Flink的API分層
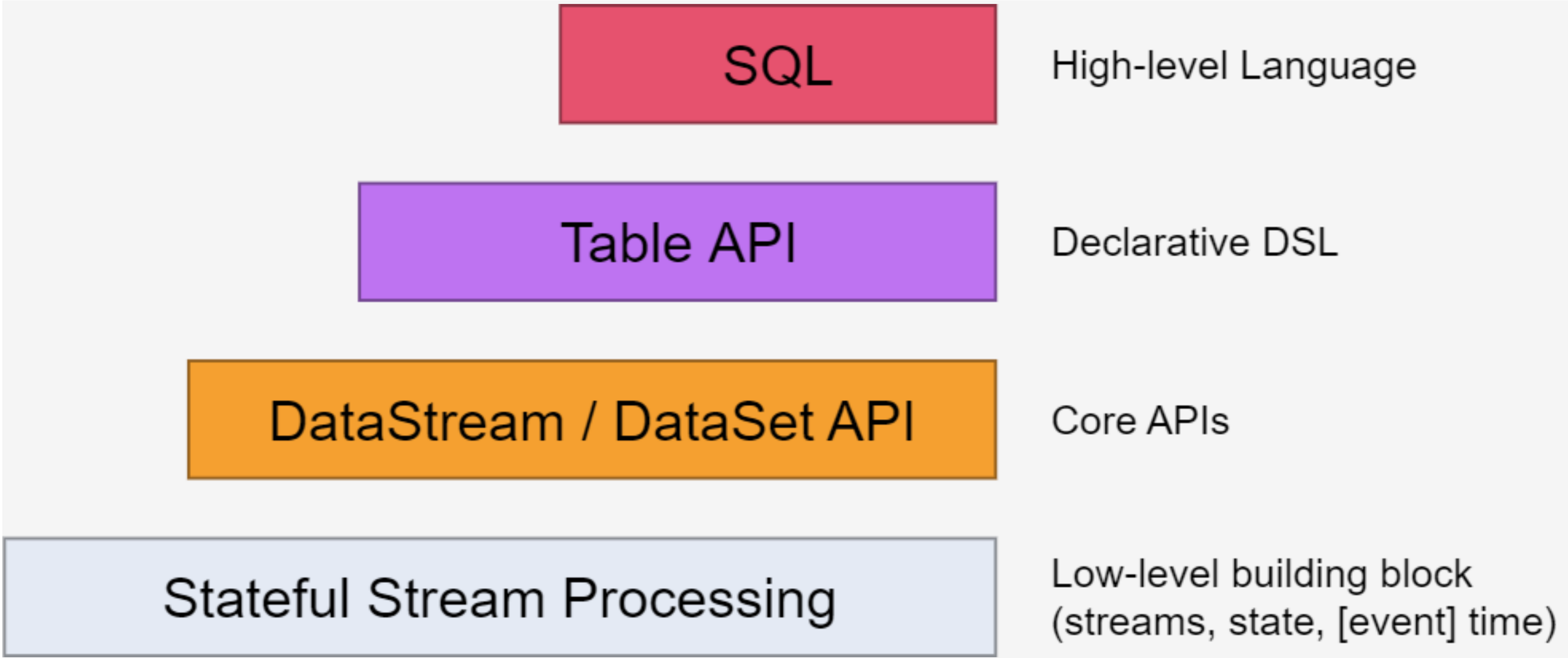
注:越底層API越靈活,越上層的API越輕便
Stateful Stream Processing
? 位于最底層, 是core API 的底層實作
? processFunction
? 利用低階,構建一些新的組件或者算子
? 靈活性高,但開發比較復雜
Core API
? DataSet - 批處理 API
? DataStream –流處理 API
Table API & SQL
? SQL 構建在Table 之上,都需要構建Table 環境
? 不同的型別的Table 構建不同的Table 環境
? Table 可以與DataStream或者DataSet進行相互轉換
? Streaming SQL不同于存盤的SQL,最侄訓轉化為流式執行計劃
Flink架構
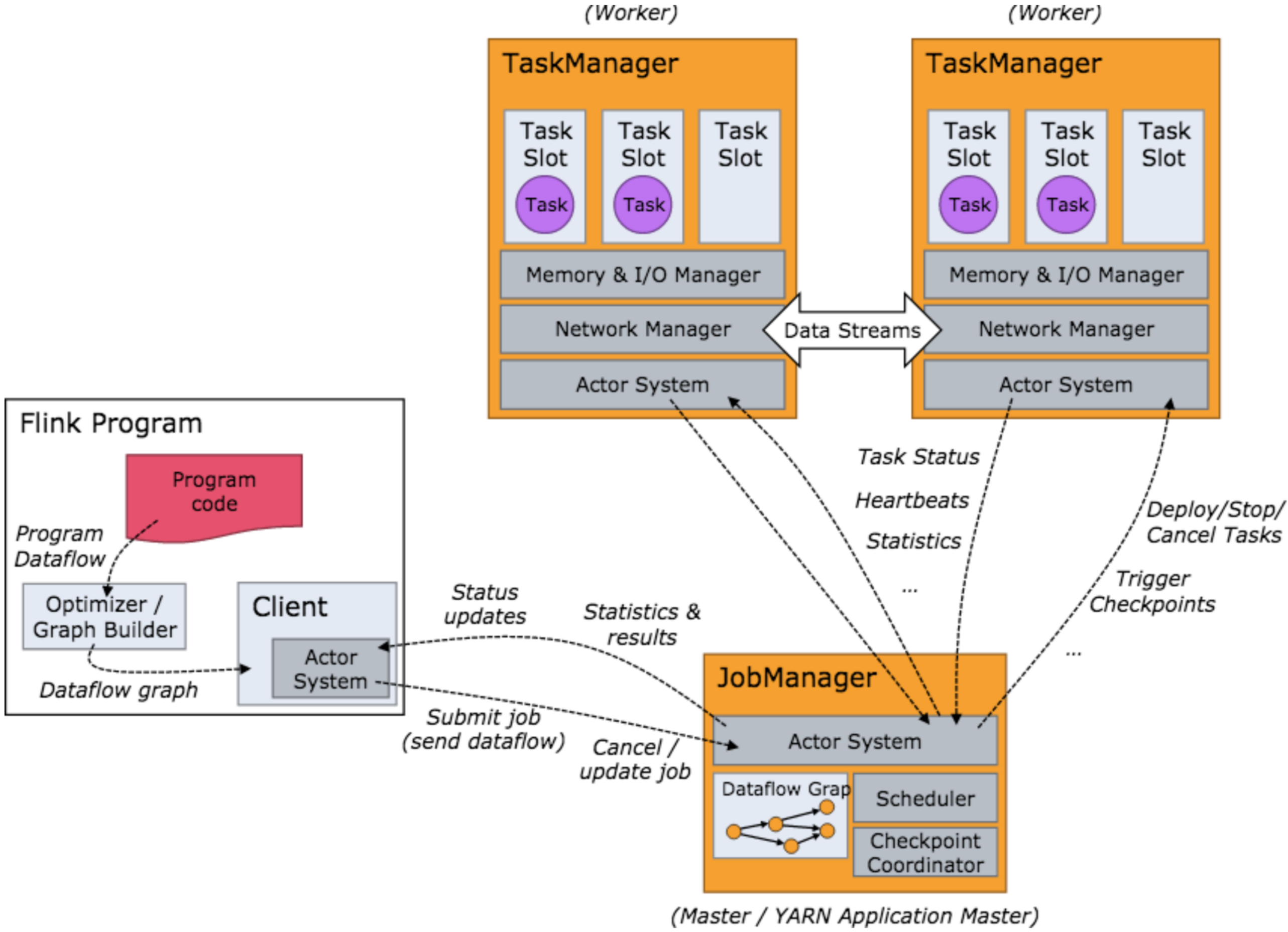
當 Flink 集群啟動后,首先會啟動一個 JobManger 和一個或多個的 TaskManager,由 Client 提交任務給 JobManager,JobManager 再調度任務到各個 TaskManager 去執行,然后 TaskManager 將心跳和統計資訊匯報給 JobManager,TaskManager 之間以流的形式進行資料的傳輸,上述三者均為獨立的 JVM 行程,
? Client 為提交 Job 的客戶端,可以是運行在任何機器上(與 JobManager 環境連通即可),提交 Job 后,Client 可以結束行程(Streaming的任務),也可以不結束并等待結果回傳,
? JobManager 主要負責從 Client 處接收到 Job 和 JAR 包等資源后,會生成優化后的執行計劃,并以 Task 的單元調度到各個 TaskManager 去執行,
? TaskManager 在啟動的時候就設定好了槽位數(Slot),每個 slot 能啟動一個 Task,Task 為執行緒,從 JobManager 處接收需要部署的 Task,部署啟動后,與自己的上游建立 Netty 連接,接收資料并處理,
? flnik架構中的角色間的通信使用Akka,資料的傳輸使用Netty
Task Slot
