(本文首發于“資料庫架構師”公號,訂閱“資料庫架構師”公號,一起學習資料庫技術,助力職業發展) 本篇為Redis性能問題診斷系列的第四篇,也是最后一篇,主要從應用程式、系統、服務器硬體及網路系統等層面上進行講解,重點分享了哪些配置需要重點關注和調整優化,才能最大程度的發揮Redis的處理能力;
 一、服務器預留足夠記憶體,監控SWAP使用
Swap是作業系統層面行為,指當服務器記憶體不足時,會將原本在記憶體中的一部分資料拿出放入磁盤,如果再次訪問這部分資料就會回應很慢,因為磁盤的訪問速度是遠遠不如記憶體的,
Redis作為記憶體資料庫,有個常識一定要記住:所有的資料默認都是在記憶體中,不存在一部分在記憶體一部分在磁盤中的情況,除非被迫發生了SWAP,
說明:Redis在2.6版本之前有個VM【虛擬記憶體】特性,可以支持資料存放在記憶體和磁盤中,不過帶來的性能波動影響太大,就被廢棄了,但現在網上還有不少人在傳抄相關VM特性的文章,太有誤導性!
官方VM廢棄說明:https://redis.io/docs/reference/internals/internals-vm/
可以通過以下方式來查看 Redis 行程是否使用到了 Swap:
1.獲取redis對應的行程id
shell> redis-cli info | grep process_id
2.查看 Swap 使用情況
shell>cat /proc/$pid/smaps | egrep '^(Swap|Size)'
輸出結果如下:
Size: 1492 kB
Swap: 0 kB
Size: 32 kB
Swap: 0 kB
Size: 2196 kB
Swap: 0 kB
Size: 2048 kB
Swap: 0 kB
Size: 4 kB
Swap: 0 kB
Size: 1576 kB
上圖中size代表Redis行程占用的一塊記憶體空間大小,并對應一個Swap,
Swap后的數字表示該記憶體空間有多少已經被換到磁盤上了,如果兩者相等,則代表這塊記憶體空間的資料全都被換到了上了,
針對使用swap的解決方案可以參考如下:
a.提高Redis所在服務器的記憶體并預留可用記憶體,建議剩余可用記憶體至少保留20%以上;
b.Redis單獨部署或降低單機部署實體數量,不和其他應用程式混合部署,避免多服務爭用記憶體導致Redis資料被swap到磁盤上,
平時對Redis所在服務器的剩余可用記憶體及Swap 使用情況進行監控,在記憶體不足或使用到 Swap 時報警出來,及時干預處理,
二、.使用萬兆網卡,避免網路帶寬打滿
Redis 的高性能,除了資料都在記憶體之外,就在于網路 IO 了,如果網路存在瓶頸,那么也會嚴重影響 Redis 的性能,
網路帶寬過載的情況下,比如帶寬被打滿,那么服務器在 TCP 層和網路層就會出現資料包發送延遲、丟包等情況,
如果確實出現這種情況,我們需要及時核對原因,主要有以下幾個:
a.某個Redis服務訪問量過大,可能QPS高疊加操作的Key過大,導致網路滿載;
b.所在服務器網卡上限過小,如千兆網卡或者虛擬機限速200MB等;
c.服務器網卡/網線/驅動等問題,導致萬兆的網卡降頻為千兆或者被限流,
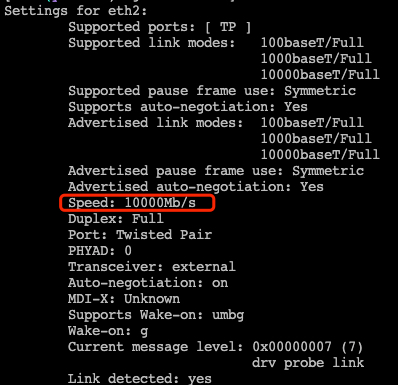
查看網卡速度:ethtool eth0
一、服務器預留足夠記憶體,監控SWAP使用
Swap是作業系統層面行為,指當服務器記憶體不足時,會將原本在記憶體中的一部分資料拿出放入磁盤,如果再次訪問這部分資料就會回應很慢,因為磁盤的訪問速度是遠遠不如記憶體的,
Redis作為記憶體資料庫,有個常識一定要記住:所有的資料默認都是在記憶體中,不存在一部分在記憶體一部分在磁盤中的情況,除非被迫發生了SWAP,
說明:Redis在2.6版本之前有個VM【虛擬記憶體】特性,可以支持資料存放在記憶體和磁盤中,不過帶來的性能波動影響太大,就被廢棄了,但現在網上還有不少人在傳抄相關VM特性的文章,太有誤導性!
