目錄
- 一、 RDD創建
- 從本地檔案系統中加載資料創建RDD
- 從HDFS加載資料創建RDD
- 通過并行集合(串列)創建RDD
- 二、 RDD操作
- 轉換操作
- filter(func)
- map(func)
- flatMap(func)
- reduceByKey()
- groupByKey()
- sortByKey()
- sortBy()
- 行動操作
- foreach(func)
- collect()
- count()
- take(n)
- reduce()
- 轉換操作
一、 RDD創建
從本地檔案系統中加載資料創建RDD
-
sc:SparkContext(shell自動創建)
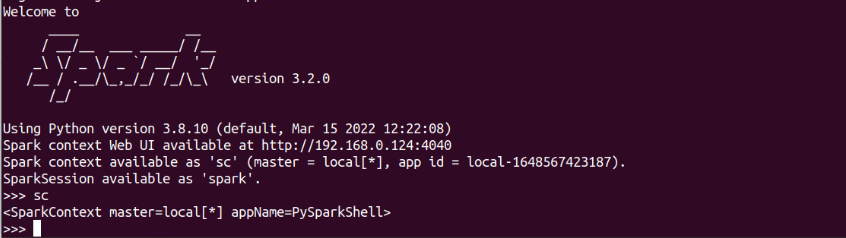
-
本地檔案系統中加載資料創建RDD
Spark采用textFile()方法來從檔案系統中加載資料創建RDD
該方法把檔案的URI作為引數,這個URI可以是:
-
本地檔案系統的地址
-
或者是分布式檔案系統HDFS的地址
-
或者是Amazon S3的地址等等
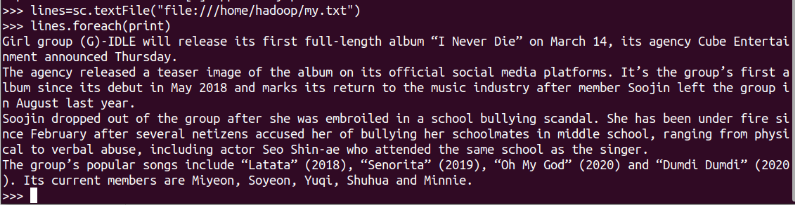
-
從HDFS加載資料創建RDD
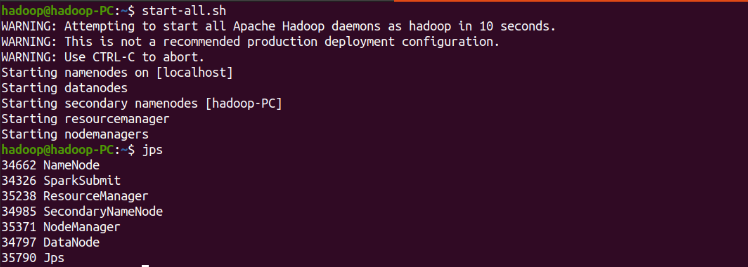
-
啟動hdfs
-
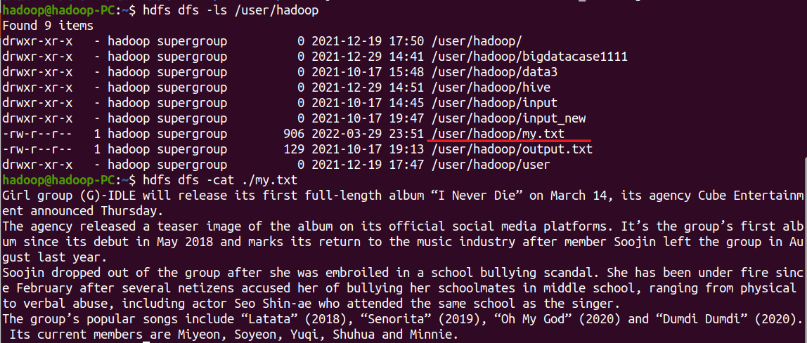
上傳檔案