在上圖中我們介紹了 TaskManager 是一個 JVM 行程,并會以獨立的執行緒來執行一個task或多個subtask,為了控制一個 TaskManager 能接受多少個 task,Flink 提出了 Task Slot 的概念,
Flink 中的計算資源通過 Task Slot 來定義,每個 task slot 代表了 TaskManager 的一個固定大小的資源子集,例如,一個擁有3個slot的 TaskManager,會將其管理的記憶體平均分成三分分給各個 slot,將資源 slot 化意味著來自不同job的task不會為了記憶體而競爭,而是每個task都擁有一定數量的記憶體儲備,需要注意的是,這里不會涉及到CPU的隔離,slot目前僅僅用來隔離task的記憶體,
通過調整 task slot 的數量,用戶可以定義task之間是如何相互隔離的,每個 TaskManager 有一個slot,也就意味著每個task運行在獨立的 JVM 中,每個 TaskManager 有多個slot的話,也就是說多個task運行在同一個JVM中,而在同一個JVM行程中的task,可以共享TCP連接(基于多路復用)和心跳訊息,可以減少資料的網路傳輸,也能共享一些資料結構,一定程度上減少了每個task的消耗,
task的并行度
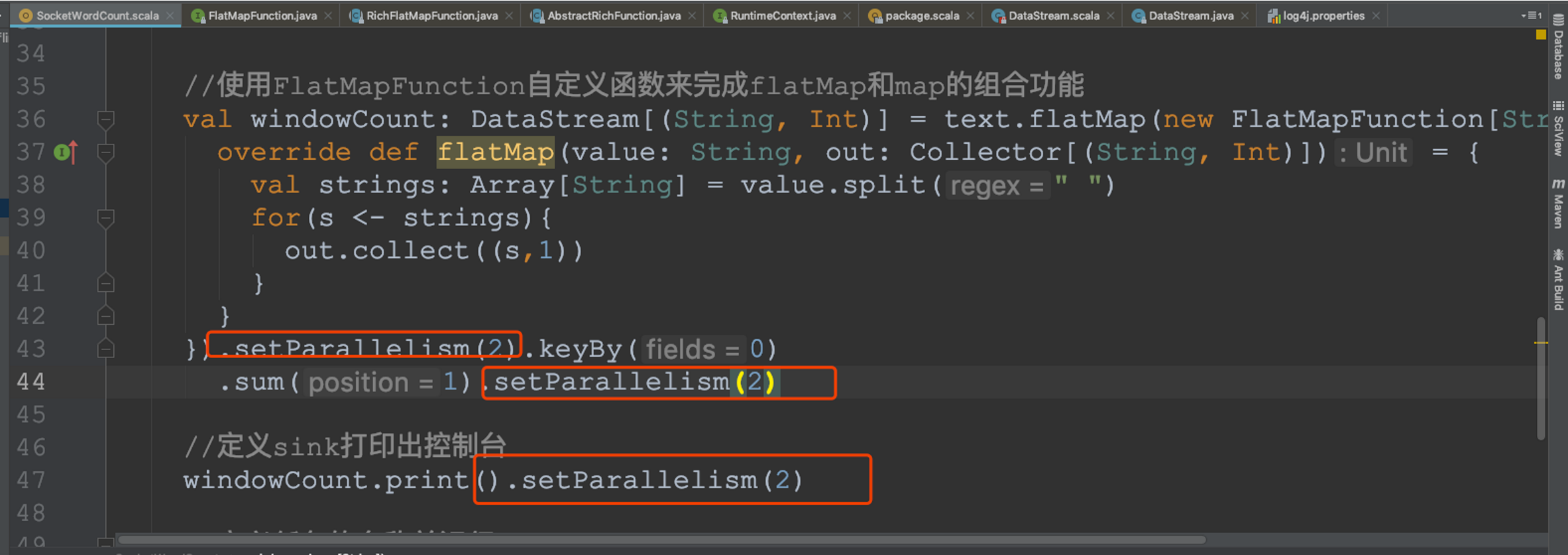
通過job的webUI界面查看任務的并行度
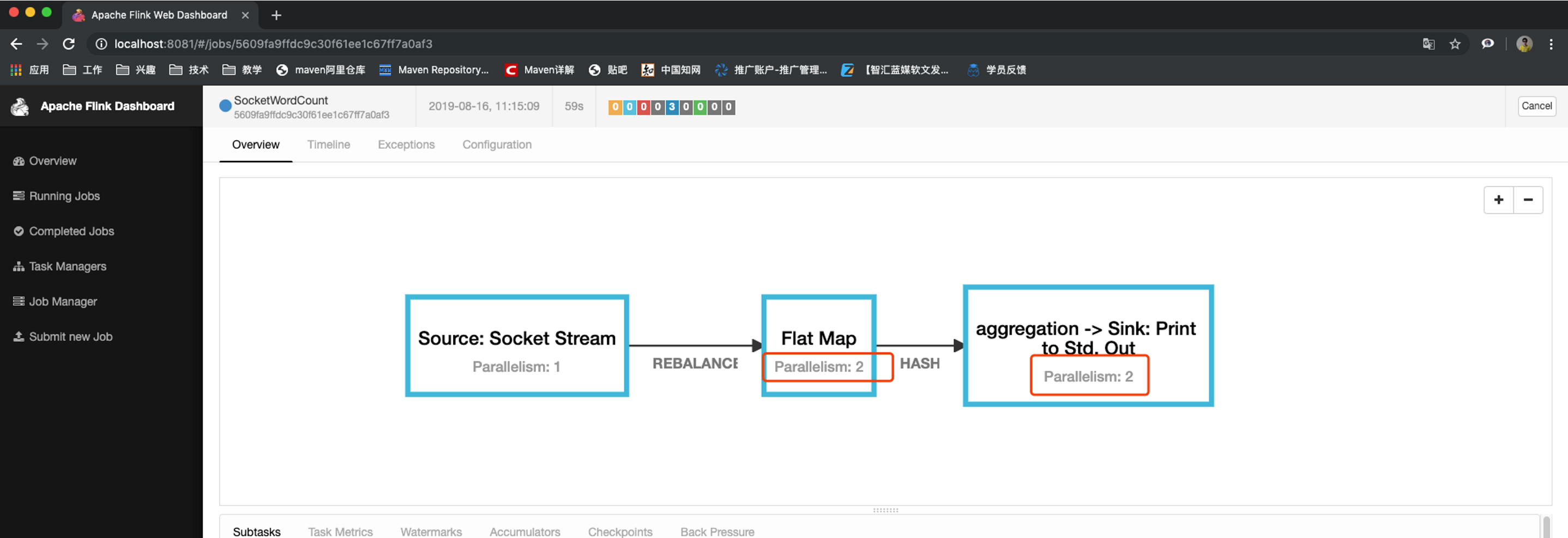
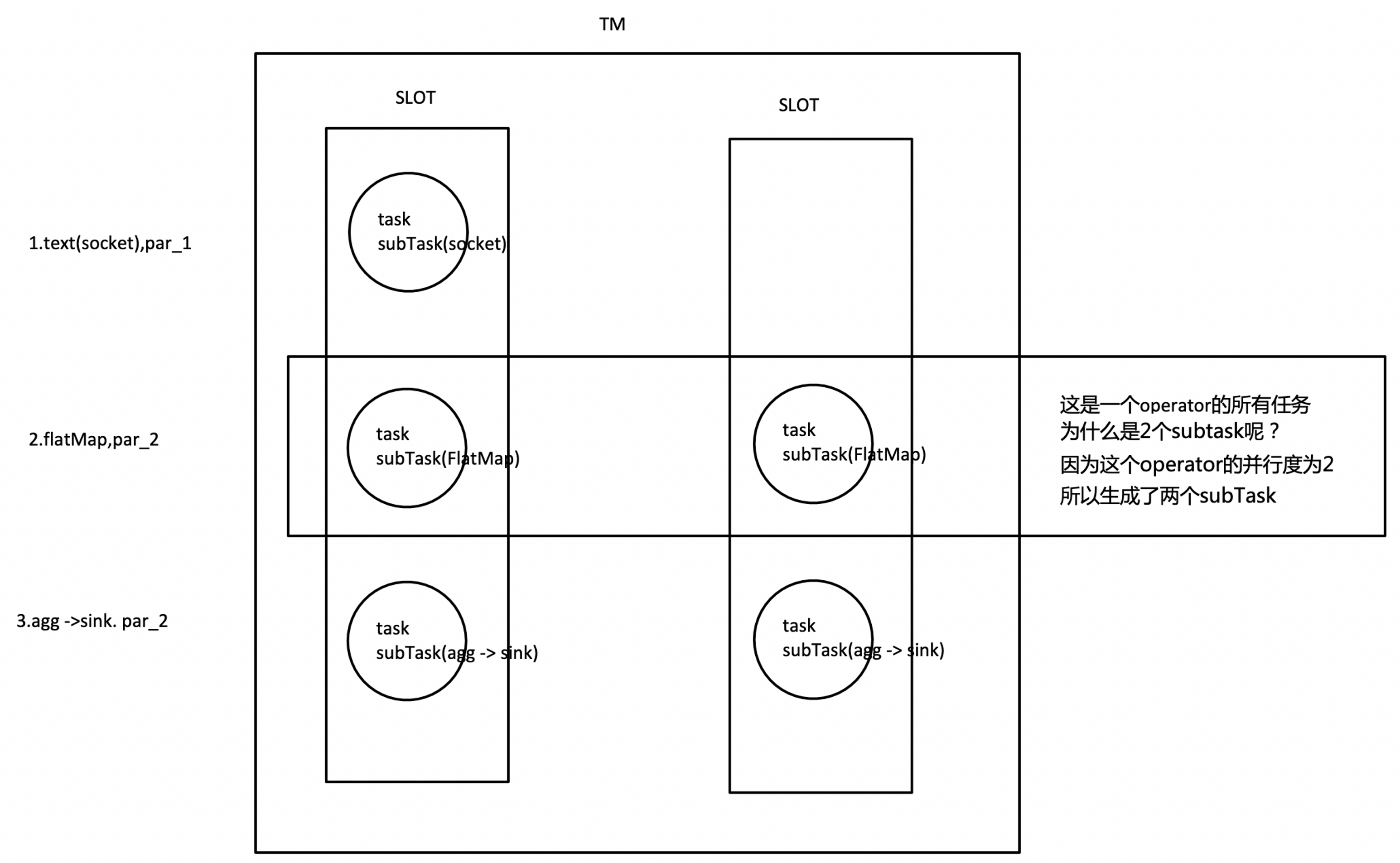
任務執行計劃
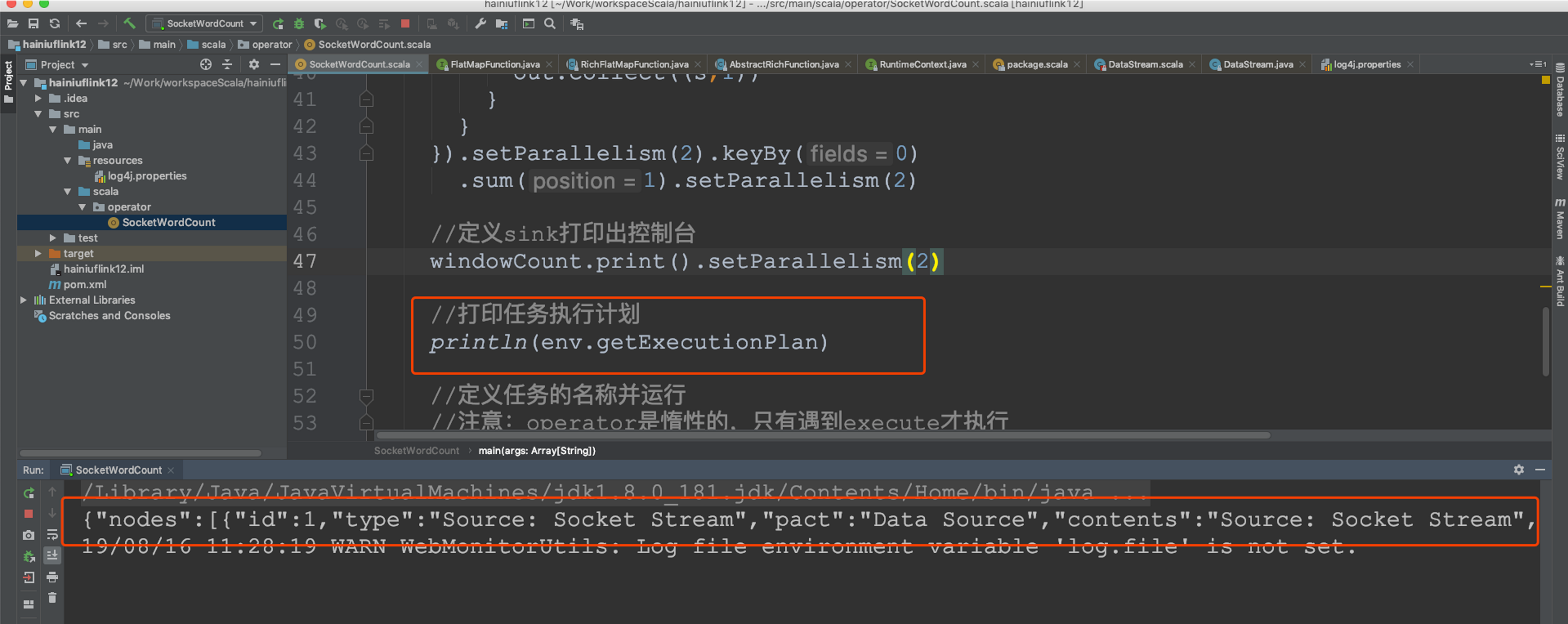
生成個json字串然后粘貼在這里 https://flink.apache.org/visualizer/會看到任務執行圖
但這并不是最終在 Flink 中運行的執行圖,只是一個表示拓撲節點關系的計劃圖,在 Flink 中對應了 SteramGraph,另外,提交拓撲后(并發度設為2)還能在 UI 中看到另一張執行計劃圖,如下所示,該圖對應了 Flink 中的 JobGraph,

其實Flink 中的執行圖可以分成四層:StreamGraph -> JobGraph -> ExecutionGraph -> 物理執行圖
