摘要:DWS的負載管理分為兩層,第一層為cn的全域并發控制,第二層為資源池級別的并發控制,
本文分享自華為云社區《GaussDB(DWS) 并發管控&記憶體管控》,作者: fighttingman,
1背景
這里將并發管控和記憶體管控寫在一起,是因為記憶體管控實際是通過限制陳述句的并發達到記憶體管控的目的的,記憶體管控是基于陳述句的估算記憶體的前提下進行管控的,通俗的說就是陳述句有個估算記憶體,當資源池的剩余記憶體小于陳述句的估算記憶體時,這個陳述句就會排隊等待,等資源池內的陳述句執行完,資源池有足夠的剩余記憶體的時候,才會讓這個陳述句執行,所以記憶體管控的實際效果和陳述句的估算記憶體有很大關系,估算的大了就會造成大量陳述句排隊,實際沒有使用那么多記憶體,造成記憶體資源浪費,相反估算的小了,就會有很多陳述句下發,實際記憶體使用就會變多,就有陳述句報記憶體不足的錯誤風險,
資料庫系統的并發控制,在整個系統中起著很重要的作用,比如很多用戶的業務壓力過大時,有時會導致連接數量被占滿,有時會導致某種計算資源被占滿,有時會導致存盤空間被占滿,這些情況都會導致整個集群進入例外甚至不可用的狀態:正在執行的作業互相爭搶CPU,會導致大家都不能好好執行;大量作業執行時,占用大量記憶體,很容易觸發到記憶體瓶頸,造成作業記憶體不可用問題,導致業務報錯等等,在不進行并發控制的情況下,這些情況都很可能會出現,影響到正常業務,
2 總體介紹
DWS的負載管理分為兩層,第一層為cn的全域并發控制,第二層為資源池級別的并發控制,在通過第一層控制的時候,會繼續向前走到第二層資源池控制,根據資源池當前的負載資源情況決定作業繼續執行或者排隊,
基于DWS并發控制邏輯看出,實際作業執行中,可能會在兩種佇列中排隊:
一種是全域佇列(global queue)這種佇列不區分簡單和復雜作業,也不區分是DDL或者是普通陳述句,這種是每個cn生效,
一種是資源池佇列(resource pool queue),用戶下發的一般陳述句會根據資源消耗估算以及復雜程度在這里進行判斷是否排隊,
在兩層佇列的過濾下,DWS會篩選出當前能執行的陳述句,使其正常運行,運行時也會受到其所屬資源池資源的限制(只能使用資源池配置的CPU、記憶體、IO配額),
3 全域排隊
這里介紹幾個常用視圖以及SQL陳述句,可以迅速判斷目前的業務出現問題的原因,受限根據以下視圖可以看到目前的作業是不是在排隊,之后要迅速分析為什么在排隊,是因為負載管理各個引數配置問題,還是因為正在執行的陳述句占據了過多的資源導致的排隊,
pgxc_stat_activity (活躍視圖)
查詢當前執行時間最長的陳述句的排隊狀態,query_id(資料庫中作業的唯一標識),以及詳細的陳述句資訊,
select coorname,usename, current_timestamp-query_start as duration, enqueue,query_id,query from pgxc_stat_activity where state='active' and usename <> 'Ruby' order by duration desc;
根據該陳述句可以迅速判斷出哪些陳述句執行時間很長,是什么樣的陳述句執行很慢以及該陳述句的query_id,便于迅速進入下一步排查,
該視圖中enqueue欄位中如果顯示waiting in global queue就代表在全域排隊,全域排隊是受GUC引數max_active_statements引數控制的,是單cn生效的,也就是每個cn都可以支持這么大的并發量,比如集群中有3個cn實體,GUC引數max_active_statements引數設定為60,也就是說每個cn都支持60個陳述句并發執行,集群全域支持3 * 60 = 180并發執行作業,當下發作業大于這個cn設定的max_active_statements的時候就會進行全域排隊,在pgxc_stat_activity視圖中enqueue欄位就會顯示waiting in global queue,
4 資源池排隊
4.1 靜態負載管理
當GUC引數enable_dynamic_workload設定為off的時候就代表是靜態負載管理模式,靜態負載管理的情況下,pgxc_stat_activity視圖中enqueue欄位只會有waiting in respool queue,并發控制引數為資源池的max_dop(簡單作業)和active_statements(復雜作業),
