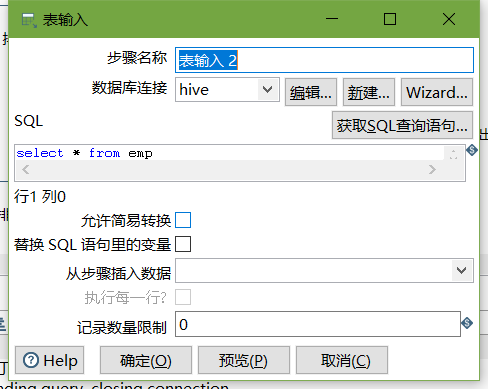
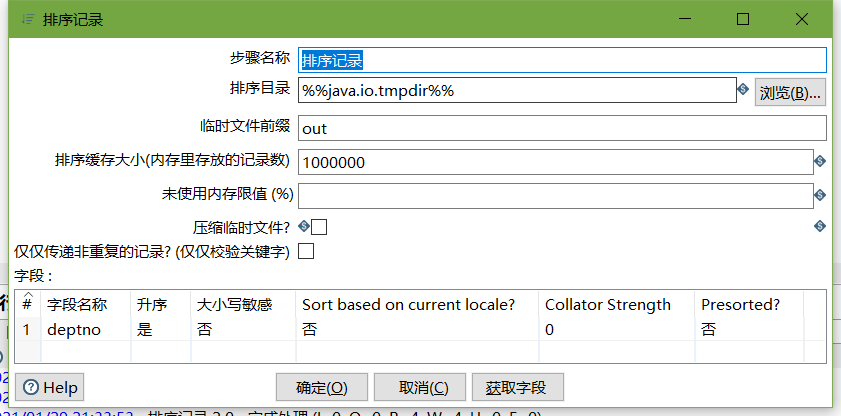
- 排序記錄
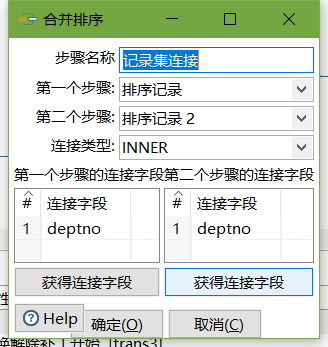
- 記錄集連接
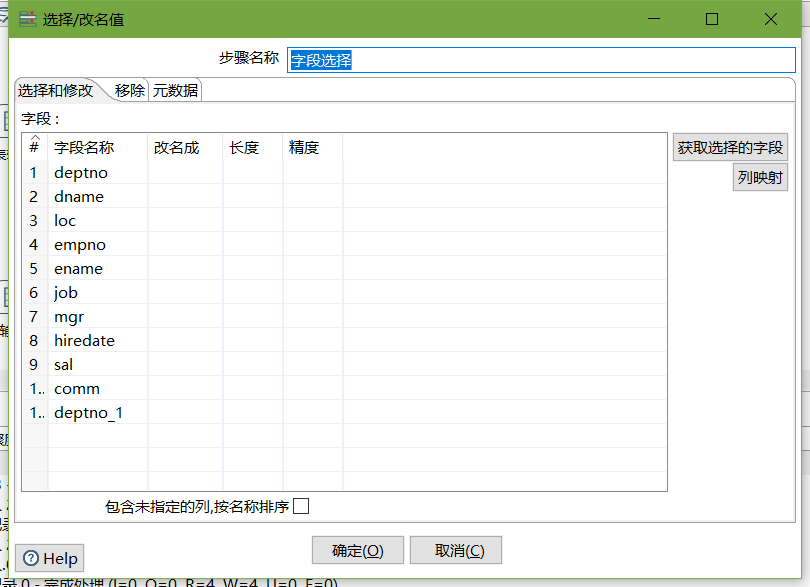
- 欄位選擇
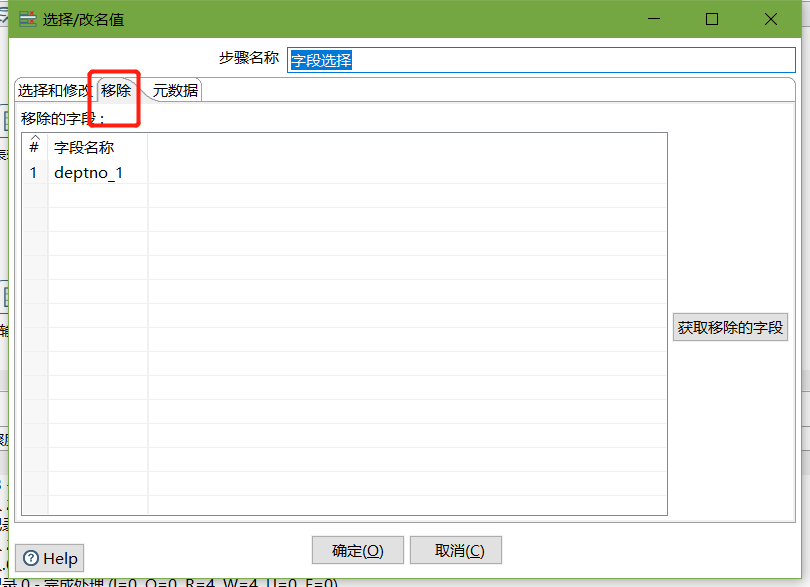
- 文本檔案輸出
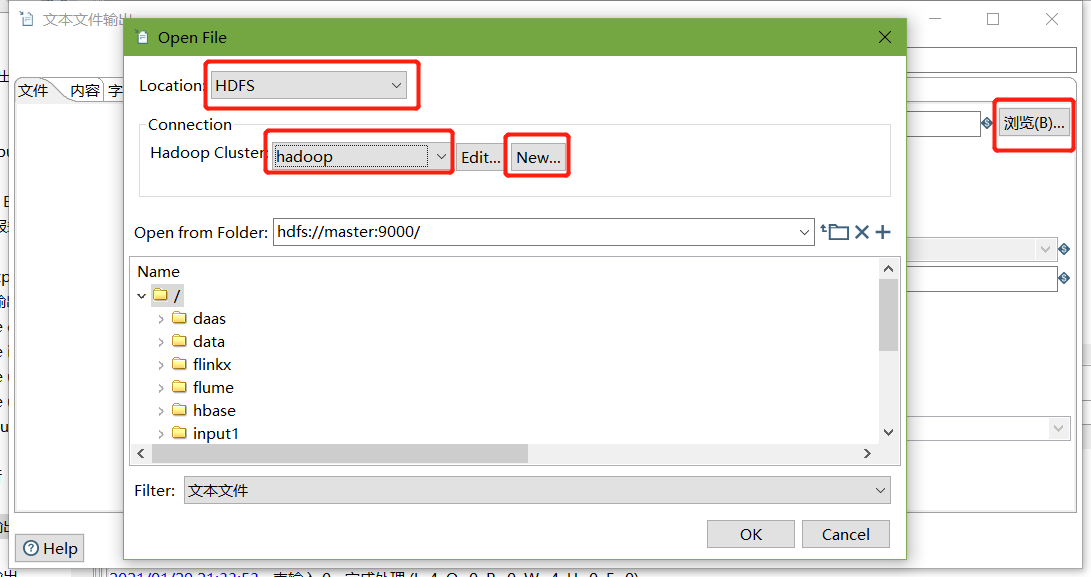
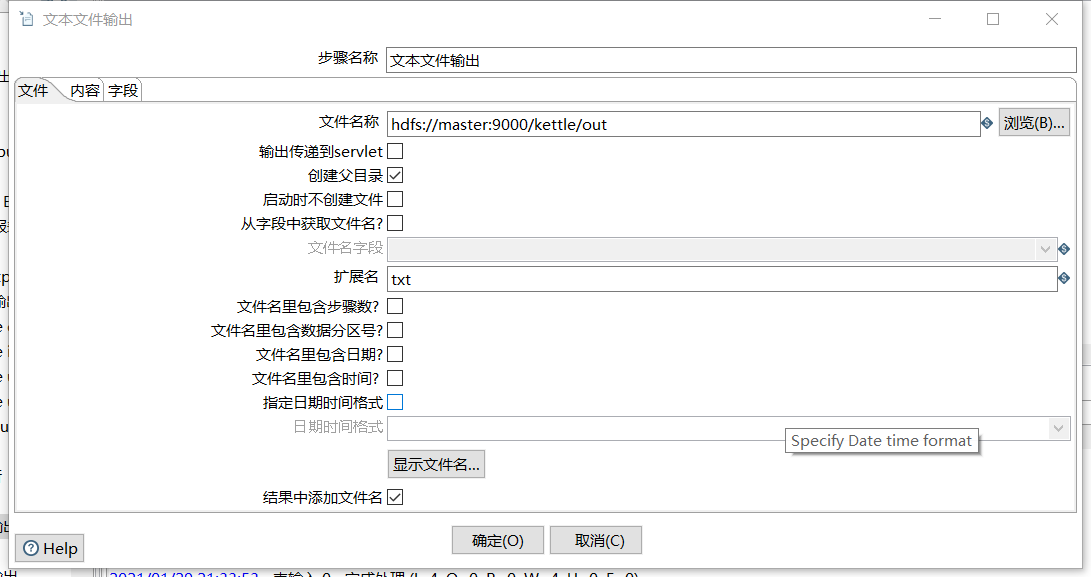
6、保存并運行查看hdfs
- 運行
- 查看HDFS檔案
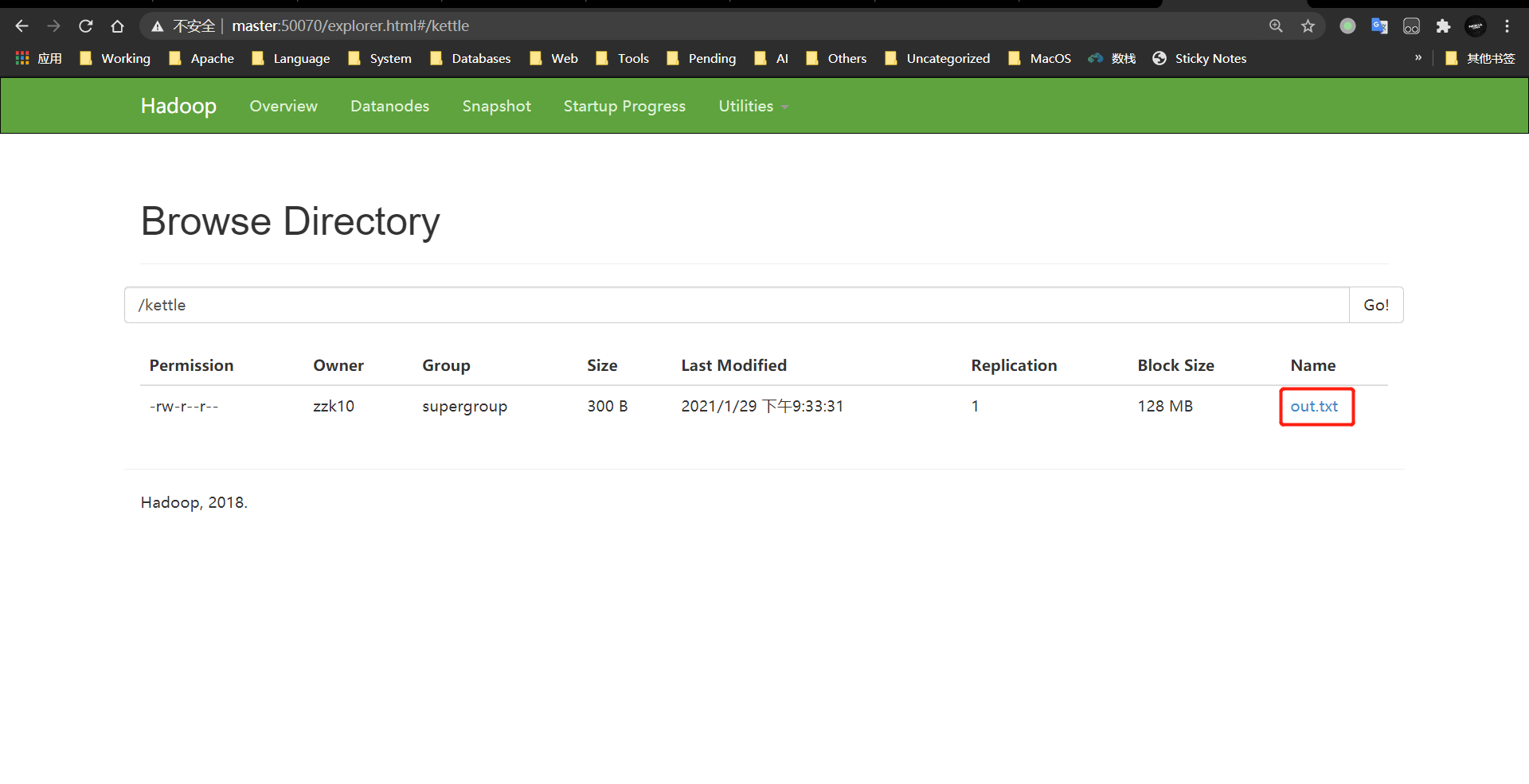
案例4:讀取hdfs檔案并將sal大于1000的資料保存到hbase中
1、在HBase中創建一張people表
hbase(main):004:0> create 'people','info'
2、按下圖建立流程圖
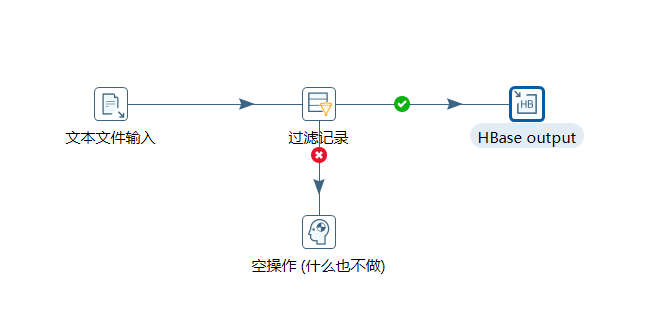
- 文本檔案輸入
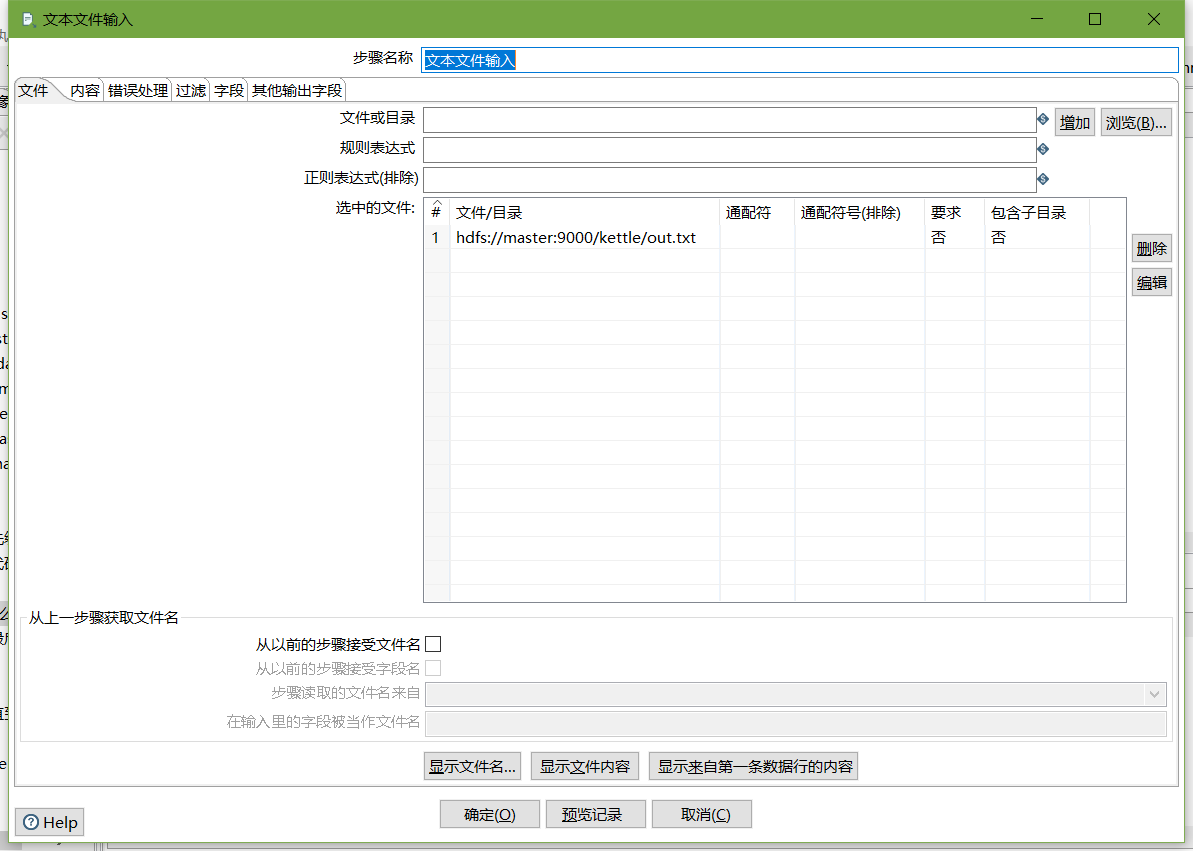
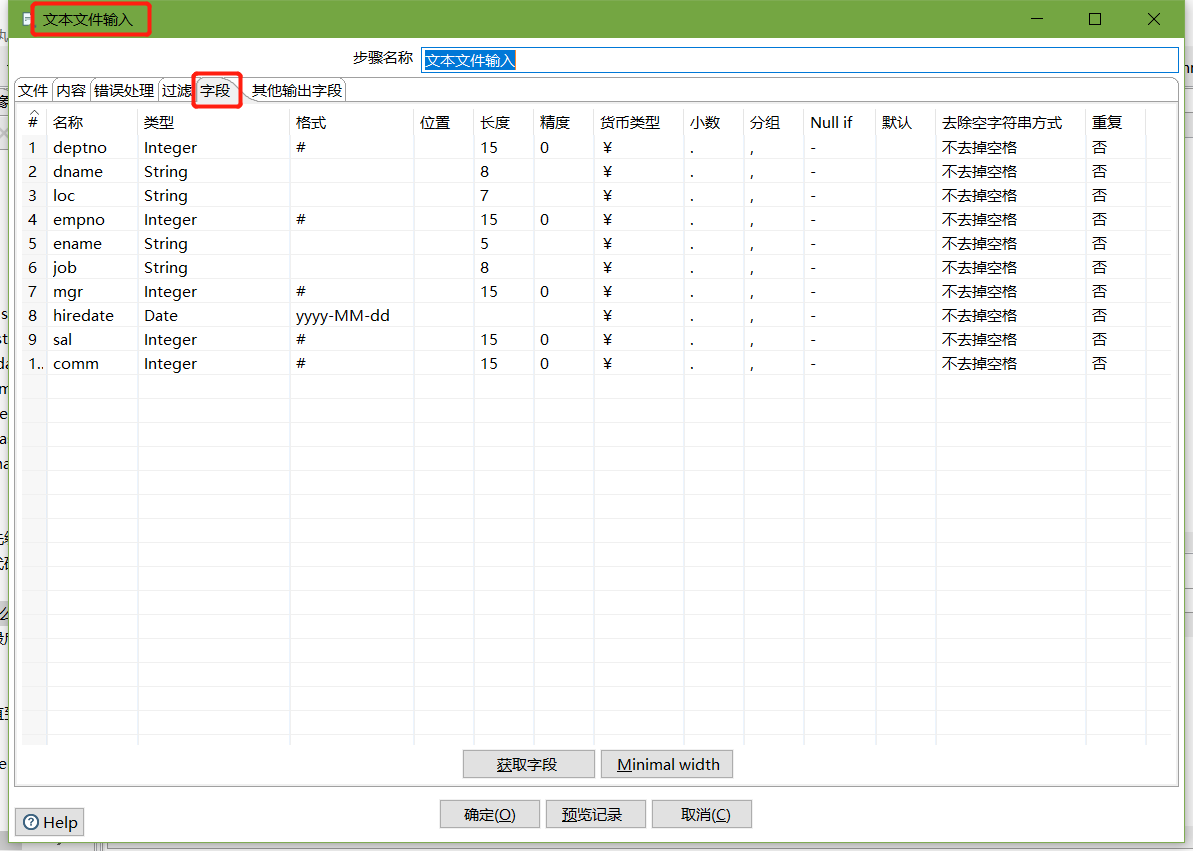
- 設定過濾記錄
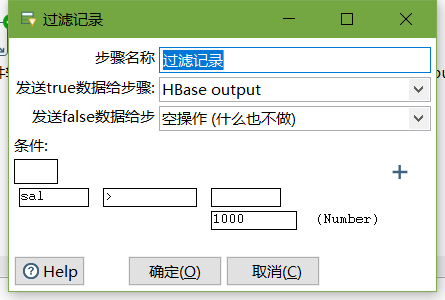
-
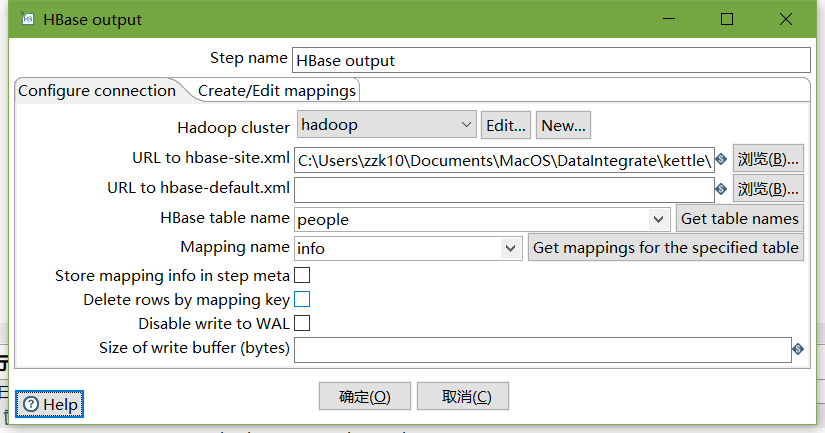
