作者:京東保險 張江濤
1、為什么要有分布式鎖?
JUC提供的鎖機制,可以保證在同一個JVM行程中同一時刻只有一個執行緒執行操作邏輯;
多服務多節點的情況下,就意味著有多個JVM行程,要做到這樣,就需要有一個中間人;
分布式鎖就是用來保證在同一時刻,僅有一個JVM行程中的一個執行緒在執行操作邏輯;
換句話說,JUC的鎖和分布式鎖都是一種保護系統資源的措施,盡可能將并發帶來的不確定性轉換為同步的確定性;
2、分布式鎖特性(五大特性 非常重要)
特性1:互斥性,在任意時刻,只有一個客戶端能持有鎖,
特性2: 不會發生死鎖,即使有一個客戶端在持有鎖的期間崩潰而沒有主動解鎖,也能保證后續其他客戶端能加鎖,
特性3: 解鈴還須系鈴人,加鎖和解鎖必須是同一個客戶端(執行緒),客戶端自己不能把別人加的鎖給解了,
特性4:可重入性,同一個現執行緒已經獲取到鎖,可再次獲取到鎖,
特性5: 具有容錯性,只要大部分的分布式鎖節點正常運行,客戶端就可以加鎖和解鎖,
2-1 常見分布式鎖的三種實作方式
1. 資料庫鎖;2. 基于ZooKeeper的分布式鎖;3. 基于Redis的分布式鎖,
2-2 本文我們主要聊 redis實作分布式鎖:
一個 setnx 就行了?value沒意義?還有人認為 incr 也可以?再加個超時時間就行了?
3、分布式鎖特性2之不會發生死鎖
很多執行緒去上鎖,誰鎖成功誰就有權利執行操作邏輯,其他執行緒要么直接走搶鎖失敗的邏輯,要么自旋嘗試搶鎖;
? 比方說 A執行緒競爭到了鎖,開始執行操作邏輯(代碼邏輯演示中,使用 Jedis客戶端為例);
public static void doSomething() {
// RedisLock是封裝好的一個類
RedisLock redisLock = new RedisLock(jedis); // 創建jedis實體的代碼省略,不是重點
try {
redisLock.lock(); // 上鎖
// 處理業務
System.out.println(Thread.currentThread().getName() + " 執行緒處理業務邏輯中...");
Thread.sleep(2000);
System.out.println(Thread.currentThread().getName() + " 執行緒處理業務邏輯完畢");
redisLock.unlock(); // 釋放鎖
} catch (Exception e) {
e.printStackTrace();
}
}
? 正常情況下,A 執行緒執行完操作邏輯后,應該將鎖釋放,如果說執行程序中拋出例外,程式不再繼續走正常的釋放鎖流程,沒有釋放鎖怎么辦?所以我們想到:
? 釋放鎖的流程一定要在 finally{} 塊中執行,當然,上鎖的流程一定要在 finally{} 對應的 try{} 塊中,否則 finally{} 就沒用了,如下:
public static void doSomething() {
RedisLock redisLock = new RedisLock(jedis); // 創建jedis實體的代碼省略,不是重點
try {
redisLock.lock(); // 上鎖,必須在 try{}中
// 處理業務
System.out.println(Thread.currentThread().getName() + " 執行緒處理業務邏輯中...");
Thread.sleep(2000);
System.out.println(Thread.currentThread().getName() + " 執行緒處理業務邏輯完畢");
} catch (Exception e) {
e.printStackTrace();
} finally {
redisLock.unlock(); // 在finally{} 中釋放鎖
}
}
寫法注意: redisLock.lock(); 上分布式鎖,必須在 try{}中,
在JAVA多執行緒中 lock.lock(); 單機多執行緒加鎖操作需要在try{}之前,
3-1 redisLock.unlock() 放在 finally{} 塊中就行了嗎?還需要設定超時時間
如果在執行 try{} 中邏輯的時候,程式出現了 System.exit(0); 或者 finally{} 中執行例外,比方說連接不上 redis-server了;或者還未執行到 finally{}的時候,JVM行程掛掉了,服務宕機;這些情況都會導致沒有成功釋放鎖,別的執行緒一直拿不到鎖,怎么辦?如果我的系統因為一個節點影響,別的節點也都無法正常提供服務了,那我的系統也太弱了,所以我們想到必須要將風險降低,可以給鎖設定一個超時時間,比方說 1秒,即便發生了上邊的情況,那我的鎖也會在 1秒之后自動釋放,其他執行緒就可以獲取到鎖,接班干活了;