官方VM廢棄說明:https://redis.io/docs/reference/internals/internals-vm/
可以通過以下方式來查看 Redis 行程是否使用到了 Swap:
1.獲取redis對應的行程id
shell> redis-cli info | grep process_id
2.查看 Swap 使用情況
shell>cat /proc/$pid/smaps | egrep '^(Swap|Size)'
輸出結果如下:
Size: 1492 kB
Swap: 0 kB
Size: 32 kB
Swap: 0 kB
Size: 2196 kB
Swap: 0 kB
Size: 2048 kB
Swap: 0 kB
Size: 4 kB
Swap: 0 kB
Size: 1576 kB
上圖中size代表Redis行程占用的一塊記憶體空間大小,并對應一個Swap,
Swap后的數字表示該記憶體空間有多少已經被換到磁盤上了,如果兩者相等,則代表這塊記憶體空間的資料全都被換到了上了,
針對使用swap的解決方案可以參考如下:
a.提高Redis所在服務器的記憶體并預留可用記憶體,建議剩余可用記憶體至少保留20%以上;
b.Redis單獨部署或降低單機部署實體數量,不和其他應用程式混合部署,避免多服務爭用記憶體導致Redis資料被swap到磁盤上,
平時對Redis所在服務器的剩余可用記憶體及Swap 使用情況進行監控,在記憶體不足或使用到 Swap 時報警出來,及時干預處理,
二、.使用萬兆網卡,避免網路帶寬打滿
Redis 的高性能,除了資料都在記憶體之外,就在于網路 IO 了,如果網路存在瓶頸,那么也會嚴重影響 Redis 的性能,
網路帶寬過載的情況下,比如帶寬被打滿,那么服務器在 TCP 層和網路層就會出現資料包發送延遲、丟包等情況,
如果確實出現這種情況,我們需要及時核對原因,主要有以下幾個:
a.某個Redis服務訪問量過大,可能QPS高疊加操作的Key過大,導致網路滿載;
b.所在服務器網卡上限過小,如千兆網卡或者虛擬機限速200MB等;
c.服務器網卡/網線/驅動等問題,導致萬兆的網卡降頻為千兆或者被限流,
查看網卡速度:ethtool eth0
 針對網路過載可以采用以下方案來解決:
a.降低單機部署Redis實體個數,打散重度使用網路帶寬的Redis服務到多臺服務器;
b.對Redis服務使用的網路帶寬進行監控,可以關注性能指標:instantaneous_input_kbps、instantaneous_output_kbps
c.使用萬兆網卡的服務器,并添加對帶寬上限【警惕網卡從萬兆降為千兆】、網路帶寬使用、丟包情況的監控;
d.遵守Redis使用規范,比如控制寫入Redis中的VALUE大小、限制使用smembers或hgetall等操作的集合成員個數等,
三、根據場景選擇是否使用SSD磁盤
大家要根據自己的實際場景判斷,比如使用單節點且用于快取服務的情形,就不需要使用SSD磁盤,
但是如果希望使用Redis的持久化能力來保證資料安全,那么磁盤IO能力就不得不重視了,
這里對于Redis的持久化不做詳細介紹,具體可以參考上篇文章,
Redis中對IO比較敏感的操作主要有下面幾類:
a.AOF持久化,相關磁盤操作有: AOF命令落盤、AOF檔案重寫;
b.RDB持久化,相關磁盤操作有:主從復制主節點RDB生成快照、從節點加載RDB檔案、備份觸發RDB快照、配置觸發自動RDB快照
上面列出的都會嚴重依賴磁盤IO能力,特別是單機部署多Redis實體的情況,如果磁盤IO能力一般,那么就會嚴重影響Redis的性能,
四、系統引數配置
1.記憶體分配策略引數vm.overcommit_memory
Redis啟動給出Warning提示:
WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add ‘vm.overcommit_memory = 1’ to /etc/sysctl.conf and then reboot or run the command ‘sysctl vm.overcommit_memory=1’ for this to take effect.
這里首先解答下什么是Overcommit?
