目錄
- 一、函式的種類
- 二、算術函式
- 2.1 ABS——絕對值
- 2.2 MOD——求余
- 2.3 ROUND——四舍五入
- 三、字串函式
- 3.1 ||——拼接
- 3.2 LENGTH——字串長度
- 3.3 LOWER——小寫轉換
- 3.4 REPLACE——字串的替換
- 3.5 SUBSTRING——字串的截取
- 3.6 UPPER——大寫轉換
- 四、日期函式
- 4.1 CURRENT_DATE——當前日期
- 4.2 CURRENT_TIME ——當前時間
- 4.3 CURRENT_TIMESTAMP——當前日期和時間
- 4.4 EXTRACT——截取日期元素
- 五、轉換函式
- 5.1 CAST——型別轉換
- 5.2 COALESCE——將 NULL 轉換為其他值
- 請參閱
學習重點
根據用途,函式可以大致分為算術函式、字串函式、日期函式、轉換函聚合函式,
函式的種類很多,無需全都記住,只需要記住具有代表性的函式就可以了,其他的可以在使用時再進行查詢,
一、函式的種類
前幾篇和大家一起學習了 SQL 的語法結構等必須要遵守的規則,本文將會進行一點改變,來學習一些 SQL 自帶的便利工具——函式,
我們在 對表進行聚合查詢 中已經學習了函式的概念,這里再回顧一下,所謂函式,就是輸入某一值得到相應輸出結果的功能,輸入值稱為引數(parameter),輸出值稱為回傳值,
KEYWORD
函式
引數(parameter)
回傳值
函式大致可以分為以下幾種,
-
算術函式(用來進行數值計算的函式)
-
字串函式(用來進行字串操作的函式)
-
日期函式(用來進行日期操作的函式)
-
轉換函式(用來轉換資料型別和值的函式)
-
聚合函式(用來進行資料聚合的函式)
KEYWORD
算術函式
字串函式
日期函式
轉換函式
聚合函式
我們已經在 對表進行聚合查詢 中學習了聚合函式的相關內容,大家應該對函式有初步的了解了吧,聚合函式基本上只包含 COUNT、SUM、AVG、MAX、MIN 這 5 種,而其他種類的函式總數則超過 200 種,可能大家會覺得怎么會有那么多函式啊,但其實并不需要擔心,雖然數量眾多,但常用函式只有 30 ~ 50 個,不熟悉的函式大家可以查閱參考檔案(詞典)來了解 [1],
本節我們將學習一些具有代表性的函式,大家并不需要一次全部記住,只需要知道有這樣的函式就可以了,實際應用時可以查閱參考檔案,
接下來,讓我們來詳細地看一看這些函式,
二、算術函式
算術函式是最基本的函式,其實之前我們已經學習過了,可能有些讀者已經想起來了,沒錯,就是 算術運算子和比較運算子 介紹的加減乘除四則運算,
KEYWORD
- 算術函式
-
+(加法) -
-(減法) -
*(乘法) -
/(除法)
KEYWORD
+運算子
-運算子
*運算子
/運算子
由于這些算術運算子具有“根據輸入值回傳相應輸出結果”的功能,因此它們是出色的算術函式,在此我們將會給大家介紹除此之外的具有代表性的函式,
為了學習算術函式,我們首先根據代碼清單 1 創建一張示例用表(SampleMath),
NUMERIC 是大多數 DBMS 都支持的一種資料型別,通過 NUMBERIC ( 全體位數, 小數位數 ) 的形式來指定數值的大小,接下來,將會給大家介紹常用的算術函式——ROUND 函式,由于 PostgreSQL 中的 ROUND 函式只能使用 NUMERIC 型別的資料,因此我們在示例中也使用了該資料型別,
代碼清單 1 創建 SampleMath 表
-- DDL :創建表
CREATE TABLE SampleMath
(m NUMERIC (10,3),
n INTEGER,
p INTEGER);
SQL Server PostgreSQL
-- DML :插入資料
BEGIN TRANSACTION; -----①
INSERT INTO SampleMath(m, n, p) VALUES (500, 0, NULL);
INSERT INTO SampleMath(m, n, p) VALUES (-180, 0, NULL);
INSERT INTO SampleMath(m, n, p) VALUES (NULL, NULL, NULL);
INSERT INTO SampleMath(m, n, p) VALUES (NULL, 7, 3);
INSERT INTO SampleMath(m, n, p) VALUES (NULL, 5, 2);
INSERT INTO SampleMath(m, n, p) VALUES (NULL, 4, NULL);
INSERT INTO SampleMath(m, n, p) VALUES (8, NULL, 3);
INSERT INTO SampleMath(m, n, p) VALUES (2.27, 1, NULL);
INSERT INTO SampleMath(m, n, p) VALUES (5.555,2, NULL);
INSERT INTO SampleMath(m, n, p) VALUES (NULL, 1, NULL);