public static final String lock_key = "zjt-lock";
public void lock() {
while (!tryLock()) {
try {
Thread.sleep(50); // 在while中自旋,如果說讀者想設定一些自旋次數,等待最大時長等自己去擴展,不是此處的重點
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("執行緒:" + threadName + ",占鎖成功!★★★");
}
private boolean tryLock() {
SetParams setParams = new SetParams();
setParams.ex(1); // 超時時間1s
setParams.nx(); // nx
String response = jedis.set(lock_key, "", setParams); // 轉換為redis命令就是:set zjt-key "" ex 1 nx
return "OK".equals(response);
}
注意,上鎖的時候,設定key和設定超時時間這兩個操作要是原子性的,要么都執行,要么都不執行,
Redis原生支持:
// http://redis.io/commands/set.html
SET key value [EX seconds] [PX milliseconds] [NX|XX]
不要在代碼里邊分兩次呼叫:
set k v
exipre k time
3-2 鎖的超時時間該怎么計算?
剛才假設的超時時間 1s是怎么計算的?這個時間該設多少合適呢?
鎖中的業務邏輯的執行時間,一般是我們在測驗環境進行多次測驗,然后在壓測環境多輪壓測之后,比方說計算出平均的執行時間是 200ms,鎖的超時時間放大3-5倍,比如這里我們設定為 1s,為啥要放大,因為如果鎖的操作邏輯中有網路 IO操作,線上的網路不會總一帆風順,我們要給網路抖動留有緩沖時間,另外,如果你設定 10s,果真發生了宕機,那意味著這 10s中間,你的這個分布式鎖的服務全部節點都是不可用的,這個和你的業務以及系統的可用性有掛鉤,要衡量,要慎重(后邊3-13會再詳細聊),那如果一個節點宕機之后可以通知 redis-server釋放鎖嗎?注意,我是宕機,不可控力,斷電了兄弟,通知不了的,
回頭一想,如果我是優雅停機呢,我不是 kill -9,也不是斷電,這樣似乎可以去做一些編碼去釋放鎖,你可以參考下 JVM的鉤子、Dubbo的優雅停機、或者 linux行程級通信技術來做這件事情,當然也可以手動停服務后,手動洗掉掉 redis中的鎖,
4、分布式鎖特性3:解鈴還須系鈴人
如果說 A執行緒在執行操作邏輯的程序中,別的執行緒直接進行了釋放鎖的操作,是不是就出問題了?
什么?別的執行緒沒有獲得鎖卻直接執行了釋放鎖??現在是 A執行緒上的鎖,那肯定只能 A執行緒釋放鎖呀!別的執行緒釋放鎖算怎么回事?聯想 ReentrantLock中的 isHeldByCurrentThread()方法,所以我們想到,必須在鎖上加個標記,只有上鎖的執行緒 A執行緒知道,相當于是一個密語,也就是說釋放鎖的時候,首先先把密語和鎖上的標記進行匹配,如果匹配不上,就沒有權利釋放鎖;
private boolean tryLock() {
SetParams setParams = new SetParams();
setParams.ex(1); // 超時時間1s
setParams.nx(); // nx
String response = jedis.set(lock_key, "", setParams); // 轉換為redis命令就是:set zjt_key "" ex 1 nx
return "OK".equals(response);
}
// 別的執行緒直接呼叫釋放鎖操作,分布式鎖崩潰!
public void unlock() {
jedis.del(encode(lock_key));
System.out.println("執行緒:" + threadName + " 釋放鎖成功!☆☆☆");
}
private byte[] encode(String param) {
return param.getBytes();
}
4-1 這個密語value(約定)設定成什么呢?
