我有這個資料框:
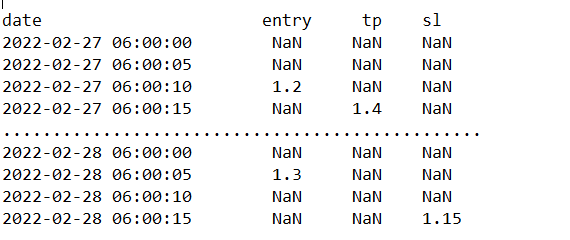
我需要根據條件進行一些上癮和減法。
如果我們首先在 tp 中有一個非 NaN 值,那么這樣做: tp-entry
相反,如果第一個非 NaN 值包含在“sl”列中,則執行此 sl 條目。
我們將這些值存盤在一個名為“pl”的新列中,因此最終的資料幀將如下所示:

我試過(沒有成功)這個(可重現的代碼):
tbl = {"date" :["2022-02-27", "2022-02-27", "2022-02-27", "2022-02-27", "2022-02-28",
"2022-02-28","2022-02-28", "2022-02-28"],
"entry" : ["NaN", "NaN", 1.2, "NaN", "NaN", 1.3, "NaN", "NaN"],
"tp" : ["NaN", "NaN", "NaN", 1.4, "NaN", "NaN", "NaN", "NaN"],
"sl" : ["NaN", "NaN", "NaN", "NaN", "NaN", "NaN", "NaN", 1.15]}
df = pd.DataFrame(tbl)
df.sort_values(by = "date", inplace=True)
df['pl'] = np.where(df["entry"]) #i don't know how to continue...
有任何想法嗎?你知道更好的方法嗎?
編輯
在照片中輸入-sl 是錯誤的,我需要 sl-entry
uj5u.com熱心網友回復:
IIUC,您可以組合“tp”和“pl”,然后bfill按組。bfill每組也是“條目”。然后僅在每個日期的第一行(即非重復)上分配差異:
group = df['date']
s1 = df['tp'].fillna(df['sl']).groupby(group).bfill()
s2 = df['entry'].groupby(group).bfill()
df.loc[~group.duplicated(), 'pl'] = s1-s2
注意。如果您確實有時間日期,請改用組:
group = pd.to_datetime(df['date']).dt.date
輸出:
date entry tp sl pl
0 2022-02-27 NaN NaN NaN 0.20
1 2022-02-27 NaN NaN NaN NaN
2 2022-02-27 1.2 NaN NaN NaN
3 2022-02-27 NaN 1.4 NaN NaN
4 2022-02-28 NaN NaN NaN -0.15
5 2022-02-28 1.3 NaN NaN NaN
6 2022-02-28 NaN NaN NaN NaN
7 2022-02-28 NaN NaN 1.15 NaN
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/435575.html