據中國信通院發布,2012年到2021年10年間,我國數字經濟規模由12萬億元增長到45.5萬億元,在整個GDP中的比重由21.6%提升至39.8%,順應時代發展新趨勢,“資料”成為新的生產要素已是毋庸置疑的共識,
如果說資料中臺的崛起代表著企業數字化轉型從流程驅動走向資料驅動,從數字化走向智能化,那么DataOps,則是實作資料中臺的一個優秀的理念或方法論,
DataOps的概念早在2014年即由Lenny Liebmann提出,2018年DataOps正式被納入Gartner的資料管理技術成熟度曲線當中,標志著DataOps正式被業界所接納并推廣起來,雖然目前在國內仍處于發展初期,但是DataOps的熱度逐年上升,在可預見的未來2-5年內將得到更加廣泛的實踐應用,
袋鼠云便是其中的一位探索者,作為全鏈路數字化技術與服務提供商的袋鼠云,從創立以來便一直深耕大資料領域,伴隨著各行各業加速數智化轉型的步伐逐年加快,對于資料治理、資料管理等方面的許多問題也逐漸顯露,
為此,在技術進步和客戶數字轉型需求的驅動下,袋鼠云打造的一站式大資料開發與治理平臺——數堆疊DTinsight,基于DataOps理念開展資料價值化流程,實作了資料全生命周期的質量監管和資料開發流程規范,為資料治理保駕護航,
回應變化
DataOps的核心理念之一就是及時回應需求端的變化,下面是一張很典型的企業資料架構圖:
資料從左側的源系統流入,中間環節是各類資料處理的工具,例如資料湖、資料倉庫或資料集市、AI分析等,資料經過清洗、加工、匯總統計、資料治理等程序,最終通過BI、定制化報表、API等工具服務于各類需求方,
