SIGMOD 資料管理國際會議是資料庫領域具有最高學術地位的國際性會議,位列資料庫方向頂級會議之首,近日,騰訊云資料庫團隊的最新研究成果入選 SIGMOD 2022 Research Full Paper(研究類長文),入選論文題目為“HUNTER: An Online Cloud Database Hybrid Tuning System for Personalized Requirements”,標志著騰訊云資料庫團隊在資料庫AI智能化上取得進一步突破,實作性能領先,
資料庫引數自動調優在學術界和工業界都已有較多研究,但現有的方法在缺少歷史資料時或是面對新負載進行引數調優時,往往面臨著調優時間過長的問題(可達到數天),在此篇論文中,團隊提出了混合調優系統Hunter,即改進后的 CDBTune+,主要解決了?個問題:如何在保證調優效果的前提下顯著減少調優時間,經實驗調優效果明顯:隨著并發度提升實作調優時間準線性降低,在單并發度場景下調優時間只需17小時,在20并發度場景下調優時間縮短至2小時,
作業原理(技術原理決議)
這是CDB/CynosDB資料庫團隊第三次研究成果論文被SIGMOD收錄,繼2019年資料庫團隊首度提出基于深度強化學習(DRL)的端到端云資料庫引數調優系統CDBTune,該研究論文“An End-to-End