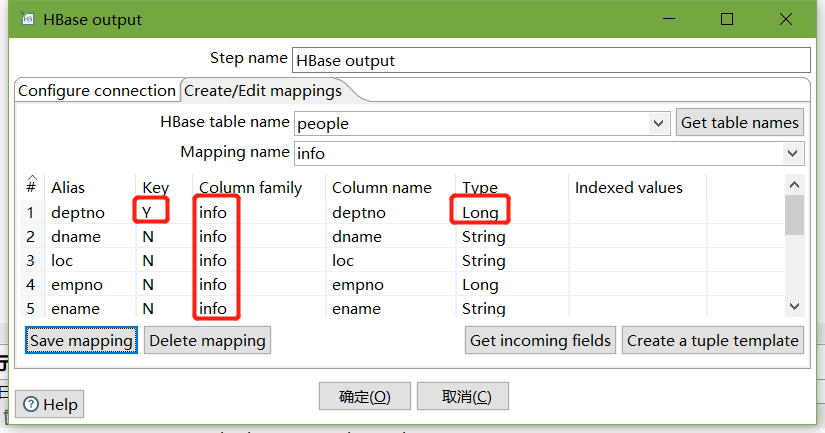
設定HBase output
編輯hadoop連接,并配置zookeeper地址
- 執行轉換

-
查看hbase people表的資料
scan 'people'注意:若報錯沒有權限往hdfs寫檔案,在Spoon.bat中第119行添加引數
"-DHADOOP_USER_NAME=root" "-Dfile.encoding=UTF-8"
三、創建資源庫
1、資料庫資源庫
資料庫資源庫是將作業和轉換相關的資訊存盤在資料庫中,執行的時候直接去資料庫讀取資訊,方便跨平臺使用
-
在MySQL中創建kettle資料庫
mysql> create database kettle; Query OK, 1 row affected (0.01 sec) -
點擊右上角connect,選擇Other Resporitory
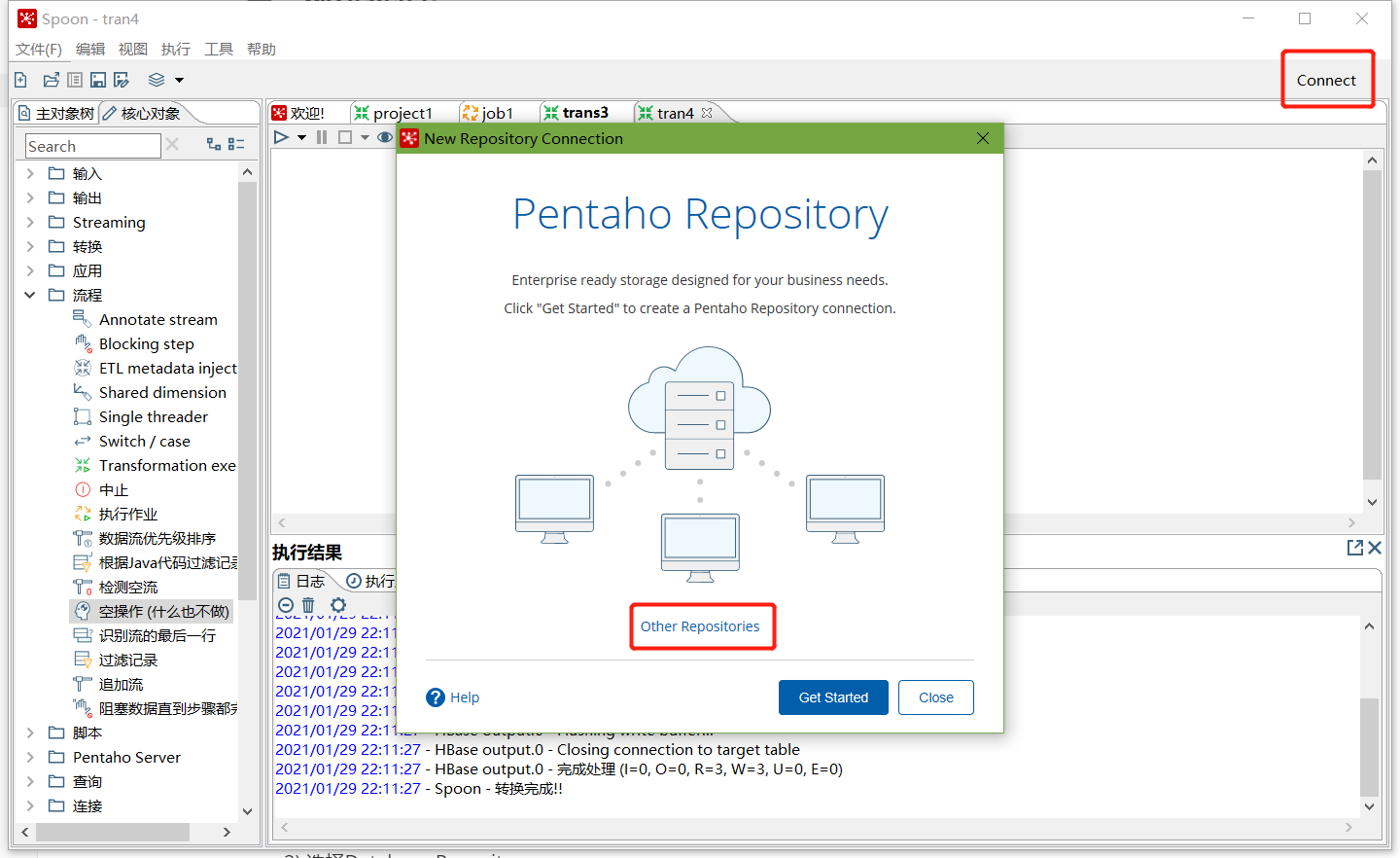
- 選擇Database Repository
- 建立新連接
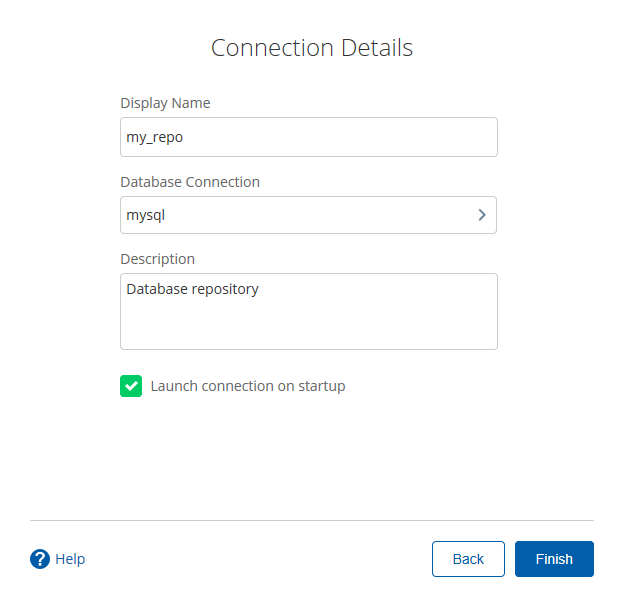
- 填好之后,點擊finish,會在指定的庫中創建很多表,至此資料庫資源庫創建完成
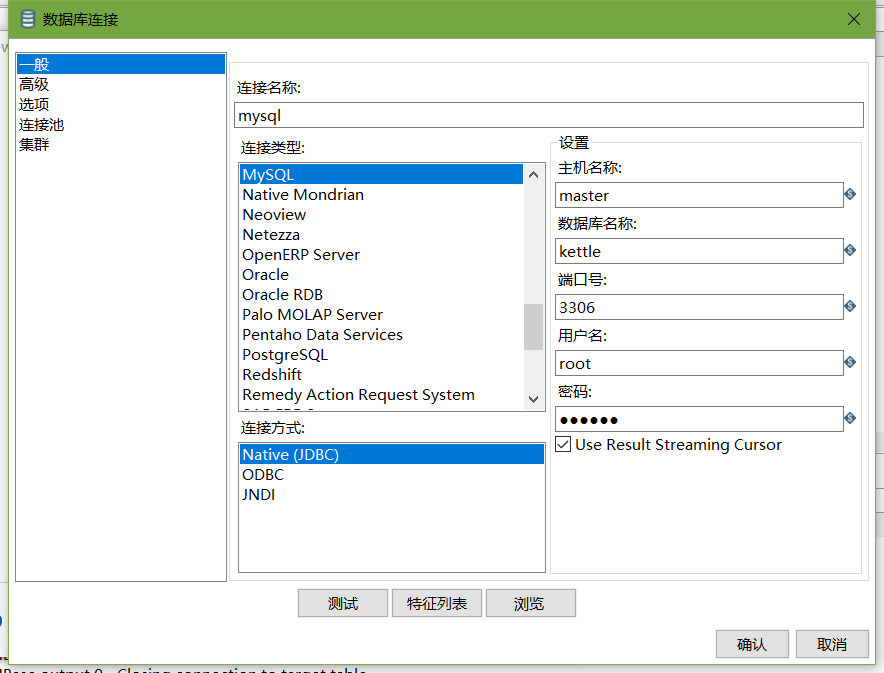
-
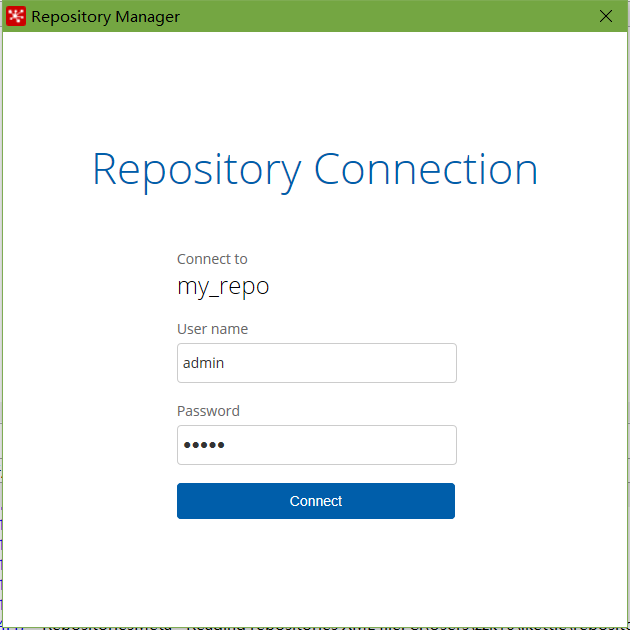
連接資源庫
默認賬號密碼為admin
-
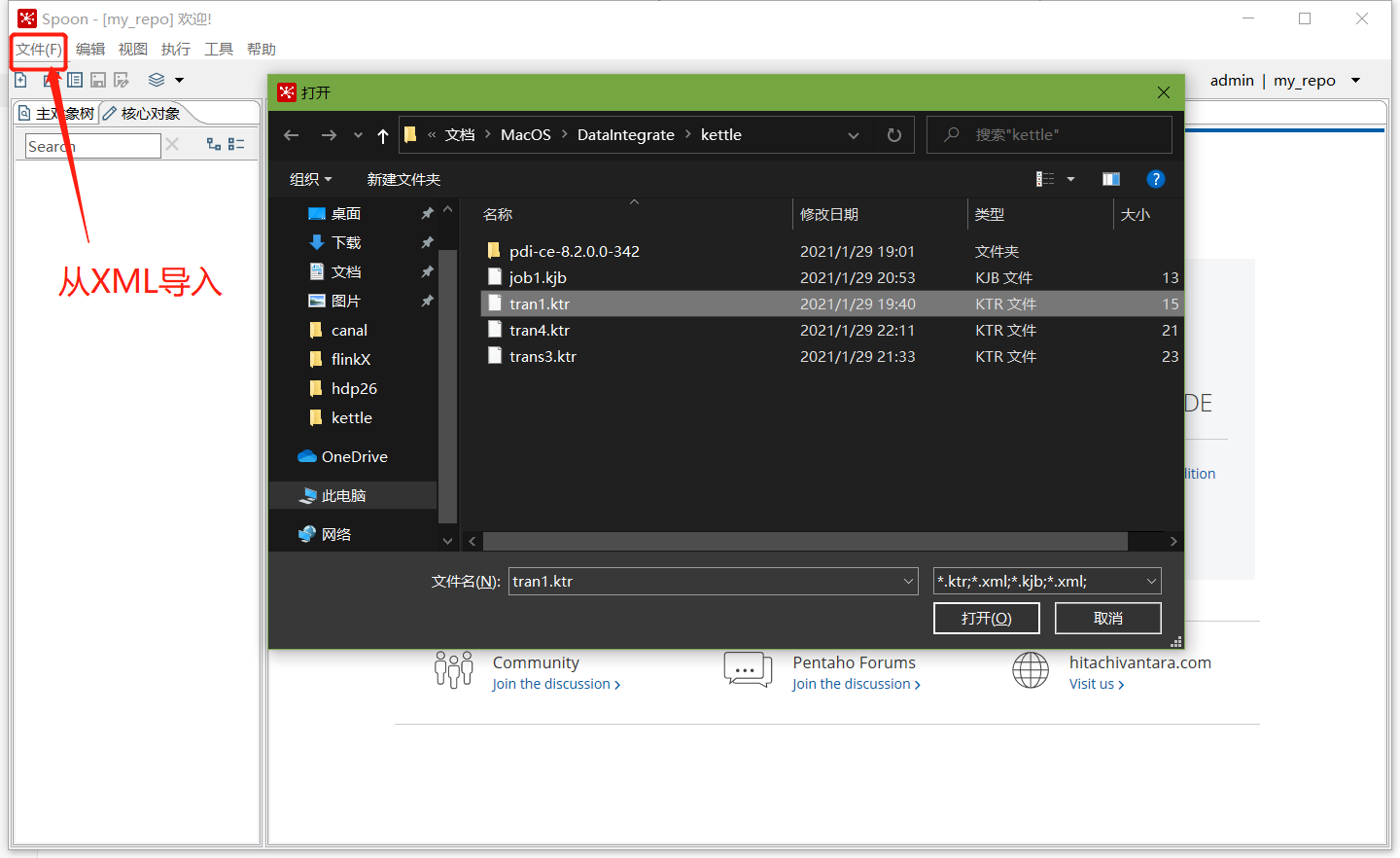
將之前做過的轉換匯入資源庫
-
選擇從xml檔案匯入
-