INSERT INTO SampleMath(m, n, p) VALUES (8.76, NULL, NULL);
COMMIT;
特定的 SQL
不同的 DBMS 事務處理的語法也不盡相同,代碼清單 1 中的 DML 陳述句在 MySQL 中執行時,需要將 ① 部分更改為“
STARTTRANSACTION;”,在 Oracle 和 DB2 中執行時,無需用到 ① 的部分(請洗掉),詳細內容請大家參考 事務 中的“創建事務”,
下面讓我們來確認一下創建好的表中的內容,其中應該包含了 m、n、p 三列,
SELECT * FROM SampleMath;
執行結果
m | n | p
---------+---+--
500.000 | 0 |
-180.000 | 0 |
| |
| 7 | 3
| 5 | 2
| 4 |
8.000 | | 3
2.270 | 1 |
5.555 | 2 |
| 1 |
8.760 | |
2.1 ABS——絕對值
語法 1 ABS 函式
ABS(數值)
ABS 是計算絕對值的函式,絕對值(absolute value)不考慮數值的符號,表示一個數到原點的距離,簡單來講,絕對值的計算方法就是:0 和正數的絕對值就是其本身,負數的絕對值就是去掉符號后的結果,
KEYWORD
ABS函式絕對值
代碼清單 2 計算數值的絕對值
SELECT m,
ABS(m) AS abs_col
FROM SampleMath;
執行結果
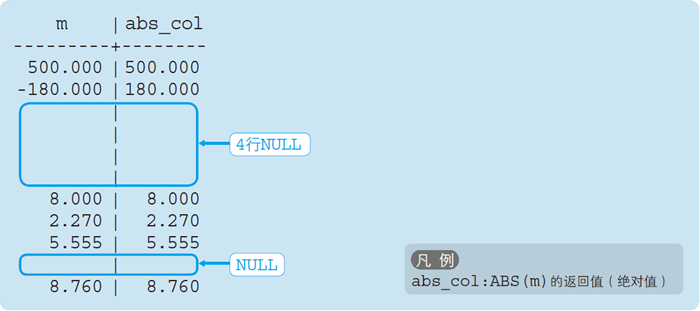
右側的 abs_col 列就是通過 ABS 函式計算出的 m 列的絕對值,請大家注意,-180 的絕對值就是去掉符號后的結果 180,
通過上述結果我們可以發現,ABS 函式的引數為 NULL 時,結果也是 NULL,并非只有 ABS 函式如此,其實絕大多數函式對于 NULL 都回傳 NULL [2],
2.2 MOD——求余
語法 2 MOD 函式
MOD(被除數,除數)
MOD 是計算除法余數(求余)的函式,是 modulo 的縮寫,例如,7/3 的余數是 1,因此 MOD(7, 3) 的結果也是 1(代碼清單 3),因為小數計算中并沒有余數的概念,所以只能對整數型別的列使用 MOD 函式,
KEYWORD
MOD函式
代碼清單 3 計算除法 (n ÷ p) 的余數
Oracle DB2 PostgreSQL MySQL
SELECT n, p,
MOD(n, p) AS mod_col
FROM SampleMath;
執行結果
n | p | mod_col
---+---+--------
0 | |
0 | |
| |
7 | 3 | 1
5 | 2 | 1
4 | |
| 3 |
1 | |
2 | |
1 | |
| |
凡例
mod_col:MOD(n,p)的回傳值(n÷p的余數)
這里有一點需要大家注意:主流的 DBMS 都支持 MOD 函式,只有 SQL Server 不支持該函式,
特定的 SQL
SQL Server 使用特殊的運算子(函式)“
%”來計算余數,使用如下的專用語法可以得到與代碼清單 3 相同的結果,需要使用 SQL Server 的讀者需要特別注意,KEYWORD
%運算子(SQL Server)SQL Server
SELECT n, p, n % p AS mod_col FROM SampleMath;
2.3 ROUND——四舍五入
語法 3 ROUND 函式
ROUND(物件數值,保留小數的位數)
ROUND 函式用來進行四舍五入操作,四舍五入在英語中稱為 round,如果指定四舍五入的位數為 1,那么就會對小數點第 2 位進行四舍五入處理,如果指定位數為 2,那么就會對第 3 位進行四舍五入處理(代碼清單 4),
KEYWORD
ROUND函式
代碼清單 4 對 m 列的數值進行 n 列位數的四舍五入處理
SELECT m, n,
ROUND(m, n) AS round_col
FROM SampleMath;
執行結果
m | n | round_col
---------+---+----------
500.000 | 0 | 500
-180.000 | 0 | -180
| |
| 7 |
| 5 |
| 4 |
8.000 | |
2.270 | 1 | 2.3
5.555 | 2 | 5.56
| 1 |
8.760 | |
凡例
m:物件數值
n:四舍五入位數
round_col:ROUND(m,n)的回傳值(四舍五入的結果)
三、字串函式
截至目前,我們介紹的函式都是主要針對數值的算術函式,但其實算術函式只是 SQL(其他編程語言通常也是如此)自帶的函式中的一部分,雖然算術函式是我們經常使用的函式,但是字串函式也同樣經常被使用,
KEYWORD
- 字串函式
在日常生活中,我們經常會像使用數字那樣,對字串進行替換、截取、簡化等操作,因此 SQL 也為我們提供了很多操作字串的功能,
為了學習字串函式,我們再來創建一張表(SampleStr),參見代碼清單 5,
代碼清單 5 創建 SampleStr 表