Automatic Cloud Database Tuning System Using Deep Reinforcement Learning”入選SIGMOD 2019 Research Full Paper(研究類長文),
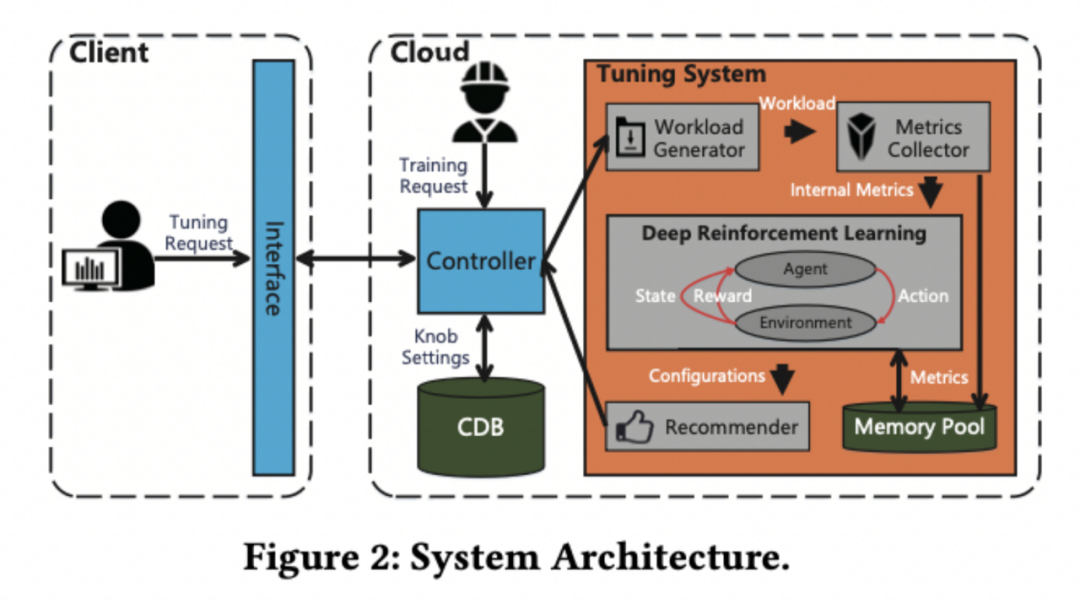
雖然CDBTune 在調參效果上已經達到了?個相當高的水平,但我們也發現,CDBTune 需要較長的調優時間才能通過自我學習達到較高的性能,
對此,本次收錄論文中提出改進的 CDBTune+,能夠在保證調優效果的前提下極大地縮減調優耗時,
改進的混合調優系統CDBTune+,主要包含樣本生成、搜索空間優化、深度推薦三個階段,樣本生成階段利用遺傳演算法進行初期調優,快速獲取高質量樣本;搜索空間優化階段利用上?階段的樣本資訊減小解空間,減少學習成本;深度推薦階段利用之前階段的資訊進行維度優化和強化學習預訓練,保證調優效果的同時顯著減少調優時間,
為了進?步對調優程序進行加速,我們充分利用CDB 的克隆技術,采用多臺資料庫實體實作并行化, 令整個調優時間更進?步地減少,
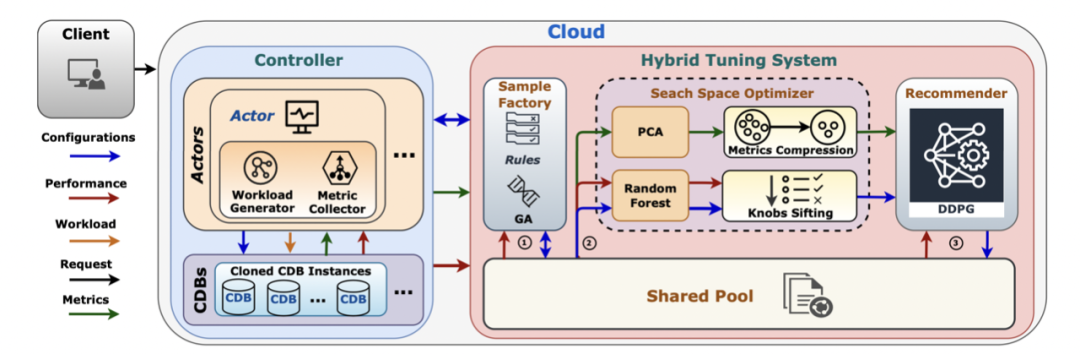
樣本生成
如下圖所示,由于基于學習的調優方法在訓練初期都有著調優效果差、收斂速度慢等問題(我們稱之為冷啟動問題),