Linux對大部分申請記憶體的請求都回復"yes",以便能跑更多更大占用記憶體的程式,因為申請記憶體后,并不會馬上使用記憶體,這種技術叫做Overcommit,
當linux發現記憶體不足時,會發生OOM killer(OOM=out-of-memory),它會選擇殺死一些行程(用戶態行程,不是內核執行緒),以便釋放記憶體,
overcommit_memory的幾個主要值的說明:
0:表?內核將檢查是否有?夠的可?記憶體供應?行程使?;如果有?夠的可?記憶體,記憶體申請允許;否則,記憶體申請失敗,并把錯誤回傳給應?行程;
1: 表?內核允許分配所有的物理記憶體,?不管當前的記憶體狀態如何;
2: 表?內核允許分配超過所有物理記憶體和交換空間總和的記憶體,
這里建議調整為1,相關調整方式:
永久生效:
編輯vim /etc/sysctl.conf ,改vm.overcommit_memory=1,然后sysctl -p 使組態檔生效
臨時生效:
echo 1 > /proc/sys/vm/overcommit_memory
上述日志中的Background save代表的是bgsave和bgrewriteaof, 如果當前可用記憶體不足, 作業系統應該如何處理fork操作呢?
如果vm.overcommit_memory=0, 代表如果沒有可用記憶體, 就申請記憶體失敗, 對應到Redis就是執行fork失敗, 在Redis的日志會出現:
Cannot allocate memory
Redis建議把這個值設定為1, 是為了讓fork操作能夠在低記憶體下也執行成功,
2.作業系統記憶體大頁引數配置
Redis啟動給出Warning提示:
WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
意思是:你的Redis所在服務器當前使用的是記憶體大頁機制,可能導致Redis訪問延遲和記憶體使用問題,
那什么是記憶體大頁呢?
應用程式向作業系統申請記憶體空間時,是按記憶體頁為單位進行申請的,默認大小是4KB,不過Linux從 2.6.38內核版本開始,支持了記憶體大頁機制,可以允許向作業系統一次申請 2MB 大小的記憶體,由于申請的記憶體單位變大,也意味著申請耗時相對變長,
那對于 Redis服務會有什么影響呢?
當 Redis 在執行后臺 RDB 和 AOF rewrite 時,采用 fork 子行程的方式來處理,但主行程 fork 子行程后,此時的主行程依舊是可以接收寫請求的,而進來的寫請求,會采用 Copy On Write(寫時復制)的方式操作記憶體資料,
也就是說,主行程一旦有資料需要修改,Redis 并不會直接修改現有記憶體中的資料,而是先將這塊記憶體資料拷貝出來,再修改這塊新記憶體的資料,這就是所謂的「寫時復制」,
寫時復制可以理解為:需要發生寫操作哪個Key,就需要先拷貝這個Key,然后再修改,
這里注意,主行程在修改拷貝記憶體資料時,這個階段就涉及到新記憶體的申請,如果此時作業系統開啟了記憶體大頁,那么在此期間,應用程式即便只修改 10B 的資料,Redis 在申請記憶體時也會以 2MB 為單位向作業系統申請,申請記憶體的耗時變長,進而導致每個寫請求的延遲增加,影響到 Redis 性能,
所以為了避免過多的記憶體申請,我們需要關閉記憶體大頁機制:
cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
如果輸出選項是 always,就表示目前開啟了記憶體大頁機制,我們需要關掉它:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
其實,作業系統提供的記憶體大頁機制,其優勢是可以在一定程式上降低應用程式申請記憶體的次數,
比如針對大資料、物件存盤相關的服務來說可能會更好,但是對于 Redis 這種對性能和延遲極其敏感的資料庫來說,我們希望 Redis 在每次申請記憶體時,耗時盡量短,建議關閉這個引數,
五、其他影響訪問Redis的性能的因素
1.應用程式配置不合理
a.應配置合理的連接數等相關引數,比如jedis,默認MaxActive最大連接數只有8個,在高QPS時就會出現無法獲取新連接的提示:
redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool … Caused by: java.util.NoSuchElementException: Timeout waiting for idle object at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:449)
b.驅動版本過低,低版本的Driver連接高版本Redis,除了無法使用最新的特性外,還會經常出現連接不釋放、記憶體泄露、訪問緩慢等問題,
2.使用連接池,避免使用短連接模式.特別是使用PHP的應用,頻繁的連接創建與銷毀,在高QPS訪問時網路開銷巨大;
3.CPU綁核及主頻影響
Redis是單執行緒模型處理處理用戶需求,那么處理的吞吐、效率就會極度依賴CPU的處理能力,所以選型CPU時,如果部署的Redis平時QPS較高,可以采購主頻高些的CPU.