? StreamGraph:是根據用戶通過 Stream API 撰寫的代碼生成的最初的圖,用來表示程式的拓撲結構,
? JobGraph:StreamGraph經過優化后生成了 JobGraph,提交給 JobManager 的資料結構,主要的優化為,將多個符合條件的節點 chain 在一起作為一個節點,這樣可以減少資料在節點之間流動所需要的序列化/反序列化/傳輸消耗,
? ExecutionGraph:JobManager 根據 JobGraph 生成ExecutionGraph,ExecutionGraph是JobGraph的并行化版本,是調度層最核心的資料結構,
? 物理執行圖:JobManager 根據 ExecutionGraph 對 Job 進行調度后,在各個TaskManager 上部署 Task 后形成的“圖”,并不是一個具體的資料結構,
例如上文中的2個并發度(Source為1個并發度)的 SocketTextStreamWordCount 四層執行圖的演變程序如下圖所示:
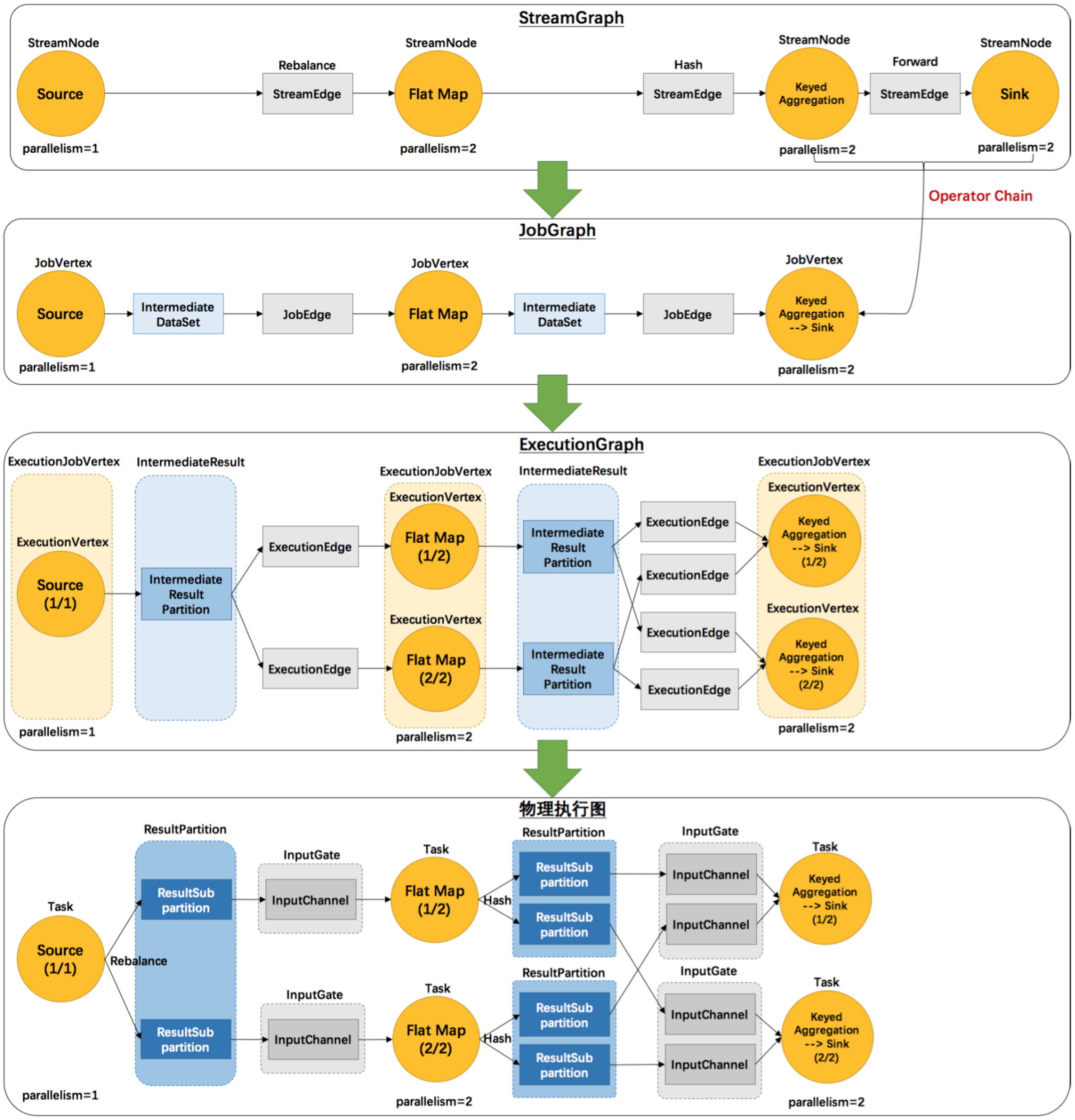
那么 Flink 為什么要設計這4張圖呢,其目的是什么呢?Spark 中也有多張圖,資料依賴圖以及物理執行的DAG,其目的都是一樣的,就是解耦,每張圖各司其職,每張圖對應了 Job 不同的階段,更方便做該階段的事情,我們給出更完整的 Flink Graph 的層次圖,
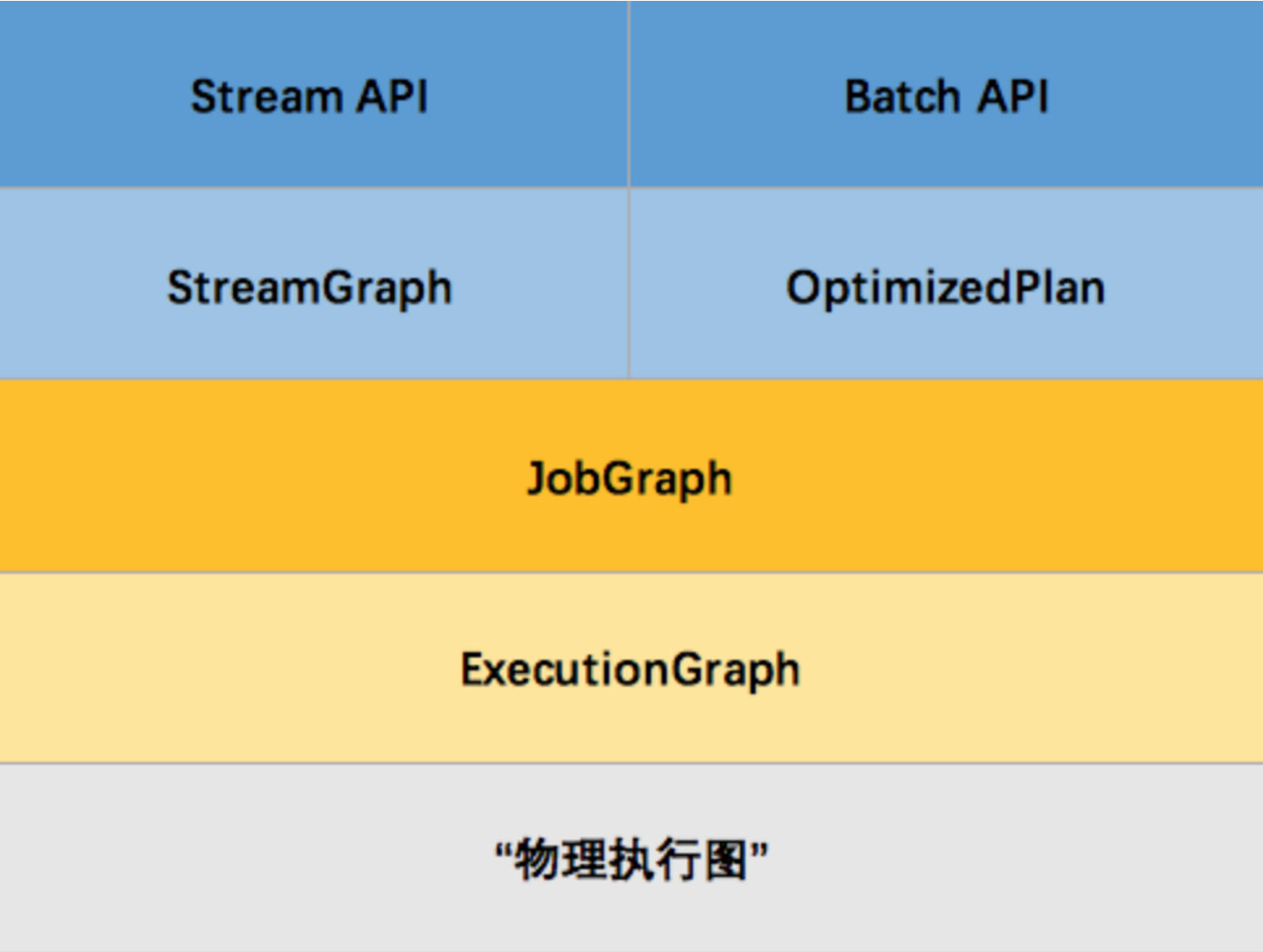
首先我們看到,JobGraph 之上除了 StreamGraph 還有 OptimizedPlan,OptimizedPlan 是由 Batch API 轉換而來的,StreamGraph 是由 Stream API 轉換而來的,為什么 API 不直接轉換成 JobGraph?因為,Batch 和 Stream 的圖結構和優化方法有很大的區別,比如 Batch 有很多執行前的預分析用來優化圖的執行,而這種優化并不普適于 Stream,所以通過 OptimizedPlan 來做 Batch 的優化會更方便和清晰,也不會影響 Stream,JobGraph 的責任就是統一 Batch 和 Stream 的圖,用來描述清楚一個拓撲圖的結構,并且做了 