我們認為這些方法面臨冷啟動問題主要是因為:
1、樣本數量少質量差,網路難以快速學到正確的探索方向,
2、搜索空間大,網路結構復雜,學習速度緩慢,
為了緩解上述問題,我們采用收斂速度更快的啟發式方法(如:遺傳演算法(GA))進行初期的調優,以此快速獲得高質量的樣本,
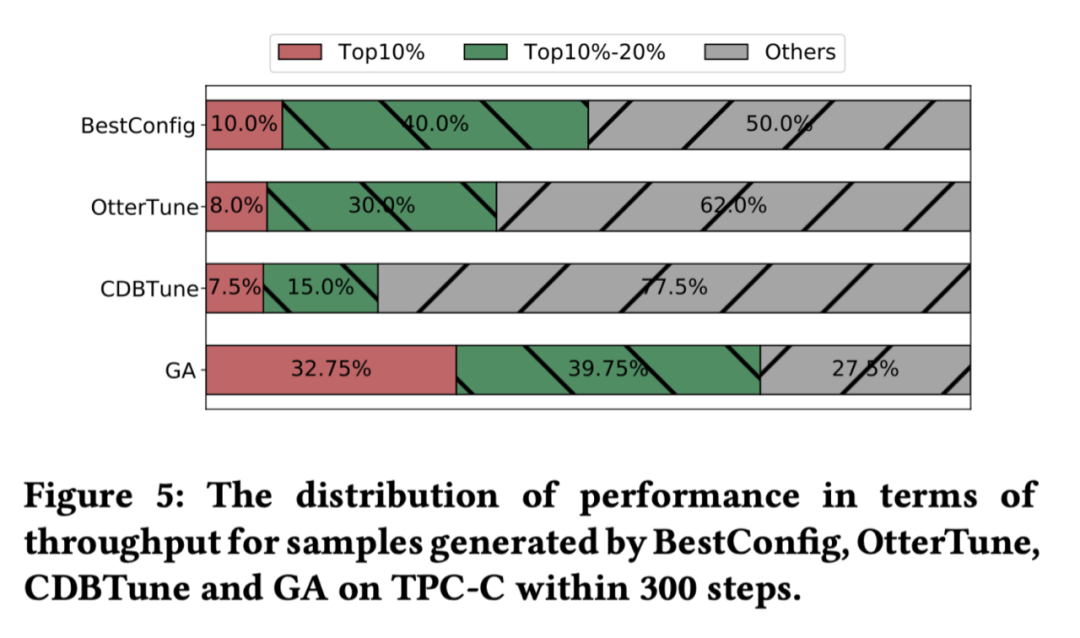
如圖 5 所示,不同方法進行 300 次的引數推薦,圖中是這 300 次引數所對應的資料庫性能分布,可以見得,相較于其他的方法,GA 能夠收集到更多的高性能引數,
雖然有著更快的學習速度,但是 GA 卻可能更容易收斂到次優解,如圖 6 所示,
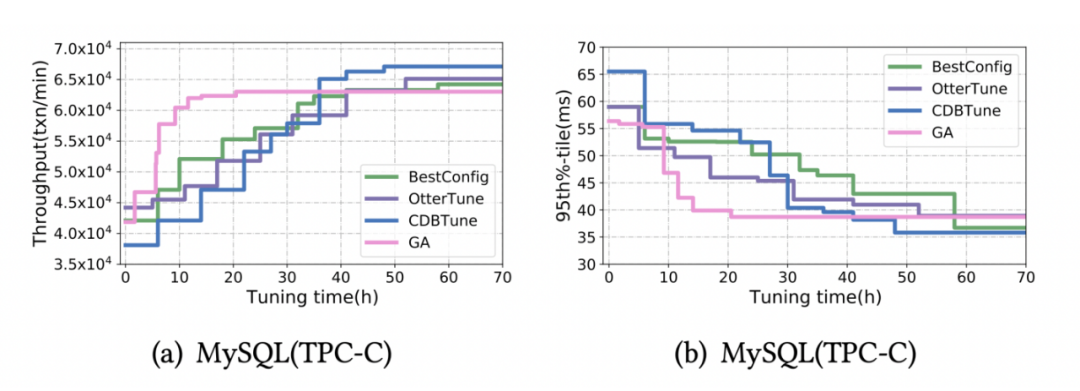
啟發式方法雖有著較快的收斂速度,但是卻容易收斂到區域最優,導致最終調優效果不佳,
而基于學習的方法卻在較長的調優時間后可以得到較高的性能,但是卻需要較長的訓練時間,速度較慢,我們將兩種方法結合,即加快了調優速度,也確保了引數質量,
搜索空間優化
單純地將兩者拼接難以有?定的性能提升(節約約 20%的時間),但是我們期望更多,
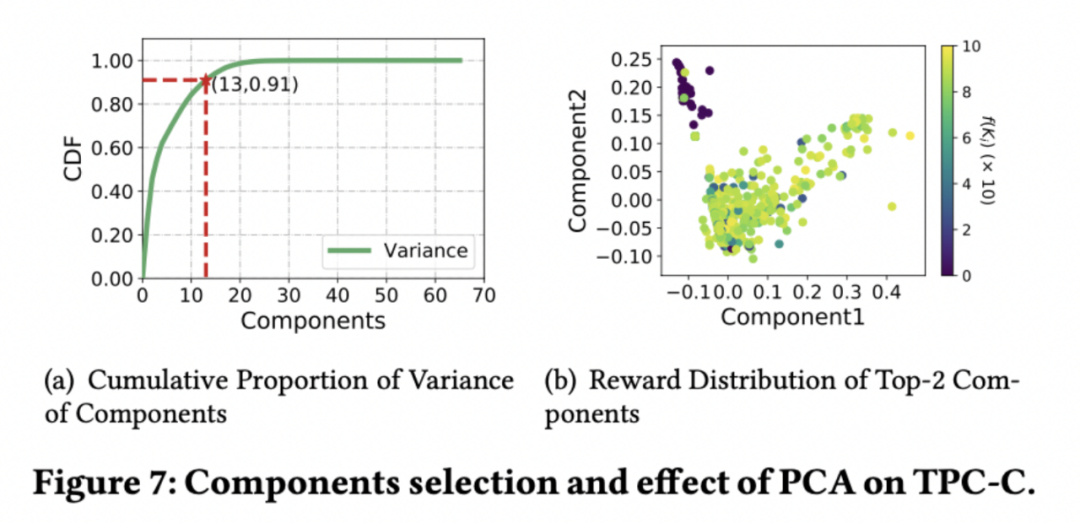