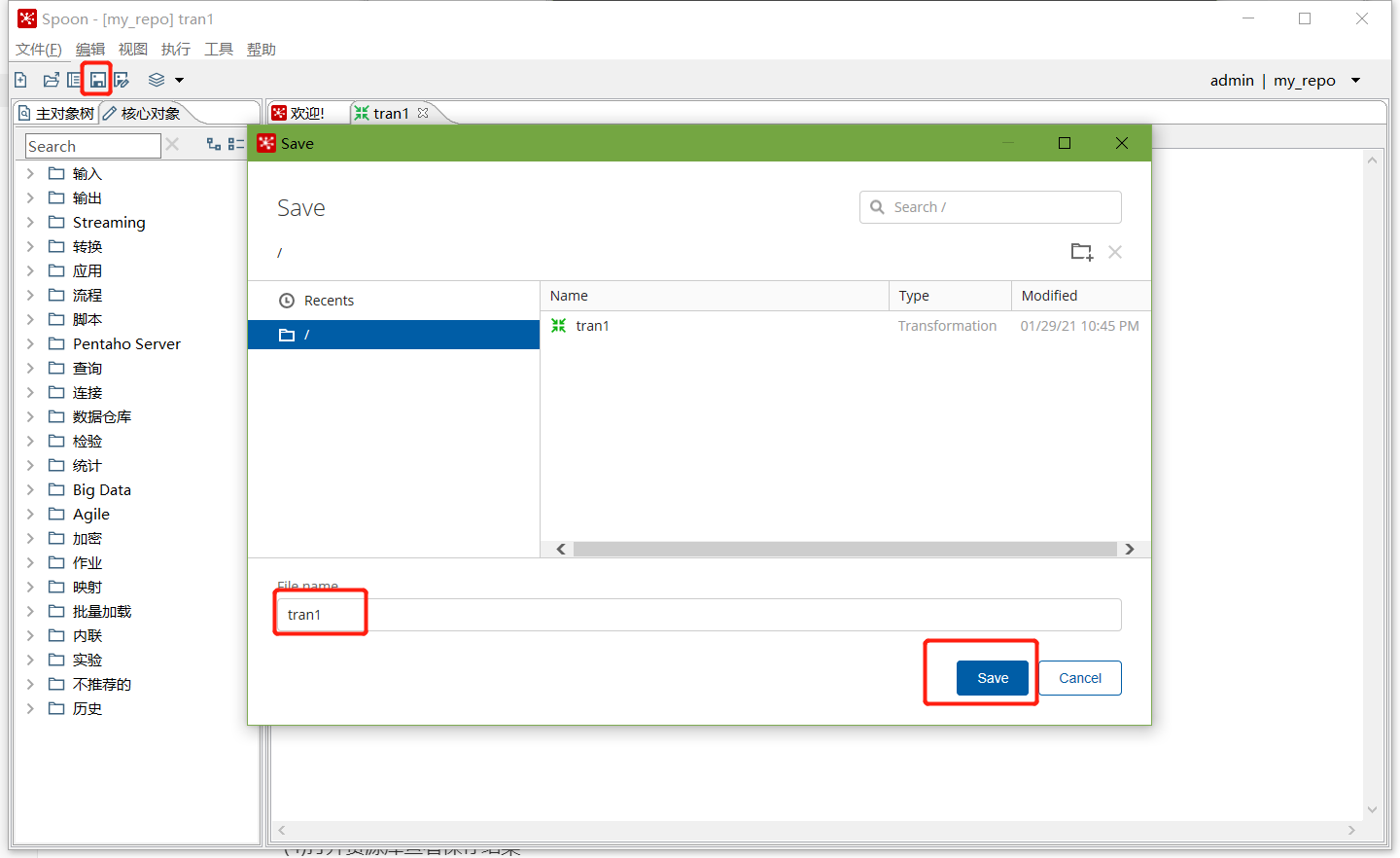
點擊保存,選擇存盤位置及檔案名
-
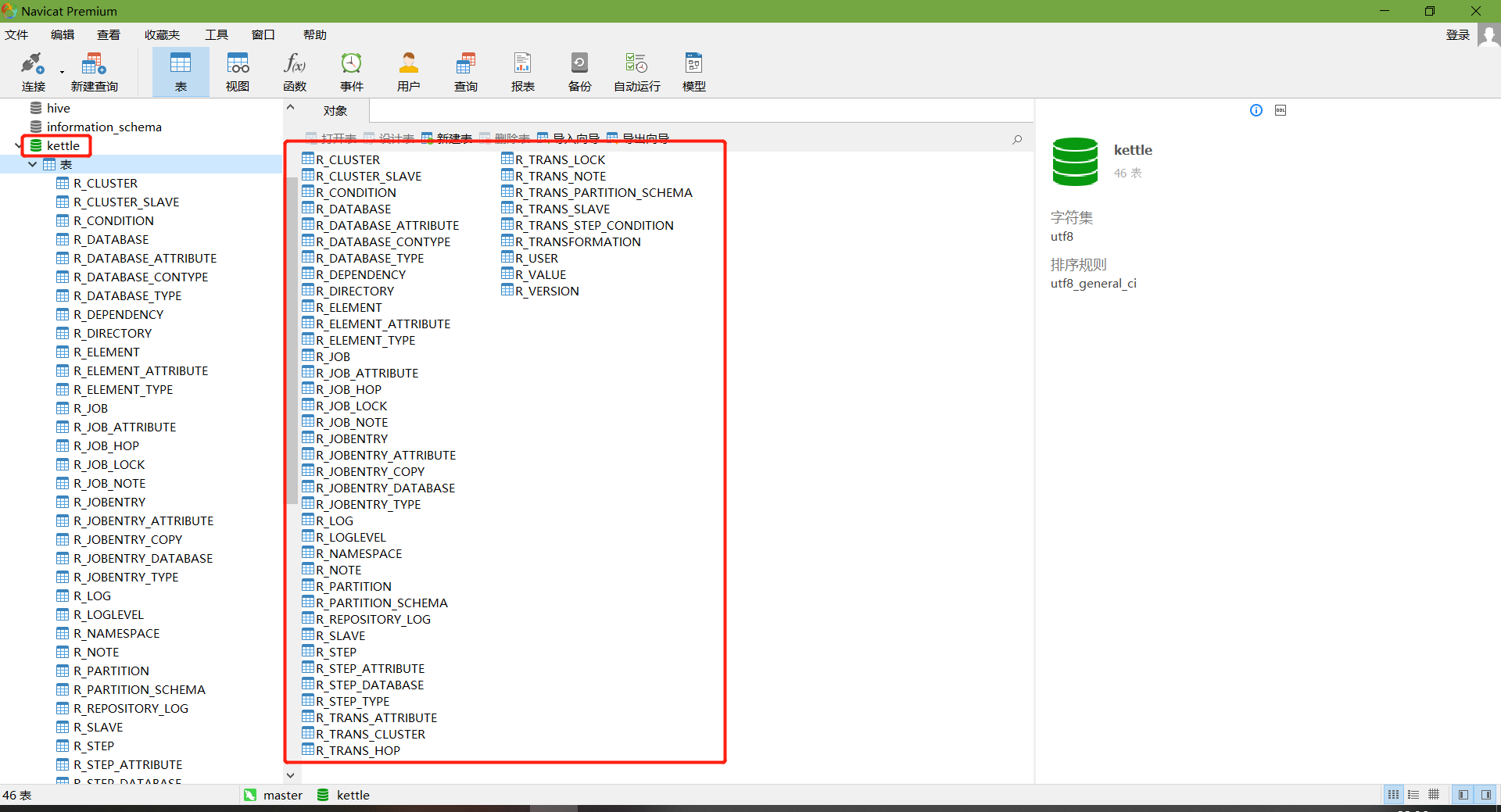
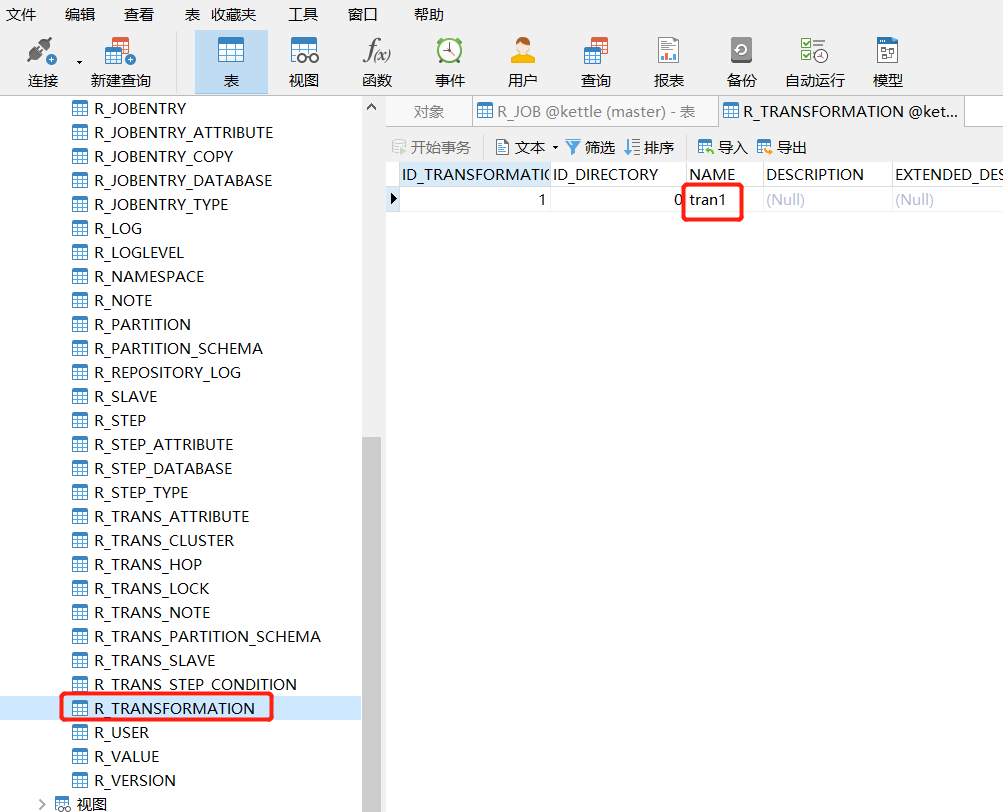
查看MySQL中kettle庫中的R_TRANSFORMATION表,觀察轉換是否保存
-
2、檔案資源庫
將作業和轉換相關的資訊存盤在指定的目錄中,其實和XML的方式一樣
創建方式跟創建資料庫資源庫步驟類似,只是不需要用戶密碼就可以訪問,跨
平臺使用比較麻煩
-
選擇connect
-
點擊add后點擊Other Repositories
-
選擇File Repository
-
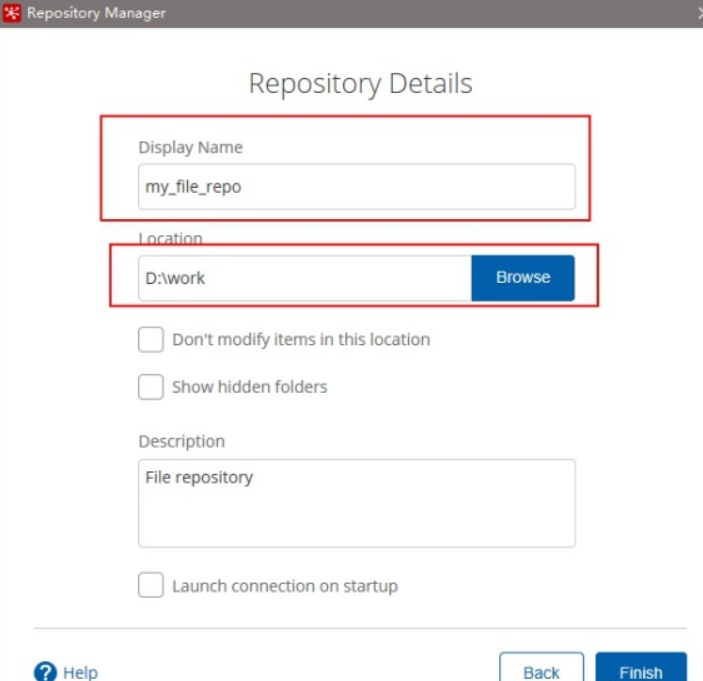
填寫資訊
四、 Linux下安裝使用
1、單機
-
jdk安裝
-
安裝包上傳到服務器,并解壓
注意:
-
把mysql驅動拷貝到lib目錄下
-
將windows本地用戶家目錄下的隱藏目錄C:\Users\自己用戶名\.kettle 目錄,
整個上傳到linux的用戶的家目錄下,root用戶的家目錄為/root/
-
-
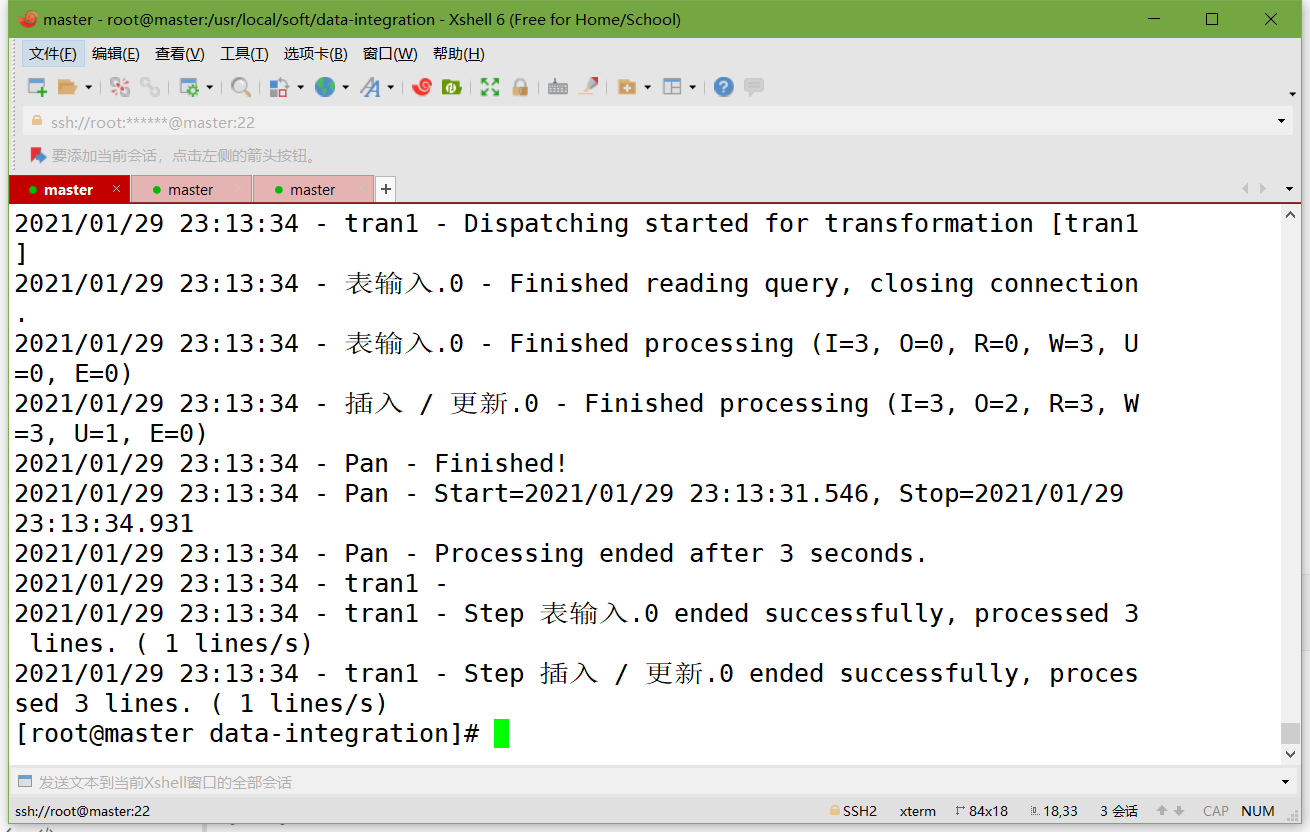
運行資料庫資源庫中的轉換:
cd /usr/local/soft/data-integration ./pan.sh -rep=my_repo -user=admin -pass=admin -trans=tran1引數說明:
? -rep 資源庫名稱
? -user 資源庫用戶名
? -pass 資源庫密碼