-- DDL :創建表
CREATE TABLE SampleStr
(str1 VARCHAR(40),
str2 VARCHAR(40),
str3 VARCHAR(40);)
SQL Server PostgreSQL
-- DML :插入資料
BEGIN TRANSACTION; -------------①
INSERT INTO SampleStr (str1, str2, str3) VALUES ('opx' ,'rt',NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES ('abc' ,'def' ,NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES ('山田' ,'太郎' ,'是我');
INSERT INTO SampleStr (str1, str2, str3) VALUES ('aaa' ,NULL ,NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES (NULL ,'xyz',NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES ('@!#$%' ,NULL ,NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES ('ABC' ,NULL ,NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES ('aBC' ,NULL ,NULL);
INSERT INTO SampleStr (str1, str2, str3) VALUES ('abc太郎' ,'abc' ,'ABC');
INSERT INTO SampleStr (str1, str2, str3) VALUES ('abcdefabc' ,'abc' ,'ABC');
INSERT INTO SampleStr (str1, str2, str3) VALUES ('micmic' ,'i' ,'I');
COMMIT;
特定的 SQL
不同的 DBMS 事務處理的語法也不盡相同,代碼清單 5 中的 DML 陳述句在 MySQL 中執行時,需要將①部分更改為“
START TRANSACTION;”,在 Oracle 和 DB2 中執行時,無需用到 ① 的部分(請洗掉),詳細內容請大家參考 事務 節中的“創建事務”,
下面讓我們來確認一下創建好的表中的內容,其中應該包含了 str1、str2、str3 三列,
SELECT * FROM SampleStr;
執行結果
str1 | str2 | str3
-----------+------+-----
opx | rt |
abc | def |
山田 | 太郎 | 是我
aaa | |
| xyz |
@!#$% | |
ABC | |
aBC | |
abc太郎 | abc | ABC
abcdefabc | abc | ABC
micmic | i | I
3.1 ||——拼接
語法 4 || 函式
字串1||字串2
在實際業務中,我們經常會碰到 abc + de = abcde 這樣希望將字串進行拼接的情況,在 SQL 中,可以通過由兩條并列的豎線變換而成的“||”函式來實作(代碼清單 6),
KEYWORD
||函式
代碼清單 6 拼接兩個字串(str1+str2)
Oracle DB2 PostgreSQL
SELECT str1, str2,
str1 || str2 AS str_concat
FROM SampleStr;
執行結果
str1 | str2 | str_concat
-----------+------+------------
opx | rt | opxrt
abc | def | abcdef
山田 | 太郎 | 山田太郎
aaa | |
| xyz |
@!#$% | |
ABC | |
aBC | |
abc太郎 | abc | abc太郎abc
abcdefabc | abc | abcdefabcabc
micmic | i | micmaci
凡例
str_concat:str1 || str2的回傳值(拼接結果)
進行字串拼接時,如果其中包含 NULL,那么得到的結果也是 NULL,這是因為“||”也是變了形的函式,當然,三個以上的字串也可以進行拼接(代碼清單 7),
代碼清單 7 拼接三個字串(str1+str2+str3)
Oracle DB2 PostgreSQL
SELECT str1, str2, str3,
str1 || str2 || str3 AS str_concat
FROM SampleStr
WHERE str1 = '山田';
執行結果
str1 | str2 | str3 | str_concat
------+------+------+-----------
山田 | 太郎 | 是我 | 山田太郎是我
凡例
