我正在嘗試抓取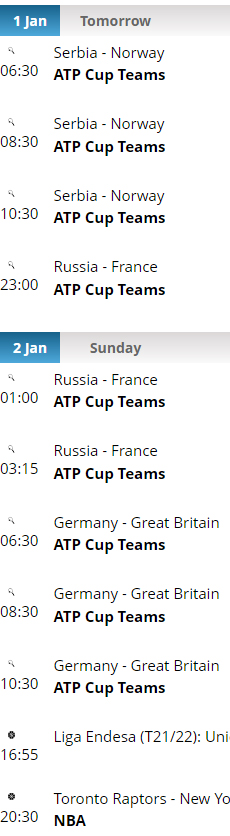
uj5u.com熱心網友回復:
如何實作?
稍微改變收集資料的方法并選擇元素,以便它們出現在日期分隔符下。
步驟1
選擇所有日期分隔符:
soup.select('.dateSeparator')
第2步
迭代它們中的每一個及其所有下一個兄弟姐妹,如果兄弟姐妹是 ,則中斷<div>:
for item in date.find_next_siblings():
if item.name == 'div':
break
第 3 步
提取文本stripped_strings并進行一些調整,因為結構并不總是相同的:
text = tuple(item.stripped_strings)
...
步驟4
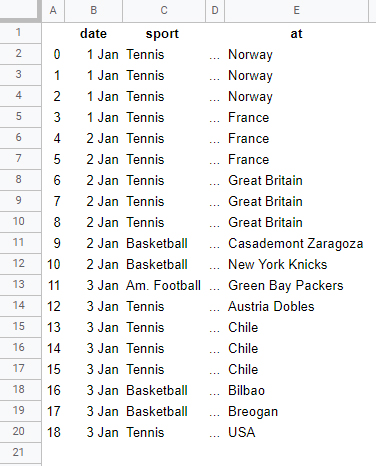
將資訊存盤在字典串列中并創建您的資料框。
pd.DataFrame(data)
例子
注意: 輸出可能與預期的略有不同,因為我在您添加螢屏截圖之前創建了它,并且我看到了德國網站。但是,方向應該是明確的,方法是要調整的。
...
data = []
for date in soup.select('.dateSeparator'):
for item in date.find_next_siblings():
if item.name == 'div':
break
text = tuple(item.stripped_strings)
data.append({
'date':date.span.text.strip(),
'time':text[0],
'sport':text[1],
'at':text[3].split('-')[-1] if len(text) > 4 else text[3].split(':')[-1].split('-')[-1],
'teams':text[3] if len(text) > 4 else text[3].split(':')[-1],
'event':text[4] if len(text) > 4 else text[3].split(':')[0]
})
pd.DataFrame(data)
輸出
| 日期 | 時間 | 運動 | 在 | 團隊 | 事件 |
|---|---|---|---|---|---|
| 1 月 1 日 | 07:30 | 網球 | 挪威 | 塞爾維亞 - 挪威 | ATP杯球隊 |
| ... | ... | ... | ... | ... | ... |
| 1月3日 | 21:30 | 籃球 | 布里奧根 | Obradoiro CAB - Breogan | ACB |
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/400756.html
下一篇:重命名列與替換列屬性之間的區別