1)簡單作業和復雜作業的定義
在靜態負載管理中,簡單作業是估算代價cost值小于GUC引數parctl_min_cost值的作業,反之則判定為復雜作業,該GUC引數默認為10W,
當parctl_min_cost為-1時,或者作業估算代價小于10時,作業都判定為簡單作業,
2)簡單作業并發限制
ALTER RESOURCE POOL resource_pool_a1 WITH (max_dop=10);
通過設定資源池的max_dop引數設定簡單作業并發,關聯資源池resource_pool_a1的用戶都受到這個引數的控制,當所有關聯這個資源池的用戶的所有作業數量之和大于這個引數的時候,就會進行資源池排隊,活躍視圖enqueue欄位就會顯示waiting in respool queue,
3)復雜作業并發限制
ALTER RESOURCE POOL resource_pool_a2 WITH (active_statements=10);
通過設定資源池的active_statements引數控制復雜作業的并發數,關聯資源池resource_pool_a2的用戶都受到這個引數的控制,
- 當MEM_PERCENT引數數值為0時,ACTIVE_STATEMENTS為x(1~INT_MAX),該資源池上的作業并發數不大于x,
- 當ACTIVE_STATEMENTS引數數值為-1且MEM_PERCENT為正值時,并發由運行作業的記憶體估值和MEM_PERCENT的取值決定,
- 當MEM_PERCENT引數數值為正值且ACTIVE_STATEMENTS為x(1~INT_MAX)時,并發由運行作業的記憶體估值和MEM_PERCENT的取值決定,且并發不能大于x,
- 當MEM_PERCENT引數數值為0且ACTIVE_STATEMENTS為-1時,資源池并發不受限,
資源池使用并發點數的計數方式來計算可執行的復雜作業并發數量,并發點數計算公式為
作業使用記憶體點數:active_points = (query_mem/respool_mem) * active_statements * 100
作業使用并發點數:active_points = 100
資源池總點數:total_points = active_statements * 100
單位點數: 100
4)相關說明
- 資源池分快慢車道,快車道管控簡單作業,慢車道管控復雜作業
- MAX_DOP對快車道并發進行限制,取值范圍為-1 ~ INT_MAX,默認為-1,表示不管控,
- ACTIVE_STATEMENTS取值范圍為 -1 ~ INT_MAX, 默認值為10,建議使用該默認值,當取值設定為0或者-1時,慢車道并發不受ACTIVE_STATEMENTS限制,
- MEM_PERCENT取值范圍為0~100,當取值設定為0時,慢車道并發不受MEM_PERCENT限制,
- 慢車道并發受ACTIVE_STATEMENTS和MEM_PERCENT限制,同時點數由ACTIVE_STATEMENTS決定,當ACTIVE_STATEMENTS=-1或0時,total_points=90,total_points點數耗盡后,慢車道查詢會觸發排隊操作,佇列滿足先進先出,
- query_mem為優化器估算的作業記憶體大小,即PG_SESSION_WLMSTAT視圖中的statement_mem;作業無估算記憶體數值時,不進行并發控制,
- respool_mem為資源池的實際記憶體,
4.2 動態負載管理
當GUC引數enable_dynamic_workload設定為on的時候就代表是動態負載管理模式,動態負載管理的情況下,pgxc_stat_activity視圖中enqueue欄位會有waiting in respool queue和waiting in global queue,
1)簡單作業和復雜作業的定義
動態負載管理下優化器估算記憶體大于32M認為是復雜作業,反之認為是簡單作業,
運行中的作業復雜簡單情況可以通過PG_SESSION_WLMSTAT中的attribute欄位查看,
2)動態負載管理相關說明