str_concat:str1 || str2 || str3的回傳值(拼接結果)
這里也有一點需要大家注意,|| 函式在 SQL Server 和 MySQL 中無法使用,
特定的 SQL
SQL Server 使用“
+”運算子(函式)來連接字串 [3],MySQL 使用CONCAT函式來完成字串的拼接,使用如下 SQL Server/MySQL 的專用語法能夠得到與代碼清單 7 相同的結果,另外,在 SQL Server 2012 及其之后的版本中也可以使用CONCAT函式,KEYWORD
+運算子(SQL Server)
CONCAT函式(MySQL)SQL Server
SELECT str1, str2, str3, str1 + str2 + str3 AS str_concat FROM SampleStr;MySQL SQL Server 2012 及之后
SELECT str1, str2, str3, CONCAT(str1, str2, str3) AS str_concat FROM SampleStr;
3.2 LENGTH——字串長度
語法 5 LENGTH 函式
LENGTH(字串)
想要知道字串中包含多少個字符時,可以使用 LENGTH(長度)函式(代碼清單 8),
KEYWORD
LENGTH函式
代碼清單 8 計算字串長度
Oracle DB2 PostgreSQL MySQL
SELECT str1,
LENGTH(str1) AS len_str
FROM SampleStr;
執行結果
str1 | len_str
-----------+--------
opx | 3
abc | 3
山田 | 2
aaa | 3
|
@!#$% | 5
ABC | 3
aBC | 3
abc太郎 | 5
abcdefabc | 9
micmic | 6
凡例
len_str:LENGTH(str1)的回傳值(str1的字符長度)
需要注意的是,該函式也無法在 SQL Server 中使用,
特定的 SQL
SQL Server 使用
LEN函式來計算字串的長度,使用如下 SQL Server 的專用語法能夠得到與代碼清單 8 相同的結果,KEYWORD
LEN函式(SQL Server)SQL Server
SELECT str1, LEN(str1) AS len_str FROM SampleStr;
我想大家應該逐漸明白“SQL 中有很多特定的用法”這句話的含義了吧,
專欄
對 1 個字符使用
LENGTH函式有可能得到 2 位元組以上的結果
LENGTH函式中,還有一點需要大家特別注意,那就是該函式究竟以什么為單位來計算字串的長度,這部分是初級以上階段才會學習到的內容,在此先簡單介紹一下,可能有些讀者已經有所了解,與半角英文字母占用 1 位元組不同,漢字這樣的全角字符會占用 2 個以上的位元組(稱為多位元組字符),因此,使用 MySQL 中的
LENGTH這樣以位元組為單位的函式進行計算時,“LENGTH(山田)”的回傳結果是 4,同樣是LENGTH函式,不同 DBMS 的執行結果也不盡相同 [4],KEYWORD
位元組
多位元組字符
位元組(byte)是計算機中用來表述資料大小的基本單位,通常情況下“1 字符 = 1 位元組”,單位位元組(KB)是位元組的 1024 倍,單位兆位元組(MB)是千位元組的 1024 倍,單位千兆字 節(GB)是兆 位元組 的 1024 倍,表示硬碟容量時經常會使用的“100 GB”“250 GB”,其中 100 GB 指的是可以存盤 1024× 1024× 1024×100=107,374,182,400 個半角英文字母,
LENGTH函式(MySQL)
CHAR_LENGTH函式(MySQL)雖然有些混亂,但這正是我希望大家能夠牢記的,
3.3 LOWER——小寫轉換
語法 6 LOWER 函式
LOWER(字串)
LOWER 函式只能針對英文字母使用,它會將引數中的字串全都轉換為小寫(代碼清單 9),因此,該函式并不適用于英文字母以外的場合,此外,該函式并不影響原本就是小寫的字符,
KEYWORD
LOWER函式
代碼清單 9 大寫轉換為小寫
SELECT str1,
LOWER(str1) AS low_str
FROM SampleStr
WHERE str1 IN ('ABC', 'aBC', 'abc', '山田');
執行結果
str1 | low_str
------+--------
abc | abc
山田 | 山田
ABC | abc
aBC | abc
凡例
low_str:LOWER(str1)的回傳值
既然存在小寫轉換函式,那么肯定也有大寫轉換函式,UPPER 就是大寫轉換函式,
3.4 REPLACE——字串的替換
語法 7 REPLACE 函式
REPLACE(物件字串,替換前的字串,替換后的字串)
使用 REPLACE 函式,可以將字串的一部分替換為其他的字串(代碼清單 10),
KEYWORD
REPLACE函式
代碼清單 10 替換字串的一部分
SELECT str1, str2, str3,