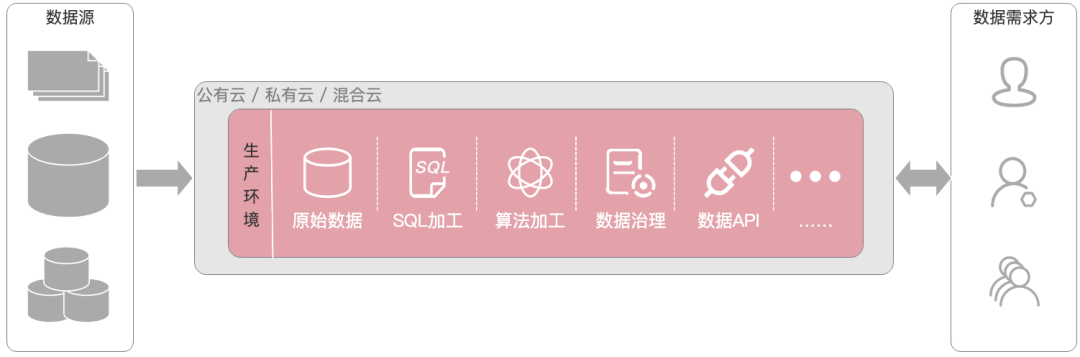
企業內的資料架構師或管理者,在定義平臺架構時,一般主要考慮生產環境下的極致的性能、延遲、負載管理等問題,很多計算引擎/資料庫都精于此道,但這種架構并沒有體現出「回應快速變化」的能力:
這就像是設計一條公路,在設計時只考慮了正常情況下的通行能力,并沒有考慮事故、堵車、暴雨等各種臨時變化,在「上線」之后發現每日疲于應對,并沒有提升太多通行能力(比如只有2個車道的隧道,一個小的剮蹭事故就可能把整條隧道堵住),企業內的資料平臺也會遇到類似的情況,企業內的資料作業者,每天甚至每個小時都要回應這種變化,有時一個簡單的SQL變更上線甚至可能要花幾天的時間,
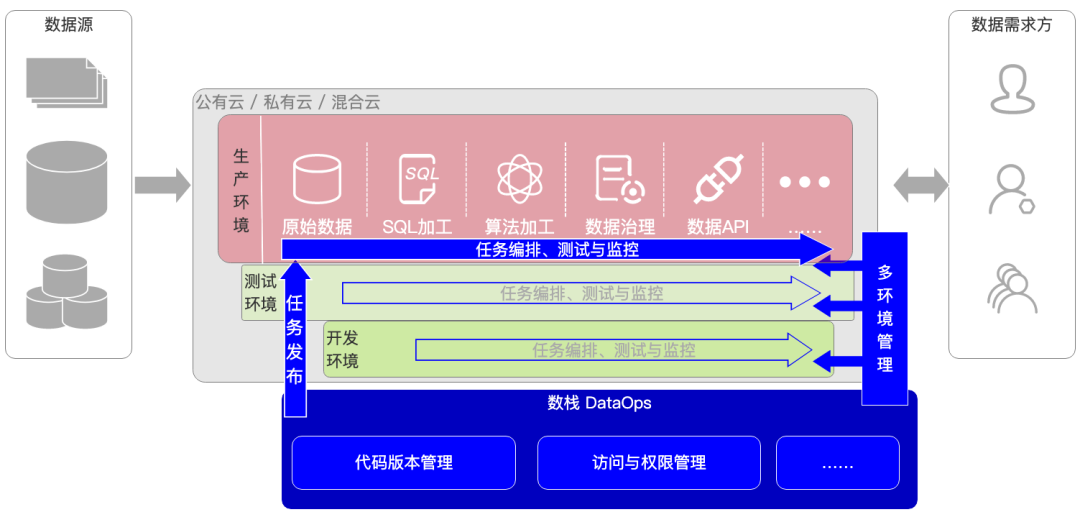
在設計階段考慮各種變化,可以更靈活、更穩定的回應,下面是DataOps視角下的資料架構,
DataOps視角下的資料架構
資料架構師在建設伊始就提出如下一些敏捷性的標準,例如:
? 任務從完成開發到發布生產,需要在1小時內完成,且對生產環境無影響
? 在發布至生產環境前,及時發現資料錯誤
? 重大變更,在1天內完成
同時需要考慮一些環境的問題,包括:
? 必需維護獨立的開發、測驗和生產環境,但要在一定程度上保證其一致性,至少是元資料的一致性
? 可以人工編排,或自動化的實作資料的測驗、質量監控以及部署至生產環境
當架構師開始思考資料質量、快速發布、資料的實時監控等問題時,企業就向DataOps邁進了一步,