chaining 的優化,chaining 是普適于 Batch 和 Stream 的,所以在這一層做掉,ExecutionGraph 的責任是方便調度和各個 tasks 狀態的監控和跟蹤,所以 ExecutionGraph 是并行化的 JobGraph,而“物理執行圖”就是最終分布式在各個機器上運行著的tasks了,所以可以看到,這種解耦方式極大地方便了我們在各個層所做的作業,各個層之間是相互隔離的,
8.Operator Chains
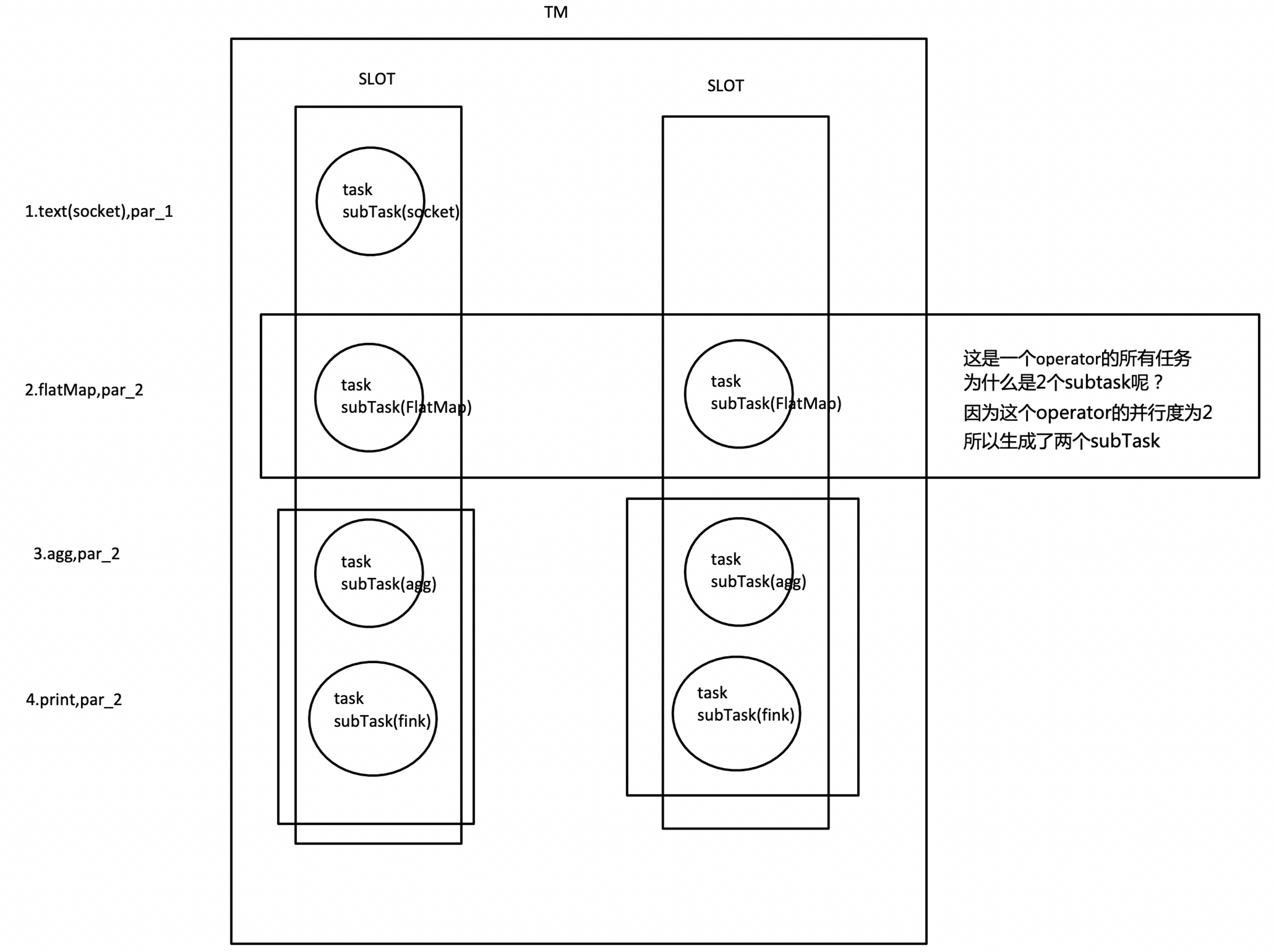
為了更高效地分布式執行,Flink會盡可能地將operator的subtask鏈接(chain)在一起形成task,每個task在一個執行緒中執行,將operators鏈接成task是非常有效的優化:它能減少執行緒之間的切換,減少訊息的序列化/反序列化,減少資料在緩沖區的交換,減少了延遲的同時提高整體的吞吐量,
我們仍以上面的 WordCount 為例,下面這幅圖,展示了Source并行度為1,FlatMap、KeyAggregation、Sink并行度均為2,最終以5個并行的執行緒來執行的優化程序,
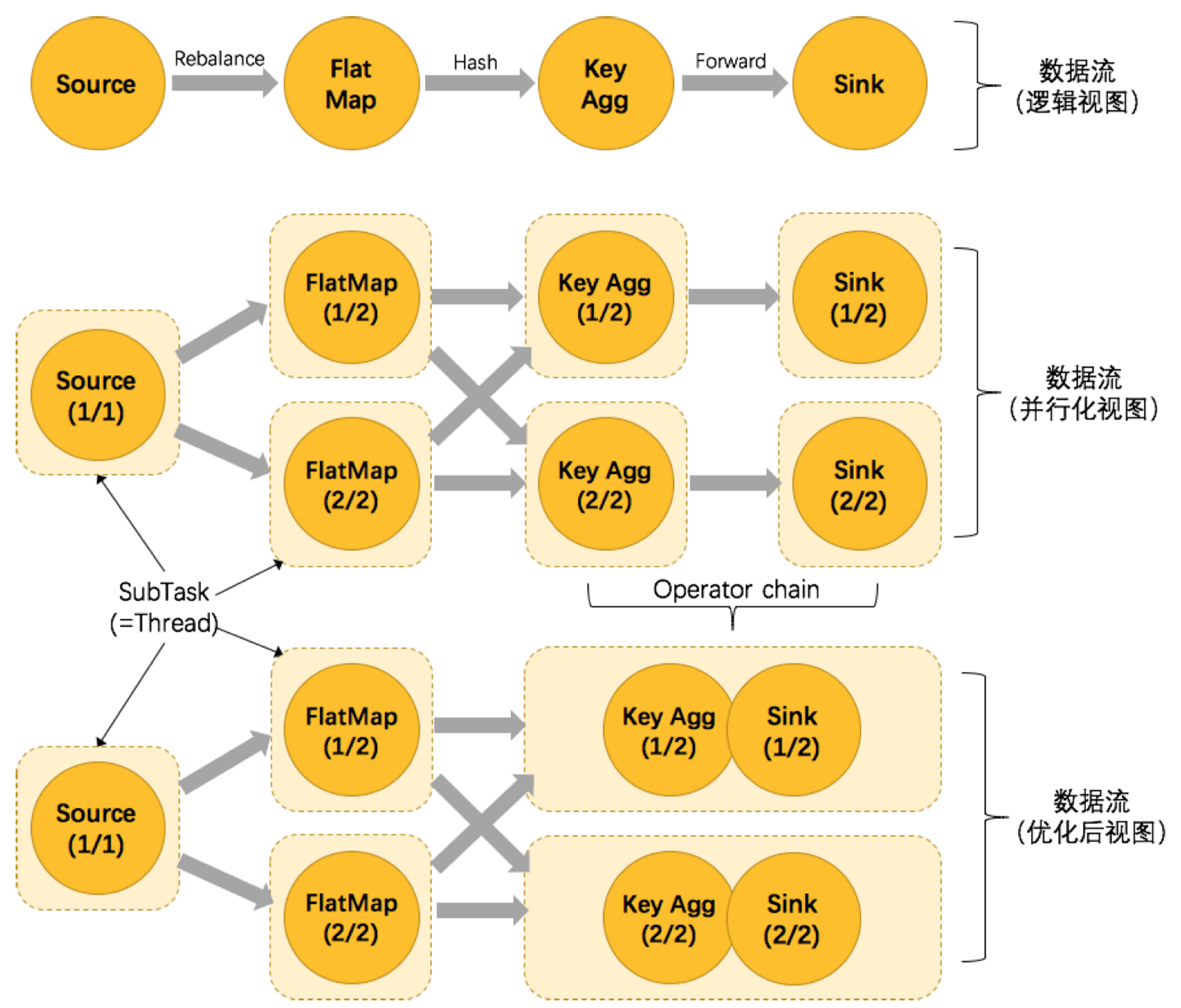
上圖中將KeyAggregation和Sink兩個operator進行了合并,因為這兩個合并后并不會改變整體的拓撲結構,但是,并不是任意兩個 operator 就能 chain 一起的,其條件還是很苛刻的:
1. 上下游的并行度一致
2. 下游節點的入度為1 (也就是說下游節點沒有來自其他節點的輸入)
3. 上下游節點都在同一個 slot group 中(下面會解釋 slot group)
4. 下游節點的 chain 策略為 ALWAYS(可以與上下游鏈接,map、flatmap、filter等默認是ALWAYS)
5. 上游節點的 chain 策略為 ALWAYS 或 HEAD(只能與下游鏈接,不能與上游鏈接,Source默認是HEAD)
6. 
7. 上下游算子之間沒有資料shuffle (資料磁區方式是 forward)
8. 用戶沒有禁用 chain