? -trans 要啟動的轉換名稱
? -dir 目錄(不要忘了前綴 /)(如果是以ktr檔案運行時,需要指定ktr檔案的路徑)
-
運行資源庫里的作業:
記得把作業里的轉換變成資源庫中的資源
記得把作業也變成資源庫中的資源
cd /usr/local/soft/data-integration mkdir logs ./kitchen.sh -rep=my_repo -user=admin -pass=admin -job=job1 -logfile=./logs/log.txt引數說明:
-rep - 資源庫名
-user - 資源庫用戶名
-pass – 資源庫密碼
-job – job名
-dir – job路徑(當直接運行kjb檔案的時候需要指定)
-logfile – 日志目錄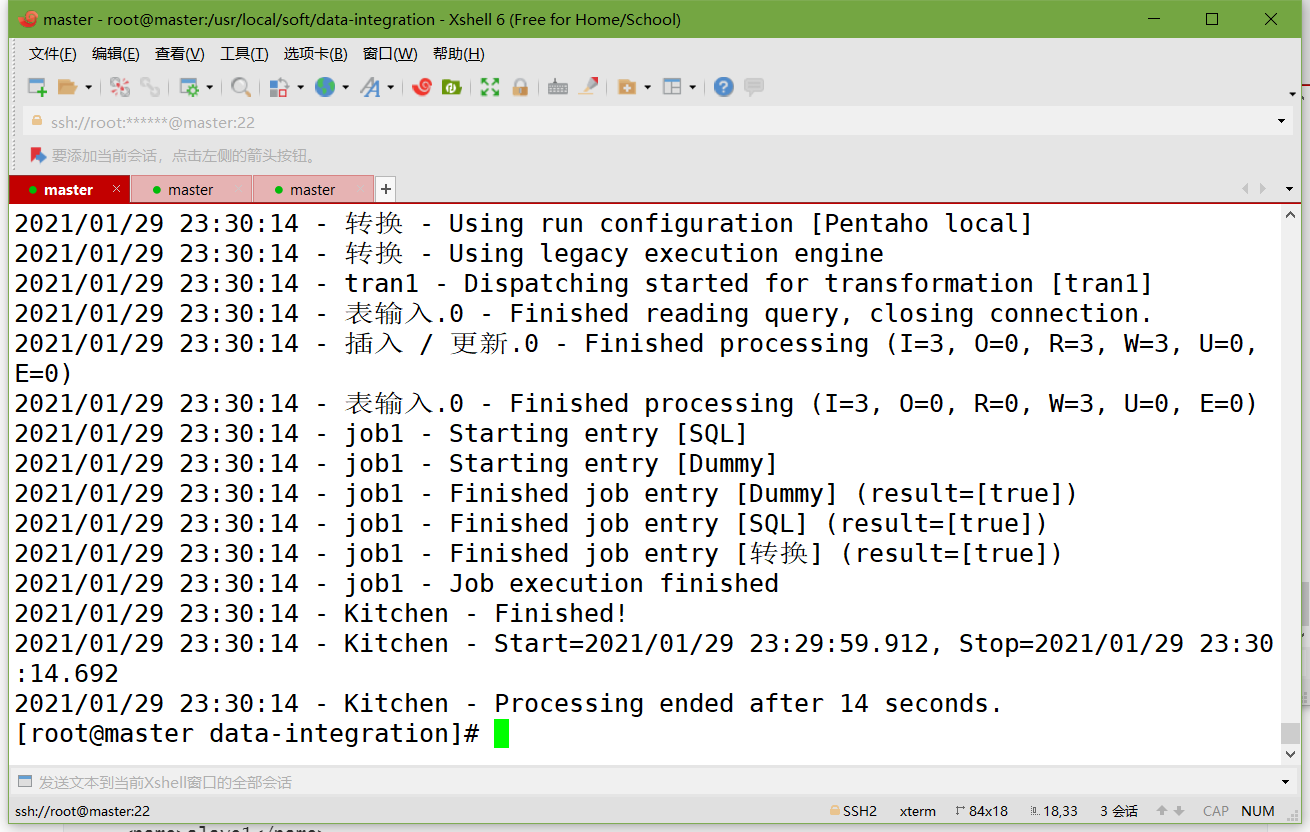
2、 集群模式
-
準備三臺服務器
master作為Kettle主服務器,服務器埠號為8080,
node1和node2作為兩個子服務器,埠號分別為8081和8082,
-
安裝部署jdk
-
hadoop完全分布式環境搭建
-
上傳并解壓kettle的安裝包至
/usr/local/soft/目錄下 -
進到/usr/local/soft/data-integration/pwd目錄,修改組態檔
-
修改主服務器組態檔carte-config-master-8080.xml
<slaveserver> <name>master</name> <hostname>master</hostname> <port>8080</port> <master>Y</master> <username>cluster</username> <password>cluster</password> </slaveserver> -