DataOps架構的分解與實踐
講完了DataOps視角下的資料架構,接下來來講講DataOps架構的分解與實踐,DataOps具體實踐可以分解為如下幾個關鍵點:
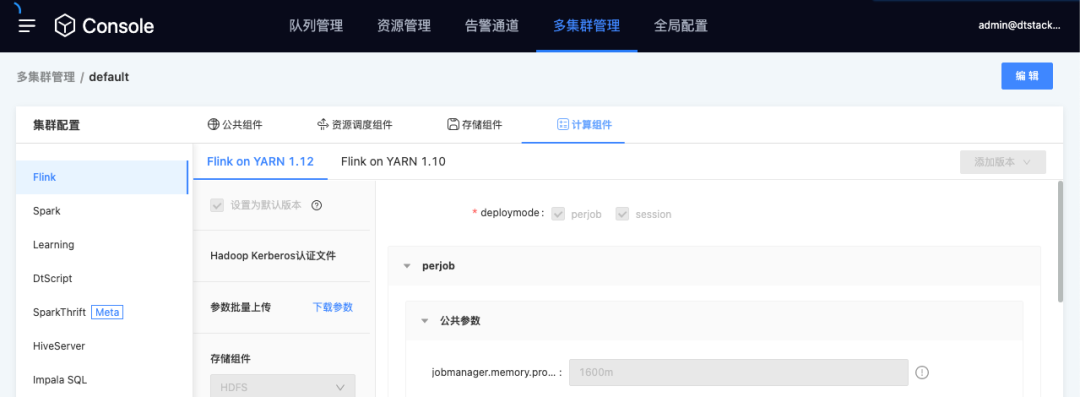
多環境的管理
DataOps的第一步從「環境管理」開始,一般是指獨立的開發、測驗和生產環境,每個環境下都可以支持任務的編排、監控和自動化測驗,
數堆疊目前可支持同時對接多套環境,只要網路相通,即可實作一套數堆疊對多個不同環境的統一對接和統一管理,數堆疊是通過Console中的「集群」概念來進行不同環境的區分,不同的集群可靈活對接各類不同的計算引擎,例如各類開源或發行版Hadoop、星環Inceptor、Greenplum、OceanBase,甚至MySQL、Oracle等傳統的關系型資料庫,如下圖所示:
任務發布
承接上個步驟的多環境管理,在實際開發程序中,需要進行多個環境之間的任務發布,假設存在開發、測驗、生產環境,則需要在多個環境之間進行級聯形式的發布,如下圖所示:
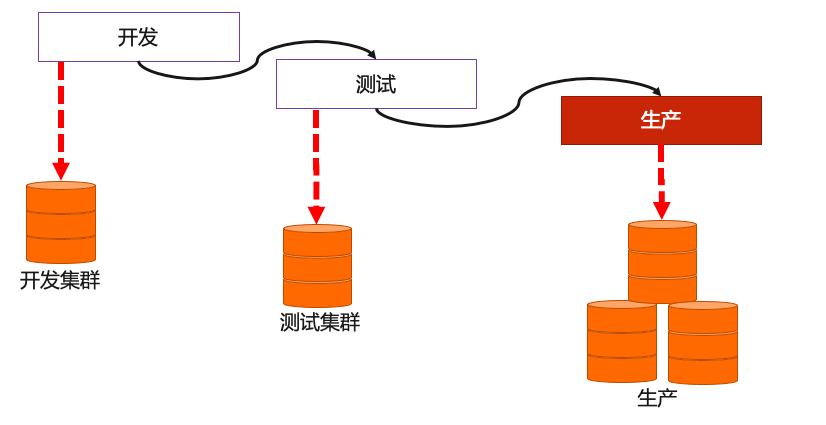
在這種多環境發布的情況下,數堆疊可支持三種方式進行發布管理:
● 一鍵發布
當各個環境網路相通,可使用一套平臺對接各個環境,實作「一鍵發布」,一鍵發布程序中,僅有一定權限的用戶才可以執行發布動作,提升生產環境穩定性,與此同時,可自動替換一些關鍵的環境資訊,例如同步任務中的資料源連接引數、不同環境下的算力配置等,一鍵發布比較適合SaaS或內部云平臺的管理方式,
