零基礎學MySQL
筆記目錄:(https://www.cnblogs.com/wenjie2000/p/16378441.html)
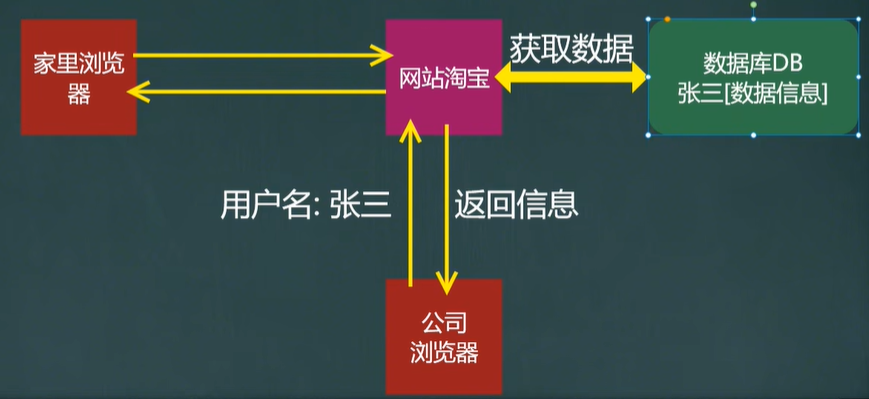
一個問題
淘寶網,京東、微信,抖音都有各自的功能,那么當我們退出系統的時候,下次再訪問時,為什么資訊還存在? =》資料庫
解決之道-檔案、資料庫
為了解決上述問題,使用更加利于管理資料的東東-資料庫,它能更有效的管理資料,
舉一個生活化的復列說明
如果說圖書館是保存書籍的,那么資料庫就是保存資料的,
資料庫的簡單原理圖
MySQL安裝和配置
Mysql下載地址:https://downloads.mysql.com/archives/community/
我安裝的版本為MySQL5.7,如果是安裝其他版本,請自行百度,不同版本的MySql安裝程序存在差別,
特別說明
如果安裝過Mysql程序中,出錯了或者想重新安裝
sc delete mysql 【會洗掉已經安裝好的mysql服務 ,慎重使用】
安裝步驟
請注意,zip 安裝檔案是壓縮檔案,和.exe安裝檔案是不一樣的, 要嚴格的下面的步驟來執行,否則安裝很可能不會成功,
-
下載后會得到zip 安裝檔案
-
解壓的路徑最好不要有中文和空格
-
這里我解壓到 D:\ZhuangYeRuanJian\mysql\mysql-5.7.38-winx64 目錄下 【可自行指定目錄,目錄不能有中文,盡量不安裝在系統盤】
-
添加環境變數 : 電腦-屬性-高級系統設定-環境變數,在Path 環境變數增加mysql的安裝目錄\bin目錄,如下圖所示
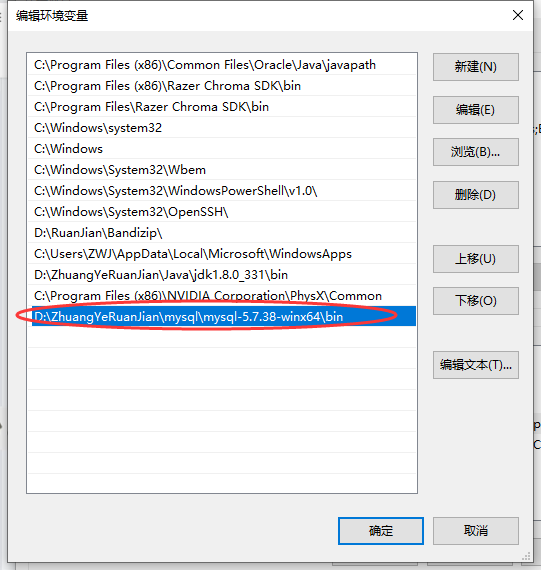
-
在D:\ZhuangYeRuanJian\mysql\mysql-5.7.38-winx64目錄下下創建 my.ini 檔案, 需要我們自己創建(其他非5.7版本會有差異),用記事本打開該檔案,寫入以下內容并保存(注意要根據自己的安裝位置更改文本中的目錄),
[client] port=3306 default-character-set=utf8 [mysqld] # 設定為自己MYSQL的安裝目錄 basedir=D:\ZhuangYeRuanJian\mysql\mysql-5.7.38-winx64\ # 設定為MYSQL的資料目錄 datadir=D:\ZhuangYeRuanJian\mysql\mysql-5.7.38-winx64\data\ port=3306 character_set_server=utf8 #跳過安全檢查(登錄不需要密碼) skip-grant-tables -
使用管理員身份打開 cmd , 并切換到 D:\ZhuangYeRuanJian\mysql\mysql-5.7.38-winx64\bin 目錄下, 執行mysqld -install
d: cd D:\ZhuangYeRuanJian\mysql\mysql-5.7.38-winx64 mysqld -install
如果入到下面兩種情況,是由于你的電腦缺失了相關的系統檔案,下載并安裝:https://www.microsoft.com/zh-CN/download/details.aspx?id=40784
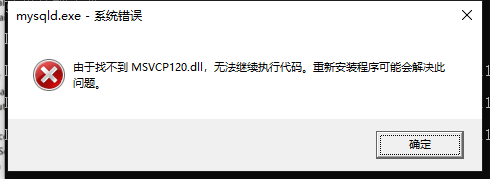
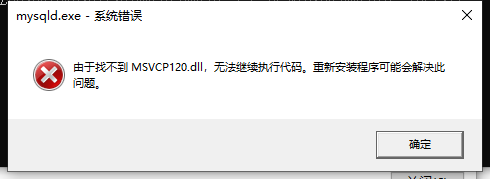
-
初始化資料庫: mysqld --initialize-insecure --user=mysql
如果執行成功,會生成 data目錄:
-
啟動mysql 服務: net start mysql 【停止mysql服務指令 net stop mysql】, 如果成功:

任務管理器中也會出現MySQL服務
-
進入mysql 管理終端: mysql -u root -p 【當前root 用戶密碼為 空,下一行要輸入密碼時直接回車】
-
修改root 用戶密碼
use mysql; update user set authentication_string=password('123456') where user='root' and Host='localhost'; 解讀: 上面的陳述句就是修改 root用戶的密碼為 123456 注意:在后面需要帶 分號,回車即可執行該指令 執行: flush privileges; 重繪權限 退出: quit -
修改my.ini , 再次進入就會進行權限驗證了
#跳過安全檢查(登錄不需要密碼) #skip-grant-tables -
重新啟動mysql
net stop mysql net start mysql 提示: 該指令需要退出mysql , 在Dos下執行. -
再次進入Mysql, 輸入正確的用戶名和密碼
mysql -u root -p 密碼正確,進入mysql 密碼錯誤,提示如下資訊 ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: NO)
安裝程序中,一定要按照老師的步驟來,不然會錯誤.
如果真的錯誤了, 清除mysql服務, 再次安裝.
連接到Mysql服務(Mysql資料庫)的指令
mysql -h 主機IP -P 埠 -u 用戶名 -p密碼
提醒:
- -p密碼不要有空格
- -p后面沒有寫密碼,回車會要求輸入密碼
- 如果沒有寫-h主機,默認就是本機
- 如果沒有寫-P埠,默認就是3306
- 在實際作業中,3306一般修改
安裝Navicat
http://www.navicat.com.cn/download/navicat-for-mysql
安裝程序很簡單,此處省略
如果想破解,百度,教程很多
安裝后,打開,點擊左側的“連接”,進行如下配置,
資料庫
注意:navicat只是方便手動操作和查看,光是會使用它沒有太大意義,實際開發中程式員操作資料庫還是要通過指令,指令是必須要認真學的,
資料庫三層結構-破除 MySQL 神秘
-
所謂安裝Mysql資料庫,就是在主機安裝一個資料庫管理系統(DBMS),這個管理程式可以管理多個資料庫,DBMS(database manage system)
-
一個資料庫中可以創建多個表,以保存資料(資訊),
-
資料庫管理系統(DBMS)、資料庫和表的關系如圖所示:示意圖
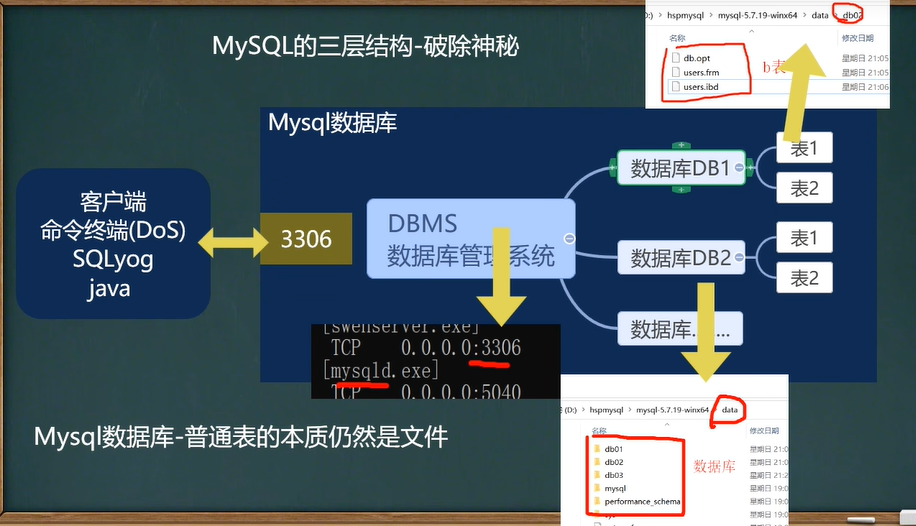
資料在資料庫中的存盤方式

SQL 陳述句分類
DDL:資料定義陳述句[create表,庫...]
DML:資料操作陳述句[增加insert,修update,洗掉delete]
DQL:資料查詢陳述句[select ]
DCL:資料控制陳述句[管理資料庫:比如用戶權限 grant revoke ]
創建
注意:
在mysql資料庫中,sql關鍵字和大小寫 是不區分大小寫的,
windows下mysql中的資料庫名、表名、列名默認是不區分大小寫的,但是linux會區分大小寫,所以當執行的sql陳述句有大小寫區別時需要注意,
因此,mysql創建資料庫、表、列時,盡量使用小寫命名,如果名字由多個單詞組成可以使用“_”作為間隔符,如果名字和關鍵字重名可以用反引號“`”括起來,
具體情況可以看這篇博客:https://www.cnblogs.com/chenhaoblog/p/13604727.html
CREATE DATABASE [IF NOT EXISTS] db_name
[create_specification [,create_specification]...]
create_specification:
[DEFAULT]CHARACTER SET charset_namel
[DEFAULT]COLLATE collation_name
#中括號中的內容為可寫可不寫的,根據實際情況決定,實際陳述句的使用中不要寫上中括號
-
CHARACTER SET:指定資料庫采用的字符集,如果不指定字符集,默認utf&,
-
COLLATE:指定資料庫字符集的校對規則(常用的utf8 bin[區分大小寫]、utf8 general ci[不區分大小寫(例:A==a)]注意默認是utf8_general_ci)
# 演示資料庫的操作 #創建一個名稱為 hsp_db01 的資料庫,[圖形化和指令 演示] #使用指令創建資料庫 CREATE DATABASE hsp_db01; #洗掉資料庫指令 DROP DATABASE hsp_db01 #創建一個使用 utf8 字符集的 hsp_db02 資料庫 CREATE DATABASE hsp_db02 CHARACTER SET utf8 #創建一個使用 utf8 字符集,并帶校對規則的 hsp_db03 資料庫 CREATE DATABASE hsp_db03 CHARACTER SET utf8 COLLATE utf8_bin #校對規則 utf8_bin 區分大小 默認 utf8_general_ci 不區分大小寫 #下面是一條查詢的 sql , select 查詢 * 表示所有欄位 FROM 從哪個表 #WHERE 從哪個欄位 NAME = 'tom' 查詢名字是 tom SELECT * FROM t1 WHERE NAME = 'tom'
查看、洗掉資料庫
顯示資料庫陳述句:
SHOW DATABASES
顯示資料庫創建陳述句:
SHOW CREATE DATABASE db_name
資料庫洗掉陳述句[一定要慎用]:
DROP DATABASE [IF EXISTS] db_name
#演示洗掉和查詢資料庫
#查看當前資料庫服務器中的所有資料庫
SHOW DATABASES
#查看前面創建的 hsp_db01 資料庫的定義資訊
SHOW CREATE DATABASE `hsp_db01`
#老師說明 在創建資料庫,表的時候,為了規避關鍵字,可以使用反引號解決
CREATE DATABASE `INT`
#洗掉前面創建的 hsp_db01 資料庫
DROP DATABASE hsp_db01
備份恢復資料庫
備份資料庫(注意:在DOS執行)
mysqldump -u 用戶名 -p[密碼] -B 資料庫1 資料庫2 資料庫n > 路徑\\檔案名.sql
-p后面可以加上密碼,也可以不寫,回車后再輸入密碼
恢復資料庫(注意:cmd進入MySQL命令列再執行)
Source 檔案名.sql
#練習 : database03.sql 備份 hsp_db02 和 hsp_db03 庫中的資料,并恢復
#備份, 要在 Dos 下執行 mysqldump 指令其實在 mysql 安裝目錄\bin
#這個備份的檔案,就是對應的 sql 陳述句
mysqldump -u root -p -B hsp_db02 hsp_db03 > d:\\bak.sql
DROP DATABASE ecshop;
#恢復資料庫(注意:在DOS界面,先進入 Mysql 命令列再執行)
source d:\\bak.sql
#第二個恢復方法, 直接將 bak.sql 的內容放到查詢編輯器中,執行
備份恢復資料庫的表
mysqldump -u 用戶名 -p[密碼] 資料庫 表1 表2 表n > 路徑\\檔案名.sql
-p后面可以加上密碼,也可以不寫,回車后再輸入密碼
恢復方式和上面一樣
表
創建
CREATE TABLE table_name
(
field1 datatype,
field2 datatype,
field3 datatype
)character set 字符集 collate 校對規則 engine 引擎
field:指定列名 datatype:指定列型別(欄位型別)
character set:如不指定則為所在資料庫字符集
collate:如不指定則為所在資料庫校對規則
engine:引擎(這個涉及內容較多,后面單獨講解)
洗掉
drop table 表名;
修改
如果看了b站 韓順平老師的課程,注意他的PPT這部分的指令有問題,下面的才是對的,
#添加列
ALTER TABLE 表名
ADD 列名 datatype [DEFAULT expr];
#修改列型別
ALTER TABLE 表名
MODIFY 列名 datatype [DEFAULT expr];
#修改列型別及名稱
ALTER TABLE 表名
CHANGE 列名 新列名 datatype;
#洗掉列
ALTER TABLE 表名;
DROP 列名;
查看表的結構: desc 表名; --可以查看表的列
#修改表名:
rename table 表名 to 新表名;
#修改表字符集:
alter table 表名 character set 字符集;
應用實體:
- 員工表emp增加一個image列,varchar型別(要求在resume后面).