Operator chain的行為可以通過編程API中進行指定,可以通過在DataStream的operator后面(如someStream.map(..))呼叫startNewChain()來指示從該operator開始一個新的chain(與前面截斷,不會被chain到前面),或者呼叫disableChaining()來指示該operator不參與chaining(不會與前后的operator chain一起),在底層,這兩個方法都是通過調整operator的 chain 策略(HEAD、NEVER)來實作的,另外,也可以通過呼叫StreamExecutionEnvironment.disableOperatorChaining()來全域禁用chaining,
代碼驗證:
? operator禁用chaining
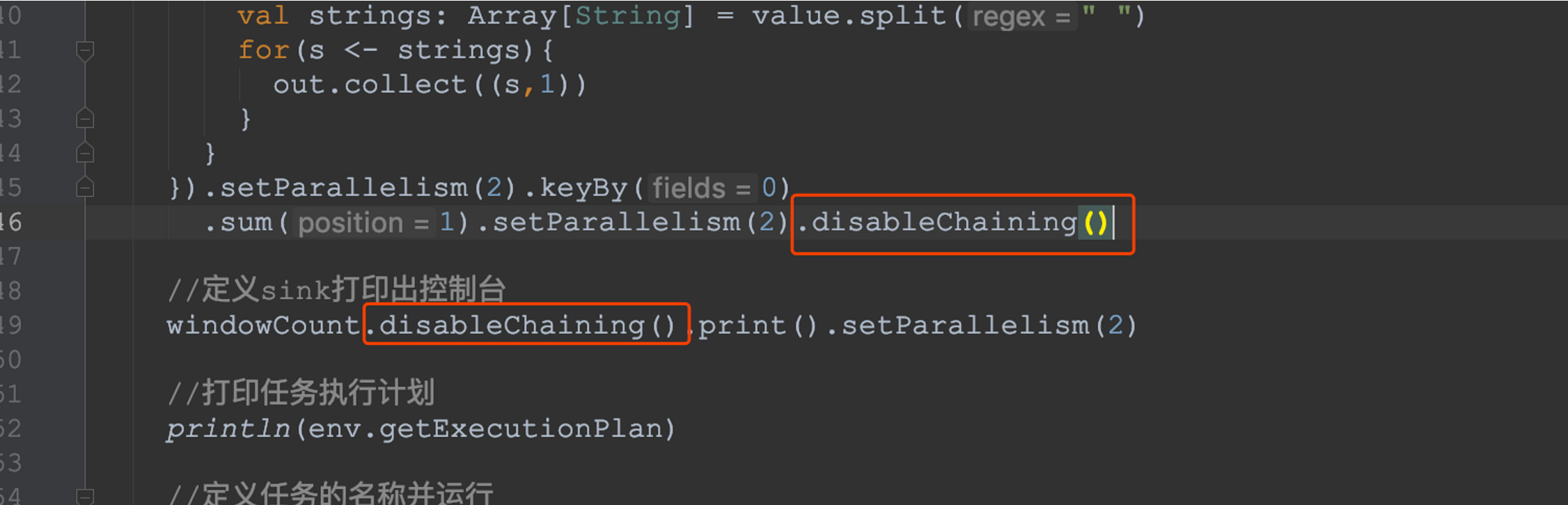
? 全域禁用chaining
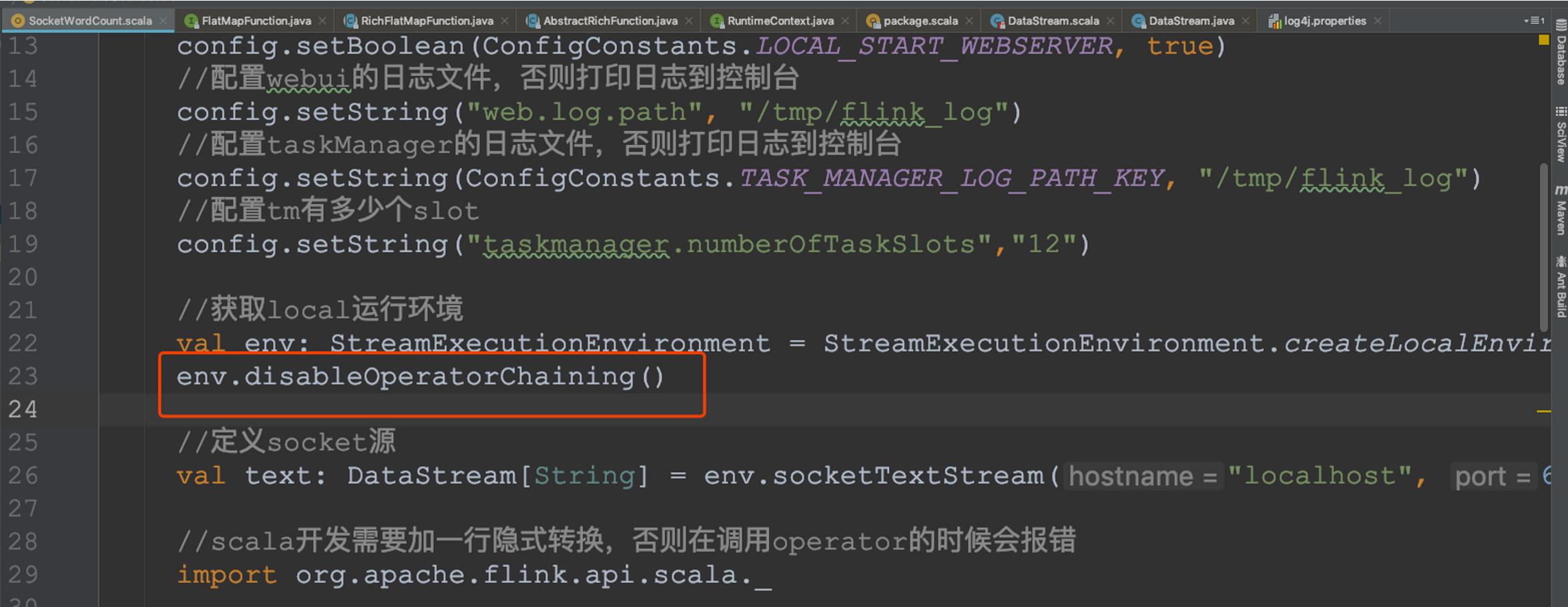
? 查看job的graph圖
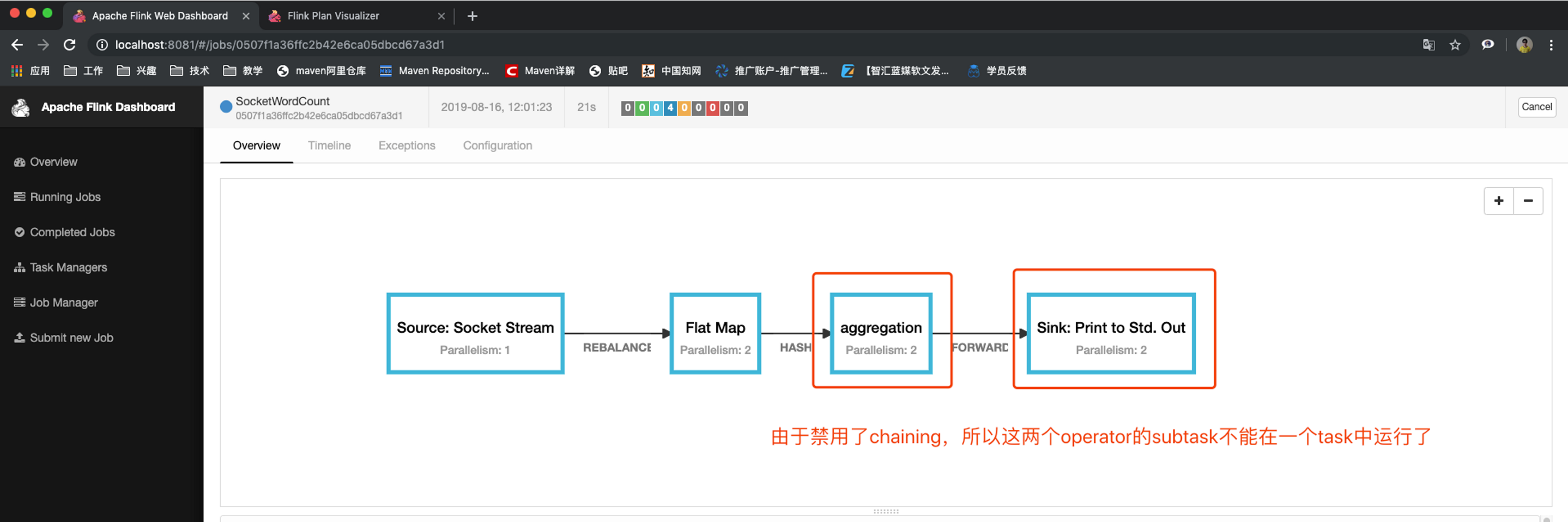
OperatorChain的優缺點:
那么 Flink 是如何將多個 operators chain在一起的呢?chain在一起的operators是如何作為一個整體被執行的呢?它們之間的資料流又是如何避免了序列化/反序列化以及網路傳輸的呢?下圖展示了operators chain的內部實作:
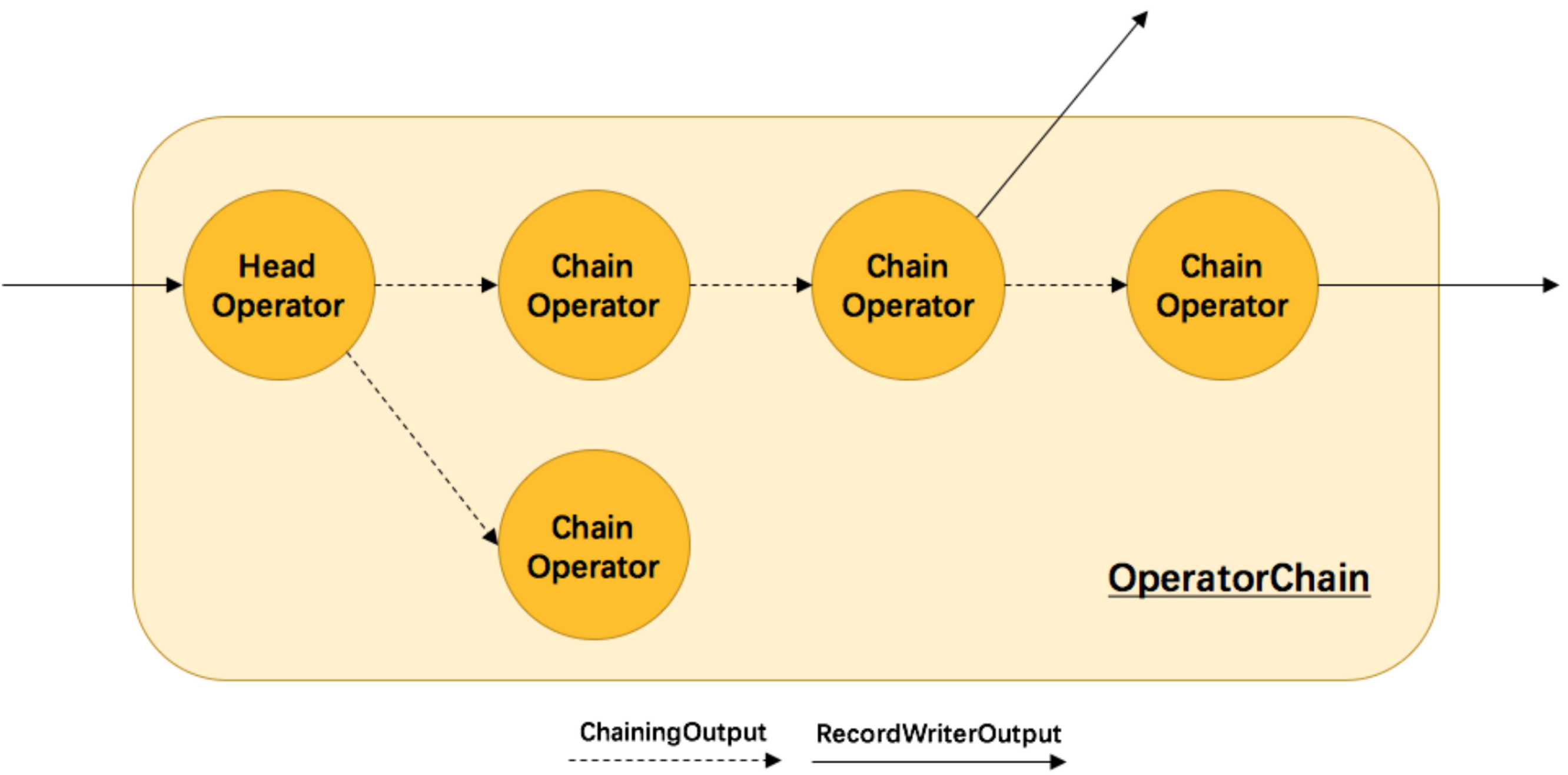
如上圖所示,Flink內部是通過OperatorChain這個類來將多個operator鏈在一起形成一個新的operator,OperatorChain形成的框框就像一個黑盒,Flink 無需知道黑盒中有多少個ChainOperator、資料在chain內部是怎么流動的,只需要將input資料交給 HeadOperator 就可以了,這就使得OperatorChain在行為上與普通的operator無差別,上面的OperaotrChain就可以看做是一個入度為1,出度為2的operator,所以在實作中,對外可見的只有HeadOperator,以及與外部連通的實線輸出,這些輸出對應了JobGraph中的JobEdge,在底層通過RecordWriterOutput來實作,另外,框中的虛線是operator chain內部的資料流,這個流內的資料不會經過序列化/反序列化、網路傳輸,而是直接將訊息物件傳遞給下游的 ChainOperator 處理,這是性能提升的關鍵點,在底層是通過 ChainingOutput 實作的