REPLACE(str1, str2, str3) AS rep_str
FROM SampleStr;
執行結果
str1 | str2 | str3 | rep_str
-----------+------+------+---------
opx | rt | |
abc | def | |
山田 | 太郎 | 是我 | 山田
aaa | | |
| xyz | |
@!#$% | | |
ABC | | |
aBC | | |
abc太郎 | abc | ABC | ABC太郎
abcdefabc | abc | ABC | ABCdefABC
micmic | i | I | mIcmIc
凡例
str1:物件字串
str2:替換前的字串
str3:替換后的字串
rep_str:REPLACE(str1,str2,str3)的回傳值(替換結果)
3.5 SUBSTRING——字串的截取
語法 8 SUBSTRING 函式(PostgreSQL/MySQL 專用語法)
SUBSTRING(物件字串 FROM 截取的起始位置 FOR 截取的字符數)
使用 SUBSTRING 函式可以截取出字串中的一部分字串(代碼清單 11),截取的起始位置從字串最左側開始計算 [5],
KEYWORD
SUBSTRING函式
代碼清單 11 截取出字串中第 3 位和第 4 位的字符
PostgreSQL MySQL
SELECT str1,
SUBSTRING(str1 FROM 3 FOR 2) AS sub_str
FROM SampleStr;
執行結果
str1 | sub_str
-----------+--------
opx | x
abc | c
山田 |
aaa | a
|
@!#$% | #$
ABC | C
aBC | C
abc太郎 | c太
abcdefabc | cd
micmic | cm
凡例
sub_str:SUBSTRING(str1 FROM 3 FOR 2)的回傳值
雖然上述 SUBSTRING 函式的語法是標準 SQL 承認的正式語法,但是現在只有 PostgreSQL 和 MySQL 支持該語法,
特定的 SQL
SQL Server 將語法 8a 中的內容進行了簡化(語法 8b),
語法 8a
SUBSTRING函式(SQL Server 專用語法)SUBSTRING(物件字串,截取的起始位置,截取的字符數)Oracle 和 DB2 將該語法進一步簡化,得到了如下結果,
語法 8b
SUBSTR函式(Oracle/DB2 專用語法)SUBSTR(物件字串,截取的起始位置,截取的字符數)SQL 有這么多特定的語法,真是有些讓人頭疼啊,各 DBMS 中能夠得到與代碼清單 11 相同結果的專用語法如下所示,
SQL Server
SELECT str1, SUBSTRING(str1, 3, 2) AS sub_str FROM SampleStr;Oracle DB2
SELECT str1, SUBSTR(str1, 3, 2) AS sub_str FROM SampleStr;
3.6 UPPER——大寫轉換
語法 9 UPPER 函式
UPPER(字串)
UPPER 函式只能針對英文字母使用,它會將引數中的字串全都轉換為大寫(代碼清單 12),因此,該函式并不適用于英文字母以外的情況,此外,該函式并不影響原本就是大寫的字符,
KEYWORD
UPPER函式
代碼清單 12 將小寫轉換為大寫
SELECT str1,
UPPER(str1) AS up_str
FROM SampleStr
WHERE str1 IN ('ABC', 'aBC', 'abc', '山田');
執行結果
str1 | up_str
------+--------
abc | ABC
山田 | 山田
ABC | ABC
aBC | ABC
凡例
up_str:UPPER(str1)的回傳值
與之相對,進行小寫轉換的是 LOWER 函式,
四、日期函式
雖然 SQL 中有很多日期函式,但是其中大部分都依存于各自的 DBMS,因此無法統一說明 [6],本節將會介紹那些被標準 SQL 承認的可以應用于絕大多數 DBMS 的函式,
KEYWORD
- 日期函式
4.1 CURRENT_DATE——當前日期
語法 10 CURRENT_DATE 函式
CURRENT_DATE
CURRENT_DATE 函式能夠回傳 SQL 執行的日期,也就是該函式執行時的日期,由于沒有引數,因此無需使用括號,
KEYWORD
CURRENT_DATE函式
執行日期不同,CURRENT_DATE 函式的回傳值也不同,如果在 2009 年 12 月 13 日執行該函式,會得到回傳值“2009-12-13”,如果在 2010 年 1 月 1 日執行,就會得到回傳值“2010-01-01”(代碼清單 13),
代碼清單 13 獲得當前日期
SELECT CURRENT_DATE;
執行結果
date
------------
2016-05-20
該函式無法在 SQL Server 中執行,此外,Oracle 和 DB2 中的語法略有不同,