- 集群有一個CN會作為中心協調節點(CCN),用于收集和調度作業執行,該節點可以通過cm_ctl query -Cv查詢到,Central Coordinator State會顯示其狀態,當CCN不存在時,作業不再受動態負載管理控制,
- CCN上包含全域記憶體管控佇列和資源池佇列,目前暫不支持跨佇列優先級,在以下場景下優先級低的作業可能優先下發:如果優先級高的作業在全域記憶體管控佇列排隊,優先級低的作業在資源池佇列排隊,則優先級低的作業會優先下發,
- 單CN上依然受到max_active_statements引數限制,但不是強制限制,實際運行的作業可能稍微大于該數值,
- 簡單查詢作業(估算值<32MB)、非DML(即非INSERT、UPDATE、DELETE和SELECT)陳述句,不走自適應負載,需要通過max_active_statements來進行單CN的上限控制,
- 默認work_mem數值為512MB,在自適應負載特性下,該數值不能變大,否則會引起記憶體不受控(例如未做Analyze的陳述句),
- 作業估算記憶體小于等于0時,如果強制將作業指定為慢車道管控,作業不會發往CCN管控將直接運行,
- 以下場景或陳述句由于記憶體使用特殊性和不確定性,可能導致大并發場景記憶體不受控,如果遇到需要降低并發數,
- 單條元組占用記憶體過大的場景,例如,基表包含超過MB級別的寬列,
- 完全下推陳述句的查詢,
- 需要在CN上耗費大量記憶體的陳述句,例如,不能下推的陳述句,withhold cursor場景,
- 由于計劃生成不當導致hashjoin算子建立的hash表重復值過多,占用大量記憶體,
- 包含UDF的場景,且UDF中使用大量記憶體的場景,
3)短查詢加速(默認開啟,建議開啟)
混合負載場景下,復雜查詢可能會長時間占用大量資源,雖然簡單查詢執行時間短、消耗資源少,但是因為資源耗盡,簡單查詢不得不在佇列中等待復雜查詢執行完成,為提升執行效率、提高系統吞吐量,GaussDB(DWS)的“短查詢加速”功能,實作對簡單查詢的單獨管理,
- 開啟短查詢加速后,簡單查詢與復雜查詢分開管理,
- 關閉短查詢加速后,簡單查詢與復雜查詢執行相同的作業負載管理,
雖然單個簡單作頁澩消耗少,但是大量簡單作業并發運行還是會占用大量資源,因此短查詢加速開啟情況下,需要對簡單查詢進行并發管理;資源管理可能會影響查詢性能,影響系統吞吐量,因此簡單查詢不進行資源管理,例外規則也不生效,
設定方法:
- 通過GUC引數wlm_query_accelerate設定
- 通過資源池alter resource pool query_pool with(short_acc='f');
4.3 資源池記憶體管理
資源池的記憶體管理是基于陳述句的估算記憶體進行管理的,
1)資源池可用記憶體設定方法
ALTER RESOURCE POOL resource_pool_a1 WITH (MEM_PERCENT=20);
- 當MEM_PERCENT引數取值設定為0時,表示查詢作業的記憶體不受限,
- 當MEM_PERCENT引數取值設定為"x"(1<=x<=100)時,表示設定資源池使用的記憶體大小為可用記憶體大小的"x%",查詢作業將使用給定的記憶體來運行,
2)資源池作業估算記憶體限制設定方法
ALTER RESOURCE POOL resource_pool_a1 WITH (MEMORY_LIMIT="300MB");
- 當MEMORY_LIMIT引數取值設定為unlimited時,表示作業記憶體受資料庫記憶體限制,
- 當MEMORY_LIMIT引數取值設定為default時,表示作業記憶體限制為資源池記憶體的1/2,
- 當MEMORY_LIMIT引數取值設定為x kB/MB/GB時,表示作業記憶體限制為xkB/MB/GB,
- 當memory_limit配置小于256M時,為防止估算記憶體過小導致問題,作業估算記憶體上限為256MB,
5 資源管理相關視圖
GaussDB(DWS)對外提供諸多系統視圖,可以用來輔助資源管理及資源使用相關問題的分析定位,常用視圖及用法說明如下表所示,(☆代表常用程度)
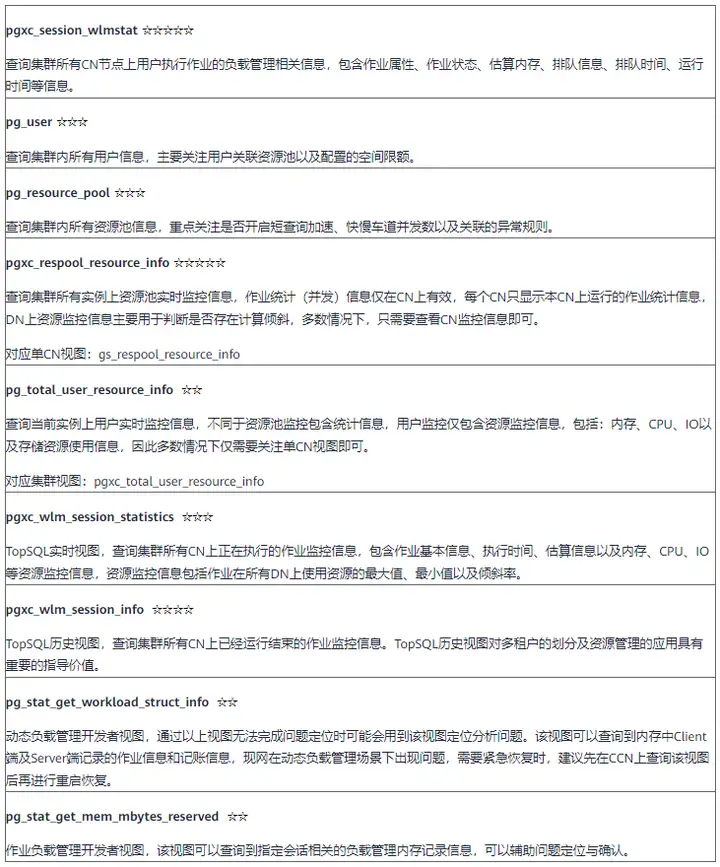
除過上述常用視圖,資源管理問題定位程序需要根據實際場景,結合實體日志、集群狀態等共同分析定位,