-
查看檔案
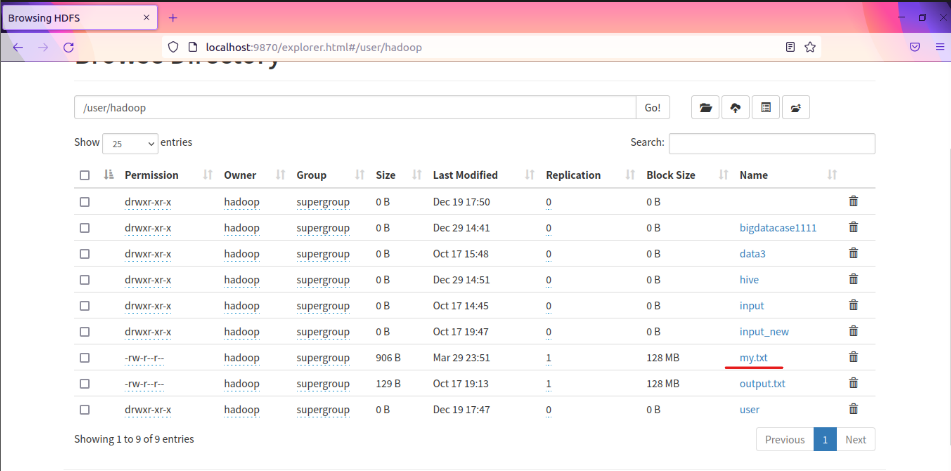
-
spark內加載檔案
textFile默認是讀hdfs,所以hdfs可以省略,
hdfs的默認目錄,前三條陳述句是完全等價的,可以使用其中任意一種方式
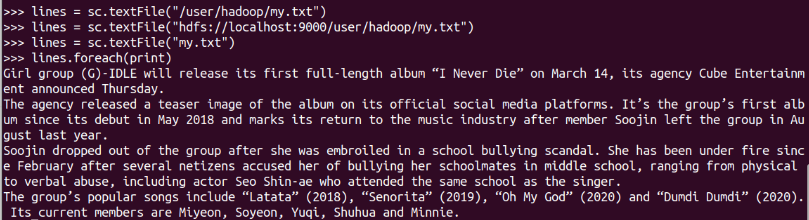
不是默認目錄,要還上路徑
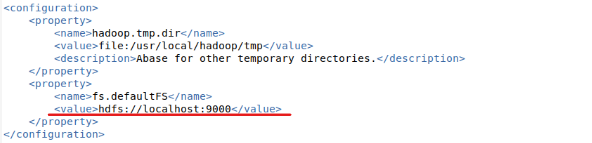
-
停止hdfs
通過并行集合(串列)創建RDD
-
輸入串列、字串、numpy生成陣列

