PostgreSQL 高可用資料庫的常見搭建方式主要有兩種,邏輯復制和物理復制,上周已經寫過了關于在Windows環境搭建PostgreSQL邏輯復制的教程,這周來記錄一下 物理復制的搭建方法,
首先介紹一下邏輯復制和物理復制的一些基本區別:
- 物理復制要求多個實體之間大版本一致,并且作業系統平臺一致,如主實體是 Windows環境下的 PostgreSQL15 則 從實體也必須是這個環境和版本,邏輯復制則沒有要求,
- 物理復制是直接傳遞 WAL歸檔 檔案,在從實體進行重放執行,可以理解為實時的 WAL歸檔恢復,所以延遲低,性能高,,
- 邏輯復制可以簡單理解為決議了WAL歸檔檔案中的資訊,處理成為 標準的SQL陳述句,傳遞給存庫進行執行,相對于直接傳遞WAL性能較低,延遲高,
- 物理復制不需要像邏輯復制一些去手動的建立資料庫,資料表,因為物理復制是直接恢復WAL所以包含了DDL操作,邏輯復制則需要自己進行DDL操作,
- 邏輯復制更加靈活,可以自己指定需要復制的庫,從實體,還可以建立其他庫用于其他業務,而物理復制則是面向整個實體進行的,從實體和主實體100%一致最多只能進行只讀操作,
關于 Windows 系統 PostgreSQL 的安裝方法可以直接看之前的博客 Windows 系統 PostgreSQL 手工安裝配置方法
如果追求高性能,高一致性的資料庫復制備份方案建議采用物理復制的方式,
搭建物理復制模式的主從訂閱首先要調整主實體的 postgresql.conf 檔案
wal_level = replica
synchronous_commit = remote_apply

因為我們采用的 synchronous_commit = remote_apply 是同步復制的模式,該模式可以理解為同步復制,當客戶端像主實體提交事務之后,需要等 synchronous_standby_names 總配置的節點全部完成 remote_apply 收到資料之后,主實體才會給備庫回傳事務成功提交的狀態,創建好名為 s 的訂閱創建之后,我們再次打開 主實體的 postgresql.conf 檔案進行調整設定
synchronous_standby_names = 's'

當有多個從實體從主實體同步的時候synchronous_standby_names 還可以采用以下配置模式
- synchronous_standby_names='s1' 代表s1備機回傳就可以提交,
- synchronous_standby_names='FIRST 2 (s1,s2,s3)' 代表s1,s2,s3三個備機中前兩個s1和s2回傳主實體就可以提交,
- synchronous_standby_names='ANY 2 (s1,s2,s3)' 代表s1,s2,s3三個備機中任意兩個備機回傳主實體就可以提交,
- synchronous_standby_names='ANY 2 (*)' 代表所有備機中任意兩個備機回傳主實體就可以提交,
- synchronous_standby_names='*' 代表匹配任意主機,也就是任意主機回傳就可以提交,