- 修改job列,使其長度為60,
- 洗掉sex列,
- 表名改為employee,
- 修改表的字符集為utf8
- 列名name修改為user_name
ALTER TABLE emp
ADD image varchar(32) NOT NULL DEFAULT '' AFTER resume;
ALTER TABLE emp
MODIFY job varchar(60);
ALTER TABLE emp
DROP sex;
DESC emp;
rename table emp to employee;
ALTER TABLE employee character set utf8;
ALTER TABLE employee CHANGE `name` `user_name` varchar(20);
Mysql資料型別
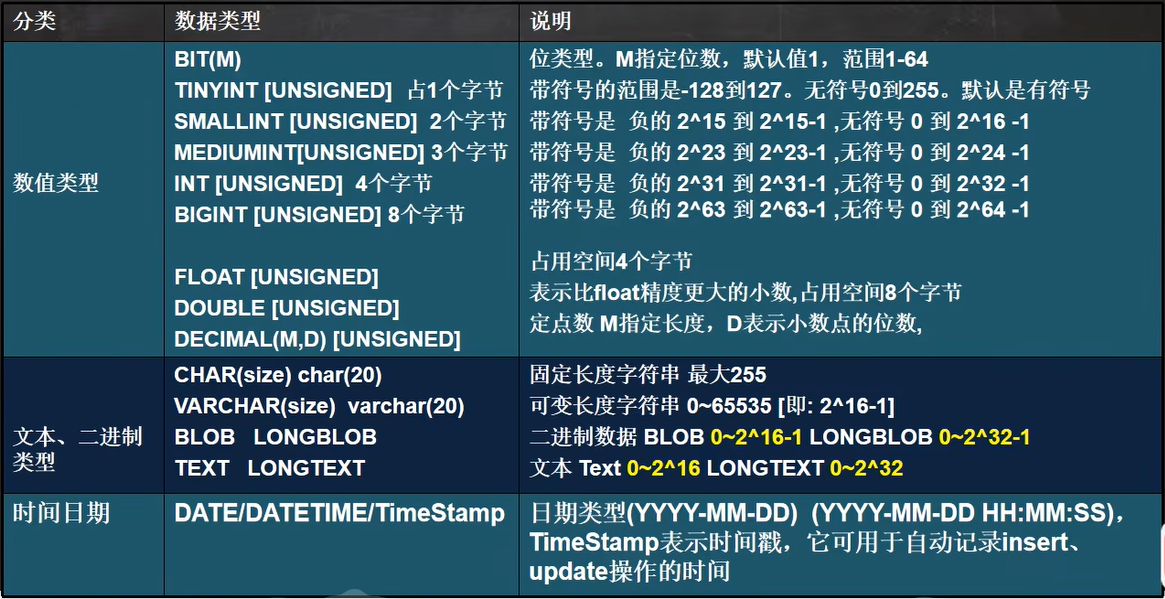
數值型(整數)的基本使用
說明:在能夠滿足需求的情況下,盡量選擇占用空間小的型別(節省資源)
| 型別 | 位元組 | 最小值 | 最大值 |
|---|---|---|---|
| (帶符號的/無符號的) | (帶符號的/無符號的) | ||
| TINYINT | 1 | -128 | 127 |
| [unsigned] | 0 | 255 | |
| SMALLINT | 2 | -32768 | 32767 |
| 0 | 65535 | ||
| MEDIUMINT | 3 | -8388608 | 8388607 |
| 0 | 16777215 | ||
| INT | 4 | -2147483648 | 2147483647 |
| 0 | 4294967295 | ||
| BIGINT | 8 | -9223372036854775808 | 9223372036854775807 |
| 0 | 18446744073709551615 |
#演示整型的是一個
#使用 tinyint 來演示范圍 有符號 -128 ~ 127 如果沒有符號 0-255
#說明: 表的字符集,校驗規則, 存盤引擎,老師使用默認
#1. 如果沒有指定 unsinged , 則 TINYINT 就是有符號
#2. 如果指定 unsinged , 則 TINYINT 就是無符號 0-255
CREATE TABLE t3 (id TINYINT);
CREATE TABLE t4 (id TINYINT UNSIGNED);
INSERT INTO t3 VALUES(127); #這是非常簡單的添加陳述句
SELECT * FROM t3;
INSERT INTO t4 VALUES(255);
SELECT * FROM t4;
數值型(bit)的使用
-
基本使用
create table t02 (num bit(8)); insert into t02 (1,3); insert into t02 values(2,65); -
細節說明
bit欄位顯示時,按照位的方式顯示.查詢的時候仍然可以用使用添加的數值
如果一個值只有0,1可以考慮使用bit(1),可以節約空間位型別,M指定位數,默認值1,范圍1-64
使用不多.#演示 bit 型別使用 #說明 #1. bit(m) m 在 1-64 #2. 添加資料 范圍 按照你給的位數來確定,比如 m = 8 表示一個位元組 0~255 #3. 顯示按照 bit #4. 查詢時,仍然可以按照數來查詢 CREATE TABLE t05 (num BIT(8)); INSERT INTO t05 VALUES(255); SELECT * FROM t05; SELECT * FROM t05 WHERE num = 1;
數值型(小數)的基本使用
- FLOAT/DOUBLE [UNSIGNED]
Float單精度精度,Double 雙精度
-
DECIMAL[M,D] [UNSIGNED]
可以支持更加精確的小數位,M是位數(整數位數+小數位數)的總數,D是小數點(標度)后面的位數,
如果D是0,則值沒有小數點或分數部分,M最大65,D最大是30,如果D被省略,默認是0,如果M被省略,默認是10,
建議:如果希望小數的精度高,推薦使用decimal
#演示 decimal 型別、float、double 使用
#創建表
CREATE TABLE t06 (
num1 FLOAT,
num2 DOUBLE,
num3 DECIMAL(30,20));
#添加資料
INSERT INTO t06 VALUES(88.12345678912345, 88.12345678912345,88.12345678912345);
SELECT * FROM t06;
#decimal 可以存放很大的數
CREATE TABLE t07 (
num DECIMAL(65));
INSERT INTO t07 VALUES(8999999933338388388383838838383009338388383838383838383);
字串的基本使用
-
CHAR(size)
固定長度字串最大255字符
-
VARCHAR(size)
可變長度字串最大65532位元組【utf8編碼最大21844字符(因為(65535-2)/3)=21844.3),1-2個位元組用于記錄存盤資料長度,如果允許為null也要占用一個位元組,不允許為空則不占用這一個位元組】
字串使用細節
-
細節1
char(4)//這個4表示字符數(最大255),不是位元組數,不管是中文還是字母都是放四個,按字符計算.
varchar(4)//這個4表示字符數,不管是字母還是中文都以定義好的表的編碼來存放資料.
不管是中文還是英文字母,都是最多存放4個,是按照字符來存放的.
-
細節2
char(4)是定長(固定的大小),就是說,即使你插入'aa',也會占用分配的4個字符的空間.
varchar(4)是變長,就是說,如果你插入了'aa',實際占用空間大小并不是4個字符,而是按照實際占用空間來分配(說明:varchar本身還需要多占用1-3個位元組)
-
細節3
什么時候使用char,什么時候使用varchar
- 如果資料是定長,推薦使用char,比如md5的密碼,郵編,手機號,身份證號碼等. char(32)
- 如果一個欄位的長度是不確定,我們使用varchar,比如留言,文章
查詢速度:char > varchar
-
細節4
在存放文本時,也可以使用Text 資料型別,可以將TEXT列視為VARCHAR列,注意Text不能有默認值,大小0~216位元組
如果希望存放更多字符,可以選擇 MEDIUMTEXT (0~224位元組) 或者LONGTEXT (0~232位元組)
#演示字串型別的使用細節
#char(4) 和 varchar(4) 這個 4 表示的是字符,而不是位元組, 不區分字符是漢字還是字母
CREATE TABLE t11(`name` CHAR(4));
INSERT INTO t11 VALUES('韓順平123');
SELECT * FROM t11;
CREATE TABLE t12(`name` VARCHAR(4));
INSERT INTO t12 VALUES('韓順平212');
INSERT INTO t12 VALUES('ab 北京');
SELECT * FROM t12;
#如果 varchar 不夠用,可以考試使用 mediumtext 或者 longtext,
#如果想簡單點,可以使用直接使用 text
CREATE TABLE t13( content TEXT, content2 MEDIUMTEXT , content3 LONGTEXT);
INSERT INTO t13 VALUES('韓順平教育', '韓順平教育 100', '韓順平教育 1000~~');
SELECT * FROM t13;
日期型別的基本使用
CREATE TABLE birthday( t1 DATE, t2 DATETIME,
t3 TIMESTAMP NOT NULL DEFAULTCURRENT TIMESTAMP ON UPDATE
CURRENT TIMESTAMP );
mysql> INSERT INTO birthday(t1,t2)
VALUES('2022-11-11','2022-11-11 10:10:10');
#timestamp時間戳
日期型別的細節說明
TimeStamp在Insert和update時,自動更新
#演示時間相關的型別
#創建一張表, date , datetime , timestamp
CREATE TABLE t14 (
birthday DATE , -- 生日
job_time DATETIME, -- 記錄年月日 時分秒
login_time TIMESTAMP
NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP); -- 登錄時間, 如果希望 login_time 列自動更新, 需要配置
SELECT * FROM t14;
INSERT INTO t14(birthday, job_time)
VALUES('2022-11-11','2022-11-11 10:10:10');
-- 如果我們更新 t14 表的某條記錄,login_time 列會自動的以當前時間進行更新
練習題
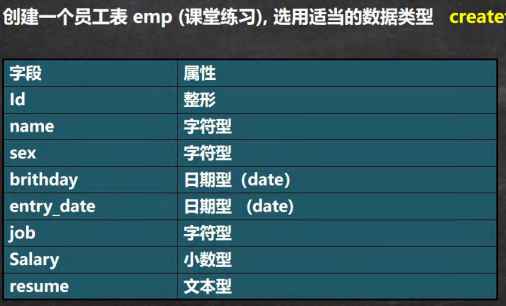
-- 自己一定要練習一把
CREATE TABLE `emp` (id INT,
`name` VARCHAR(32),
sex CHAR(1),
brithday DATE,
entry_date DATETIME,
job VARCHAR(32),
salary DOUBLE,
`resume` TEXT) CHARSET utf8 COLLATE utf8_bin ENGINE INNODB;
-- 添加一條
INSERT INTO `emp`
VALUES(100, '小妖怪', '男', '2000-11-11',
'2010-11-10 11:11:11', '巡山的', 3000, '大王叫我來巡山');
SELECT * FROM `emp`;
CRUD
C[creat]R[read]U[update]D[delete]
lnsert(添加資料)
INSERT INTO 表名 [(column1 [, column2. . .])]
VALUES (value1 [, value2...]);
快速入門案例:
-
創建一張商品表goods(id int , goods_name varchar(10),price double);
-
添加2條記錄
create table goods(id int,goods_name varchar(10),price double); INSERT INTO goods VALUES (10,'可樂',4.5); INSERT INTO goods (id,goods_name,price) VALUES (11,'可樂2',4.6);
細節說明
-
插入的資料應與欄位的資料型別相同,
比如把'abc'添加到int型別會錯誤
-
資料的長度應在列的規定范圍內,例如:不能將一個長度為80的字串加入到長度為40的列中,
-
在values中列出的資料位置必須與被加入的列的排列位置相對應,
-
字符和日期型資料應包含在單引號中,
-
列可以插入空值[前提是該欄位允許為空],insert into table value(null)
-
insert into 表名 (列名...) values (),(),()形式添加多條記錄
INSERT INTO `goods` (id,goods_name,price) VALUES(50,'三星手機',2300),(60,'海爾手機',1800); -
如果是給表中的所有欄位添加資料,可以不寫前面的欄位名稱
INSERT INTO goods VALUES (10,'可樂',4.5); -
默認值的使用,當不給某個欄位值時,如果有默認值就會添加,否則報錯
Update(更新資料)
UPDATE 表名
SET 列名1=expr1 [, 列名2=expr2 ...][WHERE where_definition]
基本使用:
要求:在上面創建的employee表中修改表中的紀錄
-
將所有員工薪水修改為5000元,
-
將姓名為小妖怪的員工薪水修改為3000元,
-
將老妖怪的薪水在原有基礎上增加1000元,
-- 1. 將所有員工薪水修改為 5000 元,[如果沒有帶 where 條件,會修改所有的記錄,因此要小心] UPDATE employee SET salary=5000; -- 2 UPDATE employee SET salary=3000 WHERE `user_name`='小妖怪'; -- 3 UPDATE employee SET salary=salary+1000 WHERE `user_name`='老妖怪';
使用細節:
-
UPDATE語法可以用新值更新原有表行中的各列,
-
SET子句指示要修改哪些列和要給予哪些值,
-
WHERE子句指定應更新哪些行,如沒有WHERE子句,則更新所有的行,
-
如果需要修改多個欄位,可以通過 set 欄位1=值1,欄位2=值2…….
UPDATE employee SET salary =salary +1000, job ='出主意的' WHERE user_name ='老妖怪';
Delete(洗掉資料)
delete from 表名
[WHERE where_definition]
快速入門案例(使用employee測驗)
-
洗掉表中名稱為'老妖怪'的記錄
-
洗掉表中所有記錄,
-- 1 DELETE FROM `employee` WHERE user_name='老妖怪'; -- 2 DELETE FROM `employee`;
使用細節
- 如果不使用where子句,將洗掉表中所有資料,
- Delete陳述句不能洗掉某一列的值(可使用update設為null或者'')
- 使用delete陳述句僅洗掉記錄,不洗掉表本身,如要洗掉表,使用droptable陳述句,drop table 表名;
Select(查找資料-單表)
SELECT [DISTINCT] * | {column1, column2, column3... }
FROM 表名;
注意事項
- Select 指定查詢哪些列的資料,
- column指定列名,
- *號代表查詢所有列,
- From指定查詢哪張表,
- DISTINCT可選,指顯示結果時,去掉重復資料(此處重復指的是兩行內容完全相同)
練習題
先使用以下指令創建表,不只是這題需要用,后面還要用:
create table student(
id int not null default 1,
name varchar(20) not null default '',
chinese float not null default 0.0,
english float not null default 0.0,
math float not null default 0.0
);
insert into student(id,name,chinese,english,math) values(1,'韓順平',89,78,90);
insert into student(id,name,chinese,english,math) values(2,'張飛',67,98,56);
insert into student(id,name,chinese,english,math) values(3,'宋江',87,78,77);
insert into student(id,name,chinese,english,math) values(4,'關羽',88,98,90);
insert into student(id,name,chinese,english,math) values(5,'趙云',82,84,67);
insert into student(id,name,chinese,english,math) values(6,'歐陽鋒',55,85,45);
insert into student(id,name,chinese,english,math) values(7,'黃蓉',75,65,30);
insert into student(id,name,chinese,english,math) values(8,'李明',80,65,30);
-
查詢表中所有學生的資訊,
-
查詢表中所有學生的姓名和對應的英語成績,
-
過濾表中重復資料distinct ,
-
要查詢的記錄,每個欄位都相同,才會去重
-- 1 SELECT * FROM `student`; -- 2 SELECT `name`,`english` FROM student; -- 3 SELECT DISTINCT * FROM `student`; -- 4 SELECT DISTINCT * FROM `student`;
使用運算式對查詢的列進行運算
SELECT * | { column1 | expression,column2 | expression,...}
FROM tablename;
在select陳述句中可使用as陳述句
SELECT column_name [as] 別名 from 表名;
-- 此處as可加可不加,如果不加就必須中間有空格
練習
-
統計每個學生的總分
-
在所有學生總分加10分的情況
-
使用別名表示學生分數,
-- 1 SELECT `name`,(chinese+english+math) FROM `student`; -- 2 SELECT `name`,(chinese+english+math+10) FROM `student`; -- 3 SELECT `name` AS '名字',(chinese+english+math) AS total_score FROM `student`;
在where子句中經常使用的運算子
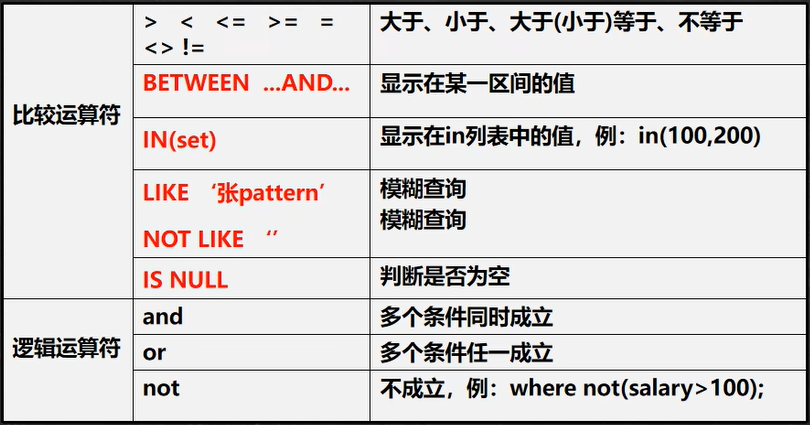
練習
使用where子句,進行過濾查詢select
-
查詢姓名為趙云的學生成績
-
查詢英語成績大于90分的同學
-
查詢總分大于200分的所有同學
-- 1 SELECT * FROM `student` WHERE `name`='趙云'; -- 2 SELECT * FROM `student` WHERE `english`>90; -- 3 SELECT * FROM `student` WHERE (chinese+english+math)>200;
練習2
使用where子句,練習[5min]:
-
查詢math大于60并且(and) id大于4的學生成績
-
查詢英語成績大于語文成績的同學
-
查詢總分大于200分并且數學成績小于語文成績,的姓趙的學生.