很多同學說設定成一個 UUID就行了,上鎖之前,在該執行緒代碼中生成一個 UUID,將這個作為秘鑰,存在鎖鍵的 value中,釋放鎖的時候,用這個進行校驗,因為只有上鎖的執行緒知道這個秘鑰,別的執行緒是不知道的,這個可行嗎,當然可行,
String releaseLock_lua = "if redis.call(\"get\",KEYS[1]) == ARGV[1] \n" +
"then\n" +
" return redis.call(\"del\", KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
private boolean tryLock(String uuid) {
SetParams setParams = new SetParams();
setParams.ex(1); // 超時時間1s
setParams.nx(); // nx
String response = jedis.set(lock_key, uuid, setParams); // 轉換為redis命令就是:set zjt-key "" ex 1 nx
return "OK".equals(response);
}
public void unlock(String uuid) {
List<byte[]> keys = Arrays.asList(encode(lock_key));
List<byte[]> args = Arrays.asList(encode(uuid));
// 使用lua腳本,保證原子性
long eval = (Long) jedis.eval(encode(releaseLock_lua), keys, args);
if (eval == 1) {
System.out.println("執行緒:" + threadName + " 釋放鎖成功!☆☆☆");
} else {
System.out.println("執行緒:" + threadName + " 釋放鎖失敗!該執行緒未持有鎖!!!");
}
}
private byte[] encode(String param) {
return param.getBytes();
}
為什么使用 lua腳本?因為保證原子性
因為是兩個操作,如果分兩步那就是:
get k // 進行秘鑰 value的比對
del k // 比對成功后,洗掉k
如果第一步比對成功后,第二步還沒來得及執行的時候,鎖到期,然后緊接著別的執行緒獲取到鎖,里邊的 uuid已經變了,也就是說持有鎖的執行緒已經不是該執行緒了,此時再執行第二步的洗掉鎖操作,肯定是錯誤的了,
5.分布式鎖特性4之可重入性
作為一把鎖,我們在使用 synchronized、ReentrantLock的時候是不是有可重入性?
那咱們這把分布式鎖該如何實作可重入呢?如果 A執行緒的鎖方法邏輯中呼叫了 x()方法,x()方法中也需要獲取這把鎖,按照這個邏輯,x()方法中的鎖應該重入進去即可,那是不是需要將剛才生成的這個 UUID秘鑰傳遞給 x()方法?怎么傳遞?用引數傳遞就會侵入業務代碼
5-1 不侵入業務代碼實作可重入:Thread-Id
我們主要是想給上鎖的 A執行緒設定一個只有它自己知道的秘鑰,把思路時鐘往回撥,想想:
執行緒本身的 id(Thread.currentThread().getId())是不是就是一個唯一標識呢?我們把秘鑰 value設定為執行緒的 id不就行了,
String releaseLock_lua = "if redis.call(\"get\",KEYS[1]) == ARGV[1] \n" +
"then\n" +
" return redis.call(\"del\", KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
String addLockLife_lua = "if redis.call(\"exists\", KEYS[1]) == 1\n" +
"then\n" +
" return redis.call(\"expire\", KEYS[1], ARGV[1])\n" +
"else\n" +
" return 0\n" +
"end";
public void lock() {
// 判斷是否可重入
if (isHeldByCurrentThread()) {
return;
}
while (!tryLock()) {
try {
Thread.sleep(50); // 自旋
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("執行緒:" + threadName + ",占鎖成功!★★★");
}
// 是否是當前執行緒占有鎖,同時將超時時間重新設定,這個很重要,同樣也是原子操作
private boolean isHeldByCurrentThread() {
List<byte[]> keys = Arrays.asList(encode(lock_key));
List<byte[]> args = Arrays.asList(encode(String.valueOf(threadId)), encode(String.valueOf(1)));
long eval = (Long) jedis.eval(encode(addLockLife_lua), keys, args);
return eval == 1;
}
private boolean tryLock(String uuid) {
SetParams setParams = new SetParams();
setParams.ex(1); // 超時時間1s
setParams.nx(); // nx
String response = jedis.set(lock_key, String.valueOf(threadId), setParams); // 轉換為redis命令就是:set zjt-key xxx ex 1 nx