OperatorChain的優點總結:
? 減少執行緒切換
? 減少序列化與反序列化
? 減少資料在緩沖區的交換
? 減少延遲并且提高吞吐能力
OperatorChain的缺點總結:
? 可能會讓N個比較復雜的業務跑在一個slot中,本來一個業務就慢,這發生這種情況就更慢了,所以可以通過startNewChain()/disableChaining()或全域禁用disableOperatorChaining()給分開
SlotSharingGroup 與 CoLocationGroup
每一個 TaskManager 會擁有一個或多個的 task slot,每個 slot 都能跑由多個連續 task 組成的一個 pipeline,比如 MapFunction 的第n個并行實體和 ReduceFunction 的第n個并行實體可以組成一個 pipeline,
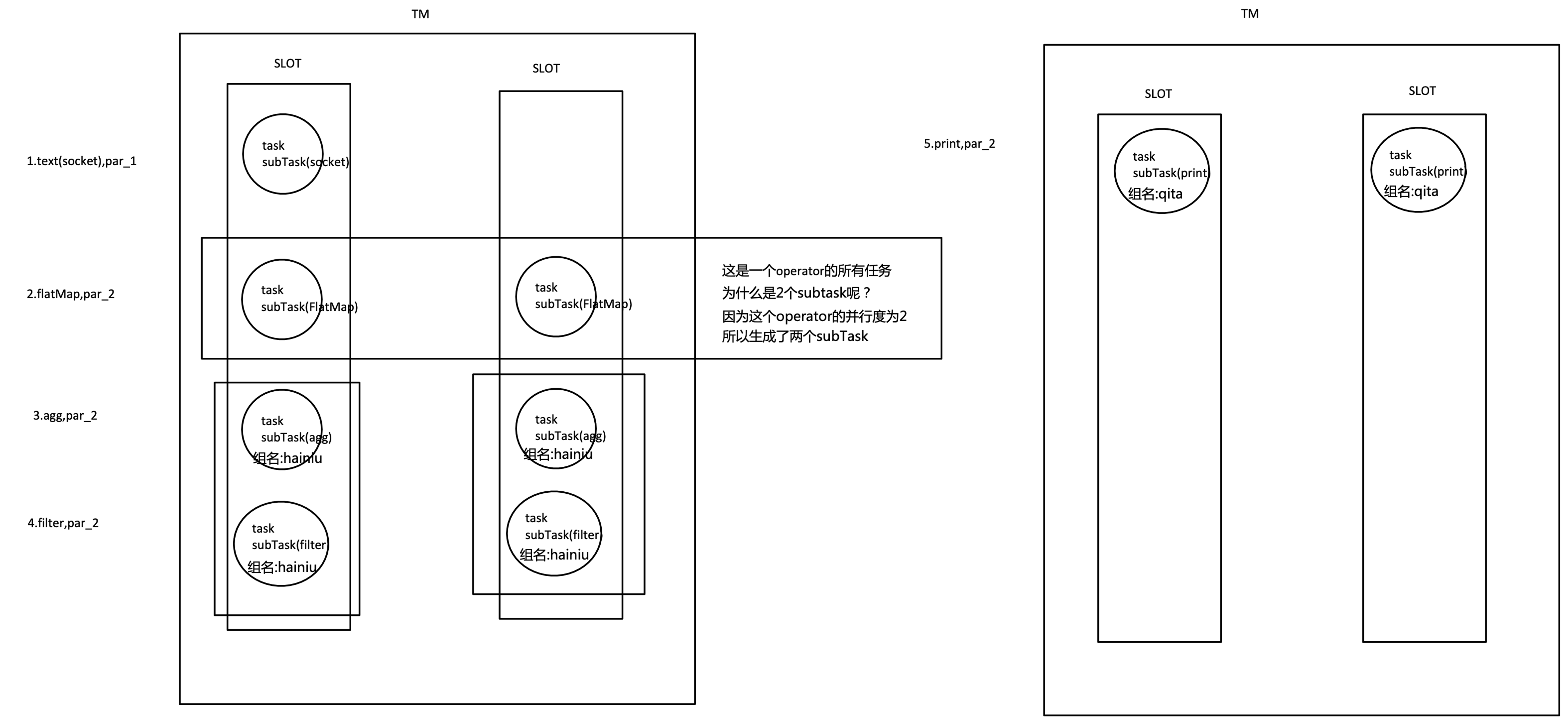
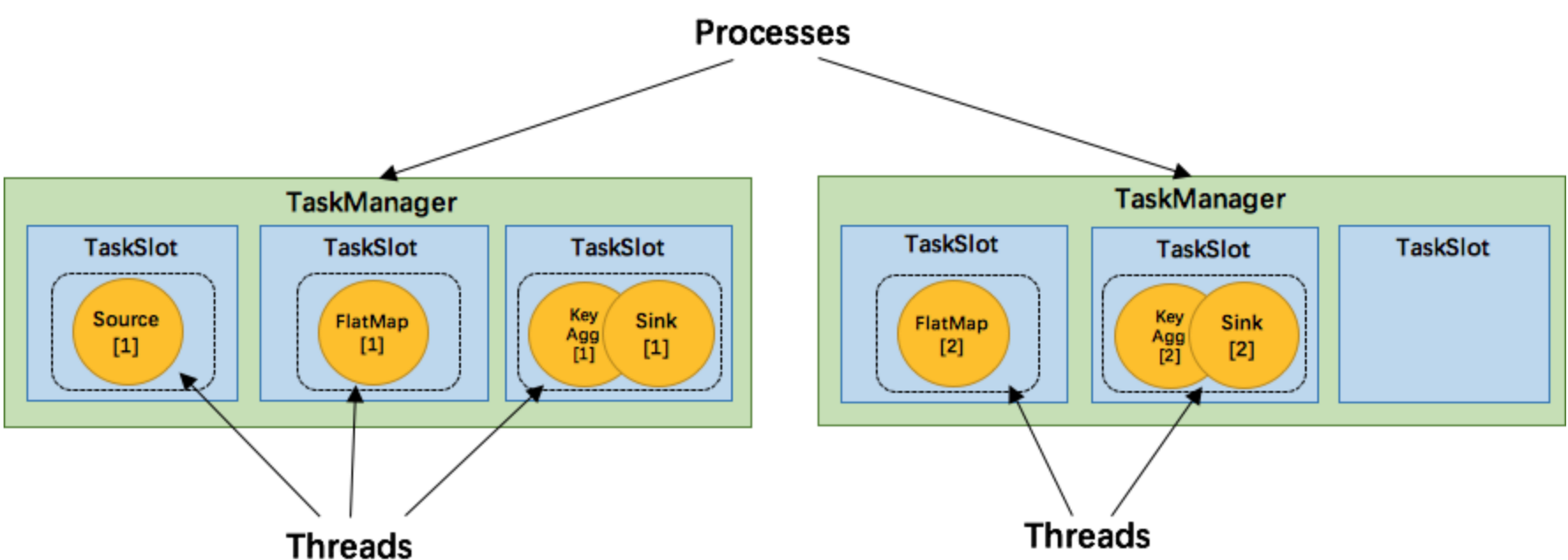
如上文所述的 WordCount 例子,5個Task沒有solt共享的時候在TaskManager的slots中如下圖分布,2個TaskManager,每個有3個slot:
默認情況下,Flink 允許subtasks共享slot,條件是它們都來自同一個Job的不同task的subtask,結果可能一個slot持有該job的整個pipeline,允許slot共享有以下兩點好處:
1. Flink 集群所需的task slots數與job中最高的并行度一致,
2. 更容易獲得更充分的資源利用,如果沒有slot共享,那么非密集型操作source/flatmap就會占用同密集型操作 keyAggregation/sink 一樣多的資源,如果有slot共享,將基線的2個并行度增加到6個,能充分利用slot資源,同時保證每個TaskManager能平均分配到相同數量的subtasks,
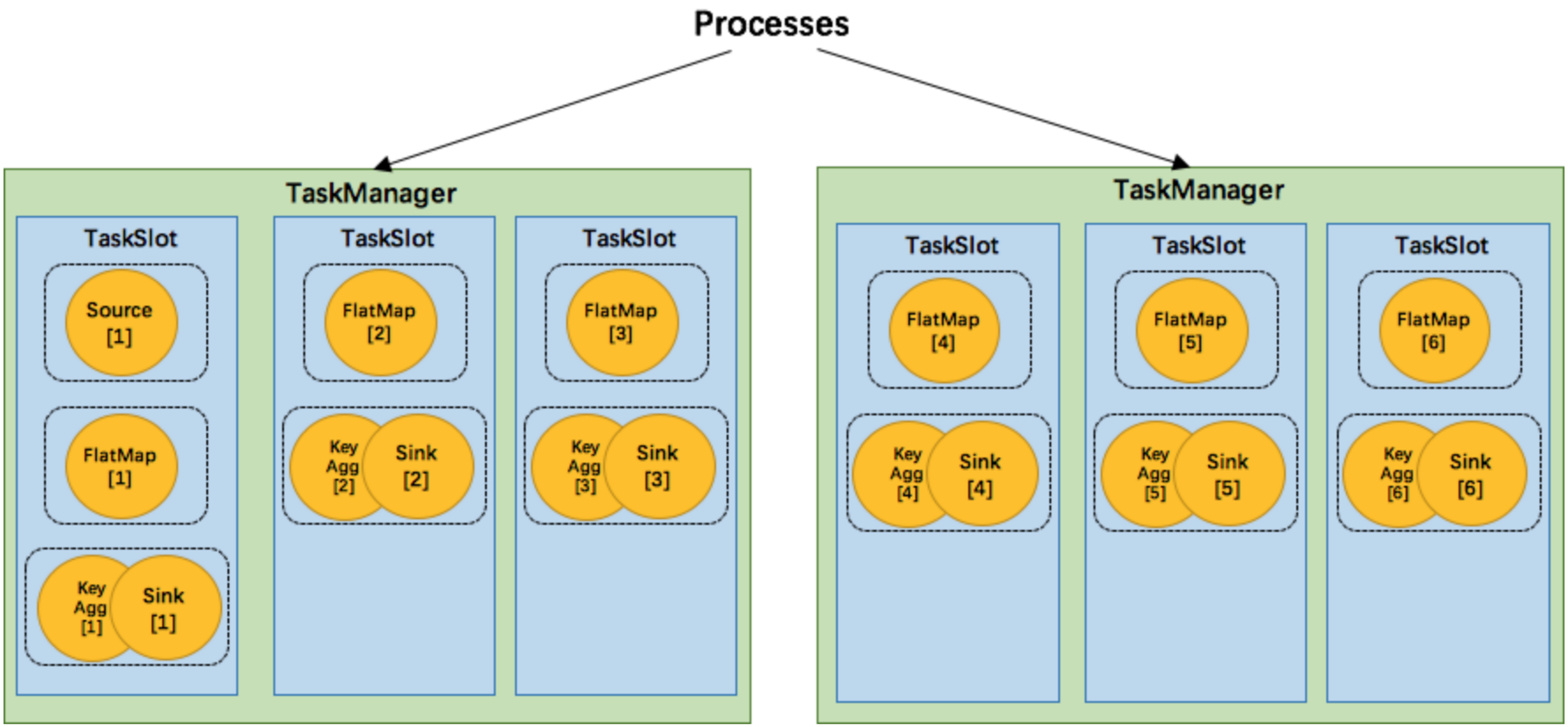