-- 1 SELECT * FROM `student` WHERE `math`>60 and `id`>4; -- 2 SELECT * FROM `student` WHERE `english`>`chinese`; -- 3 #韓% 表示名字以韓開頭的就可以,%表示0個到多個字符,可以和Like搭配使用 SELECT * FROM `student` WHERE (chinese+english+math)>200 and `math`<`chinese` and `name` LIKE '趙%';
練習3
-
查詢英語分數在80 - 90之間的同學,
-
查詢數學分數為89,90,91的同學,
-
查詢所有姓李的學生成績,
-
查詢數學分>80,語文分>80的同學,
-
查詢總分為189,190,233的同學,
-
查詢所有姓李或者姓宋的學生成績,
-
查詢數學比語文多30分的同學,
-- 1 SELECT * FROM `student` WHERE `english`>=80 and `english`<=90; SELECT * FROM `student` WHERE `english` BETWEEN 80 and 90;-- between and是一個閉區間,[80,90] -- 2 SELECT * FROM `student` WHERE `math`=89 OR `math`=90 or `math`=91; SELECT * FROM `student` WHERE `math` IN (89,90,91); -- 3 SELECT * FROM `student` WHERE `name` Like '李%'; -- 4 SELECT * FROM `student` WHERE `math`>80 and `chinese`>80; -- 5 SELECT * FROM `student` WHERE (chinese+english+math)=189 OR (chinese+english+math)=190 or (chinese+english+math)=233; SELECT * FROM `student` WHERE (chinese+english+math) in (189,190,233); -- 6 SELECT * FROM `student` WHERE `name` Like '李%' or `name` Like '宋%'; -- 7 SELECT * FROM `student` WHERE `math`-`chinese`>30;
使用order by子句排序查詢結果
SELECT column1, column2, column3...
FROM table
order by column4 asc|desc,column5 asc|desc,...
- Order by指定排序的列,排序的列既可以是表中的列名,也可以是select陳述句后指定的列名,
- Asc升序[默認]、Desc降序
- ORDER BY子句應位于SELECT陳述句的結尾,
練習:
-
對數學成績排序后輸出【升序】,
-
對總分按從高到低的順序輸出
-
對姓李的學生成績[總分]排序輸出(升序)
-- 1 SELECT * FROM `student` ORDER BY `math`; -- 2 #可以使用別名排序 SELECT *,(chinese+english+math) AS total_score FROM `student` ORDER BY total_score DESC; -- 3 SELECT `name`,(chinese+english+math) AS total_score FROM `student` WHERE `name` Like '李%' ORDER BY total_score;
函式
統計函式
合計/統計函式- count
Count回傳行的總數
Select count(*) | count(列名) from table_name
[WHERE where_definition]
練習:
-
統計一個班級共有多少學生?
-
統計數學成績大于90的學生有多少個?
-
統計總分大于250的人數有多少?
-
count(*)和count(列)的區別
-- 1 Select count(*) FROM `student`; -- 2 Select count(*) FROM `student` WHERE `math`>90; -- 3 SELECT count(*) FROM `student` WHERE (chinese+english+math)>250; -- 4 #count(*)和count(列)的區別 -- 解釋: count(*)回傳滿足條件的記錄的行數 -- count(列):統計滿足條件的某列有多少個,但是會排除為null的情況
合計函式-sum
Sum函式回傳滿足where條件的行的和 一般使用在數值列
select sum(列名){, sum(列名)...} from tablename
[WHERE where_definition]
練習
-
統計一個班級數學總成績?
-
統計一個班級語文、英語、數學各科的總成績
-
統計一個班級語文、英語、數學的成績總和
-
統計一個班級語文成績平均分
注意: sum僅對數值起作用,否則沒有意義,
注意:對多列求和,“,”號不能少,
-- 1 SELECT SUM(math) from `student`; -- 2 select sum(chinese),sum(english),sum(math) from `student`; -- 3 SELECT SUM(chinese+english+math) from `student`; -- 4 SELECT SUM(chinese)/count(*) from `student`;
合計函式- avg
AVG函式回傳滿足where條件的一列的平均值
Select avg(列名){,avg(列名)...]from tablename
[WHERE where_definition]
練習:
-
求一個班級數學平均分?
-
求一個班級總分平均分
-- 1 select avg(math) from `student`; -- 2 select avg(chinese+english+math) from `student`;
合計函式-Max/min
Max/min函式回傳滿足where條件的一列的最大/最小值
select max(列名) from tablename
[WHERE where_definition]
練習:
-
求班級最高分和最低分(數值范圍在統計中特別有用)
select max(chinese+english+math),min(chinese+english+math) from `student`;
分組統計GROUP BY和HAVING
使用group by子句對列進行分組[先創建測驗表]
SELECT column1, column2. column3... FROM table
group by column1 [,column2...];
使用having子句對分組后的結果進行過濾
SELECT column1, column2, column3 ...
FROM table
group by column having ...
group by用于對查詢的結果分組統計
having子句用于限制分組顯示結果.(注意:where是對原始每行的資料過濾,having是對經過分組集成的資料進行進行限制,一般和group by配套使用)
練習
先使用下面的指令創建表
CREATE TABLE dept( /*部門表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
);
INSERT INTO dept VALUES(10, 'ACCOUNTING', 'NEW YORK'), (20, 'RESEARCH', 'DALLAS'), (30, 'SALES', 'CHICAGO'), (40, 'OPERATIONS', 'BOSTON');
#創建表EMP雇員
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*編號*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*作業*/
mgr MEDIUMINT UNSIGNED ,/*上級編號*/
hiredate DATE NOT NULL,/*入職時間*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) ,/*紅利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部門編號*/
);
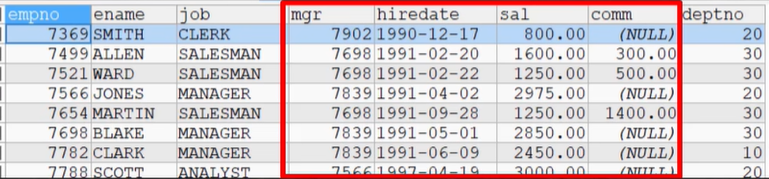
INSERT INTO emp VALUES(7369, 'SMITH', 'CLERK', 7902, '1990-12-17', 800.00,NULL , 20),
(7499, 'ALLEN', 'SALESMAN', 7698, '1991-2-20', 1600.00, 300.00, 30),
(7521, 'WARD', 'SALESMAN', 7698, '1991-2-22', 1250.00, 500.00, 30),
(7566, 'JONES', 'MANAGER', 7839, '1991-4-2', 2975.00,NULL,20),
(7654, 'MARTIN', 'SALESMAN', 7698, '1991-9-28',1250.00,1400.00,30),
(7698, 'BLAKE','MANAGER', 7839,'1991-5-1', 2850.00,NULL,30),
(7782, 'CLARK','MANAGER', 7839, '1991-6-9',2450.00,NULL,10),
(7788, 'SCOTT','ANALYST',7566, '1997-4-19',3000.00,NULL,20),
(7839, 'KING','PRESIDENT',NULL,'1991-11-17',5000.00,NULL,10),
(7844, 'TURNER', 'SALESMAN',7698, '1991-9-8', 1500.00, NULL,30),
(7900, 'JAMES','CLERK',7698, '1991-12-3',950.00,NULL,30),
(7902, 'FORD', 'ANALYST',7566,'1991-12-3',3000.00, NULL,20),
(7934,'MILLER','CLERK',7782,'1992-1-23', 1300.00, NULL,10);
#工資級別表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
);
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
-
如何顯示每個部門的平均工資和最高工資
-
顯示每個部門的每種崗位的平均工資和最低工資
-
顯示平均工資低于2000的部門號和它的平均工資
-- 1 select deptno,avg(sal),max(sal) from emp group by deptno; -- 2 select deptno,job,avg(sal),min(sal) from emp group by deptno,job; -- 3 -- 分析〔寫sql陳述句的思路是化繁為簡,各個擊破] -- 3.1 顯示各個部門的平均工資和部門號 -- 3.2 在1的結果基礎上,進行過濾,保留AVG(sal) <2000 select deptno,avg(sal) from emp group by deptno; select deptno,avg(sal) from emp group by deptno HAVING AVG(sal) <2000;
字串函式
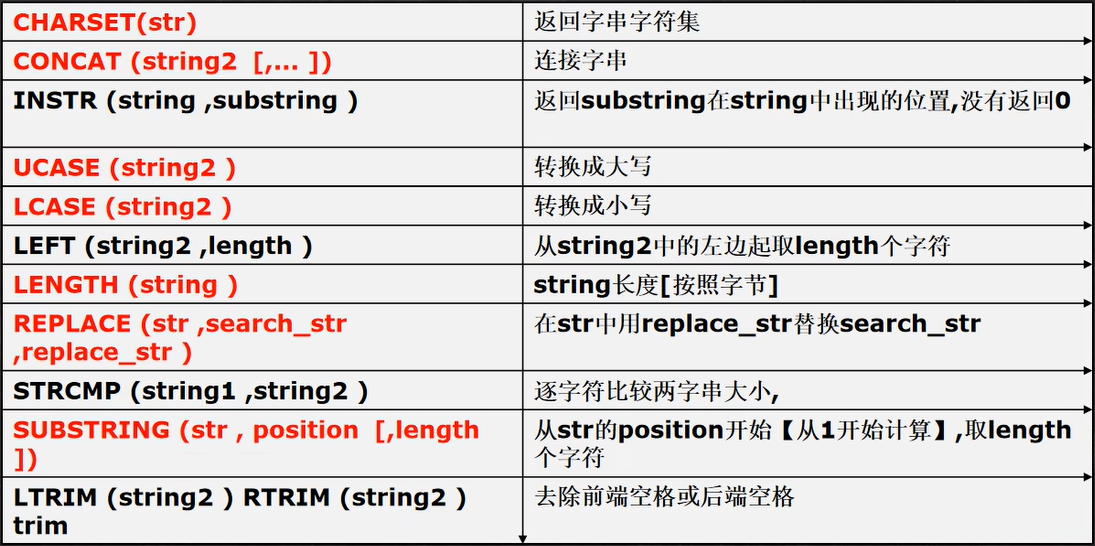
-- 演示字串相關函式的使用 , 使用 emp 表來演示
-- CHARSET(str) 回傳字串字符集
SELECT CHARSET(ename) FROM emp;
-- CONCAT (string2 [,... ]) 連接字串, 將多個列拼接成一列
SELECT CONCAT(ename, ' 作業是 ', job) FROM emp;
-- INSTR (string ,substring ) 回傳 substring 在 string 中出現的位置,沒有則回傳 0
-- 注意:和java不一樣 ,mysql是從1開始計算順序的
-- dual 亞元表, 系統表 可以作為測驗表使用