修改從服務器組態檔carte-config-8081.xml
<masters> <slaveserver> <name>master</name> <hostname>master</hostname> <port>8080</port> <username>cluster</username> <password>cluster</password> <master>Y</master> </slaveserver> </masters> <report_to_masters>Y</report_to_masters> <slaveserver> <name>slave1</name> <hostname>node1</hostname> <port>8081</port> <username>cluster</username> <password>cluster</password> <master>N</master> </slaveserver> -
修改從組態檔carte-config-8082.xml
<masters> <slaveserver> <name>master</name> <hostname>master</hostname> <port>8080</port> <username>cluster</username> <password>cluster</password> <master>Y</master> </slaveserver> </masters> <report_to_masters>Y</report_to_masters> <slaveserver> <name>slave2</name> <hostname>node2</hostname> <port>8082</port> <username>cluster</username> <password>cluster</password> <master>N</master> </slaveserver>
-
-
分發整個kettle的安裝目錄,通過scp命令
-
分發/root/.kettle目錄到node1、node2
-
啟動相關行程,在master,node1,node2上分別執行
[root@master]# ./carte.sh master 8080
[root@node1]# ./carte.sh node1 8081
[root@node2]# ./carte.sh node2 8082
- 訪問web頁面
http://master:8080
案例:讀取hive中的emp表,根據id進行排序,并將結果輸出到hdfs上
注意:因為涉及到hive和hbase的讀寫,需要修改相關組態檔,
修改解壓目錄下的data-integration\plugins\pentaho-big-data-plugin下的plugin.properties,設定active.hadoop.configuration=hdp26,并將如下組態檔拷貝到data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp26下
-
創建轉換,編輯步驟,填好相關配置
直接使用trans1
-
