準備作業
最小化安裝master后,確定可以連接Xshell后,克隆出slave1、slave2,修改好網路配置并且確保三臺虛擬機都在一個網關里,并能連接Xshell,
使用此教程前,確保已安裝過偽分布式,有一定的linux基礎,(還沒走穩就想跑你想啥呢,老老實實安裝偽分布去)
同時對三臺虛擬機操作有兩種方式:
1、使用Xshall中發送鍵到所有對話功能
2、在一臺虛擬機中配置完畢后,使用scp命令將檔案發送其他主機,如果沒有進行過SSH免密配置,scp命令需要輸入接收方主機密碼,進行SSH免密配置后不需要再輸密碼,非常方便,
命名約定:
安裝包提前拷貝在/usr/local/package中,三臺虛擬機都有,
安裝的軟體都在/usr/local/下,配置的資料檔案地址一般在軟體安裝檔案夾中,
基礎環境配置(master、slave1、slave2)
基礎環境配置在三臺主機上都要運行命令
修改主機名
分別在三臺對應主機上修改,bash命令使改名及時生效
hostnamectl set-hostname master
hostnamectl set-hostname slave1
hostnamectl set-hostname slave2
bash
關閉防火墻
關閉防火墻
systemctl stop firewalld
禁止防火墻開機自啟
systemctl disable firewalld.service
安裝vim
由于最小化安裝,默認自帶的檔案編輯是vi,沒有代碼高亮很不方便,于是安裝vim
首先配置源
1、將源檔案備份
cd /etc/yum.repos.d/ && mkdir backup && mv *repo backup/
2、下載阿里源檔案
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-8.repo
3、更新源里面的地址
sed -i -e "s|mirrors.cloud.aliyuncs.com|mirrors.aliyun.com|g " /etc/yum.repos.d/CentOS-*
sed -i -e "s|releasever|releasever-stream|g" /etc/yum.repos.d/CentOS-*
4、生成快取
yum clean all && yum makecache
安裝vim
yum install vim
hosts添加映射
在檔案中添加對應ip地址
vim /etc/hosts
192.168.178.100 master
192.168.178.101 slave1
192.168.178.102 slave2
更改時區
timedatectl set-timezone Asia/Shanghai
SSH配置
首先生成密鑰(master、slave1、slave2)
輸入三個回車
ssh-keygen -t rsa
cd ~/.ssh
生成后把密鑰分發,使三臺主機之間可以互相連接
由于現在SSH沒有完成,使用scp命令需要輸入主機密碼
# master將生成的密鑰復制到authorized_keys檔案中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# slave1和slave2的authorized_keys檔案發送給master
# 下面兩行命令分別slave1和slave2運行
scp id_rsa.pub root@master:~/.ssh/id_rsa.pub_s1 # slave1
scp id_rsa.pub root@master:~/.ssh/id_rsa.pub_s2 # slave2
# master上把密鑰整合,再發放給slave1和slave2
# 下面命令都在master上運行
cat id_rsa.pub_s1 >> authorized_keys
cat id_rsa.pub_s2 >> authorized_keys
scp ~/.ssh/authorized_keys root@slave1:~/.ssh/
scp ~/.ssh/authorized_keys root@slave2:~/.ssh/
注:如果遇到權限錯誤,使用下面兩個命令
# 修改權限,不一定會用到
chmod 600 ~/.ssh/authorized_keys
chmod 700 -R ~/.ssh
查看三臺主機的authorized_keys檔案中有三臺主機的密鑰,
cat authorized_keys
測驗ssh是否成功,不需要再輸密碼,三臺虛擬機都可以正常聯通,
ssh master
ssh slave1
ssh slave2
java配置(master、slave1、slave2)
進入安裝包檔案夾,解壓java到/usr/local目錄下
tar -xzf /usr/local/package/jdk-8u221-linux-x64.tar.gz -C /usr/local
# 修改檔案夾名字
mv /usr/local/jdk1.8.0_202 /usr/local/jdk
配置環境變數
vim /etc/profile
export JAVA_HOME=/usr/local/jdk
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
或者/etc/profile中可以這樣配置