SELECT INSTR('hanshunping', 'ping') FROM DUAL;
-- UCASE (string2 ) 轉換成大寫
SELECT UCASE(ename) FROM emp;
-- LCASE (string2 ) 轉換成小寫
SELECT LCASE(ename) FROM emp;
-- LEFT (string2 ,length )從 string2 中的左邊起取 length 個字符
-- RIGHT (string2 ,length ) 從 string2 中的右邊起取 length 個字符
SELECT ename,LEFT(ename, 2),RIGHT(ename,2) FROM emp;
-- LENGTH (string )string 長度[按照位元組]
SELECT LENGTH(ename) FROM emp;
-- REPLACE (str ,search_str ,replace_str )
-- 在 str 中用 replace_str 替換所有的 search_str
-- 如果是 manager 就替換成 經理
SELECT ename, REPLACE(job,'MANAGER', '經理') FROM emp;
-- STRCMP (string1 ,string2 ) 逐字符比較兩字串大小(不區分大小寫) 回傳數字0(一樣),-1(string2大),1(string1大)
SELECT STRCMP('hsp', 'jsp') FROM DUAL;#輸出 -1
-- SUBSTRING (str , position [,length ])
-- 從 str 的 position 開始【從 1 開始計算】,取 length 個字符
-- 從 ename 列的第一個位置開始取出 2 個字符
SELECT SUBSTRING(ename, 1, 2) FROM emp;
-- LTRIM (string2) RTRIM (string2 ) TRIM(string)
-- 去除前端空格或后端或前后兩端空格
SELECT LTRIM(' 韓順平教育') FROM DUAL;
SELECT RTRIM('韓順平教育 ') FROM DUAL;
SELECT TRIM(' 韓順平教育 ') FROM DUAL;
練習:
-
以首字母小寫的方式顯示所有員工emp表的姓名
SELECT ename,CONCAT(LCASE(LEFT(`ename`,1)),SUBSTRING(ename,2)) from emp;
數學函式
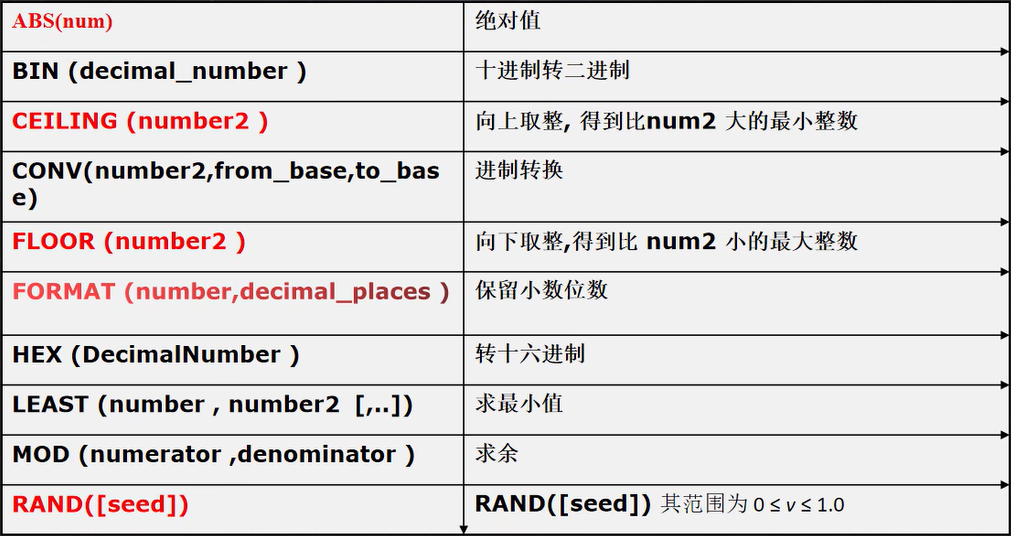
-- 演示數學相關函式
-- ABS(num) 絕對值
SELECT ABS(-10) FROM DUAL;
-- BIN (decimal_number )十進制轉二進制
SELECT BIN(10) FROM DUAL;
-- CEILING (number2 ) 向上取整, 得到 >=num2 的最小整數
SELECT CEILING(-1.1) FROM DUAL;
-- CONV(number2,from_base,to_base) 進制轉換
-- 下面的 8 是十進制的 8, 轉成 2 進制輸出
SELECT CONV(8, 10, 2) FROM DUAL;
-- 下面的 16 是 16 進制的 16, 轉成 10 進制輸出
SELECT CONV(16, 16, 10) FROM DUAL;
-- FLOOR (number2 ) 向下取整,得到比 num2 小的最大整數
SELECT FLOOR(-1.1) FROM DUAL;
-- FORMAT (number,decimal_places ) 保留小數位數(四舍五入)
SELECT FORMAT(78.125458,2) FROM DUAL;
-- HEX (DecimalNumber ) 轉十六進制 (括號內的數是十進制)
SELECT HEX(46) FROM DUAL;#2E
-- LEAST (number , number2 [,..]) 求最小值
SELECT LEAST(0,1, -10, 4) FROM DUAL;
-- MOD (numerator ,denominator ) 求余
SELECT MOD(10, 3) FROM DUAL;
-- RAND([seed]) 回傳亂數 其范圍為 0 ≤ v ≤ 1.0
-- 說明
-- 1. 如果使用 rand() 每次回傳不同的亂數 ,在 0 ≤ v ≤ 1.0
-- 2. 如果使用 rand(seed) 回傳亂數, 范圍 0 ≤ v ≤ 1.0, 如果 seed 不變,該亂數也不變了
SELECT RAND() FROM DUAL;
-- ROUND(number) 四舍五入
select round(5.5);
時間日期
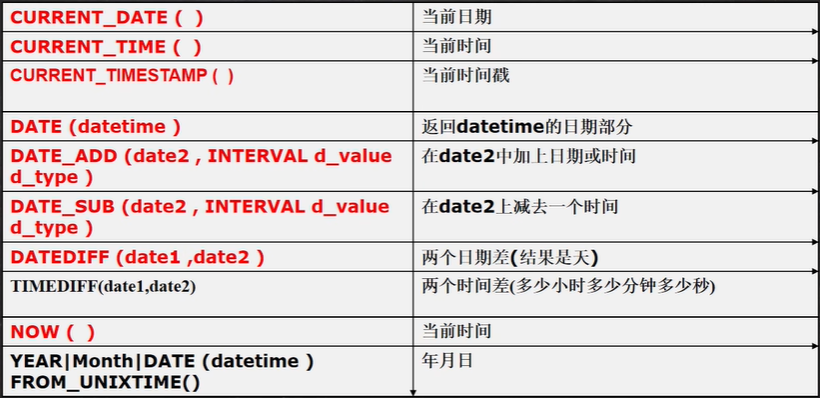
上面函式的細節說明:
- DATE_ADD()中的interval后面可以是year、month、day、hour、minute、second,
- DATE SUB()中的interval后面可以是year、month、day、hour、minute、second,
- DATEDIFF(date1,date2)得到的是天數,而且是date1-date2的天數,因此可以取負數
- DATE、DATE_ADD、DATE_SUB、DATEDIFF這四個函式的日期型別可以是date, datetime或者timestamp
-- 日期時間相關函式【1】
-- CURRENT_DATE ( ) 當前日期
SELECT CURRENT_DATE() FROM DUAL; #2022-09-15
-- CURRENT_TIME ( )當前時間
SELECT CURRENT_TIME() FROM DUAL; #20:23:10
-- CURRENT_TIMESTAMP ( ) 當前時間戳
SELECT CURRENT_TIMESTAMP() FROM DUAL; #2022-09-15 20:23:19
-- NOW( ) 當前時間
-- CURRENT_TIMESTAMP()和NOW()沒區別
SELECT NOW() FROM DUAL; #2022-09-15 20:23:20
-- LAST_DAY(datetime) 回傳datetime當月最后一天的日期
LAST_DAY(NOW()); -- 2022-09-15
實體
-- 創建測驗表 資訊表
CREATE TABLE mes(
id INT ,
content VARCHAR(30),
send_time DATETIME);
-- 添加記錄
INSERT INTO mes VALUES(1, '北京新聞', CURRENT_TIMESTAMP());
INSERT INTO mes VALUES(2, '上海新聞', NOW());
INSERT INTO mes VALUES(3, '廣州新聞', NOW());
SELECT * FROM mes;
-
顯示所有留言資訊,發布日期只顯示日期,不用顯示時間.
-
請查詢在10分鐘內發布的帖子
-
請在mysql 的sql陳述句中求出2011-11-11和1990-1-1相差多少天
-
請用mysql的sql陳述句求出你活了多少天?[練習]
-
如果你能活80歲,求出你還能活多少天.[練習]
-- 日期時間相關函式【2】 -- 1 SELECT id,content,DATE(send_time) FROM mes; -- 2 (兩種方式) select * FROM mes WHERE TIMEDIFF(NOW(),send_time)<'00:10:00'; SELECT * FROM mes WHERE DATE_ADD(send_time, INTERVAL 10 MINUTE) >= NOW(); SELECT * FROM mes WHERE send_time >= DATE_SUB(NOW(), INTERVAL 10 MINUTE) -- 3 SELECT DATEDIFF('2011-11-11','1990-1-1'); -- 4 SELECT DATEDIFF(NOW(), '2000-08-11'); -- 5 SELECT DATEDIFF(DATE_ADD('2000-08-11', INTERVAL 80 YEAR),NOW());
-- 日期時間相關函式【3】
-- YEAR|Month|DAY|DATE (datetime )
SELECT YEAR(NOW()) FROM DUAL;#2022
SELECT MONTH(NOW()) FROM DUAL;#9
SELECT DAY(NOW()) FROM DUAL;#15
SELECT MONTH('2013-11-10');#11
-- unix_timestamp() : 回傳的是 1970-1-1 到現在的秒數
SELECT UNIX_TIMESTAMP() FROM DUAL;
-- FROM_UNIXTIME() : 可以把一個 unix_timestamp 秒數[時間戳],轉成指定格式的時間
-- %Y-%m-%d 格式是規定好的,表示年月日
-- 意義:在開發中,可以存放一個整數,然后表示時間,通過 FROM_UNIXTIME 轉換
SELECT FROM_UNIXTIME(1618483484, '%Y-%m-%d') FROM DUAL;
SELECT FROM_UNIXTIME(1618483100, '%Y-%m-%d %H:%i:%s') FROM DUAL;
加密和系統函式
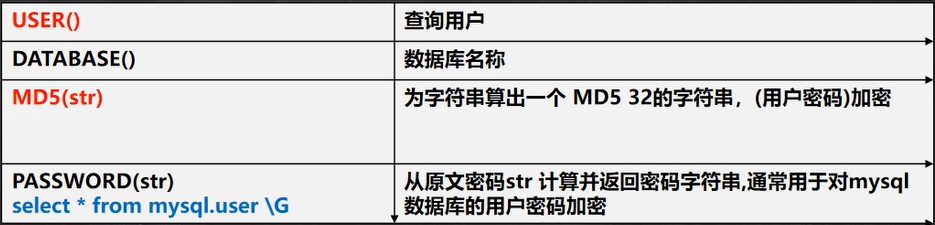
-- 演示加密函式和系統函式
-- USER() 查詢用戶
-- 可以查看登錄到 mysql 的有哪些用戶,以及登錄的 IP
SELECT USER(); -- 用戶@IP 地址
-- DATABASE()查詢當前使用資料庫名稱
SELECT DATABASE();
-- MD5(str) 為字串算出一個 MD5 32 的字串,常用(用戶密碼)加密
-- root 密碼是 hsp -> 加密 md5 -> 在資料庫中存放的是加密后的密碼
SELECT MD5('hsp') FROM DUAL;
SELECT LENGTH(MD5('hsp')) FROM DUAL;
-- 演示用戶表,存放密碼時,是 md5
CREATE TABLE hsp_user(id INT , `name` VARCHAR(32) NOT NULL DEFAULT '', pwd CHAR(32) NOT NULL DEFAULT '');
INSERT INTO hsp_user VALUES(100, '韓順平', MD5('hsp'));
SELECT * FROM hsp_user;
SELECT * FROM hsp_user WHERE `name`='韓順平' AND pwd = MD5('hsp');
-- PASSWORD(str)
-- 加密函式, MySQL 資料庫的用戶密碼就是 PASSWORD 函式加密SELECT PASSWORD('123456') FROM DUAL;
-- 資料庫中存盤的密碼是 *6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
-- select * from mysql.user \G 從原文密碼 str 計算并回傳密碼字串
-- 通常用于對 mysql 資料庫的用戶密碼加密
-- mysql.user 表示 '資料庫.表' 這樣不不需要切換到mysql表再查user
SELECT user,user.authentication_string FROM mysql.user;#可看到用戶名和加密后的密碼
select password('123456'); #*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9 和資料庫中存盤的密碼對應
流程控制
先看兩個需求:
- 查詢emp表,如果comm是null,則顯示0.0
- 如果emp表的job是CLERK則顯示職員,如果是 MANAGER 則顯示經理如果是SALESMAN則顯示銷售人員,其它正常顯示.
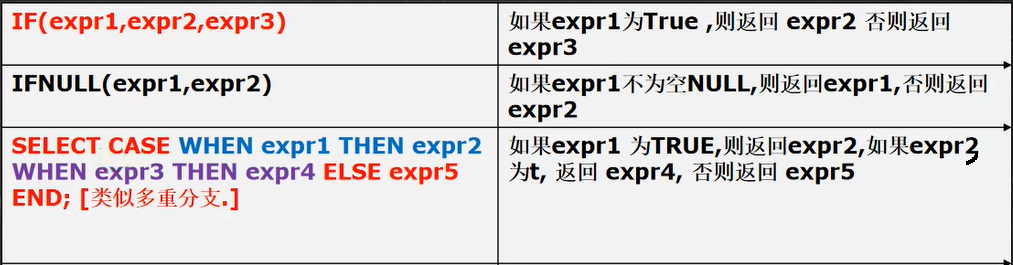
# 演示流程控制陳述句
# IF(expr1,expr2,expr3) 如果 expr1 為 True ,則回傳 expr2 否則回傳 expr3
SELECT IF(TRUE, '北京', '上海') FROM DUAL;
# IFNULL(expr1,expr2) 如果 expr1 為空 NULL,回傳 expr2,否則回傳 expr1
SELECT IFNULL( NULL, '韓順平教育') FROM DUAL;