● 匯入/匯出式發布
在目前國內接觸的絕大多數場景中,客戶為了實作更高的安全等級,生產環境會采用嚴格的物理隔離,這種場景可以采用匯入匯出的方式實作任務的跨環境發布,用戶可手動將新增、變更或洗掉的任務匯入至下游環境,
● Devops發布
某些客戶可能已經采購或自研了公司級的線上發布工具,此時需要數堆疊定制化的對接其介面,將相關變更資訊由第三方CI工具(例如Jekins)代為執行發布,
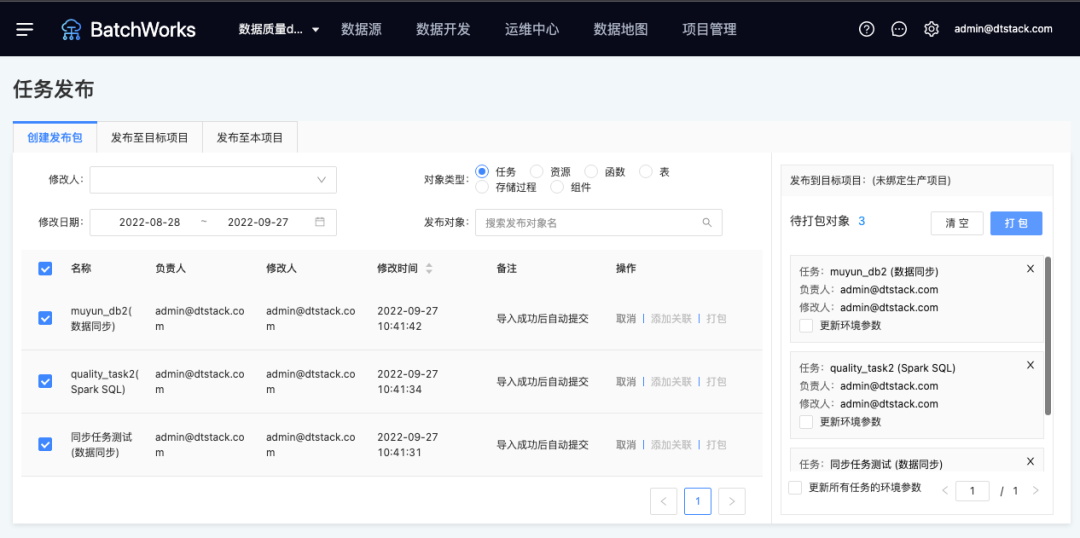
代碼的版本管理
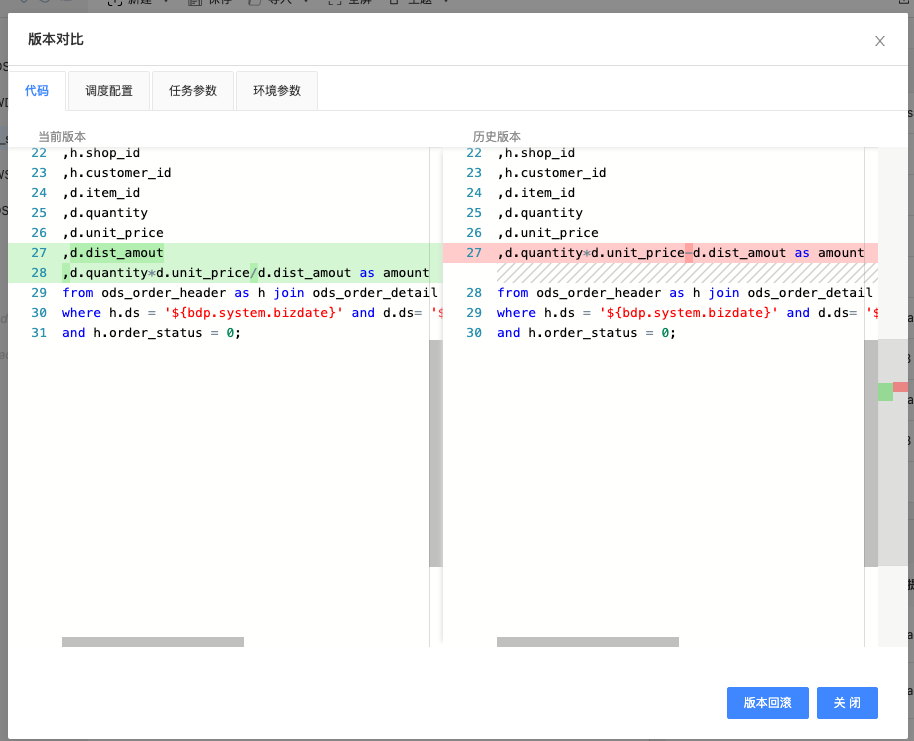
每次進行跨環境的發布時,需要記錄每次發布代碼的版本,便于后期排查問題,在實際場景中,經常需要進行不同版本間的代碼對比、版本回退等操作,
數堆疊除了支持對代碼內容進行對比之外,還支持對任務相關的更多資訊進行對比,包括任務調度周期的配置、任務執行引數、環境引數等,并可以「一鍵回退」至指定的版本,
訪問與權限管理
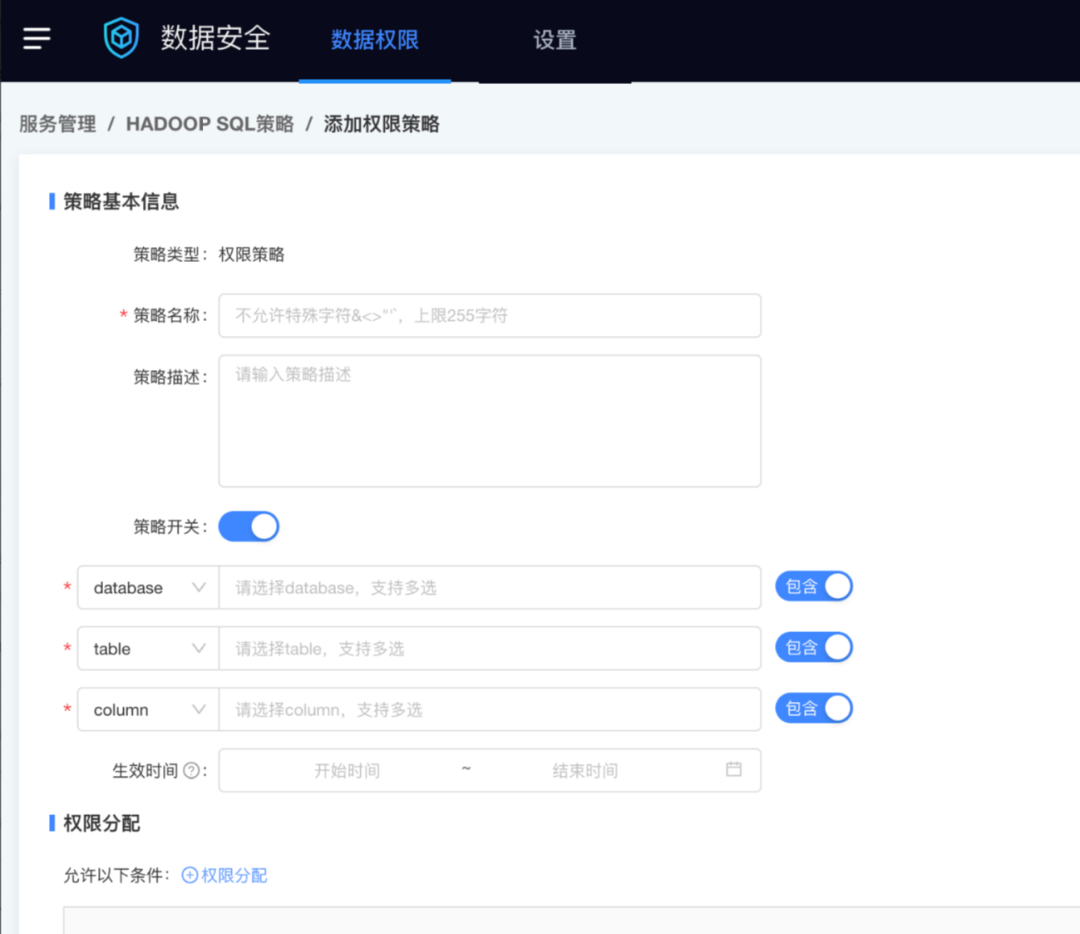
在企業內的多個環境中,一般對生產環境的要求最高,對開發和測驗環境相對寬松,在這種情況下,即需要管理用戶在不同環境下的認證或訪問資訊,實際上為了開發和測驗方便,且沒有敏感資料,在這2個環節,一般是普通用戶都有全部的資料權限,并可以訪問各種工具,但在生產環境中,用戶肯定只有自己權限范圍內的資料權限,
根據引擎的不同,數堆疊可支持多種資料權限管理方式,包括:
● Hadoop引擎
以Kerberos為基礎的認證安全+以Ranger/LDAP為基礎的資料安全,可以支持庫、表、欄位級別的資料權限控制,同時可支持資料脫敏,
● JDBC類引擎
部分場景中,客戶可能并未采用Hadoop來建設資料平臺,而是采用一些JDBC類的資料庫(例如TiDB、Doris、Greenplum),而數堆疊本身并不管理JDBC資料庫的權限,而是采用賬號系結的方式來控制,以此區分不同賬號的權限,例如:
· 數堆疊A賬號,系結資料庫root賬號
· 數堆疊B賬號,系結資料庫admin賬號
● 任務編排、測驗與監控
在發布上線至生產后,數堆疊可將上述各個環節串連起來,用戶從開發階段可以一鍵發布至測驗環境,經測驗環境驗證后,觀察任務實體、資料產出的運行情況,運行無誤后可發布至生產環境,
寫在最后的話
DataOps是一種最佳實踐的理念,但目前在國內還處于比較早期的階段,數堆疊在這方面有過一些實踐經驗,但還有不少可以優化的內容,比如資料質量的規則也需要跨環境發布、任務代碼、任務模板的匯出需要支持更多的任務型別等等,期待未來行業內有更多的DataOps的最佳實踐能產生,
袋鼠云開源框架釘釘技術交流qun(30537511),歡迎對大資料開源專案有興趣的同學加入交流最新技術資訊,開源專案庫地址:https://github.com/DTStack/Taier
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/510831.html
標籤:其他