特定的 SQL
SQL Server 使用如下的
CURRENT_TIMESTAMP(后述)函式來獲得當前日期,SQL Server
-- 使用CAST(后述)函式將CURRENT_TIMESTAMP轉換為日期型別 SELECT CAST(CURRENT_TIMESTAMP AS DATE) AS CUR_DATE;執行結果
CUR_DATE ---------- 2010-05-25在 Oracle 中使用該函式時,需要在
FROM子句中指定臨時表(DUAL),而在 DB2 中使用時,需要在CRUUENT和DATE之間添加半角空格,并且還需要指定臨時表SYSIBM.SYSDUMMY1(相當于 Oracle 中的DUAL),這些容易混淆的地方請大家多加注意,Oracle
SELECT CURRENT_DATE FROM dual;DB2
SELECT CURRENT DATE FROM SYSIBM.SYSDUMMY1;
4.2 CURRENT_TIME ——當前時間
語法 11 CURRENT_TIME** 函式**
CURRENT_TIME
CURRENT_TIME 函式能夠取得 SQL 執行的時間,也就是該函式執行時的時間(代碼清單 14),由于該函式也沒有引數,因此同樣無需使用括號,
KEYWORD
CURRENT_TIME函式
代碼清單 14 取得當前時間
PostgreSQL MySQL
SELECT CURRENT_TIME;
執行結果
timetz
-----------------
17:26:50.995+09
該函式同樣無法在 SQL Server 中執行,在 Oracle 和 DB2 中的語法同樣略有不同,
特定的 SQL
SQL Server 使用如下的
CURRENT_TIMESTAMP函式(后述)來獲得當前日期,-- 使用CAST函式(后述)將CURRENT_TIMESTAMP轉換為時間型別 SELECT CAST(CURRENT_TIMESTAMP AS TIME) AS CUR_TIME;執行結果
CUR_TIME ---------------- 21:33:59.3400000在 Oracle 和 DB2 中使用時的語法如下所示,需要注意的地方和
CURRENT_DATE函式相同,在 Oracle 中使用時所得到的結果還包含日期,Oracle
-- 指定臨時表(DUAL) SELECT CURRENT_TIMESTAMP FROM dual;DB2
/* CURRENT和TIME之間使用了半角空格,指定臨時表SYSIBM.SYSDUMMY1 */ SELECT CURRENT TIME FROM SYSIBM.SYSDUMMY1;
4.3 CURRENT_TIMESTAMP——當前日期和時間
語法 12 CURRENT_TIMESTAMP函式
CURRENT_TIMESTAMP
CURRENT_TIMESTAMP 函式具有 CURRENT_DATE + CURRENT_TIME 的功能,使用該函式可以同時得到當前的日期和時間,當然也可以從結果中截取日期或者時間,
KEYWORD
CURRENT_TIMESTAMP函式
代碼清單 15 取得當前日期和時間
SQL Server PostgreSQL MySQL
SELECT CURRENT_TIMESTAMP;
執行結果
now
---------------------------
2016-04-25 18:31:03.704+09
該函式可以在 SQL Server 等各個主要的 DBMS 中使用 [7],但是,與之前的 CURRENT_DATE 和 CURRENT_TIME 一樣,在 Oracle 和 DB2 中該函式的語法略有不同,
特定的 SQL
Oracle 和 DB2 使用如下寫法可以得到與代碼清單 15 相同的結果,其中需要注意的地方與
CURRENT_DATE時完全相同,Oracle
-- 指定臨時表(DUAL) SELECT CURRENT_TIMESTAMP FROM dual;DB2
/* CURRENT和TIME之間使用了半角空格,指定臨時表SYSIBM.SYSDUMMY1 */ SELECT CURRENT TIMESTAMP FROM SYSIBM.SYSDUMMY1;
4.4 EXTRACT——截取日期元素
語法 13 EXTRACT 函式
EXTRACT(日期元素 FROM 日期)
使用 EXTRACT 函式可以截取出日期資料中的一部分,例如“年”“月”,或者“小時”“秒”等(代碼清單 16),該函式的回傳值并不是日期型別而是數值型別,
KEYWORD
EXTRACT函式
代碼清單 16 截取日期元素
PostgreSQL MySQL
SELECT CURRENT_TIMESTAMP,
EXTRACT(YEAR FROM CURRENT_TIMESTAMP) AS year,
EXTRACT(MONTH FROM CURRENT_TIMESTAMP) AS month,
EXTRACT(DAY FROM CURRENT_TIMESTAMP) AS day,