利用樣本生成階段可以獲得較多高質量的樣本,但是卻沒有將其效果充分發揮,我們利用PCA 進行狀態空間降維,Random Forests 進行引數重要性排序,
PCA 是?種常用的降維方法,可將高維資料降為低維資料的同時保留大部分資訊,我們采用累計方差貢獻率來衡量資訊的保留度,?般來說,當累計方差貢獻率 > 90%時即可認為資訊得到了完全的保留,
我們選擇貢獻率最大的兩個成分,并以此作為 x、y 軸描點,以其對應的資料庫性能作為點的顏色(顏色越深性能越低),可以看出,低性能的點可以被兩個成分較為明顯的區分開來,由此可見,PCA 能夠幫助 DRL 更好地學習,
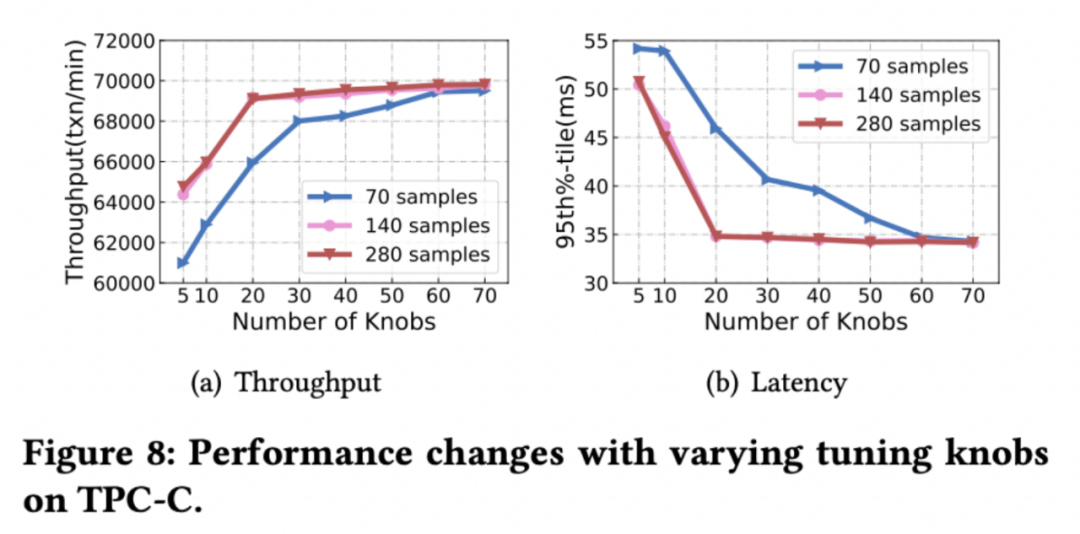
隨機森林可以被用來計算特征的重要性,我們以資料庫引數為輸入,對應的資料庫性能為輸出訓練隨機森林模型,然后計算各個資料庫引數的重要性,并進行排序,采用不同數量的 Top 引數進行引數調優可以看到資料庫最優性能的變化,在?定數量的樣本保證下,TPC-C 負載調整 20 個引數即可達到較高的性能,
深度推薦
經歷樣本生成和搜索空間優化后,我們在深度推薦階段采用深度強化學習(DRL)來進行引數推薦,
首先,搜索空間優化的結果會對 DRL 的網路進行優化,減少其輸入輸出的維度,簡化網路結構,