這里有一點需要注意,這是 PostgreSQL 在同步復制時的一個已知問題,假設 一個主實體,一個備庫 s1,采用同步模式,然后 synchronous_standby_names 配置為 synchronous_standby_names='s1',雖然從配置上來看似乎資料必須要提交到s1并且s1成功回應之后,主實體才會為客戶端回傳事務操作成功的回應,但是實際情況下,當備庫掛掉的情況下,主實體在收到一個事務操作時,在等待 s1 備庫的回傳時因為 s1庫已經掛掉了所以這個操作肯定會超時,當主備節點通信超時之后,主節點還是會像客戶端回傳事務成功提交的命令,客戶端的操作還是會成功,同時因為每個事務操作都要經歷這個超時的流程,所以客戶端的所有事務操作都會相對很卡,
比如每個 insert 都會經過主實體和備庫的這個通信超時程序,所以每個 insert 動作都變成了大約30秒次才能完成,就會導致應用程式很卡,這時候就相當于主實體在以(很卡的)獨立模式運行,這個情況在備庫重新上線之后就會恢復正常(如果備庫短期之內無法恢復,可以調整主實體的 synchronous_standby_names設定 移除對于s1備庫的事務等待驗證,變為單庫運行模式重啟實體之后也就不會卡了),但是要注意當主實體脫離備庫獨立運行時,如果這個時候主實體發生災難比如硬碟壞掉,則就會產生資料丟失,所以建議至少有2個從實體來提升保障級別,
然后還需要調整主實體的 pg_hba.conf,添加 replication 模式的連接白名單配置,
host replication all 0.0.0.0/0 scram-sha-256
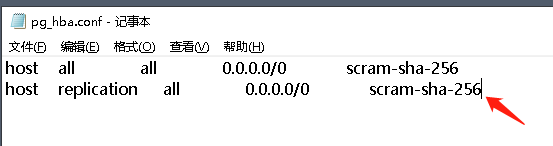
調整組態檔之后記得重啟主實體,
主實體重啟之后,我們還需要連接到主實體創建復制槽,默認情況下WAL歸檔檔案是回圈滾動清理,這就會導致一個問題如果我們的從實體掛機之后離線的時間較長,就有可能因為主實體的WAL檔案已經回圈滾動洗掉了,這種情況下就算從實體修復好之后重新上線,因為主實體的部分WAL歸檔檔案已經清理了,也無法再追趕上我們主實體的資料進度,從實體會直接報錯,因為有這種場景的存在所以 PostgreSQL 里面出現了一個復制槽的概念,主實體可以創建多個復制槽,一個復制槽系結給一個從實體使用,復制槽的好處在于會確保從實體獲取到WAL檔案之后才會進行清理,不會有前面說的滾動回圈自動清理的問題,
復制槽的維護都在主實體進行:創建,查詢,洗掉的陳述句如下
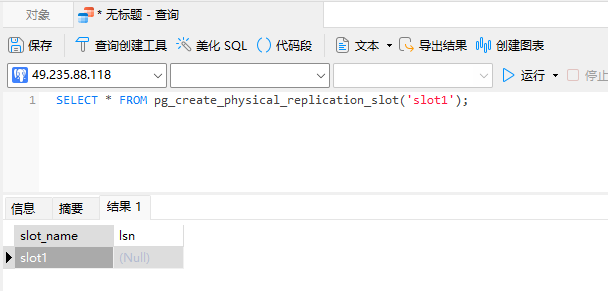
創建復制槽
SELECT * FROM pg_create_physical_replication_slot('slot1');
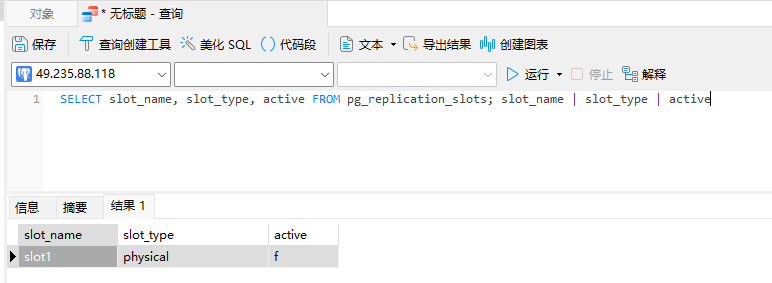
查詢全部的復制槽
SELECT slot_name, slot_type, active FROM pg_replication_slots; slot_name | slot_type | active
洗掉復制槽
SELECT * FROM pg_drop_replication_slot('slot1')
至此主實體的配置就都完成了,接下來就是準備我們的從實體,可以直接停止主實體的運行,然后把PostgreSQL檔案夾和Data整體打包壓縮復制一份到新的服務器上啟動起來作為從實體,
