位元組跳動資料湖團隊在實時數倉構建寬表的業務場景中,探索實踐出的一種基于 Hudi Payload 的合并機制提出的全新解決方案,
位元組跳動資料湖團隊在實時數倉構建寬表的業務場景中,探索實踐出的一種基于 Hudi Payload 的合并機制提出的全新解決方案,
該方案在存盤層提供對多流資料的關聯能力,旨在解決實時場景下多流 JOIN 遇到的一系列問題,接下來,本文會詳細介紹多流拼接方案的背景以及實踐經驗,
業務面臨的挑戰
位元組跳動存在較多業務場景需要基于具有相同主鍵的多個資料源實時構建一個大寬表,資料源一般包括 Kafka 中的指標資料,以及 KV 資料庫中的維度資料,
業務側通常會基于實時計算引擎在流上做多個資料源的 JOIN 產出這個寬表,但這種解決方案在實踐中面臨較多挑戰,主要可分為以下兩種情況:
- 維表 JOIN
-
場景挑戰:指標資料與維度資料進行關聯,其中維度資料量比較大,指標資料 QPS 比較高,導致資料可能會產出延遲,
-
當前方案:將部分維度資料快取起起來,緩解高 QPS 下訪問維度資料存盤引擎產生的任務背壓問題,
-
存在問題:由于業務方的維度資料和指標資料時間差比較大,所以指標資料流無法設定合理的 TTL;而且存在 Cache 中維度資料沒有及時更新,導致下游資料不準確的問題,
- 多流 JOIN
- 場景挑戰:多個指標資料進行關聯,不同指標資料可能會出現時間差比較大的例外情況,
- 當前方案:使用基于視窗的 JOIN,并且維持一個比較大的狀態,
- 存在問題:維持大的狀態不僅會給記憶體帶來的一定的壓力,同時 Checkpoint 和 Restore 的時間會變 得更長,可能會導致任務背壓.
分析與對策
總結上述場景遇到的挑戰,主要可歸結為以下兩點:
- 由于多流之間時間差比較大,需要維持大狀態,同時 TTL 不好設定,
- 由于對維度資料做了 Cache,維度資料資料更新不及時,導致下游資料不準確,
針對這些問題,并結合業務場景對資料延遲有一定容忍,但對資料準確性要求比較高的背景,我們在不斷的實踐中探索出了基于 Hudi Payload 機制的多流拼接方案:
- 多流資料完全在存盤層進行拼接,與計算引擎無關,因此不需要保留狀態及其 TTL 的設定,
- 維度資料和指標資料作為不同的流獨立更新,更新程序中不需要做多流資料合并,下游讀取時再 Merge 多流資料,因此不需要快取維度資料,同時可以在執行 Compact 時進行 Merge,加速下游查詢,
此外,多流拼接方案還支持:
- 內置通用模板,支持資料去重等通用介面,同時可滿足用戶定制化資料處理需求,
- 支持離線場景和流批混合場景,
方案介紹
基本概念
首先簡單介紹下本方案依賴 Hudi 的一些核心概念:
- Hudi MetaStore
這是一個中心化的資料湖元資料管理系統,它基于 Timeline 樂觀鎖實作并發寫控制,可以支持列級別的沖突檢查,這在 Hudi 多流拼接方案中能夠實作并發寫入至關重要,更多細節可參考位元組跳動資料湖團隊向社區貢獻的 RFC-36,
- MergeOnRead 表讀寫邏輯
MergeOnRead 表里面的檔案包含兩種, LogFile (行存) 和 BaseFile (列存),適用于實時高頻更新場景,更新資料會直接寫入 LogFile 中,讀時再進行合并,為了減少讀放大的問題,會定期合并 LogFile 到 BaseFile 中,此程序叫 Compact,
原理概述
針對上述業務場景,我們設計了一種完全基于存盤層的多流拼接方案,支持多個資料流并發寫入,讀時按照主鍵合并多流資料,此外還支持異步 Compact 來加速下游讀取資料,
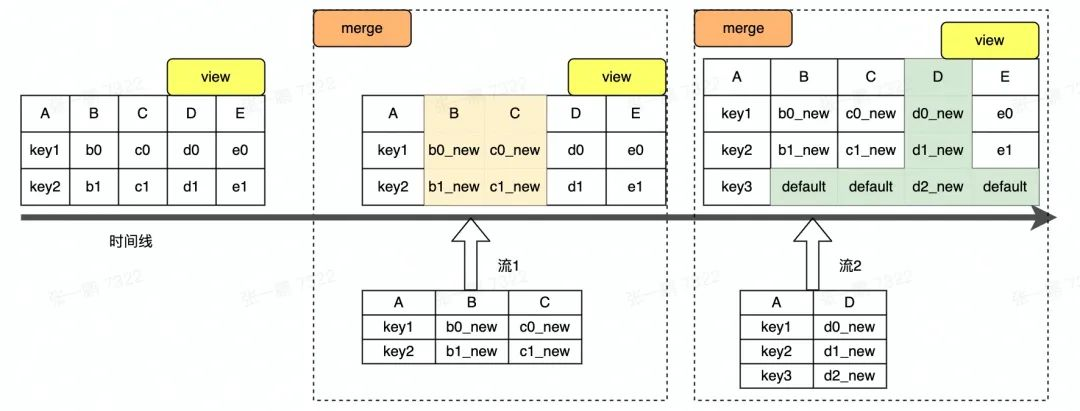
圖 1 Hudi 多流拼接概念圖(本文所有圖中示例資料均與圖 1 一致)
現以一個簡單的示例流程對方案原理進行闡述,圖 1 為多流拼接示意圖,圖中的寬表包含 BCDE 五列,是由兩個實時流和一個離線流拼接而成,其中 A 是主鍵列,實時流 1 負責寫入 ABC 三列,實時 流 2 負責寫入 AD 兩列,離線流負責寫入 AE 兩列,此處僅對兩個實時流的拼接程序進行介紹,
圖 1 中顯示兩個流寫入資料以 LogFile 形式存盤,Merge 程序是合并 LogFile 和 BaseFile 中的資料,合并程序中,LogFile 中每一列的值被更新到 BaseFile 中對應的列上,BaseFile 中未被更新的列保持原來的值不變,如圖 1 中 BCD 三列被更新成新值,E 列保持舊值不變,
寫入程序
多流資料拼接方案支持多流并發寫入,相互獨立,對于單個流的寫入,邏輯與 Hudi 原有寫入流程一致,即資料以 Upsert 的方式寫入 Hudi 表,以 LogFile 的形式存盤,并在資料寫入的程序中對資料去重,在多流寫入的場景,核心點在于如何處理并發問題,
圖 2 顯示了資料并發寫入的流程,流 1 和 流 2 是兩個并發的任務,檢查這兩個任務寫入的列除了主鍵以外是不是存在其它交集,例如:
流 1 的 Schema 包含三列 (A,B,C),流 2 的 Schema 包含兩列 (A,D),
在并發寫入的時候,先在 Hudi MetaStore 對兩個任務發起的 DeltaCommit 做列沖突檢查,即除了主鍵列外的其它列是否存在交集,如圖中的 (B,C) 和 (D):
- 如果有交集,則后發起的 DeltaCommit 失敗,