EXTRACT(HOUR FROM CURRENT_TIMESTAMP) AS hour,
EXTRACT(MINUTE FROM CURRENT_TIMESTAMP) AS minute,
EXTRACT(SECOND FROM CURRENT_TIMESTAMP) AS second;
執行結果
now | year | month | day | hour | minute | second
---------------------------+------+-------+-----+------+--------+-------
2010-04-25 19:07:33.987+09 | 2010 | 4 | 25 | 19 | 7 | 33.987
需要注意的是 SQL Server 也無法使用該函式,
特定的 SQL
SQL Server 使用如下的
DATEPART函式會得到與代碼清單 16 相同的結果,KEYWORD
DATEPART函式(SQL Server)SQL Server
SELECT CURRENT_TIMESTAMP, DATEPART(YEAR , CURRENT_TIMESTAMP) AS year, DATEPART(MONTH , CURRENT_TIMESTAMP) AS month, DATEPART(DAY , CURRENT_TIMESTAMP) AS day, DATEPART(HOUR , CURRENT_TIMESTAMP) AS hour, DATEPART(MINUTE , CURRENT_TIMESTAMP) AS minute, DATEPART(SECOND , CURRENT_TIMESTAMP) AS second;Oracle 和 DB2 想要得到相同結果的話,需要進行如下改變,注意事項與
CURRENT_DATE時完全相同,Oracle
-- 在FROM子句中指定臨時表(DUAL) SELECT CURRENT_TIMESTAMP, EXTRACT(YEAR FROM CURRENT_TIMESTAMP) AS year, EXTRACT(MONTH FROM CURRENT_TIMESTAMP) AS month, EXTRACT(DAY FROM CURRENT_TIMESTAMP) AS day, EXTRACT(HOUR FROM CURRENT_TIMESTAMP) AS hour, EXTRACT(MINUTE FROM CURRENT_TIMESTAMP) AS minute, EXTRACT(SECOND FROM CURRENT_TIMESTAMP) AS second FROM DUAL;DB2
/* CURRENT和TIME之間使用了半角空格,指定臨時表SYSIBM.SYSDUMMY1 */ SELECT CURRENT TIMESTAMP, EXTRACT(YEAR FROM CURRENT TIMESTAMP) AS year, EXTRACT(MONTH FROM CURRENT TIMESTAMP) AS month, EXTRACT(DAY FROM CURRENT TIMESTAMP) AS day, EXTRACT(HOUR FROM CURRENT TIMESTAMP) AS hour, EXTRACT(MINUTE FROM CURRENT TIMESTAMP) AS minute, EXTRACT(SECOND FROM CURRENT TIMESTAMP) AS second FROM SYSIBM.SYSDUMMY1;
五、轉換函式
最后將要給大家介紹一類比較特殊的函式——轉換函式,雖說有些特殊,但是由于這些函式的語法和之前介紹的函式類似,數量也比較少,因此很容易記憶,
KEYWORD
- 轉換函式
“轉換”這個詞的含義非常廣泛,在 SQL 中主要有兩層意思:一是資料型別的轉換,簡稱為型別轉換,在英語中稱為 cast [8];另一層意思是值的轉換,
KEYWORD
型別轉換
cast
5.1 CAST——型別轉換
語法 14 CAST 函式
CAST(轉換前的值 AS 想要轉換的資料型別)
進行型別轉換需要使用 CAST 函式,
KEYWORD
CAST函式
之所以需要進行型別轉換,是因為可能會插入與表中資料型別不匹配的資料,或者在進行運算時由于資料型別不一致發生了錯誤,又或者是進行自動型別轉換會造成處理速度低下,這些時候都需要事前進行資料型別轉換(代碼清單 17、代碼清單 18),
代碼清單 17 將字串型別轉換為數值型別
SQL Server PostgreSQL
SELECT CAST('0001' AS INTEGER) AS int_col;
MySQL
SELECT CAST('0001' AS SIGNED INTEGER) AS int_col;
Oracle
SELECT CAST('0001' AS INTEGER) AS int_col
FROM DUAL;
DB2
SELECT CAST('0001' AS INTEGER) AS int_col
FROM SYSIBM.SYSDUMMY1;
執行結果