二、 RDD操作
轉換操作
對于RDD而言,每一次轉換操作都會產生新的RDD,供給下一個“轉換”使用
轉換得到的RDD是惰性求值的,也就是說,整個轉換程序只是記錄了轉換的軌跡,并不會發生真正的計算,只有遇到行動操作時,才會發生真正的計算,開始從血緣關系源頭開始,進行物理的轉換操作
| 操作 | 含義 |
|---|---|
| filter(func) | 篩選出滿足函式func的元素,并回傳一個新的資料集 |
| map(func) | 將每個元素傳遞到函式func中,并將結果回傳為一個新的資料集 |
| flatMap(func) | 與map()相似,但每個輸入元素都可以映射到0或多個輸出結果 |
| groupByKey() | 應用于(K,V)鍵值對的資料集時,回傳一個新的(K, Iterable)形式的資料集 |
| reduceByKey(func) | 應用于(K,V)鍵值對的資料集時,回傳一個新的(K, V)形式的資料集,其中每個值是將每個key傳遞到函式func中進行聚合后的結果 |
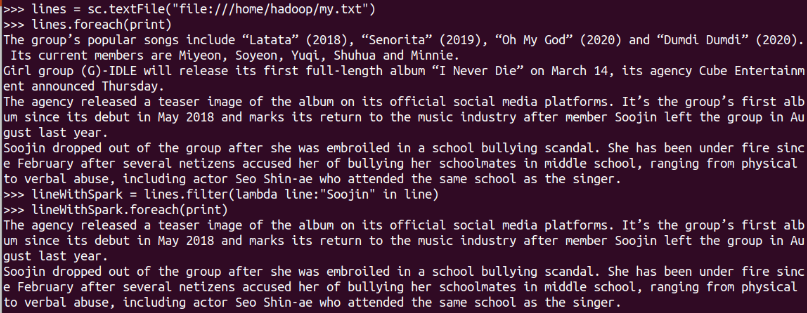
filter(func)
-
顯式定義函式
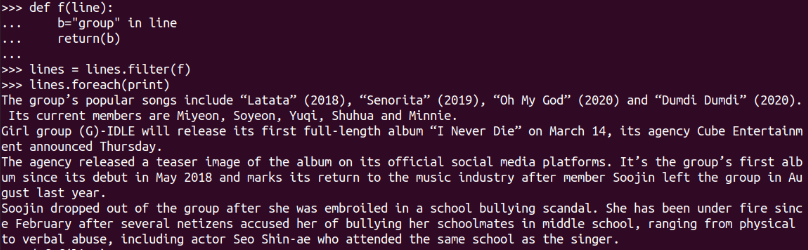
結果不明顯,換個關鍵詞
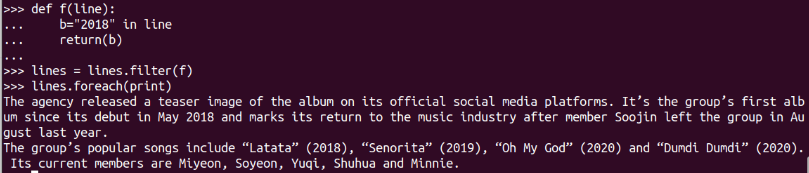
-
lambda函式
map(func)
-
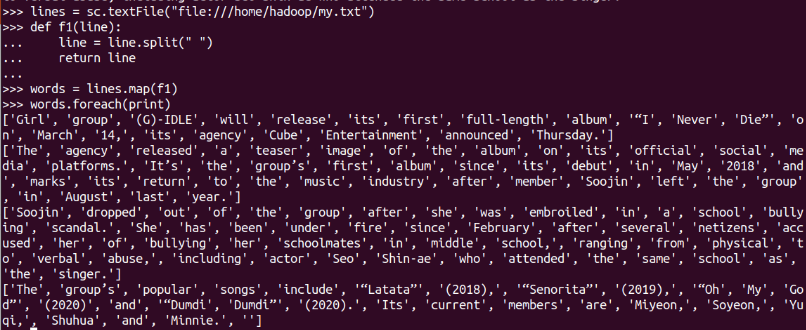
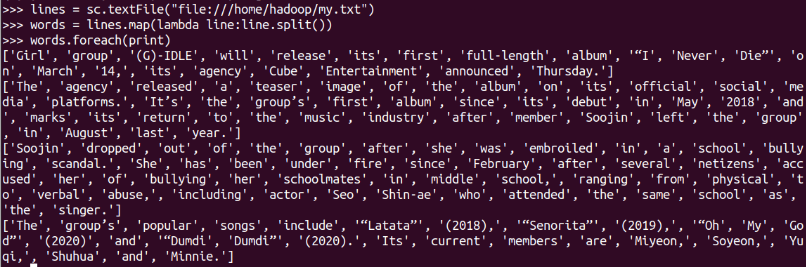
字串分詞
-
顯式定義函式
-
lambda函式
-
-
數字加100
-
顯式定義函式