# SELECT CASE WHEN expr1 THEN expr2 WHEN expr3 THEN expr4 ELSE expr5 END; [類似多重分支.]
# 如果 expr1 為 TRUE,則回傳 expr2,如果 expr2 為 t, 回傳 expr4, 否則回傳 expr5
SELECT CASE
WHEN TRUE THEN 'jack'
WHEN FALSE THEN 'tom'
ELSE 'mary' END; -- jack
練習
- 查詢 emp 表, 如果 comm 是 null , 則顯示 0.0
- 如果 emp 表的 job 是 CLERK 則顯示 職員, 如果是 MANAGER 則顯示經理-- 如果是 SALESMAN 則顯示 銷售人員,其它正常顯示
-- 1
-- 說明,判斷是否為 null 要使用 is null, 判斷不為空 使用 is not
SELECT ename, IF(comm IS NULL , 0.0, comm) FROM emp;
SELECT ename, IFNULL(comm, 0.0) FROM emp;
-- 2
SELECT ename, CASE
WHEN job = 'CLERK' THEN '職員' WHEN job = 'MANAGER' THEN '經理' WHEN job = 'SALESMAN' THEN '銷售人員' ELSE job END AS 'job' FROM emp;
SELECT * FROM emp;
MySQL表查詢--加強
先執行以下陳述句創建表,如果看過函式部分已經創建過(emp、dept、salgrade這三張表)則忽略
CREATE TABLE dept( /*部門表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
);
INSERT INTO dept VALUES(10, 'ACCOUNTING', 'NEW YORK'), (20, 'RESEARCH', 'DALLAS'), (30, 'SALES', 'CHICAGO'), (40, 'OPERATIONS', 'BOSTON');
#創建表EMP雇員
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*編號*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*作業*/
mgr MEDIUMINT UNSIGNED ,/*上級編號*/
hiredate DATE NOT NULL,/*入職時間*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) ,/*紅利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部門編號*/
);
INSERT INTO emp VALUES(7369, 'SMITH', 'CLERK', 7902, '1990-12-17', 800.00,NULL , 20),
(7499, 'ALLEN', 'SALESMAN', 7698, '1991-2-20', 1600.00, 300.00, 30),
(7521, 'WARD', 'SALESMAN', 7698, '1991-2-22', 1250.00, 500.00, 30),
(7566, 'JONES', 'MANAGER', 7839, '1991-4-2', 2975.00,NULL,20),
(7654, 'MARTIN', 'SALESMAN', 7698, '1991-9-28',1250.00,1400.00,30),
(7698, 'BLAKE','MANAGER', 7839,'1991-5-1', 2850.00,NULL,30),
(7782, 'CLARK','MANAGER', 7839, '1991-6-9',2450.00,NULL,10),
(7788, 'SCOTT','ANALYST',7566, '1997-4-19',3000.00,NULL,20),
(7839, 'KING','PRESIDENT',NULL,'1991-11-17',5000.00,NULL,10),
(7844, 'TURNER', 'SALESMAN',7698, '1991-9-8', 1500.00, NULL,30),
(7900, 'JAMES','CLERK',7698, '1991-12-3',950.00,NULL,30),
(7902, 'FORD', 'ANALYST',7566,'1991-12-3',3000.00, NULL,20),
(7934,'MILLER','CLERK',7782,'1992-1-23', 1300.00, NULL,10);
#工資級別表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
);
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
使用where子句
- 如何查找1992.1.1后入職的員工
如何使用like運算子
- %:表示O到多個字符:表示單個字符
- 如何顯示首字符為S的員工姓名和工資
- 如何顯示第三個字符為大寫O的所有員工的姓名和工資
如何顯示沒有上級的雇員的情況
查詢表結構
-- 查詢加強
-- ■ 使用 where 子句
-- ?如何查找 1992.1.1 后入職的員工
-- 老師說明: 在 mysql 中,日期型別可以直接比較, 需要注意格式
SELECT * FROM emp WHERE hiredate > '1992-01-01'
-- ■ 如何使用 like 運算子(模糊)
-- %: 表示 0 到多個任意字符 _: 表示單個任意字符
-- ?如何顯示首字符為 S 的員工姓名和工資
SELECT ename, sal FROM emp WHERE ename LIKE 'S%'
-- ?如何顯示第三個字符為大寫 O 的所有員工的姓名和工資
SELECT ename, sal FROM emp WHERE ename LIKE '__O%'
-- ■ 如何顯示沒有上級的雇員的情況
SELECT * FROM emp WHERE mgr IS NULL; -- 注意這里不能用“=”,要用“is”
-- ■ 查詢表結構
DESC emp;
-- 使用 order by 子句
-- ?如何按照工資的從低到高的順序[升序],顯示雇員的資訊
SELECT * FROM emp ORDER BY sal;
-- ?按照部門號升序而同一部門中的雇員的工資降序排列, 顯示雇員資訊
SELECT * FROM emp ORDER BY deptno ASC , sal DESC;
分頁查詢
-
按雇員的id號升序取出,每頁顯示3條記錄,請分別顯示第一頁,第二頁,第三頁
-
基本語法:select ... limit start, rows
表示從start+1行開始取,取出rows行, start 從0開始計算
練習題:
-
按雇員的id號降序取出,每頁顯示5條記錄,請分別顯示第3頁,第5頁對應的sql陳述句
-- 分頁查詢 -- 第 1 頁 SELECT * FROM emp ORDER BY empno LIMIT 0, 3; -- 第 2 頁 SELECT * FROM emp ORDER BY empno LIMIT 3, 3; -- 第 3 頁 SELECT * FROM emp ORDER BY empno LIMIT 6, 3; -- 導一個公式 SELECT * FROM emp ORDER BY empno LIMIT 每頁顯示記錄數 * (第幾頁-1) , 每頁顯示記錄數;
分組函式和分組子句group by
-
顯示每種崗位的雇員總數、平均工資,
-
顯示雇員總數,以及獲得補助(comm非空)的雇員數,
-
顯示管理者的總人數,(即mgr有多少種)
-
顯示雇員工資的最大差額,
-- 1 select job,count(*),avg(sal) from emp group by job; -- 2 -- 思路: 獲得補助的雇員數 就是 comm 列為非 null, 就是 count(列).如果此處的值為null,不會統計 select count(*),count(comm) from emp; -- 擴展要求:統計沒有獲得補助的雇員數 SELECT COUNT(*), COUNT(IF(comm IS NULL, 1, NULL)) FROM emp; SELECT COUNT(*), COUNT(*) - COUNT(comm) FROM emp -- 3 SELECT COUNT(DISTINCT mgr) FROM emp; -- 4 SELECT MAX(sal) - MIN(sal) FROM emp;
資料分組的總結
如果select陳述句同時包含有where,group by ,having , limit,order by那么他們的順序是where,group by,having , order by,limit
SELECT column1, column2, column3... FROM table
where where_definition
group by column
having condition
order by column
limit start, rows;
應用案例:
-
請統計各個部門的平均工資,并且是大于 1000 的,并且按照平均工資從高到低排序,取出前兩行記錄
select deptno,avg(sal) as avg_sal from emp group by deptno having avg_sal>1000 order by avg_sal desc limit 0,2;
MySQL多表查詢
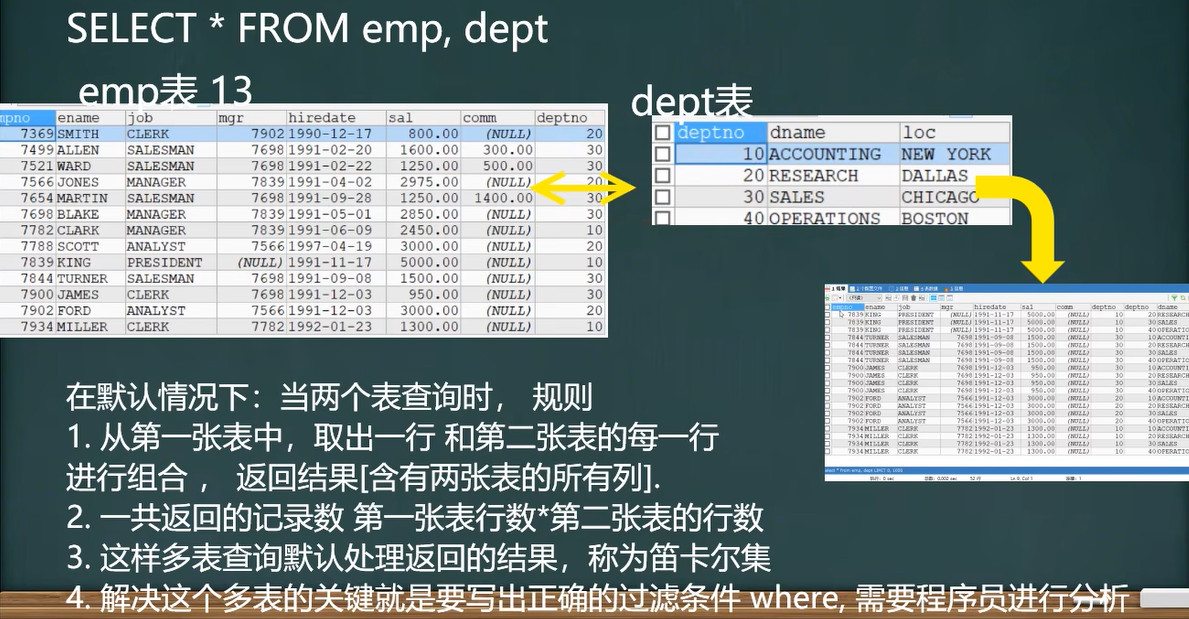
多表查詢是指基于兩個和兩個以上的表查詢.在實際應用中,查詢單個表可能不能滿足你的需求,(如下面的課堂練習),需要使用到(dept表和emp表)
多表查詢練習
-
顯示雇員名,雇員工資及所在部門的名字【笛卡爾集】
小技巧:多表查詢的條件不能少于表的個數-1,否則會出現笛卡爾集?
-
如何顯示部門號為10的部門名、員工名和工資
-
顯示各個員工的姓名,工資,及其工資的級別
-- 多表查詢 -- 1. 顯示雇員名,雇員工資及所在部門的名字 【笛卡爾集】 /* 分析 1. 雇員名,雇員工資 來自 emp 表 2. 部門的名字 來自 dept 表 3. 需求對 emp 和 dept 查詢 ename,sal,dname,deptno 4. 當我們需要指定顯示某個表的列時,需要 表名.列名 */ SELECT ename,sal,dname,emp.deptno FROM emp, dept WHERE emp.deptno = dept.deptno; SELECT * FROM emp; SELECT * FROM dept; SELECT * FROM salgrade; -- 小技巧:多表查詢的條件不能少于 表的個數-1, 否則會出現笛卡爾集 -- 2. 如何顯示部門號為 10 的部門名、員工名和工資 SELECT ename,sal,dname,emp.deptno FROM emp, dept WHERE emp.deptno = dept.deptno AND emp.deptno = 10 -- 3.顯示各個員工的姓名,工資,及其工資的級別 -- 思路 姓名,工資 來自 emp 13 -- 工資級別 salgrade 5 -- 寫 sql , 先寫一個簡單,然后加入過濾條件... select ename, sal, grade from emp , salgrade where sal between losal and hisal; -- 練習:顯示雇員名(ename),雇員工資(sal)及所在部門的名字(dname),并按部門排序[降序排]. select ename,sal,dname from emp,dept where emp.deptno=dept.deptno order by dname desc;
自連接
自連接是指在同一張表的連接查詢[將同一張表看做兩張表],
思考題:
-
顯示公司員工和他的上級的名字(給表取別名,使其能當兩張表用)
select worker.ename as '員工名',boss.ename as '上級' from emp worker,emp boss where worker.mgr=boss.empno;
子查詢
什么是子查詢:
子查詢是指嵌入在其它sql陳述句中的select陳述句,也叫嵌套查詢
單行子查詢:
單行子查詢是指只回傳一行資料的子查詢陳述句
請思考:如何顯示與SMITH同一部門的所有員工?
多行子查詢:
多行子查詢指回傳多行資料的子查詢 使用關鍵字in
-- 子查詢的演示
-- 單行子查詢
-- 請思考:如何顯示與 SMITH 同一部門的所有員工?
/*
1. 先查詢到 SMITH 的部門號得到
2. 把上面的 select 陳述句當做一個子查詢來使用
*/
SELECT deptno FROM emp WHERE ename = 'SMITH' ;
-- 下面的答案. SELECT *
FROM emp WHERE deptno = (
SELECT deptno FROM emp WHERE ename = 'SMITH' );
-- 多行子查詢
-- 練習:如何查詢和部門 10 的作業相同的雇員的
-- 名字、崗位、工資、部門號, 但是不含 10 號部門自己的雇員.
/*
1. 查詢到 10 號部門有哪些作業
2. 把上面查詢的結果當做子查詢使用
*/
select distinct job from emp where deptno=10;
select ename, job,sal,deptno from emp where job in (
select distinct job from emp where deptno=10) and
deptno != 10;
子查詢當做臨時表使用
練習題:
先使用ecshop.sql檔案創建資料庫---- 下載
-
查詢ecshop中各個類別(cat_id)中,價格最高的商品.結果 如下:
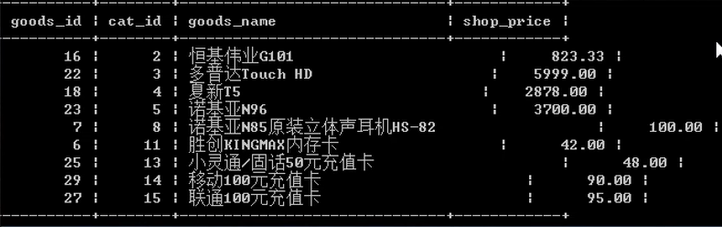
提示,可以將子查詢當做一張臨時表使用
select * from ecshop.ecs_goods; select goods_id,cat_id,goods_name,shop_price from ecshop.ecs_goods; -- 1 -- 先得到 各個類別中,價格最高的商品 max + group by cat_id, 當做臨時表 select cat_id,Max(shop_price) from ecshop.ecs_goods group by cat_id; -- 把子查詢當做一張臨時表可以解決很多很多復雜的查詢 select goods_id,cat_id,goods_name,shop_price from ecshop.ecs_goods; select temp.cat_id,goods_id,goods_name,shop_price from ( select cat_id,Max(shop_price) as max_price from ecshop.ecs_goods group by cat_id ) temp,ecs_goods where temp.cat_id=ecs_goods.cat_id and temp.max_price=ecs_goods.shop_price;
在多行子查詢中使用all運算子
請思考:如何顯示工資比部門30的所有員工的工資高的員工的姓名工資和部門號
-- 使用max()
select ename,sal,deptno from emp where sal >(select max(sal) from emp where deptno=30);
-- 使用all()
select ename,sal,deptno from emp where sal >all(select sal from emp where deptno=30);
在多行子查詢中使用any運算子
請思考:如何顯示工資比部門30的其中一個員工的工資高的員工的姓名、工資和部門號
-- 使用min()
select ename,sal,deptno from emp where sal >(select min(sal) from emp where deptno=30);
-- 使用any()
select ename,sal,deptno from emp where sal >any(select sal from emp where deptno=30);
多列子查詢
多列子查序則是指查詢回傳多個列資料的子查詢陳述句
(欄位1,欄位2…)=(select 欄位1,欄位2 from ...)
練習題:
-
請查詢student表中和宋江數學,英語,語文完全相同的學生
-
請思考如何查詢emp表中與allen的部門和崗位完全相同的所有雇員(并且不含smith本人)
-- 1 select math,english,chinese from student where name='宋江'; select * from student where (math,english,chinese)=(select math,english,chinese from student where name='宋江') and name!='宋江'; -- 2 select deptno,job from emp where LCASE(ename)='allen'; SELECT * FROM emp WHERE (deptno,job)=(select deptno,job from emp where LCASE(ename)='allen') and LCASE(ename)!='allen';
課后練習(先自己做)
- emp表中,查找每個部門工資高于本部門平均工資的人的資料
- emp表中,查找每個部門工資最高的人的詳細資料
- 查詢每個部部門的資訊(包括:部門名,編號,地址(dept表中))和人員數量,
-- 1
select deptno,avg(sal) as avg_sal from emp group by deptno;
select ename,sal,avg_sal,temp.deptno from emp,(select deptno,avg(sal) as avg_sal from emp group by deptno) temp where emp.deptno=temp.deptno and emp.sal>avg_sal;
-- 2
select deptno,max(sal) as max_sal from emp group by deptno;
select empno,ename,job,sal,emp.deptno from emp,(select deptno,max(sal) as max_sal from emp group by deptno) temp where emp.deptno=temp.deptno and sal=max_sal;
-- 3
-- 表名.* 表示將該表所有列都顯示出來, 可以簡化 sql 陳述句
select deptno,count(*) as count_dept from emp group by deptno;
select dept.*,count_dept from dept,(select deptno,count(*) as count_dept from emp group by deptno) temp where dept.deptno=temp.deptno;
合并查詢
有時在實際應用中,為了合并多個select陳述句的結果,可以使用集合運算子號
-
union all
該運算子用于取得兩個結果集的并集,當使用該運算子時,不會取消重復行,(注意:可以理解為把第二個表的內容接在第一個表的下面,不需要資料型別一致,但列數必須相同)
select ename,sal,job from emp where sal>2500 union select ename,job,sal from emp where job='MANAGER'; -
union
該操作賦與union all相似,但是會自動去掉結果集中重復行
select ename,sal,job from emp where sal>2500 union all select ename,sal,job from emp where job='manager';
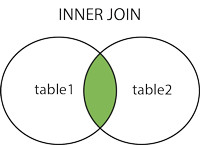
mysql表內連接
select ... from 表1 [inner] join 表2 on 條件
-- inner加不加都一樣
獲取兩個表中欄位匹配關系的記錄,
個人認為內連接用處不大,它能處理的問題用之前的自連接知識也能處理,
mysql表外連接
提出一個問題
-
前面我們學習的查詢,是利用where子句對兩張表或者多張表,形成的笛卡爾積進行篩選,根據關聯條件,顯示所有匹配的記錄,匹配不上的,不顯示
-
比如:列出部門名稱和這些部門的員工名稱和作業,同時要求顯示出那些沒有員工的部門,
-
使用我們學習過的多表查詢的SQL,看看效果如何?