創建子服務器,填寫相關配置,跟集群上的配置相同
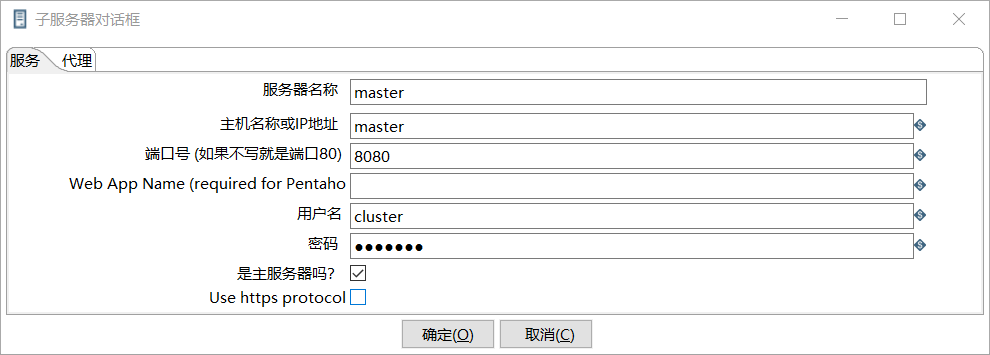
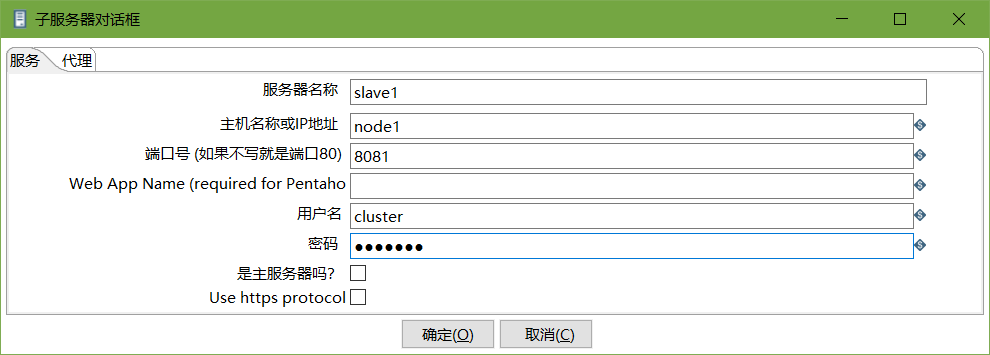
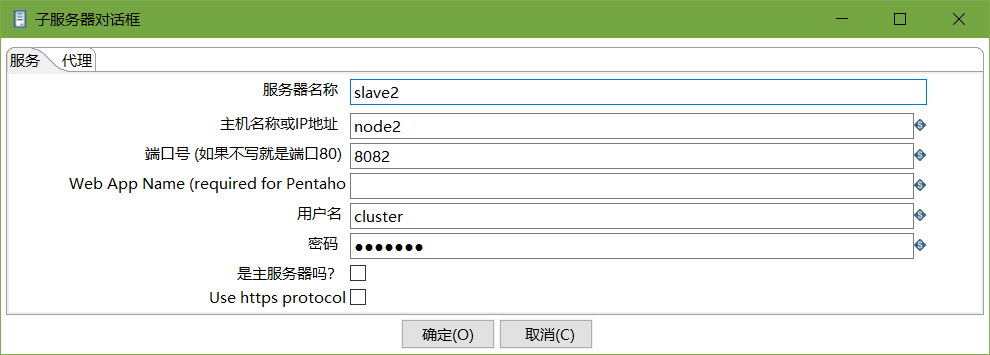
-
創建集群schema,選中上一步的幾個服務器
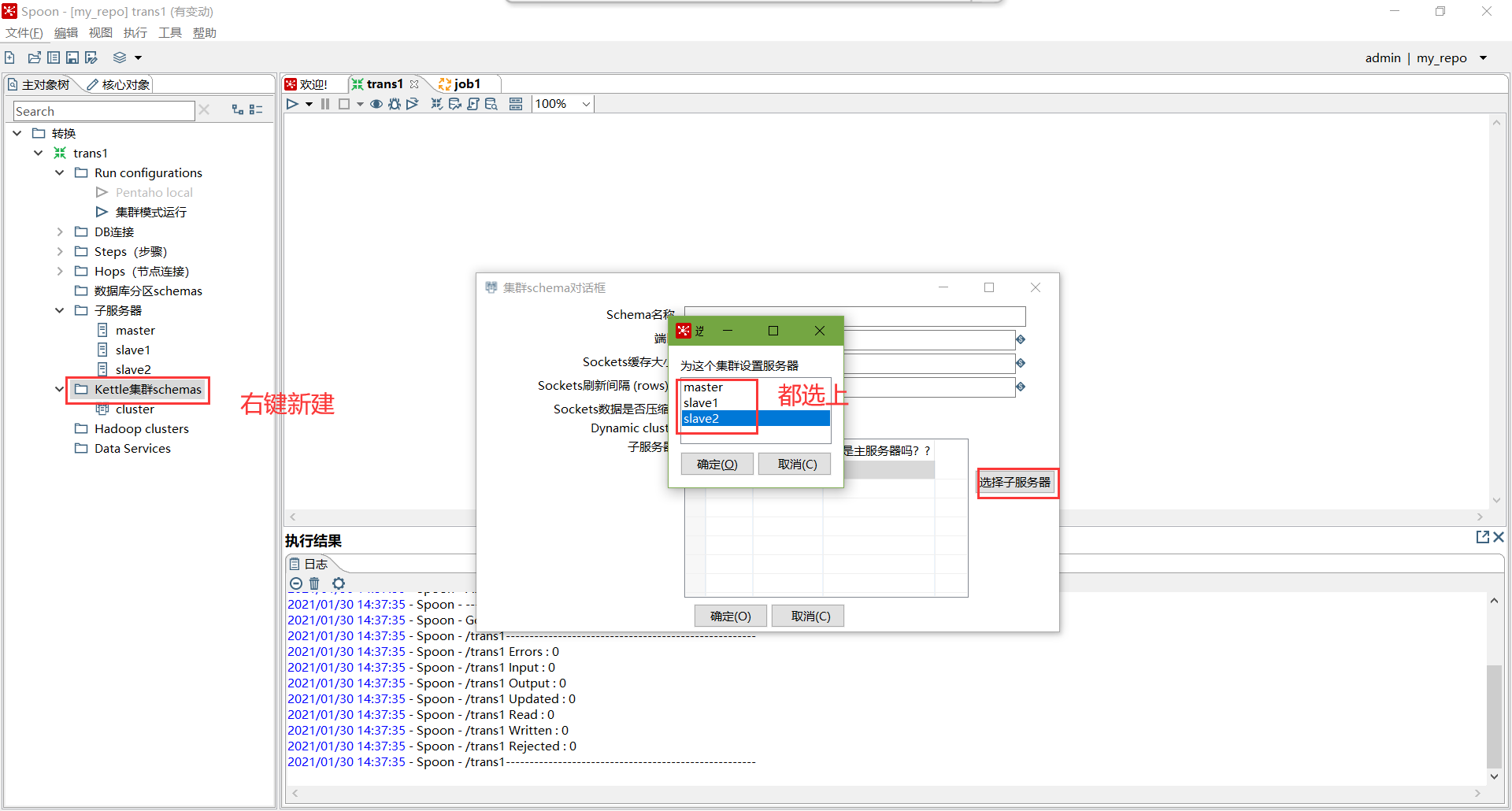
-
對于要在集群上執行的步驟,右鍵選擇集群,選中上一步創建的集群schema
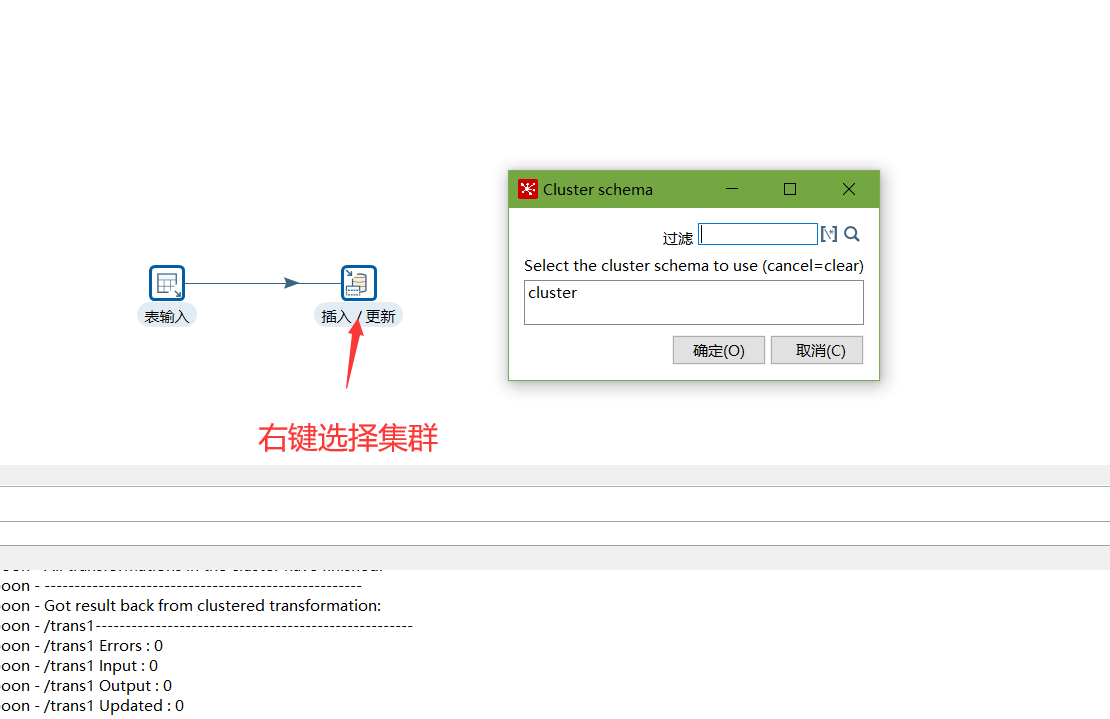
-
創建Run Configuration,選擇集群模式
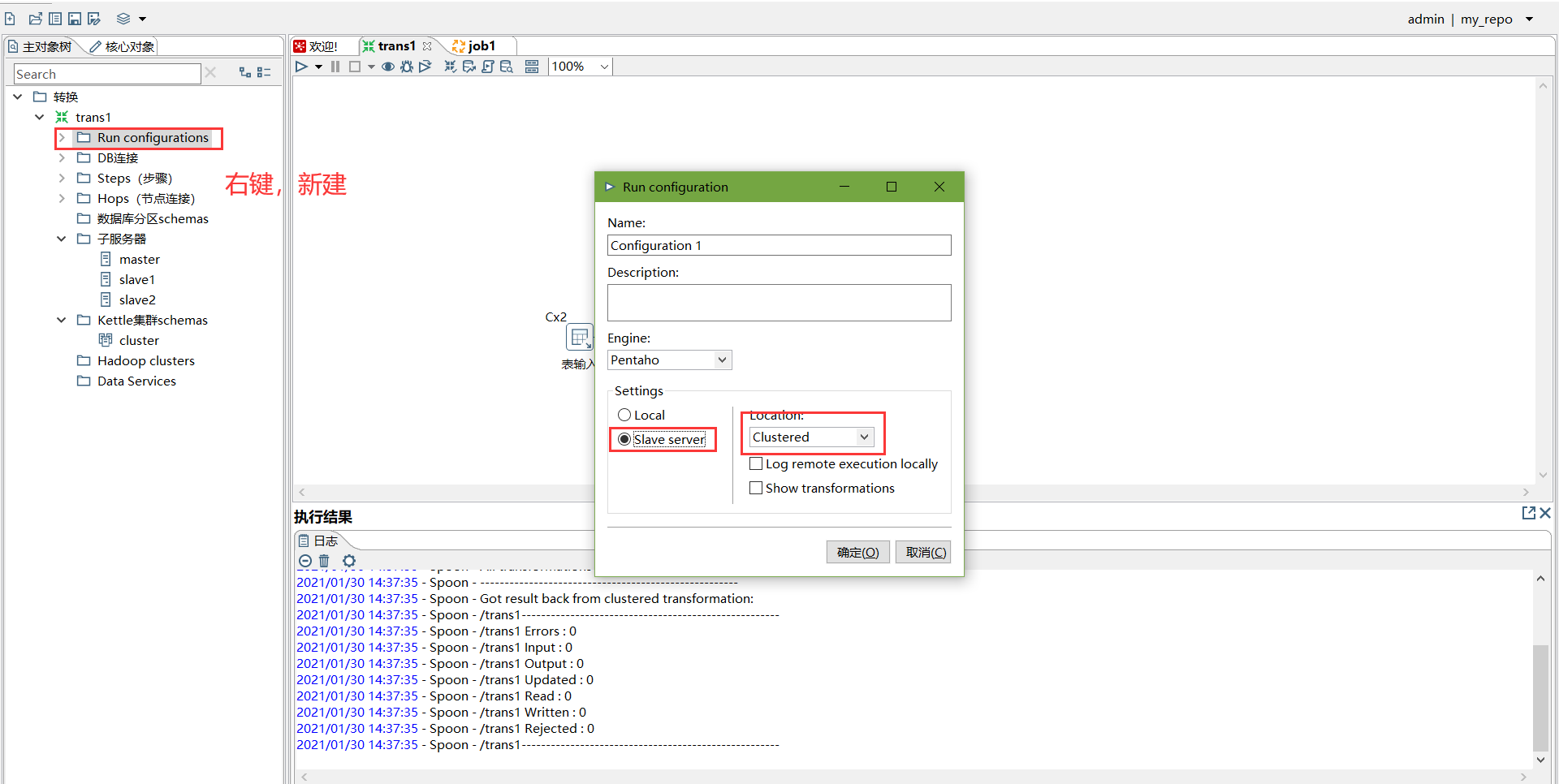
-
直接運行,選擇集群模式運行
五、調優
1、調整JVM大小進行性能優化,修改Kettle根目錄下的Spoon腳本,

引數參考:
-Xmx2048m:設定JVM最大可用記憶體為2048M,
-Xms1024m:設定JVM促使記憶體為1024m,此值可以設定與-Xmx相同,以避免每次垃圾回收完成后JVM重新分配記憶體,
-Xmn2g:設定年輕代大小為2G,整個JVM記憶體大小=年輕代大小 + 年老代大小 + 持久代大小,持久代一般固定大小為64m,所以增大年輕代后,將會減小年老代大小,此值對系統性能影響較大,Sun官方推薦配置為整個堆的3/8,
-Xss128k:設定每個執行緒的堆疊大小,JDK5.0以后每個執行緒堆疊大小為1M,以前每個執行緒堆疊大小為256K,更具應用的執行緒所需記憶體大小進行調整,在相同物理記憶體下,減小這個值能生成更多的執行緒,但是作業系統對一個行程內的執行緒數還是有限制的,不能無限生成,經驗值在3000~5000左右,
2、 調整提交(Commit)記錄數大小進行優化,Kettle默認Commit數量為:1000,可以根據資料量大小來設定Commitsize:1000~50000
3、盡量使用資料庫連接池;
4、盡量提高批處理的commit size;
5、盡量使用快取,快取盡量大一些(主要是文本檔案和資料流);
6、Kettle是Java做的,盡量用大一點的記憶體引數啟動Kettle;
7、可以使用sql來做的一些操作盡量用sql;
Group , merge , stream lookup,split field這些操作都是比較慢的,想辦法避免他們.,能用sql就用sql;
8、插入大量資料的時候盡量把索引刪掉;
9、盡量避免使用update , delete操作,尤其是update,如果可以把update變成先delete, 后insert;
10、能使用truncate table的時候,就不要使用deleteall row這種類似sql合理的磁區,如果洗掉操作是基于某一個磁區的,就不要使用delete row這種方式(不管是deletesql還是delete步驟),直接把磁區drop掉,再重新創建;
11、盡量縮小輸入的資料集的大小(增量更新也是為了這個目的);
12、盡量使用資料庫原生的方式裝載文本檔案(Oracle的sqlloader, mysql的bulk loader步驟),
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/335135.html
標籤:大數據