int_col
---------
1
代碼清單 18 將字串型別轉換為日期型別
SQL Server PostgreSQL MySQL
SELECT CAST('2009-12-14' AS DATE) AS date_col;
Oracle
SELECT CAST('2009-12-14' AS DATE) AS date_col
FROM DUAL;
DB2
SELECT CAST('2009-12-14' AS DATE) AS date_col
FROM SYSIBM.SYSDUMMY1;
執行結果
date_col
------------
2009-12-14
從上述結果可以看到,將字串型別轉換為整數型別時,前面的“000”消失了,能夠切實感到發生了轉換,但是,將字串轉換為日期型別時,從結果上并不能看出資料發生了什么變化,理解起來也比較困難,從這一點我們也可以看出,型別轉換其實并不是為了方便用戶使用而開發的功能,而是為了方便 DBMS 內部處理而開發的功能,
5.2 COALESCE——將 NULL 轉換為其他值
語法 15 COALESCE 函式
COALESCE(資料1,資料2,資料3……)
COALESCE 是 SQL 特有的函式,該函式會回傳可變引數 [9] 中左側開始第 1 個不是 NULL 的值,引數個數是可變的,因此可以根據需要無限增加,
KEYWORD
COALESCE函式
其實轉換函式的使用還是非常頻繁的,在 SQL 陳述句中將 NULL 轉換為其他值時就會用到轉換函式(代碼清單 19、代碼清單 20),就像之前我們學習的那樣,運算或者函式中含有 NULL 時,結果全都會變為 NULL,能夠避免這種結果的函式就是 COALESCE,
代碼清單 19 將 NULL 轉換為其他值
SQL Server PostgreSQL MySQL
SELECT COALESCE(NULL, 1) AS col_1,
COALESCE(NULL, 'test', NULL) AS col_2,
COALESCE(NULL, NULL, '2009-11-01') AS col_3;
Oracle
SELECT COALESCE(NULL, 1) AS col_1,
COALESCE(NULL, 'test', NULL) AS col_2,
COALESCE(NULL, NULL, '2009-11-01') AS col_3
FROM DUAL;
DB2
SELECT COALESCE(NULL, 1) AS col_1,
COALESCE(NULL, 'test', NULL) AS col_2,
COALESCE(NULL, NULL, '2009-11-01') AS col_3
FROM SYSIBM.SYSDUMMY1;
執行結果
col_1 | col_2 | col_3
-------+-------+-----------
1 | test | 2009-11-01
代碼清單 20 使用 SampleStr 表中的列作為例子
SELECT COALESCE(str2, 'NULL')
FROM SampleStr;
執行結果
coalesce
----------
rt
def
太郎
'NULL'
xyz
'NULL'
'NULL'
'NULL'
abc
abc
i
這樣,即使包含 NULL 的列,也可以通過 COALESCE 函式轉換為其他值之后再應用到函式或者運算當中,這樣結果就不再是 NULL 了,
此外,多數 DBMS 中都提供了特有的 COALESCE 的簡化版函式(如 Oracle 中的 NVL 等),但由于這些函式都依存于各自的 DBMS,因此還是推薦大家使用通用的 COALESCE 函式,
請參閱
- 各種各樣的函式
- SQL 謂詞
- CASE 運算式
(完)
參考檔案是 DBMS 手冊的一部分,大家也可以從介紹各種函式的書籍以及 Web 網站上獲取相關資訊, ??
但是轉換函式中的
COALESCE函式除外, ??由于這和 Java 中連接字串的方法相同,估計有些讀者已經比較熟悉了, ??
MySQL 中還存在計算字串長度的自有函式
CHAR_LENGTH, ??需要大家注意的是,該函式也存在和
LENGTH函式同樣的多位元組字符的問題,詳細內容請大家參考專欄“對 1 個字符使用LENGTH函式有可能得到 2 位元組以上的結果”, ??如果想要了解日期函式的詳細內容,目前只能查閱各個 DBMS 的手冊, ??
之前我們已經介紹過,在 SQL Server 中無法使用
CURRENT_DATE和CURRENT_TIME函式,可能是因為在 SQL Server 中,CURRENT_TIMESTAMP已經涵蓋了這兩者的功能吧, ??型別轉換在一般的編程語言中也會使用,因此并不是 SQL 特有的功能, ??
引數的個數并不固定,可以自由設定個數的引數, ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/374442.html
標籤:SQL Server
上一篇:SQL 關聯子查詢
下一篇:SQL 謂詞簡介