export JAVA_HOME=/usr/local/jdk
export JRE_HOME=/usr/local/jdk/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
檢測是否安裝
java -version
分發檔案(如果使用了Xshell發送到所有會話,則不用運行下面命令)
注:分發后記得 source /etc/profile
scp -r /usr/local/jdk root@slave1:/usr/local/
scp -r /usr/local/jdk root@slave2:/usr/local/
scp -r /etc/profile root@slave1:/etc/
scp -r /etc/profile root@slave2:/etc/
zookeeper完全分布式配置(master、slave1、slave2)
解壓安裝,修改檔案名
tar -zxf /usr/local/package/apache-zookeeper-3.7.0-bin.tar.gz -C /usr/local/
mv /usr/local/apache-zookeeper-3.7.0-bin /usr/local/zookeeper
配置zookeeper系統環境變數($ZOOKEEPER_HOME)
vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
source /etc/profile
修改zkServer.sh檔案,加上JAVA_HOME
vim /usr/local/zookeeper/bin/zkServer.sh
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$PATH
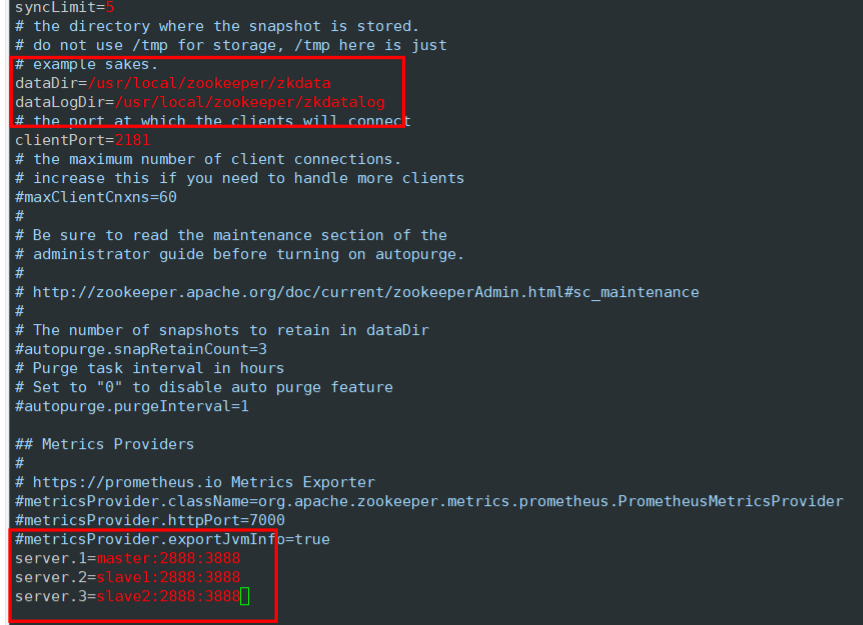
修改組態檔zoo.cfg
zoo.cfg里面的東西不要刪,增加修改就行
cd /usr/local/zookeeper
mkdir zkdata
mkdir zkdatalog
# 進入組態檔夾
cd conf
# 復制配置模板
cp zoo_sample.cfg zoo.cfg
# 編輯配置
vim zoo.cfg
# 修改其中
dataDir=/usr/local/zookeeper/zkdata
# 增加
dataLogDir=/usr/local/zookeeper/zkdatalog
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888下面是zoo.cfg原檔案
資料存盤路徑下創建myid
touch /usr/local/zookeeper/zkdata/myid
分發
scp -r /usr/local/zookeeper root@slave1:/usr/local/
scp -r /usr/local/zookeeper root@slave2:/usr/local/
scp -r /etc/profile root@slave1:/etc/
scp -r /etc/profile root@slave2:/etc/
source /etc/profile
修改myid,分別為123,
master中myid寫入1,slave1中myid寫入2,slave2中myid寫入3
可以用cat /usr/local/zookeeper/zkdata/myid命令查看里面內容
# master
echo 1 > /usr/local/zookeeper/zkdata/myid
# slave1
echo 2 > /usr/local/zookeeper/zkdata/myid
# slave2
echo 3 > /usr/local/zookeeper/zkdata/myid
啟動zookeeper服務(三臺同時啟動)
zkServer.sh start
# 如果上面的不行用這個
/usr/local/zookeeper/bin/zkServer.sh start
驗證是否成功
輸入jps后三臺主機都顯示
[root@master zkdata]# jps
6075 Jps
6031 QuorumPeerMain
查看三臺主機狀態,可以看到一臺主機為leader,另外兩臺為follower,
[root@master zkdata]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@slave1 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@slave2 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
常用命令
# 啟動
zkServer.sh start
# 重啟
zkServer.sh restart
# 停止
zkServer.sh stop
# 查看狀態
zkServer.sh status
# 這樣啟動就知道錯誤原因了
zkServer.sh start-foreground
debug
查看日志發現報錯Cannot open channel to 3 at election address
將本機zoo.cfg中的ip改為0.0.0.0
如何查看日志?