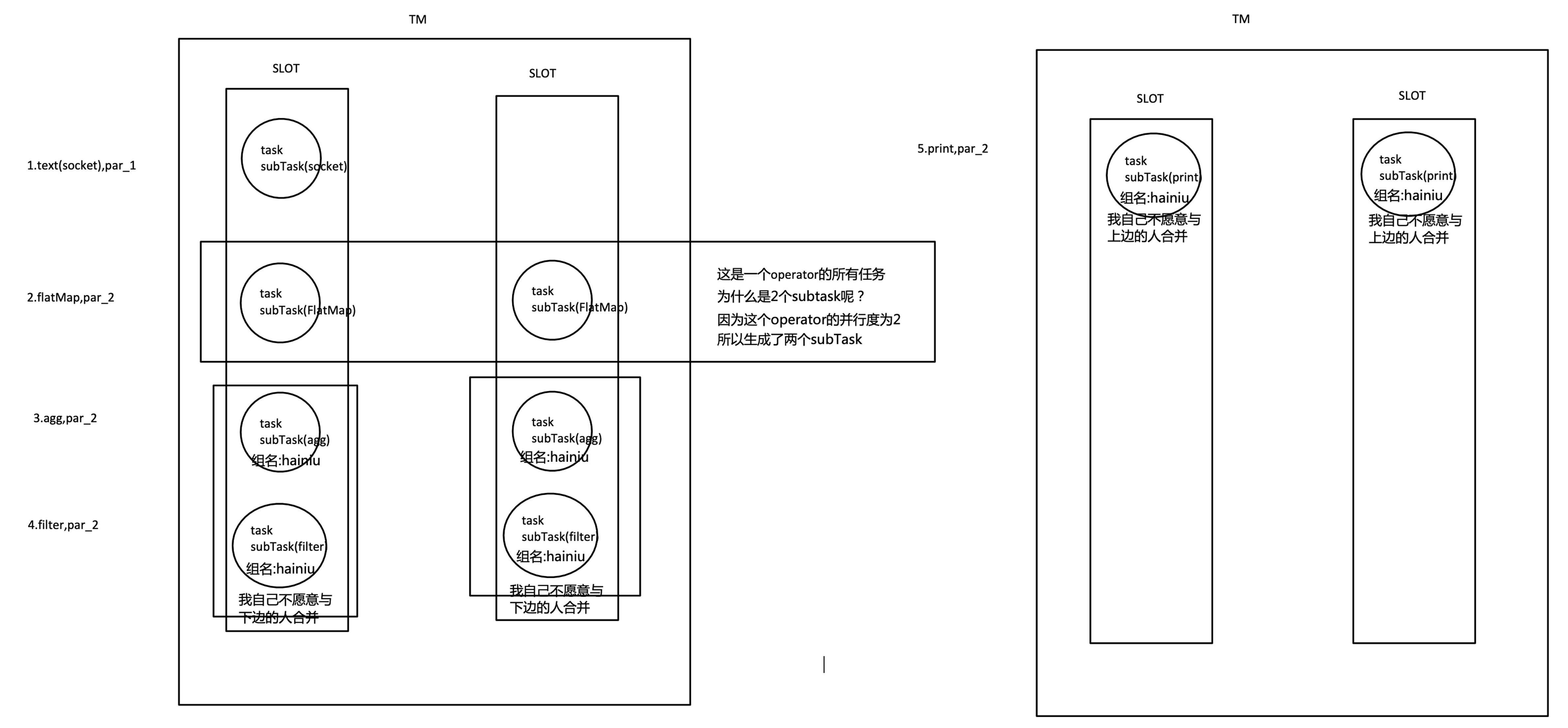
我們將 WordCount 的并行度從之前的2個增加到6個(Source并行度仍為1),并開啟slot共享(所有operator都在default共享組),將得到如上圖所示的slot分布圖,該任務最侄訓占用6個slots(最高并行度為6),其次,我們可以看到密集型操作 keyAggregation/sink 被平均地分配到各個 TaskManager,
SlotSharingGroup:
? SlotSharingGroup是Flink中用來實作slot共享的類,它盡可能地讓subtasks共享一個slot,
? 保證同一個group的并行度相同的sub-tasks 共享同一個slots
? 算子的默認group為default(即默認一個job下的subtask都可以共享一個slot)
? 為了防止不合理的共享,用戶也能通過API來強制指定operator的共享組,比如:someStream.filter(...).slotSharingGroup("group1");就強制指定了filter的slot共享組為group1,
? 怎么確定一個未做SlotSharingGroup設定的算子的Group是什么呢(根據上游算子的 group 和自身是否設定group共同確定)
? 適當設定可以減少每個slot運行的執行緒數,從而整體上減少機器的負載
CoLocationGroup(強制):
? 保證所有的并行度相同的sub-tasks運行在同一個slot
? 主要用于迭代流(訓練機器學習模型)
代碼驗證:
? 設定本地開發環境tm的slot數量
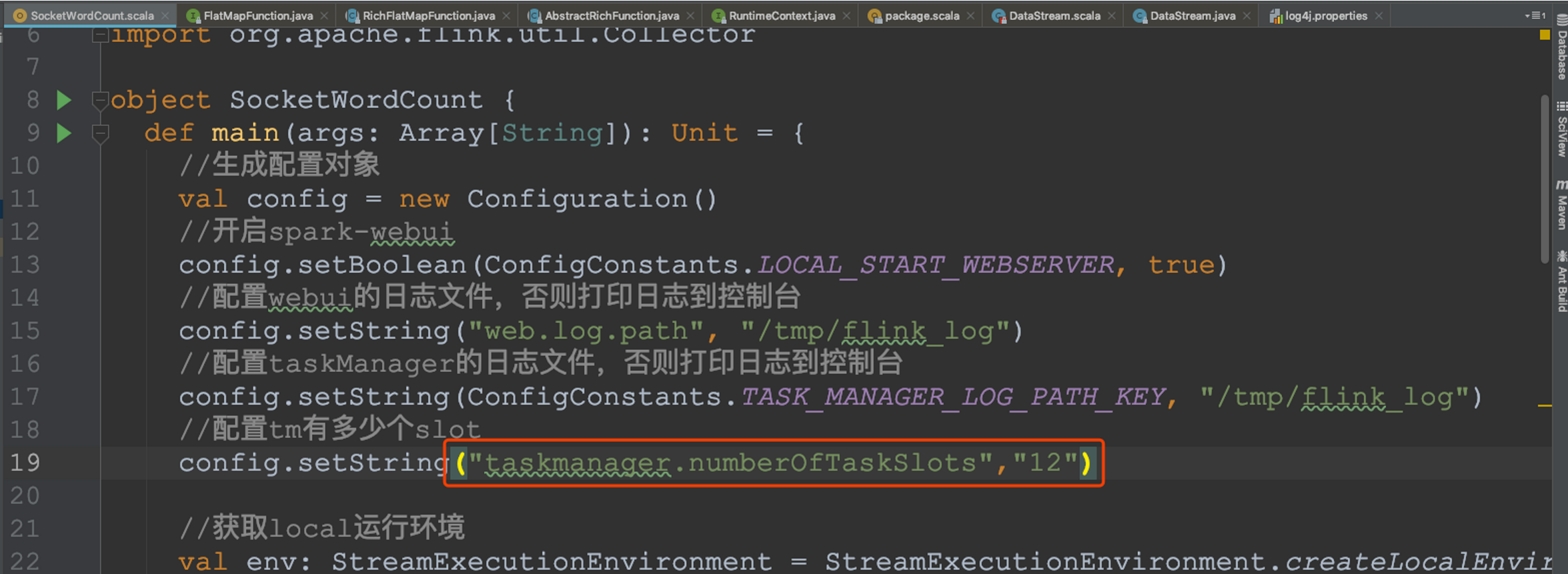
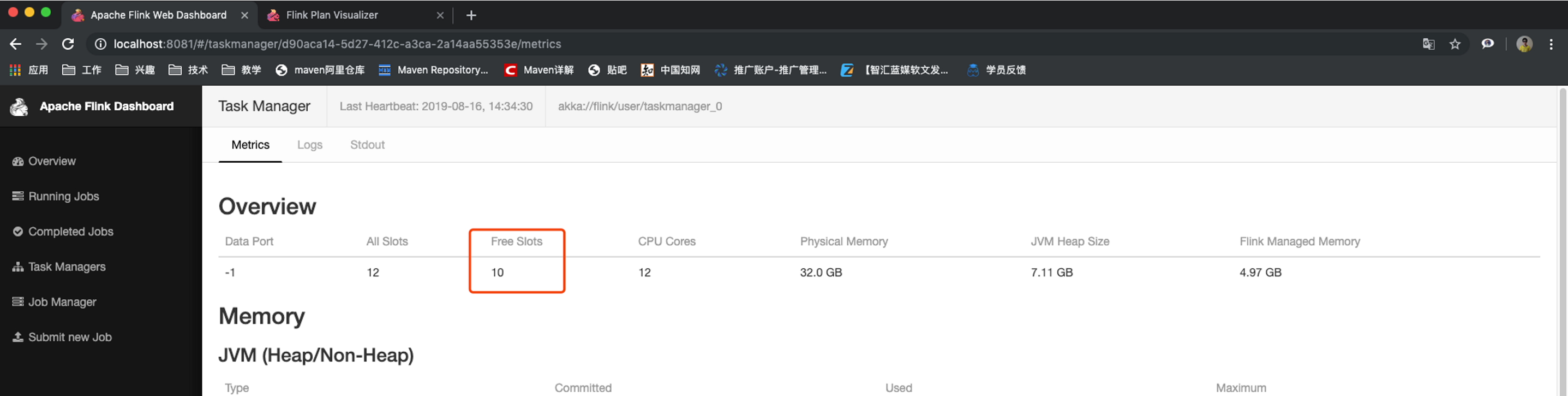
? 設定最后的operator使用新的group
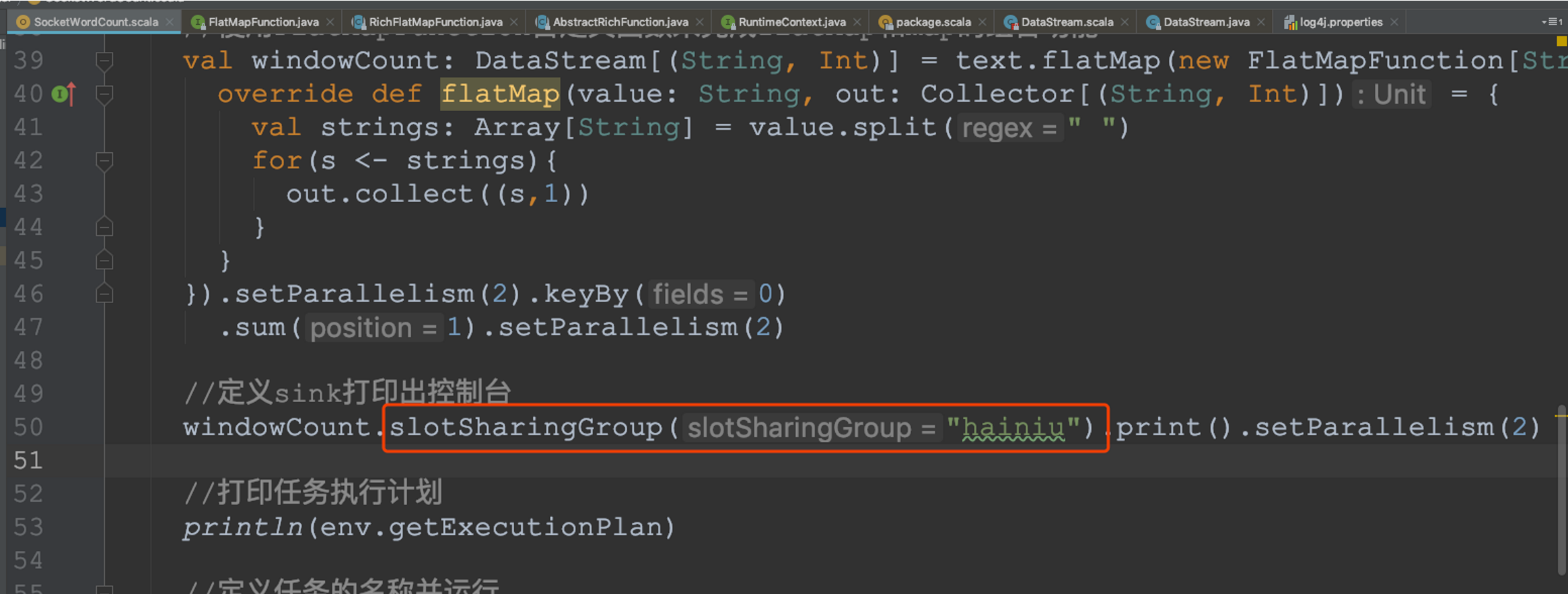
? 由于不和前面的operator在一個group,無法進行slot的共享,所以最后的operator占用了其它slot
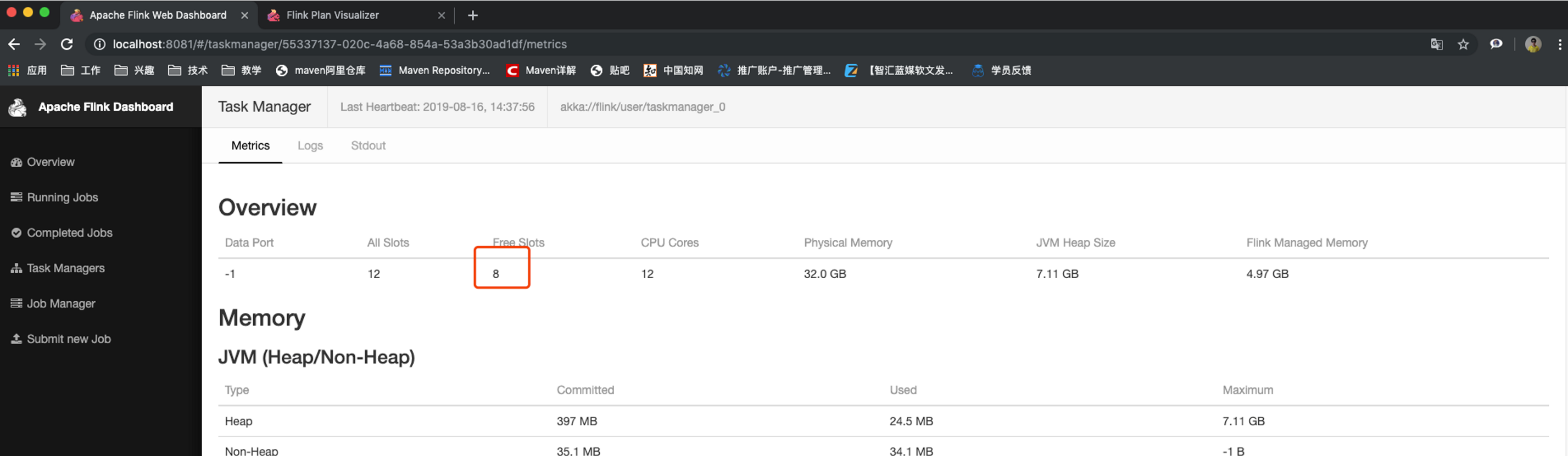
? 為什么占用了兩個呢?