SELECT dname, ename, job FROM emp, dept WHERE emp.deptno = dept.deptno; -- 因為dept.deptno為40時,其中沒有員工,“emp.deptno = dept.deptno”就會因為emp表中沒有deptno為40的員工,導致 不會顯示沒有員工的部門,
外連接
-
左外連接
如果左側的表完全顯示我們就說是左外連接
select ... from 表1 left join 表2 on 條件 [表1就是左表 表2就是右表]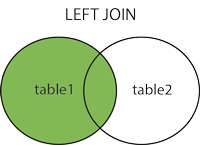
-
右外連接
如果右側的表完全顯示我們就說是右外連接
select ... from 表1 right join 表2 on 條件 [表1:就是左表 表2:就是右表]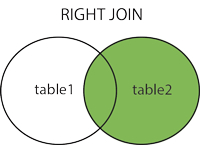
先創建表:
-- 創建 stu
/*
id name
1 Jack
2 Tom
3 Kity
4 nono
*/
CREATE TABLE stu (id INT, `name` VARCHAR(32));
INSERT INTO stu VALUES(1, 'jack'),(2,'tom'),(3, 'kity'),(4, 'nono');
SELECT * FROM stu;
-- 創建 exam
/*
id grade
1 56
2 76
11 8
*/
CREATE TABLE exam( id INT, grade INT);
INSERT INTO exam VALUES(1, 56),(2,76),(11, 8);
SELECT * FROM exam;
使用
-
使用左連接---(顯示所有人的成績,如果沒有成績,也要顯示該人的姓名和id號,成績顯示為空)
-
使用右外連接---(顯示所有成績,如果沒有名字匹配,顯示空)
-- 1 -- 使用左連接 -- (顯示所有人的成績,如果沒有成績,也要顯示該人的姓名和 id 號,成績顯示為空)SELECT `name`, stu.id, grade FROM stu, examWHERE stu.id = exam.id; -- 改成左外連接 SELECT `name`, stu.id, grade FROM stu LEFT JOIN exam ON stu.id = exam.id; -- 2 -- 使用右外連接(顯示所有成績,如果沒有名字匹配,顯示空) -- 即:右邊的表(exam) 和左表沒有匹配的記錄,也會把右表的記錄顯示出來 SELECT `name`, stu.id, grade FROM stu RIGHT JOIN exam ON stu.id = exam.id; -- 自己練習: -- 列出部門名稱和這些部門的員工資訊(名字和作業),同時列出那些沒有員工的部門名,5min -- 1.使用左外連接實作 -- 2.使用右外連接實作 select dname,ename,job from dept left join emp on emp.deptno=dept.deptno; select dname,ename,job from emp right join dept on emp.deptno=dept.deptno;
表復制和表去重
表復制
-- 表的復制
-- 為了對某個 sql 陳述句進行效率測驗,我們需要海量資料時,可以使用此法為表創建海量資料
CREATE TABLE my_tab01( id INT, `name` VARCHAR(32), sal DOUBLE, job VARCHAR(32), deptno INT);
DESC my_tab01;
SELECT * FROM my_tab01;
-- 演示如何自我復制
-- 1. 先把 emp 表的記錄復制到 my_tab01
INSERT INTO my_tab01(id, `name`, sal, job,deptno)
SELECT empno, ename, sal, job, deptno FROM emp;
-- 2. 自我復制
INSERT INTO my_tab01 SELECT * FROM my_tab01;-- 自我復制, 如果多次使用,最后資料量會很大
SELECT COUNT(*) FROM my_tab01;
表去重(面試題)
-- 如何洗掉掉一張表重復記錄
-- 1. 先創建一張表 my_tab02,
-- 2. 讓 my_tab02 有重復的記錄
CREATE TABLE my_tab02 LIKE emp; -- 這個陳述句 把 emp 表的結構(列),復制到 my_tab02
DESC my_tab02;
INSERT INTO my_tab02 SELECT * FROM emp;
SELECT * FROM my_tab02;
-- 3. 考慮去重 my_tab02 的記錄
/*
思路
(1) 先創建一張臨時表 my_tmp , 該表的結構和 my_tab02 一樣
(2) 把 my_tmp 的記錄 通過 distinct 關鍵字 處理后 把記錄復制到 my_tmp
(3) 清除掉 my_tab02 記錄
(4) 把 my_tmp 表的記錄復制到 my_tab02
(5) drop 掉 臨時表 my_tmp
*/
-- (1) 先創建一張臨時表 my_tmp , 該表的結構和 my_tab02 一樣
create table my_tmp like my_tab02;
-- (2) 把 my_tmp 的記錄 通過 distinct 關鍵字 處理后 把記錄復制到 my_tmp
insert into my_tmp select distinct * from my_tab02;
-- (3) 清除掉 my_tab02 記錄
delete from my_tab02;
-- (4) 把 my_tmp 表的記錄復制到 my_tab02
insert into my_tab02 select * from my_tmp;
-- (5) drop 掉 臨時表 my_tmp
drop table my_tmp;
select * from my_tab02;
約束
約束用于確保資料庫的資料滿足特定的商業規則,在mysql中,約束包括: not null,unique,primary key,foreign key,和check五種.
primary key(主鍵)
primary key(主鍵)-基本使用
欄位名 欄位型別 primary key
用于唯一的標示表行的資料,當定義主鍵約束后,該列不能重復
-- 主鍵使用
-- id name email
CREATE TABLE t17
(id INT PRIMARY KEY, -- 表示 id 列是主鍵
`name` VARCHAR(32),
email VARCHAR(32));
-- 主鍵列的值是不可以重復
INSERT INTO t17 VALUES(1, 'jack', '[email protected]');
INSERT INTO t17 VALUES(2, 'tom', '[email protected]');
INSERT INTO t17 VALUES(1, 'hsp', '[email protected]');
SELECT * FROM t17;
-- 主鍵使用的細節討論
-- primary key 不能重復而且不能為 null,
INSERT INTO t17 VALUES(NULL, 'hsp', '[email protected]');
-- 一張表最多只能有一個主鍵, 但可以是復合主鍵(比如 id+name)
CREATE TABLE t18
(id INT PRIMARY KEY, -- 表示 id 列是主鍵
`name` VARCHAR(32) PRIMARY KEY, -- 錯誤的
email VARCHAR(32));
-- 演示復合主鍵 (id 和 name 做成復合主鍵)
CREATE TABLE t18
(id INT , `name` VARCHAR(32),
email VARCHAR(32), PRIMARY KEY (id, `name`) -- 這里就是復合主鍵
);
INSERT INTO t18 VALUES(1, 'tom', '[email protected]');
INSERT INTO t18 VALUES(1, 'jack', '[email protected]');
INSERT INTO t18 VALUES(1, 'tom', '[email protected]'); -- 這里就違反了復合主鍵
SELECT * FROM t18;
-- 主鍵的指定方式 有兩種
-- 1. 直接在欄位名后指定:欄位名 primakry key
-- 2. 在表定義最后寫 primary key(列名);
CREATE TABLE t19(id INT , `name` VARCHAR(32) PRIMARY KEY, email VARCHAR(32));
CREATE TABLE t20(id INT , `name` VARCHAR(32) , email VARCHAR(32), PRIMARY KEY(`name`)); -- 在表定義最后寫 primary key(列名)
-- 使用 desc 表名,可以看到 primary key 的情況
DESC t20 -- 查看 t20 表的結果,顯示約束的情況
DESC t18
primary key(主鍵)-細節說明
-
primary key不能重復而且不能為null,
-
一張表最多只能有一個主鍵,但可以是復合主鍵
-
主鍵的指定方式有兩種
直接在欄位名后指定:欄位名primary key
在表定義最后寫primary key(列名);
-
使用desc表名,可以看到primary key的情況
-
提醒:在實際開發中,每個表往往都有主鍵!
not nulI(非空)
如果在列上定義了not null,那么當插入資料時,必須為列提供資料,
欄位名 欄位型別 not null
unique(唯一)
當定義了唯一約束后,該列值是不能重復的.,
欄位名 欄位型別 unique
unique細節(注意):
- 如果沒有指定not null,則unique欄位可以有多個null
- 一張表可以有多個unique欄位
-- unique 的使用
CREATE TABLE t21
(id INT UNIQUE, -- 表示 id 列是不可以重復的.
`name` VARCHAR(32) , email VARCHAR(32));
INSERT INTO t21 VALUES(1, 'jack', '[email protected]');
INSERT INTO t21 VALUES(1, 'tom', '[email protected]');
-- unqiue 使用細節
-- 1.如果沒有指定 not null , 則 unique 欄位可以有多個 null -- 如果一個列(欄位), 是 unique not null 使用效果類似 primary key
INSERT INTO t21 VALUES(NULL, 'tom', '[email protected]');
SELECT * FROM t21;
-- 2. 一張表可以有多個 unique 欄位
CREATE TABLE t22(id INT UNIQUE , -- 表示 id 列是不可以重復的.
`name` VARCHAR(32) UNIQUE , -- 表示 name 不可以重復
email VARCHAR(32));
DESC t22;
foreign key(外鍵)
foreign key (本表欄位名) references 主表名(主鍵名或unique欄位名)
用于定義主表和從表之間的關系:外鍵約束要定義在從表上,主表則必須具有主鍵約束或是unique約束.當定義外鍵約束后,要求外鍵列資料必須在主表的主鍵列存在或是為null(學生/班級圖示)
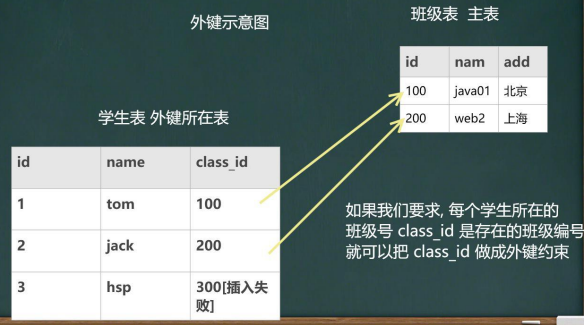
-- 外鍵演示
-- 創建 主表 my_class
CREATE TABLE my_class (
id INT PRIMARY KEY , -- 班級編號
`name` VARCHAR(32) NOT NULL DEFAULT '');
-- 創建 從表 my_stu
CREATE TABLE my_stu (
id INT PRIMARY KEY , -- 學生編號
`name` VARCHAR(32) NOT NULL DEFAULT '',
class_id INT , -- 學生所在班級的編號
-- 下面指定外鍵關系
FOREIGN KEY (class_id) REFERENCES my_class(id));
-- 測驗資料
INSERT INTO my_class VALUES(100, 'java'), (200, 'web');
INSERT INTO my_class VALUES(300, 'php');
SELECT * FROM my_class;
INSERT INTO my_stu VALUES(1, 'tom', 100);
INSERT INTO my_stu VALUES(2, 'jack', 200);
INSERT INTO my_stu VALUES(3, 'hsp', 300);
INSERT INTO my_stu VALUES(4, 'mary', 400); -- 這里會失敗...因為 400 班級不存在
INSERT INTO my_stu VALUES(5, 'king', NULL); -- 可以, 外鍵 沒有寫 not null
SELECT * FROM my_class;
DELETE FROM my_class WHERE id = 100;-- 一旦建立主外鍵的關系,資料不能隨意洗掉了
foreign key(外鍵)—細節說明
- 外鍵指向的表的欄位,要求是primary key或者是unique
- 表的型別是innodb,這樣的表才支持外鍵
- 外鍵欄位的型別要和主鍵欄位的型別一致(長度可以不同)
- 外鍵欄位的值,必須在主鍵欄位中出現過,或者為null [前提是外鍵欄位允許為null]
- 一旦建立主外鍵的關系,資料不能隨意洗掉了.
check【了解就行】
列名 型別 check (check條件)
用于強制行資料必須滿足的條件,假定在sal列上定義了check約束,要求sal列值在1000~2000之間如果不在1000 ~2000之間就會提示出錯,
oracle和sql server均支持check ,但是mysql5.7目前還不支持check ,只做語法校驗,但不會生效,
-- 演示 check 的使用
-- mysql5.7 目前還不支持 check ,只做語法校驗,但不會生效
-- 了解
-- 學習 oracle, sql server, 這兩個資料庫是真的生效.
-- 測驗
CREATE TABLE t23 (
id INT PRIMARY KEY, `name` VARCHAR(32) ,
sex VARCHAR(6) CHECK (sex IN('man','woman')),
sal DOUBLE CHECK ( sal > 1000 AND sal < 2000)); -- 添加資料
INSERT INTO t23 VALUES(1, 'jack', 'mid', 1);-- 不會報錯
SELECT * FROM t23;-- check沒有生效
商店售貨系統表設計案例【先自己練,再看對答案】
現有一個商店的資料庫shop_db,記錄客戶及其購物情況,由下面三個表組成:
商品goods(商品號goods_id,商品名goods_name,單價unitprice,商品類別category,供應商provider);
客戶customer(客戶號customer_id,姓名name,住址address,電郵email,性別sex,身份證card_ld);
購買purchase(購買訂單號order_id,客戶號customer_id,商品號goods_id,購買數量nums);
建表,在定義中要求宣告[進行合理設計]:
-
每個表的主外鍵;
-
客戶的姓名不能為空值;
-
電郵不能夠重復;
-
客戶的性別[男|女] check 列舉..
-
單價unitprice在1.0 - 9999.99之間 check
create table goods(goods_id int primary key,goods_name varchar(50),unitprice double check(unitprice>=1.0 and unitprice<=9999.99),category varchar(20),provider varchar(20)); create table customer(customer_id int primary key,name varchar(10) not null,address varchar(30),email varchar(30) unique,sex enum('男','女'),card_ld char(18)); create table purchase(order_id int primary key,customer_id int,goods_id int,nums int,foreign key (customer_id) references customer(customer_id),foreign key (goods_id) references goods(goods_id));
自增長
自增長基本介紹一個問題
在某張表中,存在一個id列(整數),我們希望在添加記錄的時候,該列從1開始,自動的增長,怎么處理?