會在當前終端目錄下生成zookeeper.out檔案
Hadoop完全分布式集群配置(master、slave1、slave2)
解壓安裝
tar -zxf /usr/local/package/hadoop-2.7.7.tar.gz -C /usr/local/
mv /usr/local/hadoop-2.7.7 /usr/local/hadoop
配置Hadoop環境變數,注意生效
vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
source /etc/profile
配置Hadoop運行環境JAVA_HOME
hadoop-env.sh 用來定義Hadoop運行環境相關的配置資訊;
cd /usr/local/hadoop/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
core-site.xml全域引數
設定全域引數,指定HDFS上NameNode地址為master,埠默認為9000
vim core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoopData/tmp</value>
</property>
hdfs-site.xml 定義名稱節點、資料節點的存放位置、文本副本的個數、檔案讀取權限等;
vim hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoopData/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoopData/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property><name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostnamedatanode</name>
<value>true</value>
</property>
設定YARN運行環境JAVA_HOME引數
vim yarn-env.sh
export JAVA_HOME=/usr/local/jdk
yarn-site.xml 集群資源管理系統引數配置
設定YARN核心引數,指定ResourceManager行程所在主機為master,埠為18141
設定YARN核心引數,指定NodeManager上運行的附屬服務為mapreduce_shuffle
vim yarn-site.xml
<!--nomenodeManager獲取資料的方式是shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置shuffle,因為map和reduce之間有個shuffle程序,-->
<property>
<name>yarn.nademanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<!--調度器介面的地址,-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<!--對每個rm-id,指定RM webapp對應的host-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
<!--對每個rm-id設定NodeManager連接的host-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<!--對每個rm-id指定管理命令的host-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
mapred-site.xml MapReduce引數
設定計算框架引數,指定MR運行在yarn上
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
