我有一個如下所示的資料框
df = pd.DataFrame(
{'sub_code' : ['CSE01', 'CSE01', 'CSE01',
'CSE02', 'CSE03', 'CSE04',
'CSE05', 'CSE06'],
'stud_level' : [101, 101, 101, 101,
101, 101, 101, 101],
'grade' : ['STA','STA','PSA','STA','STA','SSA','PSA','QSA']})
我想做以下
a)獲取資料框所有分類列中每個唯一值的頻率
我嘗試了以下方法,但它既不高效也不優雅
df['sub_code'].value_counts() # need to key in column name manually
df['grade'].value_counts() # need to key in column name manually
df.select_dtypes(include='object').value_counts() #produces incorrect output
由于我的真實資料有 200 多列和 100k 行,有沒有有效的方法來做到這一點?
我希望我的輸出如下所示。如果有任何其他更好的方法來顯示以下輸出,我也歡迎。我不知道如何以簡潔的方式捕獲這些資訊。所以,請分享你的建議
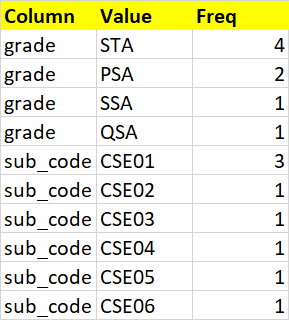
uj5u.com熱心網友回復:
使用melt和value_counts:
out = (df.select_dtypes(object)
.melt(var_name="Column", value_name="Value")
.value_counts(dropna=False)
.reset_index(name="Frequency")
.sort_values(by=['Column','Frequency','Variable'], ascending=[True,False,True])
.reset_index(drop=True))
輸出:
Column Variable Frequency
0 grade STA 4
1 grade PSA 2
2 grade QSA 1
3 grade SSA 1
4 sub_code CSE01 3
5 sub_code CSE02 1
6 sub_code CSE03 1
7 sub_code CSE04 1
8 sub_code CSE05 1
9 sub_code CSE06 1
uj5u.com熱心網友回復:
另一種方法是使用,get_dummies
s=pd.get_dummies(df.drop(columns=['stud_level'])).sum(0).to_frame('Freq').reset_index()
s=s['index'].str.split('\_(?=[A-Z0-9] $)', expand=True).join(s.iloc[:,-1]).rename(columns={0:'Column',1:'Value'})
結果
Column Value Freq
0 sub_code CSE01 3
1 sub_code CSE02 1
2 sub_code CSE03 1
3 sub_code CSE04 1
4 sub_code CSE05 1
5 sub_code CSE06 1
6 grade PSA 2
7 grade QSA 1
8 grade SSA 1
9 grade STA 4
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/418594.html
標籤:
下一篇:熊貓資料框Json展平所有行