-
lambda函式

-
-
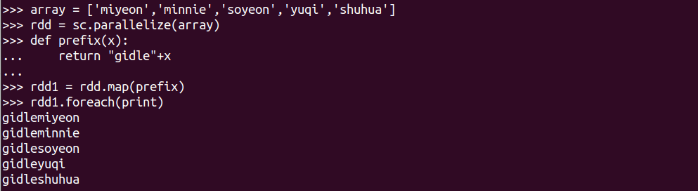
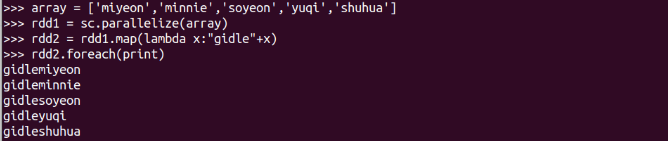
字串加固定前綴
-
顯式定義函式
-
lambda函式
-
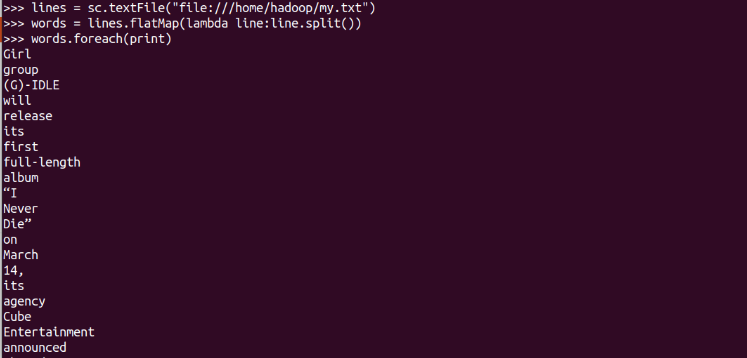
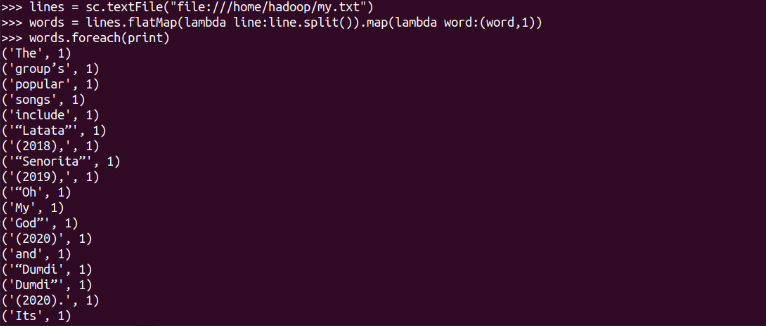
flatMap(func)
-
分詞
-
單詞映射成鍵值對
reduceByKey()
-
統計詞頻,累加

-
乘法規則

groupByKey()
-
單詞分組

-
查看分組的內容

-
分組之后做累加 map

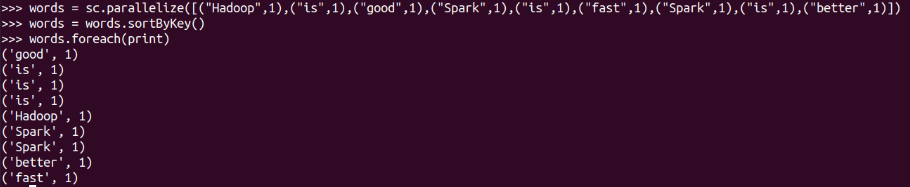
sortByKey()
-
詞頻統計按單詞排序
sortBy()
-
詞頻統計按詞頻排序

行動操作
行動操作是真正觸發計算的地方,Spark程式執行到行動操作時,才會執行真正的計算,從檔案中加載資料,完成一次又一次轉換操作,最終,完成行動操作得到結果,
| 操作 | 含義 |
|---|---|
| count() | 回傳資料集中的元素個數 |
| collect() | 以陣列的形式回傳資料集中的所有元素 |
| first() | 回傳資料集中的第一個元素 |
| take(n) | 以陣列的形式回傳資料集中的前n個元素 |
| foreach(func) | 將資料集中的每個元素傳遞到函式func中運行 |
| reduce(func) | 通過函式func(輸入兩個引數并回傳一個值)聚合資料集中的元素 |
foreach(func)
-
foreach(print)

-
foreach(lambda a:print(a.upper())

collect()

count()

take(n)

reduce()
-
數值型的rdd元素做累加

-
與reduceByKey區別
reduceByKey(func)應用于(K,V)鍵值對的資料集時,回傳一個新的(K, V)形式的資料集,其中的每個值是將每個key傳遞到函式func中進行聚合后得到的結果
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/452893.html
標籤:大數據
上一篇:位元組跳動基于 Apache Hudi 的多流拼接實踐方案
下一篇:MySQL中常用的資料型別