return "OK".equals(response);
}
public void unlock(String uuid) {
List<byte[]> keys = Arrays.asList(encode(lock_key));
List<byte[]> args = Arrays.asList(encode(String.valueOf(threadId)));
// 使用lua腳本,保證原子性
long eval = (Long) jedis.eval(encode(releaseLock_lua), keys, args);
if (eval == 1) {
System.out.println("執行緒:" + threadName + " 釋放鎖成功!☆☆☆");
} else {
System.out.println("執行緒:" + threadName + " 釋放鎖失敗!該執行緒未持有鎖!!!");
}
}
private byte[] encode(String param) {
return param.getBytes();
}
5-2 Thread-Id 真能行嗎?不行,
想想,我們說一個 Thread的id是唯一的,是在同一個 JVM行程中,是在一個作業系統中,也就是在一個機器中,而現實是,我們的部署是集群部署,多個實體節點,那意味著會存在這樣一種情況,S1機器上的執行緒上鎖成功,此時鎖中秘鑰 value是執行緒id=1,如果說同一時間 S2機器中,正好執行緒id=1的執行緒嘗試獲得這把鎖,比對秘鑰發現成功,結果也重入了這把鎖,也開始執行邏輯,此時,我們的分布式鎖崩潰!怎么解決?我們只需要在每個節點中維護不同的標識即可,怎么維護呢?應用啟動的時候,使用 UUID生成一個唯一標識 APP_ID,放在記憶體中(或者使用zookeeper去分配機器id等等),此時,我們的秘鑰 value這樣存即可:APP_ID+ThreadId
// static變數,final修飾,加載在記憶體中,JVM行程生命周期中不變
private static final String APP_ID = UUID.randomUUID().toString();
String releaseLock_lua = "if redis.call(\"get\",KEYS[1]) == ARGV[1] \n" +
"then\n" +
" return redis.call(\"del\", KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
String addLockLife_lua = "if redis.call(\"exists\", KEYS[1]) == 1\n" +
"then\n" +
" return redis.call(\"expire\", KEYS[1], ARGV[1])\n" +
"else\n" +
" return 0\n" +
"end";
public void lock() {
// 判斷是否可重入
if (isHeldByCurrentThread()) {
return;
}
while (!tryLock()) {
try {
Thread.sleep(50); // 自旋
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("執行緒:" + threadName + ",占鎖成功!★★★");
}
// 是否是當前執行緒占有鎖,同時將超時時間重新設定,這個很重要,同樣也是原子操作
private boolean isHeldByCurrentThread() {
List<byte[]> keys = Arrays.asList(encode(lock_key));
List<byte[]> args = Arrays.asList(encode(APP_ID + String.valueOf(threadId)), encode(String.valueOf(1)));
long eval = (Long) jedis.eval(encode(addLockLife_lua), keys, args);
return eval == 1;
}
private boolean tryLock(String uuid) {
SetParams setParams = new SetParams();
setParams.ex(1); // 超時時間1s
setParams.nx(); // nx
String response = jedis.set(lock_key, APP_ID + String.valueOf(threadId), setParams); // 轉換為redis命令就是:set zjt-key xxx ex 1 nx
return "OK".equals(response);
}
public void unlock(String uuid) {
List<byte[]> keys = Arrays.asList(encode(lock_key));
List<byte[]> args = Arrays.asList(encode(APP_ID + String.valueOf(threadId)));
// 使用lua腳本,保證原子性
long eval = (Long) jedis.eval(encode(releaseLock_lua), keys, args);
if (eval == 1) {
System.out.println("執行緒:" + threadName + " 釋放鎖成功!☆☆☆");
} else {
System.out.println("執行緒:" + threadName + " 釋放鎖失敗!該執行緒未持有鎖!!!");
}
}
private byte[] encode(String param) {
return param.getBytes();
}
5-3 APP_ID(實體唯一標識) + ThreadId 還是 UUID 好呢?