○ 因為不同組,與上面的default不能共享slot,組間互斥
○ 同組中的同一個operator的subtask不能在一個slot中,由于operator的并行度是2,所以占用了兩個槽位,subtask組內互斥
原理與實作
那么多個tasks(或者說operators)是如何共享slot的呢?
關于Flink調度,有兩個非常重要的原則我們必須知道:
1. 同一個operator的各個subtask是不能呆在同一個SharedSlot中的,例如FlatMap[1]和FlatMap[2]是不能在同一個SharedSlot中的,
2. Flink是按照拓撲順序從Source一個個調度到Sink的,例如WordCount(Source并行度為1,其他并行度為2),那么調度的順序依次是:Source -> FlatMap[1] -> FlatMap[2] -> KeyAgg->Sink[1] -> KeyAgg->Sink[2],假設現在有2個TaskManager,每個只有1個slot(為簡化問題),那么分配slot的程序如圖所示:
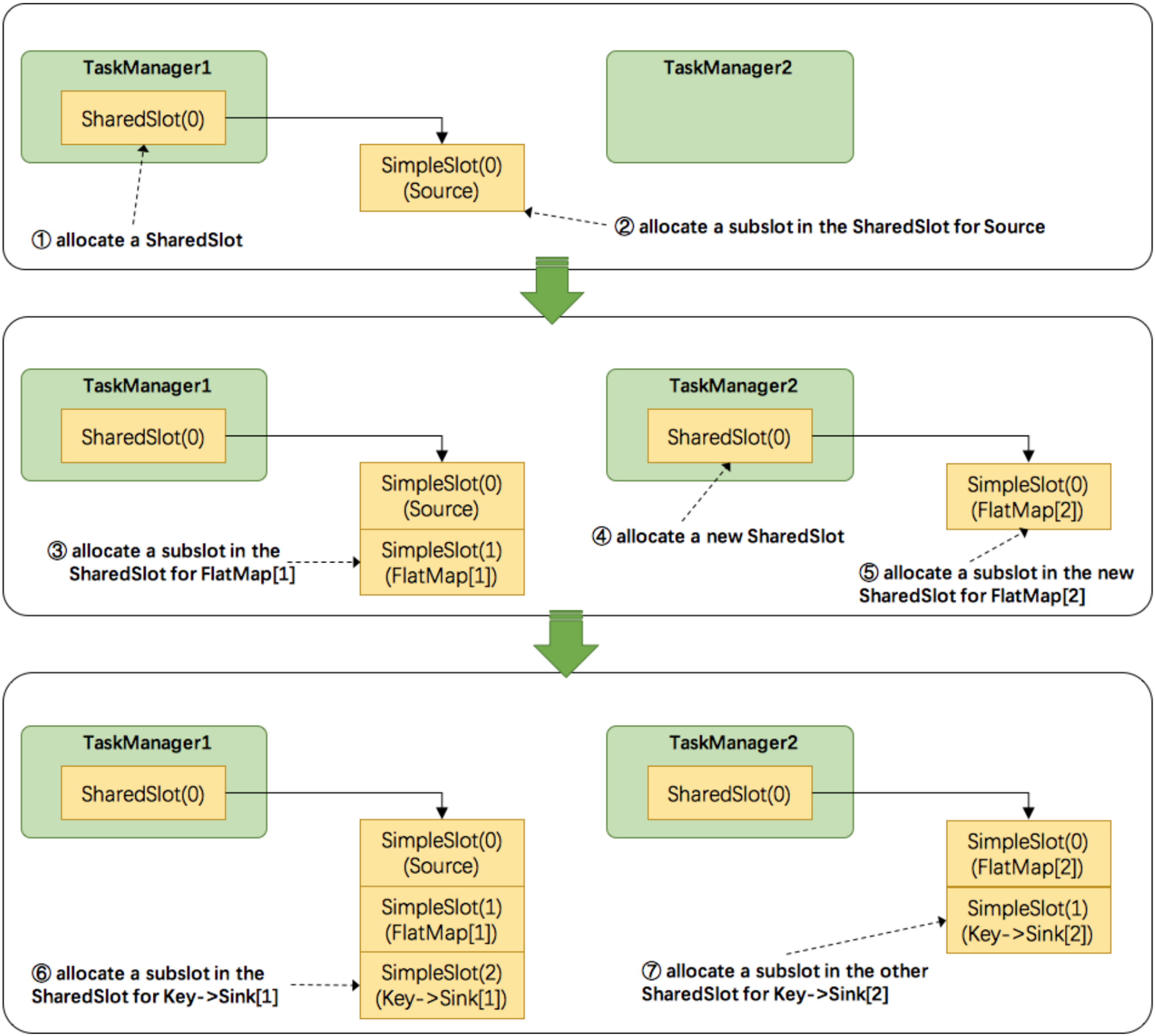
注:圖中 SharedSlot 與 SimpleSlot 后帶的括號中的數字代表槽位號(slotNumber)
1. 為Source分配slot,首先,我們從TaskManager1中分配出一個SharedSlot,并從SharedSlot中為Source分配出一個SimpleSlot,如上圖中的①和②,
2. 為FlatMap[1]分配slot,目前已經有一個SharedSlot,則從該SharedSlot中分配出一個SimpleSlot用來部署FlatMap[1],如上圖中的③,
3. 為FlatMap[2]分配slot,由于TaskManager1的SharedSlot中已經有同operator的FlatMap[1]了,我們只能分配到其他SharedSlot中去,從TaskManager2中分配出一個SharedSlot,并從該SharedSlot中為FlatMap[2]分配出一個SimpleSlot,如上圖的④和⑤,
4. 為Key->Sink[1]分配slot,目前兩個SharedSlot都符合條件,從TaskManager1的SharedSlot中分配出一個SimpleSlot用來部署Key->Sink[1],如上圖中的⑥,
5. 為Key->Sink[2]分配slot,TaskManager1的SharedSlot中已經有同operator的Key->Sink[1]了,則只能選擇另一個SharedSlot中分配出一個SimpleSlot用來部署Key->Sink[2],如上圖中的⑦,
最后Source、FlatMap[1]、Key->Sink[1]這些subtask都會部署到TaskManager1的唯一一個slot中,并啟動對應的執行緒,FlatMap[2]、Key->Sink[2]這些subtask都會被部署到TaskManager2的唯一一個slot中,并啟動對應的執行緒,從而實作了slot共享,
Flink中計算資源的相關概念以及原理實作,最核心的是 Task Slot,每個slot能運行一個或多個task,為了拓撲更高效地運行,Flink提出了Chaining,盡可能地將operators chain在一起作為一個task來處理,為了資源更充分的利用,Flink又提出了SlotSharingGroup,盡可能地讓多個task共享一個slot,
如何計算一個應用需要多少slot
? 不設定SlotSharingGroup,就是不設定新的組大家都為default組,(應用的最大并行度)
? 設定SlotSharingGroup ,就是設定了新的組,比如下圖有兩個組default和test組(所有SlotSharingGroup中的最大并行度之和)
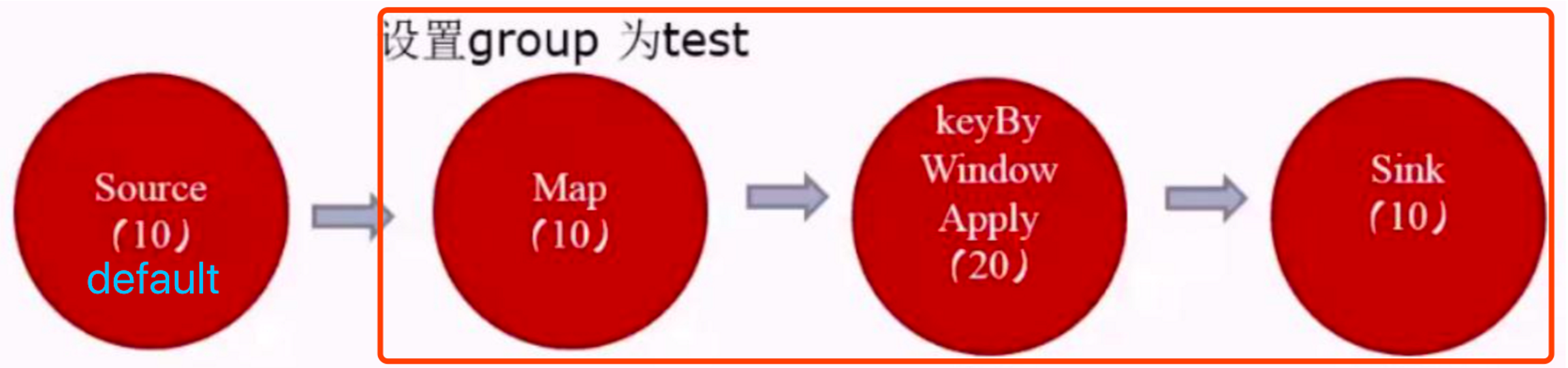
由于source和map之后的operator不屬于同一個group,所以source和它們不能在一個solt中運行,而這里的source的default組的并行度是10,test組的并行度是20,所以所需槽位一共是30
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/538258.html
標籤:大數據
上一篇:一文詳解GaussDB(DWS) 的并發管控和記憶體管控
下一篇:MySQL常見面試題