欄位名 整數型別 primary key auto_increment
添加自增長的欄位的方式
insert into xxx(欄位1,欄位2...) values(null,'值'...);
insert into xxx(欄位2...) values('值1','值2'...);
insert into xxx values(null,'值1'...);
自增長使用細節
- 一般來說自增長是和primary key配合使用的
- 自增長也可以單獨使用[但是需要配合一個unique]
- 自增長修飾的欄位為整數型的(雖然小數也可以但是非常非常少這樣使用)
- 自增長默認從1開始,你也可以通過如下命令修改:alter table 表名 auto_increment = 新的開始值;
- 建議:如果你添加資料時,給自增長欄位(列)指定的有值,則以指定的值為準,如果指定了自增長,一般來說,就按照自增長的規則來添加資料,
-- 演示自增長的使用
-- 創建表
CREATE TABLE t24(id INT PRIMARY KEY AUTO_INCREMENT, email VARCHAR(32)NOT NULL DEFAULT '',`name` VARCHAR(32)NOT NULL DEFAULT '');
DESC t24;
-- 測驗自增長的使用
INSERT INTO t24 VALUES(NULL, '[email protected]', 'tom');
INSERT INTO t24 (email, `name`) VALUES('[email protected]', 'hsp');
INSERT INTO t24 VALUES(8,'[email protected]', 'hsp');-- 可以在自增長的位置插入該列不存在的int值,但不推薦,實際情況不會這樣用,會出現一系列問題
SELECT * FROM t24;
-- 修改默認的自增長開始值
CREATE TABLE t25(id INT PRIMARY KEY AUTO_INCREMENT,
email VARCHAR(32)NOT NULL DEFAULT '',
`name` VARCHAR(32)NOT NULL DEFAULT '');
ALTER TABLE t25 AUTO_INCREMENT = 100;
INSERT INTO t25 VALUES(NULL, '[email protected]', 'mary');
INSERT INTO t25 VALUES(666, '[email protected]', 'hsp');
SELECT * FROM t25;
索引
說起提高資料庫性能,索引是最物美價廉的東西了,不用加記憶體,不用改程式,不用調sql,查詢速度就可能提高百倍干倍,
這里我們舉例說明索引的好處【構建海量表8000000】(快速體驗案例index.sql)
先執行以下陳述句創建資料庫tmp (注意有八百萬條資料,大概需要花費二十分鐘時間,占用600M的空間)
-- 創建測驗資料庫 tmp
CREATE DATABASE tmp;
先切換到tmp資料庫再執行以下陳述句
CREATE TABLE dept( /*部門表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ;
#創建表EMP雇員
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*編號*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*作業*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上級編號*/
hiredate DATE NOT NULL,/*入職時間*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) NOT NULL,/*紅利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部門編號*/
) ;
#工資級別表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
);
#測驗資料
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
delimiter $$
#創建一個函式,名字 rand_string,可以隨機回傳我指定的個數字串
create function rand_string(n INT)
returns varchar(255) #該函式會回傳一個字串
begin
#定義了一個變數 chars_str, 型別 varchar(100)
#默認給 chars_str 初始值 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
# concat 函式 : 連接函式mysql函式
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
#這里我們又自定了一個函式,回傳一個隨機的部門號
create function rand_num( )
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
#創建一個存盤程序, 可以添加雇員
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
#set autocommit =0 把autocommit設定成0
#autocommit = 0 含義: 不要自動提交
set autocommit = 0; #默認不提交sql陳述句
repeat
set i = i + 1;
#通過前面寫的函式隨機產生字串和部門編號,然后加入到emp表
insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
#commit整體提交所有sql陳述句,提高效率
commit;
end $$
#添加8000000資料
call insert_emp(100001,8000000)$$
#命令結束符,再重新設定為;
delimiter ;
索引效果
SELECT COUNT(*) FROM emp; -- 在沒有創建索引時,我們的查詢一條記錄
SELECT * FROM emp WHERE empno = 1234567 -- 我的電腦的查詢時間為6.329s
-- 使用索引來優化一下, 體驗索引的牛
-- 在沒有創建索引前 , emp.ibd 檔案大小 是 524m
-- 創建索引后 emp.ibd 檔案大小 是 655m [索引本身也會占用空間.]
-- 創建 ename 列索引,emp.ibd 檔案大小 是 827m
-- empno_index 索引名稱
-- ON emp (empno) : 表示在 emp 表的 empno 列創建索引
CREATE INDEX empno_index ON emp (empno);-- 耗時22.726s
-- 創建索引后, 查詢的速度如何
SELECT * FROM emp WHERE empno = 1234578; -- 0.023s 原來是 6.329s
-- 創建索引后,只對創建了索引的列有效
SELECT * FROM emp WHERE ename = 'PjDlwy'; -- 沒有在 ename 創建索引時,時間 7.948s
CREATE INDEX ename_index ON emp (ename); -- 在 ename 上創建索引
SELECT * FROM emp WHERE ename = 'PjDlwy';-- 0.029S
索引的原理
沒有索引為什么會慢? 因為全表掃描.
使用索引為什么會快? 形成一個索引的資料結構,比如二叉樹(例:進行n次比較最多能夠覆寫范圍2n-1個)
索引的代價
- 磁盤占用
- 對表內容的 增、刪、改 陳述句的效率影響(會對索引進行修改維護,對速度有影響,)
告訴你,在我們實際專案中,select[90%]多還是update,delete,insert[10%]操作多?
索引的型別
-
主鍵索引,主鍵自動的為主索引(型別Primary key)
-
唯一索引(UNIQUE)
-
普通索引(INDEX)
-
全文索引 (FULLTEXT) [適用于MylSAM]
一般開發,不使用mysql自帶的全文索引(因為比較拉胯),而是使用:全文搜索Solr和 ElasticSearch (ES)
索引使用
注意:約束中的primary key(主鍵)和unique(唯一)就是主鍵索引和唯一索引,創建表時如果設定了主鍵或unique,也就是創建了此處的主鍵索引或唯一索引
-
添加索引(唯一索引/普通索引)
create [UNIQUE] index index_name on tbl_name (col_name [(length)][ASC|DESC],...); alter table table_name ADD [UNIQUE] INDEX [index_name] (index_col_name,...); -
添加主鍵(索引)
ALTER TABLE 表名 ADD PRIMARY KEY(列名,…); -
洗掉索引(唯一索引/普通索引)
DROP INDEX index_name ON tbl_name; alter table table_name drop index index_name; -
洗掉主鍵索引 比較特別:
洗掉索引也就是洗掉了約束中的主鍵,
alter table t_b drop primary key; -
查詢索引(三種方式)
show index(es) from table_name;-- 加不加es結果都一樣 show keys from table_name; desc table_Name;-- 不推薦,不能顯示詳細資訊
演示:
-- 演示 mysql 的索引的使用
-- 創建索引
CREATE TABLE t25 (id INT,`name` VARCHAR(32));
-- 查詢表是否有索引
SHOW INDEXES FROM t25;
-- 添加索引
-- 添加唯一索引
CREATE UNIQUE INDEX id_index ON t25 (id);
-- 添加普通索引方式1
CREATE INDEX id_index ON t25 (id);
-- 如何選擇
-- 1. 如果某列的值,是不會重復的,則優先考慮使用 unique 索引, 否則使用普通索引
-- 添加普通索引方式2
ALTER TABLE t25 ADD INDEX id_index (id);
-- 添加主鍵索引
CREATE TABLE t26 (id INT , `name` VARCHAR(32));
ALTER TABLE t26 ADD PRIMARY KEY (id);
SHOW INDEX FROM t25;
-- 洗掉索引(非主鍵索引)
DROP INDEX id_index ON t25;
-- 洗掉主鍵索引(同時也會洗掉此表的主鍵約束)
ALTER TABLE t26 DROP PRIMARY KEY
-- 修改索引: 先洗掉,再添加新的索引
-- 查詢索引
-- 1. 方式
SHOW INDEX FROM t25
-- 2. 方式
SHOW INDEXES FROM t25
-- 3. 方式
SHOW KEYS FROM t25
-- 4 方式 (不推薦)
DESC t25 -- 能在顯示結果的Key列看到索引,但不能看到詳細資訊
練習題:
-
創建一張訂單表order (id號,商品名,訂購人,數量).要求id號為主鍵,請使用2種方式來創建主鍵.(提示:為練習方便,可以是order1 , order2)
-
創建一張特價菜譜表menu (id號,菜譜名,廚師,點餐人身份證,價格).要求id號為主鍵,點餐人身份證是unique請使用兩種方式來創建unique.(提示:為練習方便,可以是menu1 , menu2)
-
創建一張運動員表sportman (id號,名字,特長).要求id號為主鍵,
名字為普通索引,請使用兩種方式來創建索引(提示:為練習方便,可以是不同表名sportman1 , sportman2)-- 1 CREATE TABLE `order1`(id int primary key,name varchar(50),cou int); CREATE TABLE `order2`(id int,name varchar(50),cou int); alter table order2 add primary key(id); -- 2 create table menu1(id int primary key,menu_name varchar(30),cook varchar(30),user varchar(30) unique,price double); SHOW INDEXES FROM menu1; create table menu2(id int primary key,menu_name varchar(30),cook varchar(30),user varchar(30),price double); alter table menu2 add unique index uni(user); SHOW INDEX FROM menu2; create table menu3(id int primary key,menu_name varchar(30),cook varchar(30),user varchar(30),price double); create unique index aa on menu3(user); SHOW Keys FROM menu2; -- 3 create table sportman1(id int primary key, name varchar(20),specialty varchar(20)); create index iname on sportman1(name); create table sportman2(id int primary key, name varchar(20),specialty varchar(20)); alter table sportman2 add index iname(name);
哪些列上適合使用索引
-
較頻繁的作為查詢條件欄位應該創建索引
select* from emp where empno =1
-
唯一性太差的欄位不適合單獨創建索引,即使頻繁作為查詢條件
select * from emp where sex ='男‘(性別列只有兩種內容)
-
更新非常頻繁的欄位不適合創建索引
select * from emp where logincount =1
-
不會出現在WHERE子句中欄位不該創建索引
事務
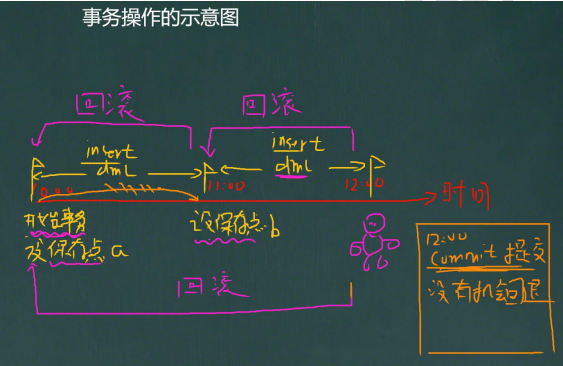
什么是事務
事務用于保證資料的一致性,它由一組相關的dml陳述句組成,該組的dml陳述句要么全部成功,要么全部失敗,如:轉賬就要用事務來處理,用以保證資料的一致性,
事務和鎖
當執行事務操作時(dml陳述句),mysql會在表上加鎖,防止其它用戶改表的資料.這對用戶來講是非常重要的,
mysql資料庫控制臺事務的幾個重要操作
- start transaction -- 開始一個事務
- savepoint 保存點名 --設定保存點
- rollback to 保存點名 --回退事務
- rollback --回退全部事務
- commit -- 提交事務,所有的操作生效,不能回退
-- 事務的一個重要的概念和具體操作
-- 看一個圖[看示意圖]
-- 演示
-- 1. 創建一張測驗表
CREATE TABLE t27( id INT, `name` VARCHAR(32));
-- 2. 開始事務
START TRANSACTION
-- 3. 設定保存點
SAVEPOINT a
-- 執行 dml 操作
INSERT INTO t27 VALUES(100, 'tom');
SELECT * FROM t27;
SAVEPOINT b
-- 執行 dml 操作
INSERT INTO t27 VALUES(200, 'jack');
-- 回退到 b
ROLLBACK TO b
-- 繼續回退 a
ROLLBACK TO a
-- 如果這樣, 表示直接回退到事務開始的狀態.
ROLLBACK
COMMIT
回退事務
在介紹回退事務前,先介紹一下保存點(savepoint).保存點是事務中的點.用于取消部分事務,當結束事務時,會自動的洗掉該事務所定義的所有保存點.當執行回退事務時,通過指定保存點可以回退到指定的點,回退后會把中間的所有點刪掉,
提交事務
使用commit陳述句可以提交事務.當執行了commit陳述句子后,會確認事務的變化、結束事務、洗掉保存點、釋放鎖,資料生效,當使用commit陳述句結束事務子后,其它會話[其他連接]將可以查看到事務變化后的新資料【所有資料正式生效】
事務細節討論
- 如果不開始事務,默認情況下,dml操作是自動提交的,不能回滾
- 如果開始一個事務,你沒有創建保存點.你可以執行rollback,默認就是回退到你事務開始的狀態.
- 你也可以在這個事務中(還沒有提交時),創建多個保存點.比如: savepoint aaa;執行dml , savepoint bbb;
- 你可以在事務沒有提交前,選擇回退到哪個保存點.
- mysql的事務機制需要innodb的存盤引擎還可以使用,myisam不好使.
- 開始一個事務start transaction, set autocommit=off;
-- 1. 如果不開始事務,默認情況下,dml 操作是自動提交的,不能回滾
INSERT INTO t27 VALUES(300, 'milan'); -- 自動提交 commit
SELECT * FROM t27
-- 2. 如果開始一個事務,你沒有創建保存點. 你可以執行 rollback,
-- 默認就是回退到你事務開始的狀態
START TRANSACTION
INSERT INTO t27 VALUES(400, 'king');
INSERT INTO t27 VALUES(500, 'scott');
ROLLBACK -- 表示直接回退到事務開始的的狀態
COMMIT;
-- 3. 你也可以在這個事務中(還沒有提交時), 創建多個保存點.比如: savepoint aaa;
-- 執行 dml , savepoint bbb
-- 4. 你可以在事務沒有提交前,選擇回退到哪個保存點
-- 5. InnoDB 存盤引擎支持事務 , MyISAM 不支持
-- 6. 開始一個事務 start transaction, set autocommit=off;
mysql事務隔離級別
事務隔離級別介紹
- 多個連接開啟各自事務操作資料庫中資料時,資料庫系統要負責隔離操作,以保證各個連接在獲取資料時的準確性,(通俗解釋)
- 如果不考慮隔離性,可能會引發如下問題:
- 臟讀(dirty read):當一個事務讀取另一個事務尚未提交的改變(增、刪、改)時,產生臟讀
- 不可重復讀(nonrepeatable read):同一查詢在同一事務中多次進行,由于其·他提交事務所做的修改或洗掉,每次回傳不同的結果集,此時發生不可重復讀,
- 幻讀(phantom read):同一查詢在同一事務中多次進行,由于其他提交事務所做的插入操作,每次回傳不同的結果集,此時發生幻讀,
事務隔離級別
概念:Mysql隔離級別定義了事務與事務之間的隔離程度,
| Mysql隔離級別(4種) | 臟讀 | 不可重復讀 | 幻讀 | 加鎖讀 |
|---|---|---|---|---|
| 讀未提交(Read uncommitted) | ? | ? | ? | 不加鎖 |
| 讀已提交(Read committed) | ? | ? | ? | 不加鎖 |
| 可重復讀(Repeatable read) | ? | ? | ? | 不加鎖 |
| 可串行化(Serializable)[演示重開客戶端] | ? | ? | ? | 加鎖 |
| 說明: ?可能出現 ?不會出現 |
|---|
設定事務隔離級別
-
查看當前會話隔離級別
select @@tx_isolation; -
查看系統當前隔離級別
select @@global.tx_isolation; -
設定當前會話事務隔離級別(一般在事務未啟動時設定,否則需要在提交后才生效)
set session transaction isolation level repeatable read; -- repeatable read根據情況換成適合的隔離級別 -
設定系統當前隔離級別
set global transaction isolation level repeatable read; -- repeatable read根據情況換成適合的隔離級別 -
mysql默認的事務隔離級別是repeatable read,一般情況下,沒有特殊要求,沒有必要修改(因為該級別可以滿足絕大部分專案需求)
隔離級別全域修改,修改mysql.ini組態檔,在最后加上,加上后需要重啟mysql服務(不用背,面試官一般不會問)
#可選引數有:READ-UNCOMMITTED,READ-COMMITTED, REPEATABLE-READ,SERIALIZABLE.