設定節點檔案,要求master為主節點; slave1、slave2為子節點
echo master > master && echo slave1 > slaves && echo slave2 >> slaves
分發檔案
scp -r /usr/local/hadoop root@slave1:/usr/local/
scp -r /usr/local/hadoop root@slave2:/usr/local/
scp -r /etc/profile root@slave1:/etc/
scp -r /etc/profile root@slave2:/etc/
source /etc/profile
檔案系統格式化 (只在master)
建議格式化之前存快照,三個主機都存,方便后期修改
hadoop namenode -format
啟動Hadoop集群 (只在master)
/usr/local/hadoop/sbin/start-all.sh
開啟集群后在三臺主機上運行jps命令查看輸出
[root@master hadoop]# jps
6672 SecondaryNameNode
6817 ResourceManager
7074 Jps
6483 NameNode
6031 QuorumPeerMain
[root@slave1 ~]# jps
2481 DataNode
2150 QuorumPeerMain
2586 NodeManager
2686 Jps
[root@slave2 ~]# jps
2582 NodeManager
2682 Jps
2156 QuorumPeerMain
2477 DataNode
JobHistoryServer(master)
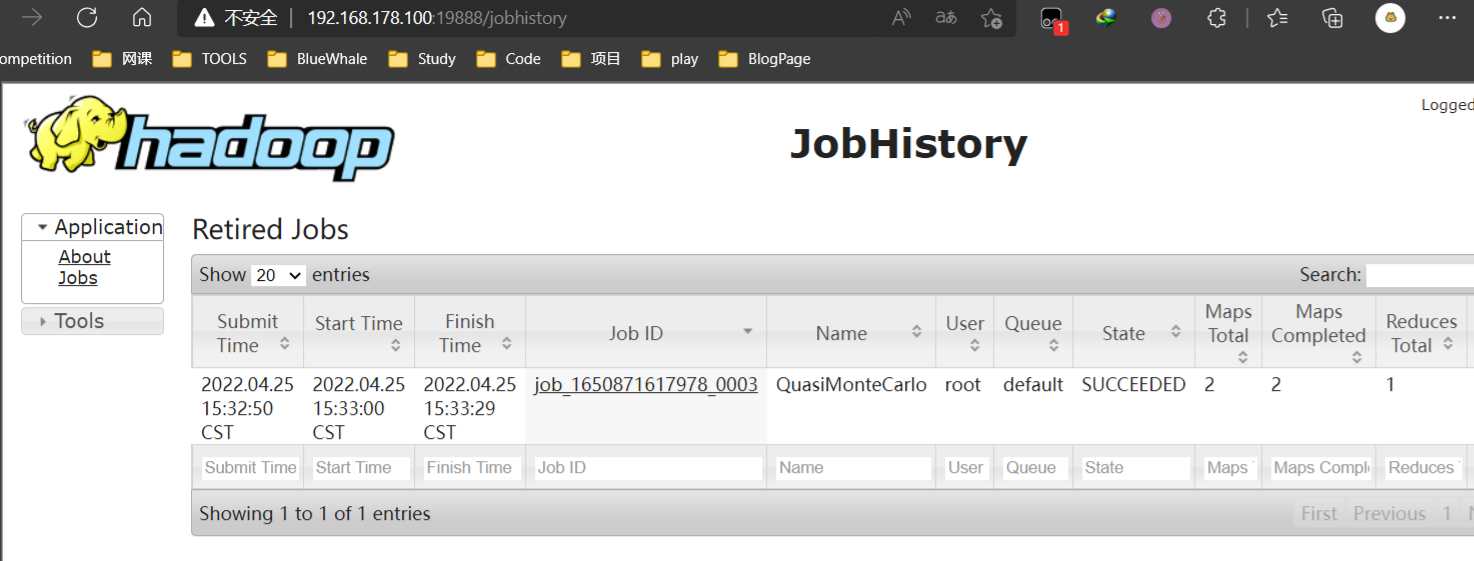
JobHistoryServer是hadoop自帶的歷史服務器,可以通過歷史服務器查看已經運行完的Mapreduce作業記錄,比如用了多少個Map、用了多少個Reduce、作業提交時間、作業啟動時間、作業完成時間等資訊,在后期學習mapreduce后,這個功能非常有用,
但是JobHistoryServer默認是不開啟的,需要自己配置,但是不需要三臺主機都配置,只在master主機配置就可以,流程如下,
首先master關閉集群
/usr/local/hadoop/sbin/stop-all.sh
在 mapred-site.xml 檔案中配置,添加下面內容
cd /usr/local/hadoop/etc/hadoop
vim mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
開啟 jobhistoryserver
/usr/local/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver
開啟集群
/usr/local/hadoop/sbin/start-all.sh
最后使用jps命令查看服務是否都打開
[root@master hadoop]# jps
7569 JobHistoryServer
8083 ResourceManager
8341 Jps
7737 NameNode
7931 SecondaryNameNode
6031 QuorumPeerMain
測驗
運行mapreduce實體,結果為4.000000
cd /usr/local/hadoop/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-2.7.7.jar pi 2 3
打開jobhistory WEB UI埠查看資訊,可以看到剛剛運行的實體資訊,
http://192.168.178.100:19888/
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/464102.html
標籤:其他
下一篇:MySQL通配符與正則運算式