其次,樣本生成階段的樣本將加入DRL 的經驗池中,由 DRL 進行?定程度的預訓練,
最后,DRL 將基于改進后的探索策略進行引數推薦,
DRL 的基本結構與 CDBTune 類似,為了充分利用高質量的歷史資料,我們修改了其探索策略,動作 (資料庫引數配置)有?定概率在歷史最優引數附近探索,具體的計算方法如下圖所示,
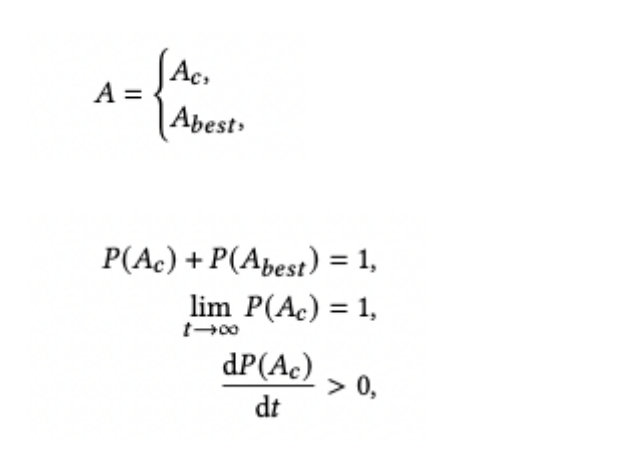
Ac 表示 DRL 的結果,Abest 表示歷史最優,初始情況下 Ac 的概率為 0.3,
調優效果性能分析
效果分析
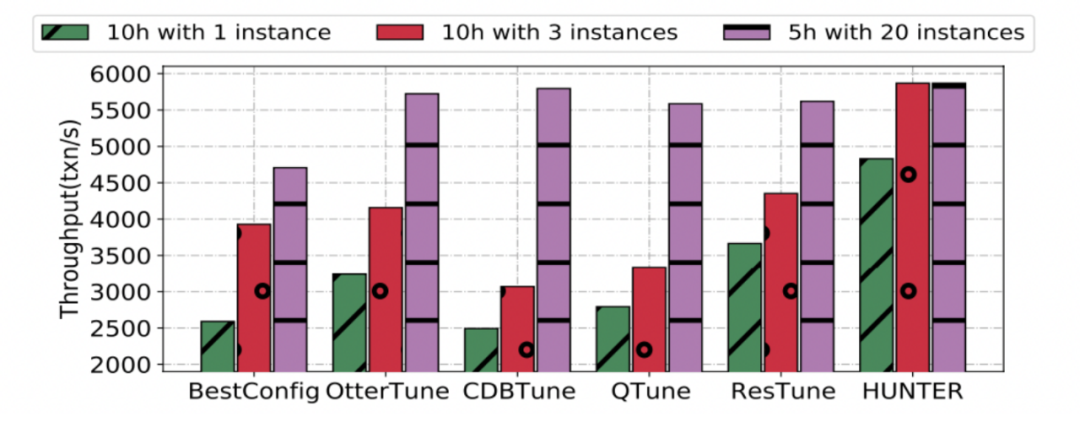
為了測驗不同調優方法從零開始進行引數調優的效果,我們在不同負載下進行了測驗,在測驗中,所有方法都沒有任何的預訓練,其中 HUNTER-20 表示以 20 個實體進行并發調優的 HUNTER,
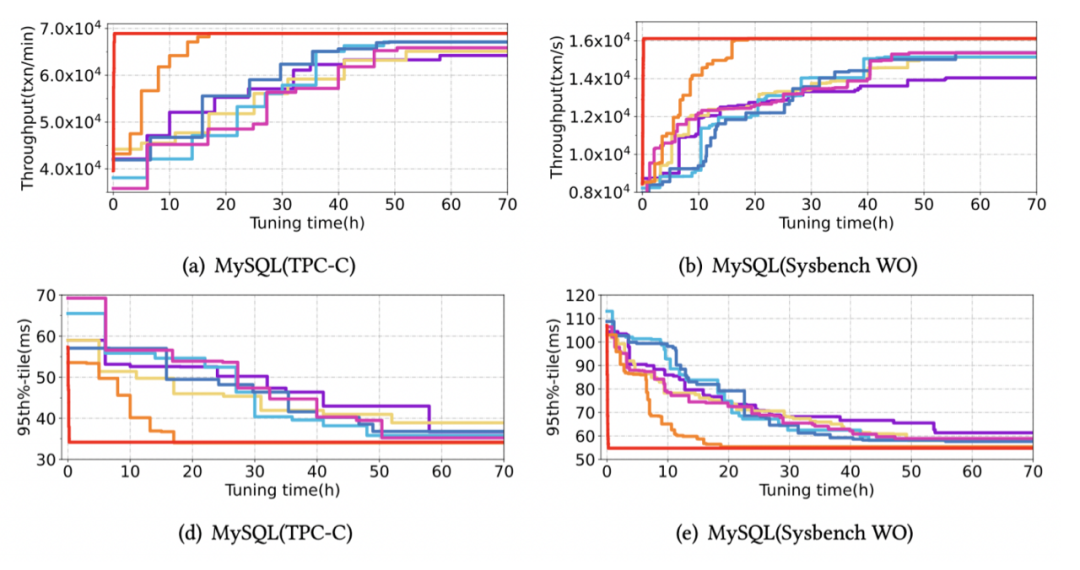
如下圖所示,雖然只有我們的方法提供了并發功能,但是并發加速本身是通用的,因此,我們在真實負載下對不同方法做了進?步測驗,雖然大部分方法借助較長的調優時間可以獲得足夠高的性能,但是,在相同的代價情況下 (時間*實體數),HUNTER 的表現是最好的,