我這里選擇直接把云服務器上的 PostgreSQL 打包壓縮然后復制到本地解壓,作為從實體
在本地解壓之后,做為 從實體 需要做如下的調整,postgresql.conf
primary_conninfo = 'host=x.x.x.x port=5432 user=postgres password=xxxxxx application_name=s'
primary_slot_name = 'slot1'
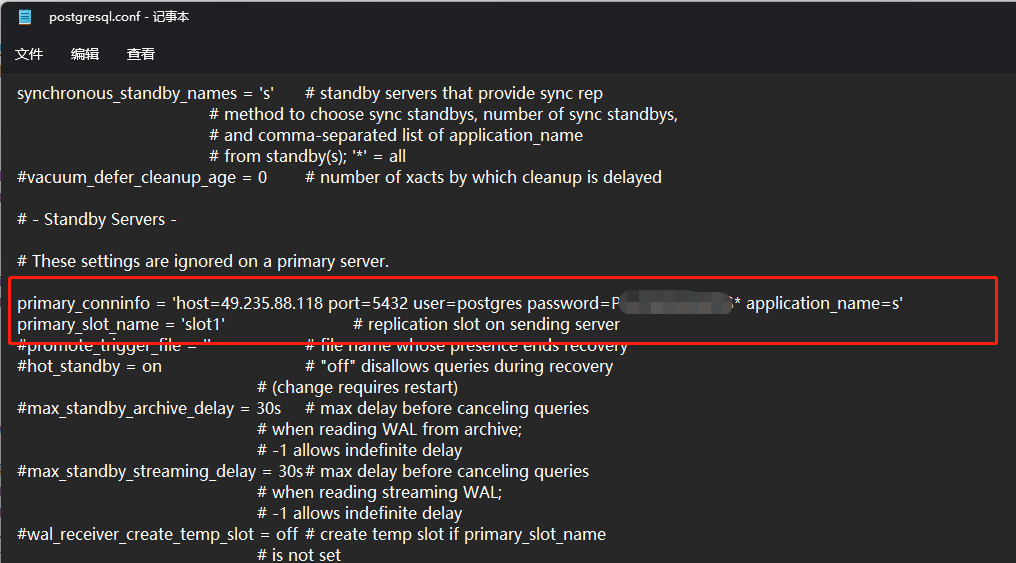
primary_conninfo 主要內容就是我們主實體的連接字串資訊然后加一個 application_name ,application_name 和我們前面在主實體上配置的 synchronous_standby_names 關聯,前面我們配置了主實體的所有事務操作都需要同步等待 名字為 s 的備庫執行完成
primary_slot_name 則是復制槽的名稱我們前面創建了一個 slot1 的復制槽,給我們的這個從實體使用,
這里需要注意一點,在配置的時候如果有多個從實體,則一個從實體對應一個復制槽,系結一個 application_name,
然后在 data 目錄下新建一個空檔案
standby.signal
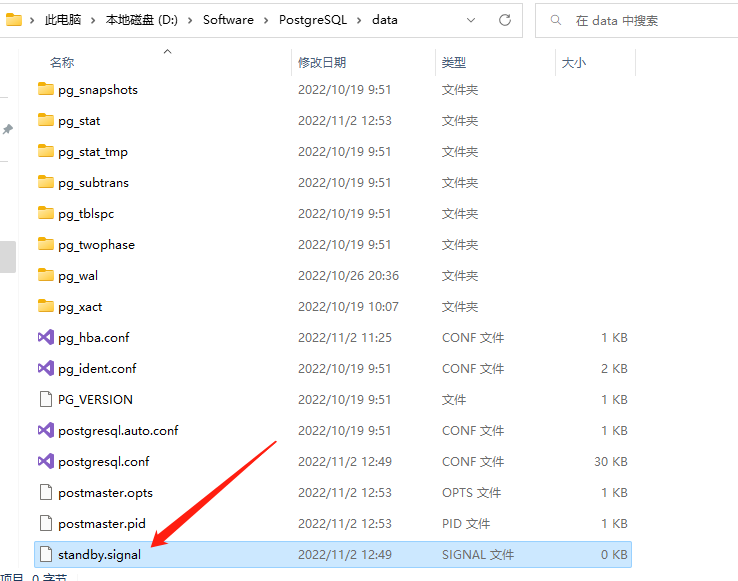
這個檔案的其實一個信號標記,標識我們當前的實體時一個只讀實體,不可以用于資料插入,
然后啟動備庫就可以了,正常情況會看到如下界面
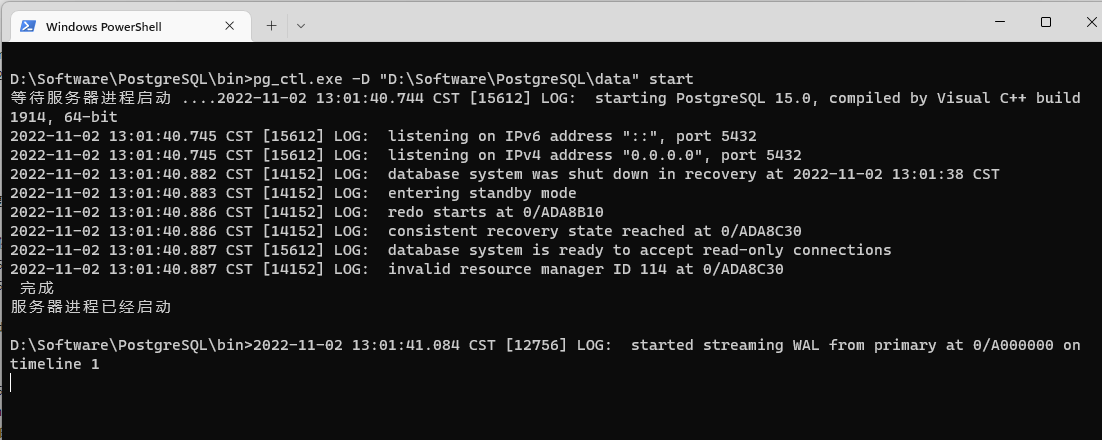
這時候我們可以嘗試去主實體創建一個資料庫做一些操作,然后連接從實體,就會發現兩邊都是互相同步的,
如果要解除從實體和主實體的關聯,操作如下:
從主實體的 postgresql.conf 找到 synchronous_standby_names 洗掉 s 節點的配置
#synchronous_standby_names='s'
如果只有一個從節點的,則直接添加 # 對 synchronous_standby_names 進行注釋即可
調整之后重啟主實體,
然后打開從實體的 postgresql.conf,注釋
#primary_conninfo
#primary_slot_name
配置節點的資訊,然后洗掉 data 目錄下的 standby.signal 檔案,重新啟動從實體即可,
至此 Windows 環境搭建 PostgreSQL 物理復制高可用架構資料庫服務 就講解完了,有任何不明白的,可以在文章下面評論或者私信我,歡迎大家積極的討論交流,有興趣的朋友可以關注我目前在維護的一個 .NET 基礎框架專案,專案地址如下
https://github.com/berkerdong/NetEngine.git
https://gitee.com/berkerdong/NetEngine.git
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/526052.html
標籤:PostgreSQL