- 如果沒有交集,則兩個任務繼續后續的寫入,
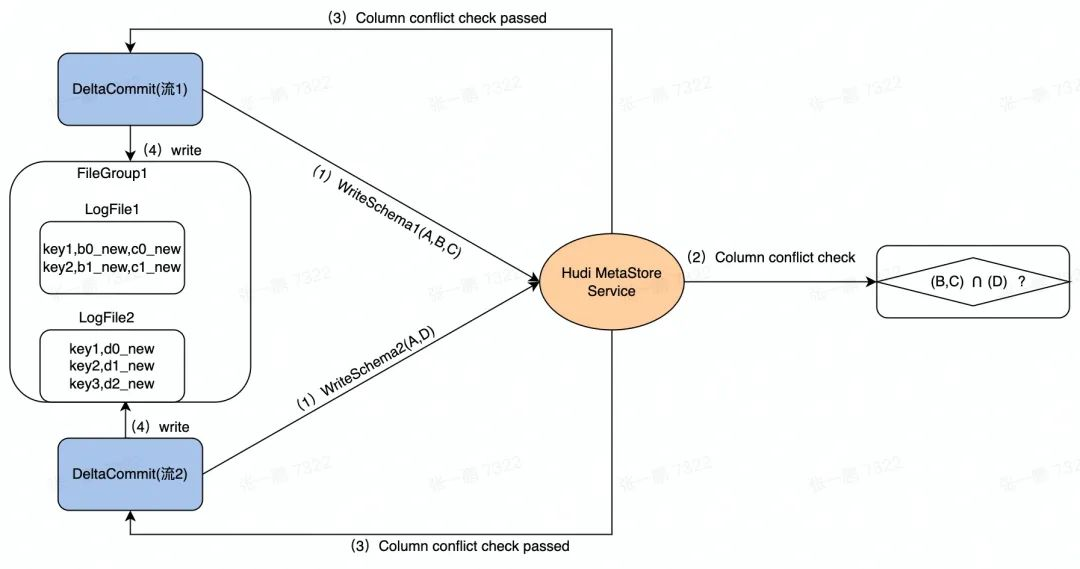
圖 2 資料寫入程序示意圖
讀取程序
接下來,介紹多流拼接場景下 Snapshot Query 的核心程序,即先對 LogFile 進行去重合并,然后再合并 BaseFile 和 去重后的 LogFile 中的資料,圖 3 顯示了整個資料合并的程序,具體可以拆分成以下 兩個程序:
- Merge LogFile
Hudi 現有邏輯是將 LogFile 中的資料讀出來存放在 Map 中,對于 LogFile 中每條 Record,如果 Key 不存在 Map 中,則直接放入 Map,如果 Key 已經存在于 Map 中,則需要更新操作,
在多流拼接中,因為 LogFile 中存在不同資料流寫入的資料,即每條資料的列可能不相同,所以在更新的時候需要判斷相同 Key 的兩個 Record 是否來自同一個流,是則做更新,不是則做拼接,
如圖 3 所示,讀到 LogFile2 中的主鍵是 key1 的 Record 時,key1 對應的 Record 在 Map 中已經存在,但這兩個 Record 來自不同流,則需要拼接形成一條新的 Record (key1,b0_new,c0_new,d0_new) 放入 Map 中,
- Merge BaseFile and LogFile
Hudi 現有默認邏輯是對于每一條存在于 BaseFile 中的 Record,查看 Map 中是否存在 key 相同的 Record,如果存在,則用 Map 中的 Record 覆寫 BaseFile 中的 Record,在多流拼接中,Map 中的 Record 不會完整覆寫 BaseFile 中對應的 Record,可能只會更新部分列的值,即 Map 中的 Record 對應的列,
如圖 3 所示,以最簡單的覆寫邏輯為例,當讀到 BaseFile 中的主鍵是 key1 的 Record 時,發現 key1 在 Map 中已經存在并且對應的 Record 有 BCD 三列的值,則更新 BaseFile 中的 BCD 列,得到新的 Record(key1,b0_new,c0_new,d0_new,e0),注意 E 列沒有被更新,所以保持原來的值 e0,
對于新增的 Key 如 Key3 對應的 Record,則需要將 BCE 三列補上默認值形成一條完整的 Record,
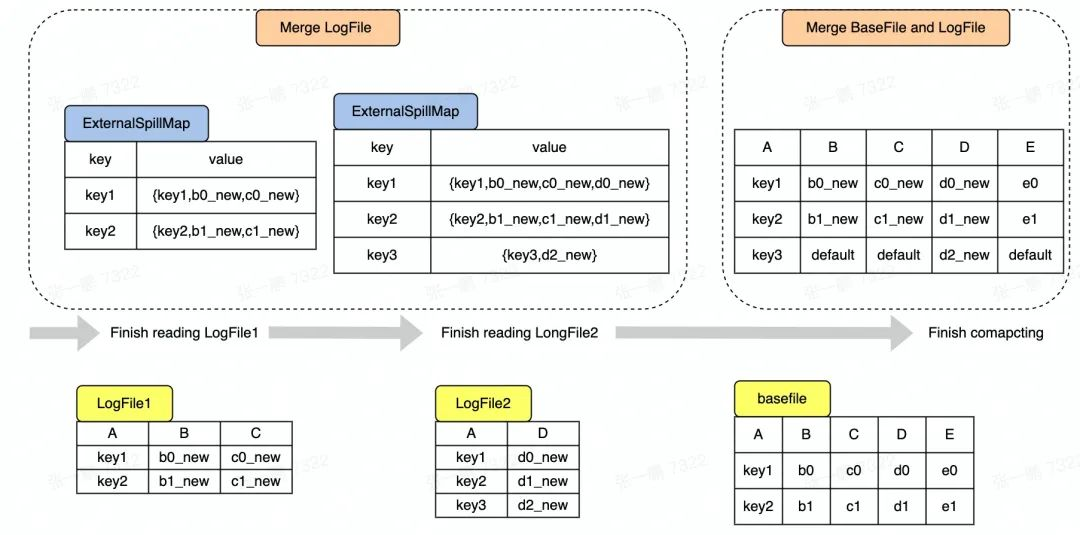
圖3 SnapShot Query 中資料合并程序
異步 Compaction