下圖展示了 HUNTER-N 達到串行所能找到的最優性能的調優耗時,可見調優速度的效果,隨著并發度增加,調優時間顯著縮短,
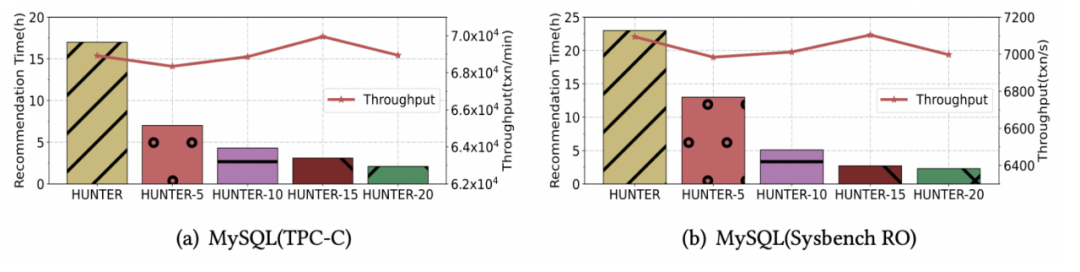
不足
對于 DBA 來說,負載越簡單所需的調優時間應該會越短,但是自動調優方法卻沒有這樣的特質,如我們上述的實驗圖所示,有些時候,簡單負載可能需要更多的時間來獲得更高的性能,更重要的在于,我們目前難以快速地判斷性能是否達到了“最優”,這導致我們花費了額外的時間來觀察調優系統是否能令資料庫性能再得到提高,
目前
通過技術解讀和效果分析,我們可以看出改進后的Hunter大幅提升調優效果,同時體現出論文對實際資料庫問題的落地可能性很高,具有指導方法意義,
在接下來的研究中,我們希望結合專家經驗來解決上文提到的問題,提高引數調優的可解釋性并更進一步壓縮調優時間,同時也希望找到一種估計最優性能的方法,從而減少額外的調優時間,
CDBTune+旨在降低資料庫引數調優的復雜度,實作引數調優零運維,是騰訊云資料庫AI智能化變革的再一次跨越和實作,智能調優一期已經在騰訊云MySQL產品上線,后續會在更多騰訊云資料庫產品上應用,為學術及工業界帶來更多貢獻和服務,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/499154.html
標籤:其它