6 推薦配置
因為并發的配置和業務的復雜程度和集群的規格配置有很大的關系,本推薦僅做參考,推薦基于3CN 12DN,每個dn實體最大可使用64G記憶體情況下推薦的
在813內核版本及以上版本推薦配置如下,
GUC引數:
- max_active_statements 60 (每個cn的最大并發數,控制全域佇列排隊)
- enable_dynamic_workload on (開啟動態負載)
- wlm_query_accelerate -1 (開啟短查詢加速)
資源池引數:
- ALTER RESOURCE POOL resource_pool_a1 WITH (MAX_DOP=50) (簡單作業數50并發)
- ALTER RESOURCE POOL resource_pool_a1 WITH (active_statements=10) (復雜作業10并發)
7 并發控制常用定位方法及解決措施
7.1 排隊問題
出現業務阻塞、性能下降、查詢無回應等類似現網問題時,通過以下方法可以排查是否排隊問題并定位排隊原因,同時根據排隊原因給出相應規避措施,
7.1.1 確認是否排隊
首先確認是否排隊問題,其次排查排隊原因,確認是否屬于正常排隊:
- 813及以上版本查詢資源池監控視圖
select rpname,slow_run,slow_wait,slow_limit,used_cpu,cpu_limit,used_mem,estimate_mem from gs_respool_resource_info;
- 老版本查詢作業負載視圖
select resource_pool,attribute,lane,status,enqueue,sum(statement_mem) as stmt_mem,count(1) from pgxc_session_wlmstat where status!='finished' and attribute!='Internal' and usename!='Ruby' group by 1,2,3,4,5;
通過視圖可以獲取到各資源池快慢車道作業運行資訊,據此可以判斷是否排隊問題:
如果有作業處于排隊狀態,則可能是排隊導致的問題,否則排除排隊問題;可能的排隊原因包括:
- 單CN全域并發排隊;
- 快車道并發排隊;
- 靜態慢車道并發排隊;
- 靜態慢車道記憶體排隊;
- 動態CCN全域記憶體排隊;
- 動態CCN慢車道并發排隊;
- 動態CCN慢車道記憶體排隊,
排查排隊原因
常見排隊原因及解決措施
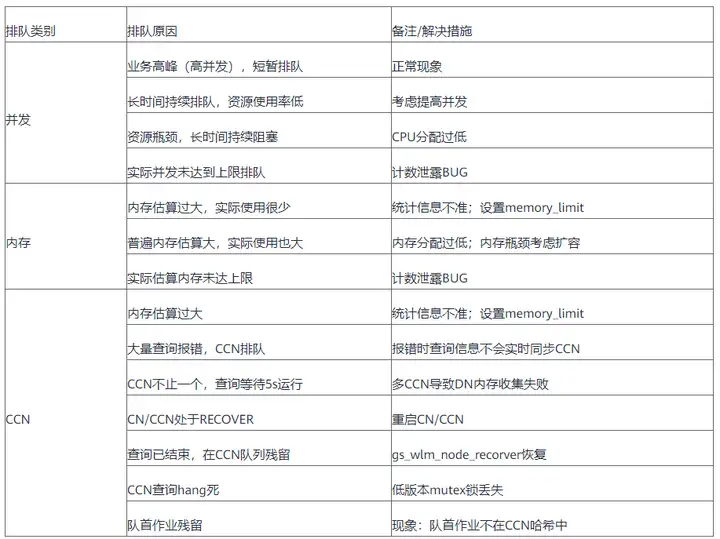
1)全域并發排隊
單CN實際運行作業數≥全域并發上限,則全域并發排隊正常;
單CN實際運行作業數長時間小于全域并發上限,則可能存在計數泄露,
2)快車道排隊
快車道實際運行作業數≥快車道并發上限,則快車道并發排隊正常;
快車道實際運行作業數長時間小于快車道并發上限,則可能存在計數泄露,
3)靜態慢車道排隊
慢車道實際運行作業數≥慢車道并發上限,則慢車道并發排隊正常;
慢車道實際運行作業累計估算記憶體≥慢車道記憶體上限,則慢車道記憶體占用達到上限導致排隊,關注是否有查詢估算記憶體過大;
如果慢車道并發和記憶體占用長時間達不到上限,則可能存在計數泄露,
4)動態CCN排隊
如果查詢在CCN排隊,則需要查詢CCN開發者視圖確認排隊原因:
select * from pg_stat_get_workload_struct_info();
CCN上可能的排隊原因:
- CCN全域可用記憶體不足導致排隊,此時需特別關注是否有查詢估算記憶體過大;
- 資源池實際運行作業數≥慢車道車道并發上限,資源池并發上限,正常排隊;
- 資源池實際運行作業累計估算記憶體≥慢車道記憶體上限,則慢車道記憶體占用達到上限導致排隊,此時需特別關注是否有查詢估算記憶體過大;
- 資源池實際運行作業數或占用記憶體與記賬值不符,則可能存在計數泄露BUG;
- 隊首作業在CCN哈希中不存在,說明隊首作業殘留導致查詢不能正常下發;
- CN/CCN處于recover狀態或收集DN記憶體資訊失敗(多CCN)導致所有查詢等待5s下發,現象為所有查詢排隊時間均為5~6s,
8 常見案例
8.1 CCN排隊