為了提升讀取性能,某些資料源的寫入任務會同步執行 Compaction,但實踐程序中發現同步執行 Compaction 會阻塞寫入任務,而且 Compaction 任務需要資源比較多,可能會搶占流式匯入任務的資源,
針對這類場景,通過獨立的 Compaction Service 來隔離 Compaction 任務和流式資料匯入任務,與 Hudi 本身自帶的異步 Compaction 不同的是,用戶無需指定要執行的 Compaction Instant,且有一個獨立的 Compaction Service 負責所有的表的 Compaction 操作,關于 Compaction Service 的細節就不在本文展開,詳情可參考 RFC-43,
具體程序是流式匯入任務同步生成 Schedule Compaction Plan,并將 Plan 存入 Hudi MetaStore,有一個獨立于流式匯入任務的 Async Compactor,它從 Hudi MetaStore 回圈拉取 Compaction Plan 并執行,
場景實踐與未來規劃
最終,基于 Hudi 多流拼接的方案,在實時數倉的 DWS 層落地,單表支持了 3+ 資料流的并發匯入,覆寫了數百 TB 的資料,
此外,在使用 Spark 對寬表資料進行查詢時,在單次掃描量幾十 TB 的查詢中,性能相比于直接使用多表關聯性能提升在 200% 以上,在一些更加復雜的查詢下,也有 40-140% 的性能提升,
目前,基于 Hudi 多流拼接方案易用性不足,單個任務至少需要配置超過 10 個引數,為了進一步降低用戶使用成本,后續會做部分列插入和更新的 SQL 的語法支持以及引數的收斂,
除此之外,為了進一步提升寬表資料查詢性能,還計劃在多流拼接場景下支持基于列存格式的 LogFile,提供列裁剪和過濾條件下推等功能,
資料湖團隊正在招人,
歡迎關注位元組跳動資料平臺同名公眾號
相關產品
- 火山引擎湖倉一體分析服務 LAS
面向湖倉一體架構的Serverless資料處理分析服務,提供一站式的海量資料存盤計算和互動分析能力,完全兼容 Spark、Presto、Flink 生態,幫助企業輕松完成資料價值洞察,點擊了解
- 火山引擎E-MapReduce
支持構建開源 Hadoop 生態的企業級大資料分析系統,完全兼容開源,提供 Hadoop、Spark、Hive、Flink 集成和管理,幫助用戶輕松完成企業大資料平臺的構建,降低運維門檻,快速形成大資料分析能力,點擊了解
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/452892.html
標籤:大數據
上一篇:資料插補—拉格朗日插值法
下一篇:4.RDD操作