另外現在的CPU都是多核處理,為了提高服務性能,降低應用程式在多個 CPU 核心之間的背景關系切換帶來的性能損耗,通常采用的方案是行程系結 CPU 的方式提高性能,
但是Redis的綁核操作過于復雜,對于單機多實體的管理挑戰過高,再加上Redis 的性能已經足夠優秀,不建議系結 CPU來處理,這里也不做深入說明,
最后總結:
本篇為Redis性能診斷的完結篇,通過總結常見的可能導致訪問回應延遲、甚至阻塞的問題的各種場景,以及如何定位及分析針對性地提供了解決方案,
但是由于篇幅限制,關于 Redis 的很多細節也無法全部展開,后續也會對Redis使用的各種技巧、架構及內部的作業原理深入分享,歡迎保持關注,
針對網路過載可以采用以下方案來解決:
a.降低單機部署Redis實體個數,打散重度使用網路帶寬的Redis服務到多臺服務器;
b.對Redis服務使用的網路帶寬進行監控,可以關注性能指標:instantaneous_input_kbps、instantaneous_output_kbps
c.使用萬兆網卡的服務器,并添加對帶寬上限【警惕網卡從萬兆降為千兆】、網路帶寬使用、丟包情況的監控;
d.遵守Redis使用規范,比如控制寫入Redis中的VALUE大小、限制使用smembers或hgetall等操作的集合成員個數等,
三、根據場景選擇是否使用SSD磁盤
大家要根據自己的實際場景判斷,比如使用單節點且用于快取服務的情形,就不需要使用SSD磁盤,
但是如果希望使用Redis的持久化能力來保證資料安全,那么磁盤IO能力就不得不重視了,
這里對于Redis的持久化不做詳細介紹,具體可以參考上篇文章,
Redis中對IO比較敏感的操作主要有下面幾類:
a.AOF持久化,相關磁盤操作有: AOF命令落盤、AOF檔案重寫;
b.RDB持久化,相關磁盤操作有:主從復制主節點RDB生成快照、從節點加載RDB檔案、備份觸發RDB快照、配置觸發自動RDB快照
上面列出的都會嚴重依賴磁盤IO能力,特別是單機部署多Redis實體的情況,如果磁盤IO能力一般,那么就會嚴重影響Redis的性能,
四、系統引數配置
1.記憶體分配策略引數vm.overcommit_memory
Redis啟動給出Warning提示:
WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add ‘vm.overcommit_memory = 1’ to /etc/sysctl.conf and then reboot or run the command ‘sysctl vm.overcommit_memory=1’ for this to take effect.
這里首先解答下什么是Overcommit?
Linux對大部分申請記憶體的請求都回復"yes",以便能跑更多更大占用記憶體的程式,因為申請記憶體后,并不會馬上使用記憶體,這種技術叫做Overcommit,
當linux發現記憶體不足時,會發生OOM killer(OOM=out-of-memory),它會選擇殺死一些行程(用戶態行程,不是內核執行緒),以便釋放記憶體,
overcommit_memory的幾個主要值的說明:
0:表?內核將檢查是否有?夠的可?記憶體供應?行程使?;如果有?夠的可?記憶體,記憶體申請允許;否則,記憶體申請失敗,并把錯誤回傳給應?行程;
1: 表?內核允許分配所有的物理記憶體,?不管當前的記憶體狀態如何;
2: 表?內核允許分配超過所有物理記憶體和交換空間總和的記憶體,
這里建議調整為1,相關調整方式:
永久生效:
編輯vim /etc/sysctl.conf ,改vm.overcommit_memory=1,然后sysctl -p 使組態檔生效
臨時生效:
echo 1 > /proc/sys/vm/overcommit_memory
上述日志中的Background save代表的是bgsave和bgrewriteaof, 如果當前可用記憶體不足, 作業系統應該如何處理fork操作呢?
如果vm.overcommit_memory=0, 代表如果沒有可用記憶體, 就申請記憶體失敗, 對應到Redis就是執行fork失敗, 在Redis的日志會出現:
Cannot allocate memory
Redis建議把這個值設定為1, 是為了讓fork操作能夠在低記憶體下也執行成功,
2.作業系統記憶體大頁引數配置
Redis啟動給出Warning提示:
WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
意思是:你的Redis所在服務器當前使用的是記憶體大頁機制,可能導致Redis訪問延遲和記憶體使用問題,
那什么是記憶體大頁呢?