1)查詢資源池監控視圖,確認是否正常排隊(813及以上版本)
下面以單CN下發作業為例,多CN下發作業需查詢pgxc_respool_resource_info視圖,
select rpname,slow_run,slow_wait,slow_limit,used_cpu,cpu_limit,used_mem,estimate_mem from gs_respool_resource_info;
- 如果slow_wait不等于0,說明有查詢在CCN排隊,否則無查詢排隊;
- 如果slow_run大于等于slow_limit,說明達到慢車道并發上限導致排隊,否則說明不是并發過大導致排隊;
- 如果estimate_mem大于資源池記憶體上限,說明記憶體不足導致排隊,否則說明不是記憶體不足導致排隊;
- 如果used_mem長時間遠小于estimate_mem,說明該資源池上運行作業估算記憶體過大,可以嘗試analyze;
- 如果used_mem大于estimate_mem,則查詢可能觸發記憶體二次擴展(默認資源池)或查詢記憶體不可控;
- 如果used_cpu長時間接近甚至大于等于cpu_limit,說明資源池分配CPU過少,可能導致作業大量堆積;
通過該查詢可以直觀的觀察各資源池作業負載資訊,如果資源池running作業并發、記憶體長時間無法達到資源池上限,則考慮是否存在排隊例外,
2)查詢作業負載視圖(813以下版本)
813及以上版本建議使用上邊方法確認是否有排隊例外,當然也可以使用以下方法確認存在排隊例外,排除特性BUG影響,
813以下版本僅有pg_session_wlmstat視圖,沒有pgxc視圖,可通過以下陳述句創建臨時pgxc視圖:
CREATE OR REPLACE VIEW pgxc_session_wlmstat_tp AS SELECT * FROM pg_catalog.pgxc_parallel_query('cn', 'SELECT pg_catalog.pgxc_node_str(), * FROM pg_catalog.pg_session_wlmstat') AS ( nodename name, datid oid, datname name, threadid bigint, processid integer, usesysid oid, appname text, usename name, priority bigint, attribute text, block_time bigint, elapsed_time bigint, total_cpu_time bigint, cpu_skew_percent integer, statement_mem integer, active_points integer, dop_value integer, control_group text, status text, enqueue text, resource_pool name, query text, is_plana boolean, node_group text, lane text );
查詢集群內各資源池在所有CN上的作業運行、排隊統計資訊:
select resource_pool,attribute,lane,status,enqueue,sum(statement_mem) as stmt_mem,count(1) from pgxc_session_wlmstat where status!='finished' and attribute!='Internal' and usename!='Ruby' group by 1,2,3,4,5;
通過該查詢可以直觀的觀察各資源池作業負載資訊,如果資源池running作業并發、記憶體長時間無法達到資源池上限,則考慮是否存在排隊例外,
確認是否存在排隊例外
如果經過前兩個步驟分析,懷疑可能存在排隊例外,可能的原因有以下幾種:
- 大批作業一開始運行就報錯退出,依靠CCN周期任務完成作業同步和喚醒;
- CCN全域記憶體排隊導致資源池并發、記憶體長時間無法達到資源池上限,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/538257.html
標籤:大數據