[mysqld]
transaction-isolation = REPEATABLE-READ
事務的 acid 特性
-
原子性(Atomicity)
原子性是指事務是一個不可分割的作業單位,事務中的操作要么都發生,要么都不發生,
-
一致性(Consistency)
事務必須使資料庫從一個一致性狀態變換到另外一個一致性狀態
-
隔離性(lsolation)
事務的隔離性是多個用戶并發訪問資料庫時,資料庫為每一個用戶開啟的事務,不能被其他事務的操作資料所干擾,多個并發事務之間要相互隔離,
-
持久性(Durability)
持久性是指一個事務一旦被提交,它對資料庫中資料的改變就是永久性的,接下來即使資料庫發生故障也不應該對其有何影響
事務的課堂練習[一定要自己去練習,體會]
-
登錄mysql控制客戶端A,創建表dog (id, name),添加兩條記錄,開始一個事務;
-
登錄mysql控制客戶端B,設定為讀未提交,開始一個事務.
-
A客戶端修改Dog 一條記錄,不要提交,看看B客戶端是否看到變化,說明什么問題?
-
登錄mysql客戶端C,設定為讀已提交,開始一個事務,這時A客戶修改一條記錄,不要提交,看看C客戶端是否看到變化,A提交后,看C客戶端是否有變化,說明什么問題?
-- 1 -- A use db01; CREATE TABLE dog(id int,name varchar(20)); INSERT INTO dog values (1,'aa'),(2,'bb'); start transaction; -- 2 -- B use db01; set session transaction isolation level read uncommitted; start transaction; -- 3 -- A UPDATE dog set name='cc' where id=2; -- B SELECT * FROM dog; -- 可以看到A修改后未提交的內容 -- 4 -- C use db01; set session transaction isolation level read committed; start transaction; -- A UPDATE dog set name='ddd' where id=1; -- C select * from dog; -- 不能看到A修改后未提交的內容 -- A commit; -- C select * from dog; -- 能看到A修改后提交的內容
mysql表型別和存盤引擎
基本介紹
-
MySQL的表型別由存盤引擎(Storage Engines)決定,主要包括MyISAM、innoDB、Memory等,
-
MySQL 資料表主要支持六種型別,分別是:CSV、Memory、ARCHIVE、MRG MYISAM、MYISAM、InnoBDB,
-
這六種又分為兩類,一類是”事務安全型”(transaction-safe), 比如:InnoDB;其余都屬于第二類,稱為”非事務安全型”(non-transaction-safe)[mysiam和memory].
-- 展示引擎型別
show engines;
以下為引擎查詢結果
| Engine | Support | Comment | Transactions | XA | Savepoints |
|---|---|---|---|---|---|
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
主要的存盤引擎/表型別特點
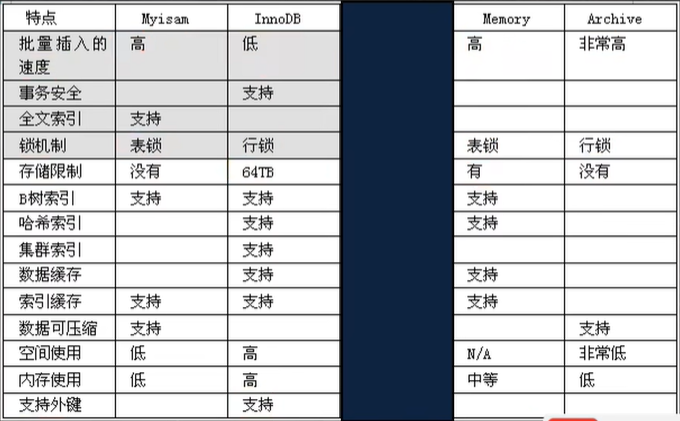
細節說明
我這里重點給大家介紹三種: MylSAM、InnoDB、MEMORY
- MyISAM不支持事務、也不支持外鍵,但其訪問速度快,對事務完整性沒有要求
- InnoDB存盤引擎提供了具有提交、回滾和崩潰恢復能力的事務安全,但是比起MyISAM存盤引擎,InnoDB寫的處理效率差一些并且會占用更多的磁盤空間以保留資料和索引,
- MEMORY存盤引擎使用存在記憶體中的內容來創建表,每個MEMORY表只實際對應一個磁盤檔案,MEMORY型別的表訪問非常得快,因為它的資料是放在記憶體中的,并且默認使用HASH索引,但是一旦MySQL服務關閉,表中的資料就會丟失掉,表的結構還在,
三種存盤引擎表使用案例
對前面我們提到的三種存盤引擎,我們舉例說明:
-- 表型別和存盤引擎
-- 查看所有的存盤引擎
SHOW ENGINES
-- innodb 存盤引擎,是前面使用過.
-- 1. 支持事務 2. 支持外鍵 3. 支持行級鎖
-- myisam 存盤引擎
CREATE TABLE t28 (id INT, `name` VARCHAR(32)) ENGINE MYISAM;
-- 1. 添加速度快 2. 不支持外鍵和事務 3. 支持表級鎖
START TRANSACTION;
SAVEPOINT t1;
INSERT INTO t28 VALUES(1, 'jack');
SELECT * FROM t28;
ROLLBACK TO t1; -- 會回滾失敗
-- memory 存盤引擎
-- 1. 資料存盤在記憶體中[關閉了 Mysql 服務,資料丟失, 但是表結構還在]
-- 2. 執行速度很快(沒有 IO 讀寫) 3. 默認支持索引(hash 表)
CREATE TABLE t29 (id INT, `name` VARCHAR(32)) ENGINE MEMORY;
DESC t29
INSERT INTO t29 VALUES(1,'tom'), (2,'jack'), (3, 'hsp');
SELECT * FROM t29;
-- 自己重啟mysql服務再看看資料和表結構是否還在
-- 指令修改存盤引擎
ALTER TABLE `t29` ENGINE = INNODB
如何選擇表的存盤引擎
-
如果你的應用不需要事務,處理的只是基本的CRUD操作,那么MylSAM是不二選擇,速度快
-
如果需要支持事務,選擇lnnoDB,
-
Memory存盤引擎就是將資料存盤在記憶體中,由于沒有磁盤I/O的等待,速度極快,但由于是記憶體存盤引擎,所做的任何修改在服務器重啟后都將消失,(經典用法用戶的在線狀態().)
修改存盤引擎
ALTER TABLE 表名 ENGINE=儲存引擎;
視圖(view)
看一個需求
emp表的列資訊很多,有些資訊是個人重要資訊(比如sal, comm,mgr, hiredate),如果我們希望某個用戶只能查詢emp表的(empno,ename, job和deptno )資訊,有什么辦法?=》視圖
基本概念
-
視圖是一個虛擬表,其內容由查詢定義,同真實的表一樣,視圖包含列,其資料來自對應的真實表(基表)
-
視圖和基表關系的示意圖

視圖的基本使用
-
創建視圖
create view 視圖名 as select陳述句 -
更新成新的視圖
alter view 視圖名 as select陳述句 -
查看創建視圖的命令
SHOW CREATE VIEW 視圖名 -
洗掉視圖
drop view 視圖名1,視圖名2
完成前面提出的需求
創建一個視圖emp_view01,只能查詢emp表的(empno、ename, job和deptno)資訊
-- 創建視圖
CREATE VIEW emp_wiew01 AS SELECT empno,ename,job,deptno from emp;
-- 查看視圖
desc emp_wiew01;
select * from emp_wiew01;
SELECT empno, job FROM emp_view01;
-- 查看創建視圖的指令
SHOW CREATE VIEW emp_view01
-- 洗掉視圖
DROP VIEW emp_view01;
視圖細節討論
- 創建視圖后,到資料庫去看,對應視圖只有一個視圖結構檔案(形式:視圖名.frm)
- 視圖的資料變化會影響到基表,基表的資料變化也會影響到視圖[insert update delete ]
- 視圖中可以再使用視圖
-- 視圖的細節
-- 1. 創建視圖后,到資料庫去看,對應視圖只有一個視圖結構檔案(形式: 視圖名.frm)
-- 2. 視圖的資料變化會影響到基表,基表的資料變化也會影響到視圖[insert update delete ]
-- 修改視圖 會影響到基表
UPDATE emp_view01 SET job = 'MANAGER' WHERE empno = 7369;
SELECT * FROM emp; -- 查詢基表
SELECT * FROM emp_view01
-- 修改基本表, 會影響到視圖
UPDATE emp SET job = 'SALESMAN' WHERE empno = 7369;
-- 3. 視圖中可以再使用視圖 , 比如從 emp_view01 視圖中,選出 empno,和 ename 做出新視圖DESC emp_view01
CREATE VIEW emp_view02 AS SELECT empno, ename FROM emp_view01;
SELECT * FROM emp_view02;
視圖最佳實踐
- 安全,一些資料表有著重要的資訊,有些欄位是保密的,不能讓用戶直接看到,這時就可以創建一個視圖,在這張視圖中只保留一部分欄位,這樣,用戶就可以查詢自己需要的欄位,不能查看保密的欄位,
- 性能,關系資料庫的資料常常會分表存盤,使用外鍵建立這些表的之間關系,這時,資料庫查詢通常會用到連接(JOIN),這樣做不但麻煩,效率相對也比較低,如果建立一個視圖,將相關的表和欄位組合在一起,就可以避免使用JOIN查詢資料,
- 靈活,如果系統中有一張舊的表,這張表由于設計的問題,即將被廢棄,然而,很多應用都是基于這張表,不易修改,這時就可以建立一張視圖,視圖中的資料直接映射到新建的表,這樣,就可以少做很多改動,也達到了升級資料表的目的,
MySQL管理
Mysql 用戶
mysql中的用戶,都存盤在系統資料庫mysql中user表中

其中user表的重要欄位說明:
- host:允許登錄的“位置”,localhost表示該用戶只允許本機登錄,也可以指定ip地址,比如:192.168.1.100
- user:用戶名;
- authentication string:密碼,是通過mysql的password()函式加密之后的密碼,
創建用戶
create user '用戶名'@'允許登錄位置' identified by '密碼';
說明:創建用戶,同時指定密碼
洗掉用戶
drop user '用戶名'@'允許登錄位置';
用戶修改密碼
修改自己的密碼:
set password = password('密碼');
修改他人的密碼(需要有修改用戶密碼權限):
set password for '用戶名'@'登錄位置' = password('密碼');
mysql 中的權限
給用戶授權
基本語法:
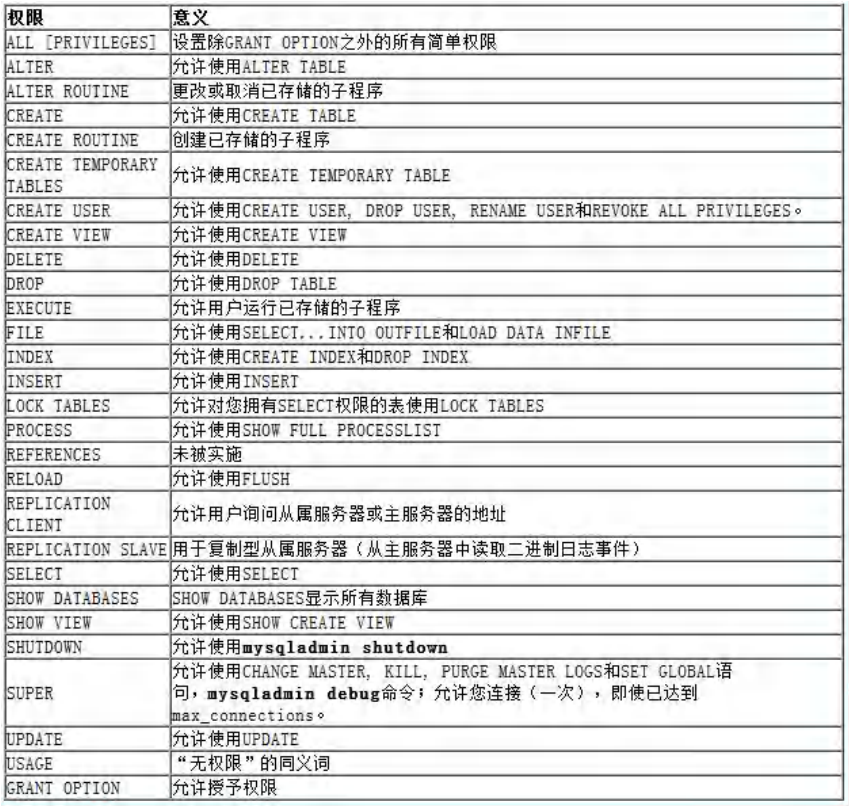
grant 權限串列 on 庫.物件名 to '用戶名'@'登錄位置' [identified by '密碼']
說明:
-
權限串列,多個權限用逗號分開
grant select on ...... grant select,delete,create on ...... grant all [privileges] on ...... //表示賦予該用戶在該物件上的所有權限 -
特別說明
*.*:代表本系統中的所有資料庫的所有物件(表,視圖,存盤程序)
庫.*:表示某個資料庫中的所有資料物件(表,視圖,存盤程序等)
-
identified by可以省略,也可以寫出.
(1)如果用戶存在,就是修改該用戶的密碼,
(2)如果該用戶不存在,就是創建該用戶!
回收用戶授權
revoke 權限串列 on 庫.物件名 from '用戶名'@'登錄位置';
權限生效指令
該指令針對5.7以下版本,5.7以及之后的版本給了權限馬上就會生效,
FLUSH PRIVILEGES;
課堂練習:
用戶管理練習題
-
創建一個用戶(你的名字:拼音),密碼123,并且只可以從本地登錄,不讓遠程登錄mysql
-
創建庫和表testdb下的news表,要求:使用root用戶創建
-
給用戶分配查看news表和添加資料的權限
-
測驗看看用戶是否只有這幾個權限
-
修改密碼為abc ,要求:使用root用戶完成
-
重新登錄
-
回收用戶的news表的所有權限
-
使用root 用戶洗掉你的用戶
-- 1 create user 'zwj'@'localhost' identified by '123'; -- 2 create database testdb; use testdb; create table news(id int ,content varchar(32)); -- 3 grant select,insert on testdb.news to 'zwj'@'localhost'; -- 4 登錄zwj用戶 SELECT * FROM news; INSERT INTO news VALUES(200,'上海新聞'); -- 5 set password FOR 'zwj'@'localhost'=password('abc'); -- 7 REVOKE select,insert on testdb.news from 'zwj'@'localhost'; -- 8 drop user 'zwj'@'localhost';
●細節說明
-
在創建用戶的時候,如果不指定Host,則為%,%表示表示所有IP都有連接權限
create user xxx; -
你也可以這樣指定
create user 'xxx'@'192.168.1.%’表示 xxx用戶在192.168.1.*的ip可以登錄mysql
-
在洗掉用戶的時候,如果host不是%需要明確指定‘用戶'@'host值'
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/509164.html
標籤:其他
上一篇:MySQL實作備份案例(2)