應用程式向作業系統申請記憶體空間時,是按記憶體頁為單位進行申請的,默認大小是4KB,不過Linux從 2.6.38內核版本開始,支持了記憶體大頁機制,可以允許向作業系統一次申請 2MB 大小的記憶體,由于申請的記憶體單位變大,也意味著申請耗時相對變長,
那對于 Redis服務會有什么影響呢?
當 Redis 在執行后臺 RDB 和 AOF rewrite 時,采用 fork 子行程的方式來處理,但主行程 fork 子行程后,此時的主行程依舊是可以接收寫請求的,而進來的寫請求,會采用 Copy On Write(寫時復制)的方式操作記憶體資料,
也就是說,主行程一旦有資料需要修改,Redis 并不會直接修改現有記憶體中的資料,而是先將這塊記憶體資料拷貝出來,再修改這塊新記憶體的資料,這就是所謂的「寫時復制」,
寫時復制可以理解為:需要發生寫操作哪個Key,就需要先拷貝這個Key,然后再修改,
這里注意,主行程在修改拷貝記憶體資料時,這個階段就涉及到新記憶體的申請,如果此時作業系統開啟了記憶體大頁,那么在此期間,應用程式即便只修改 10B 的資料,Redis 在申請記憶體時也會以 2MB 為單位向作業系統申請,申請記憶體的耗時變長,進而導致每個寫請求的延遲增加,影響到 Redis 性能,
所以為了避免過多的記憶體申請,我們需要關閉記憶體大頁機制:
cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
如果輸出選項是 always,就表示目前開啟了記憶體大頁機制,我們需要關掉它:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
其實,作業系統提供的記憶體大頁機制,其優勢是可以在一定程式上降低應用程式申請記憶體的次數,
比如針對大資料、物件存盤相關的服務來說可能會更好,但是對于 Redis 這種對性能和延遲極其敏感的資料庫來說,我們希望 Redis 在每次申請記憶體時,耗時盡量短,建議關閉這個引數,
五、其他影響訪問Redis的性能的因素
1.應用程式配置不合理
a.應配置合理的連接數等相關引數,比如jedis,默認MaxActive最大連接數只有8個,在高QPS時就會出現無法獲取新連接的提示:
redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool … Caused by: java.util.NoSuchElementException: Timeout waiting for idle object at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:449)
b.驅動版本過低,低版本的Driver連接高版本Redis,除了無法使用最新的特性外,還會經常出現連接不釋放、記憶體泄露、訪問緩慢等問題,
2.使用連接池,避免使用短連接模式.特別是使用PHP的應用,頻繁的連接創建與銷毀,在高QPS訪問時網路開銷巨大;
3.CPU綁核及主頻影響
Redis是單執行緒模型處理處理用戶需求,那么處理的吞吐、效率就會極度依賴CPU的處理能力,所以選型CPU時,如果部署的Redis平時QPS較高,可以采購主頻高些的CPU.
另外現在的CPU都是多核處理,為了提高服務性能,降低應用程式在多個 CPU 核心之間的背景關系切換帶來的性能損耗,通常采用的方案是行程系結 CPU 的方式提高性能,
但是Redis的綁核操作過于復雜,對于單機多實體的管理挑戰過高,再加上Redis 的性能已經足夠優秀,不建議系結 CPU來處理,這里也不做深入說明,
最后總結:
本篇為Redis性能診斷的完結篇,通過總結常見的可能導致訪問回應延遲、甚至阻塞的問題的各種場景,以及如何定位及分析針對性地提供了解決方案,
但是由于篇幅限制,關于 Redis 的很多細節也無法全部展開,后續也會對Redis使用的各種技巧、架構及內部的作業原理深入分享,歡迎保持關注,
 如果這篇文章對你有幫助,還請幫忙點贊、在看、轉發 一下,你的支持會激勵我們輸出更多高質量的文章,非常感謝!
如果你還想看更多優質文章,歡迎關注我的公眾號「資料庫架構師」,提升資料庫技能,
如果這篇文章對你有幫助,還請幫忙點贊、在看、轉發 一下,你的支持會激勵我們輸出更多高質量的文章,非常感謝!
如果你還想看更多優質文章,歡迎關注我的公眾號「資料庫架構師」,提升資料庫技能,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/509205.html
標籤:NoSQL
下一篇:Redis——資料操作