繼續聽我說,如果 A執行緒執行邏輯中間開啟了一個子執行緒執行任務,這個子執行緒任務中也需要重入這把鎖,因為子執行緒獲取到的執行緒 id不一樣,導致重入失敗,那意味著需要將這個秘鑰繼續傳遞給子執行緒,JUC中 InheritableThreadLocal 派上用場,但是感覺怪怪的,因為執行緒間傳遞的是父執行緒的 id,
微服務中多服務間呼叫的話可以借用系統自身有的 traceId作為秘鑰即可,比如sgm中的traceId 或者 利用RPC框架的隱式傳參
「至于選擇哪種 value的方式,根據實際的系統設計 + 業務場景,選擇最合適的即可,沒有最好,只有最合適,」
5-4、鎖重入的超時時間怎么設定?
注意,我們上邊的主要注意力在怎么重入進去,而我們這是分布式鎖,要考慮的事情還有很多,重入進去后,超時時間隨便設嗎?
比方說 A執行緒在鎖方法中呼叫了 x()方法,而 x()方法中也有獲取鎖的邏輯,如果 A執行緒獲取鎖后,執行程序中,到 x()方法時,這把鎖是要重入進去的,但是請注意,這把鎖的超時時間如果小于第一次上鎖的時間,比方說 A執行緒設定的超時時間是 1s,在 100ms的時候執行到 x()方法中,而 x()方法中設定的超時時間是 100ms,那么意味著 100ms之后鎖就釋放了,而這個時候我的 A執行緒的主方法還沒有執行完呢!卻被重入鎖設定的時間搞壞了!這個怎么搞?
如果說我在記憶體中設定一個這把鎖設定過的最大的超時時間,重入的時候判斷下傳進來的時間,我重入時 expire的時候始終設定成最大的時間,而不是由重入鎖隨意降低鎖時間導致上一步的主鎖出現問題
放在記憶體中行嗎?我們上邊舉例中,呼叫的 x()方法是在一個 JVM中,如果是呼叫遠程的一個 RPC服務呢(像這種呼叫的話就需要將秘鑰value通過 RpcContext傳遞過去了)到另一個節點的服務中進行鎖重入,這個時間依然是要用當前設定過鎖的最大時間的,所以這個最大的時間要存在 redis中而非 JVM記憶體中
經過這一步的分析,我們的重入 lua腳本就修改為這樣了:
ADD_LOCK_LIFE("if redis.call(\"get\", KEYS[1]) == ARGV[1]\n" + // 判斷是否是鎖持有者
"then\n" +
" local thisLockMaxTimeKeepKey=KEYS[1] .. \":maxTime\"\n" + // 記錄鎖最大時間的key是:鎖名字:maxTime
" local nowTime=tonumber(ARGV[2])\n" + // 當前傳參進來的time
" local maxTime=redis.call(\"incr\", thisLockMaxTimeKeepKey)\n" + // 取出當前鎖設定的最大的超時時間,如果這個保持時間的key不存在回傳的是字串nil,這里為了lua腳本的易讀性,用incr操作,這樣讀出來的都是number型別的操作
" local bigerTime=maxTime\n" + // 臨時變數bigerTime=maxTime
" if nowTime>maxTime-1\n" + // 如果傳參進來的時間>記錄的最大時間
" then\n" +
" bigerTime=nowTime\n" + // 則更新bigerTime
" redis.call(\"set\", thisLockMaxTimeKeepKey, tostring(bigerTime))\n" + // 設定超時時間為最大的time,是最安全的
" else \n" +
" redis.call(\"decr\", thisLockMaxTimeKeepKey)\n" + // 當前傳參time<maxTime,將剛才那次incr級訓來
" end\n" +
" return redis.call(\"expire\", KEYS[1], tostring(bigerTime))\n" + // 重新設定超時時間為當前鎖過的最大的time
"else\n" +
" return 0\n" +
"end"),
其實,還有另外一種方案比較簡單,就是鎖的超時時間=第一次上鎖的時間+后面所有重入鎖的時間,也就是(expire = 主ttl + 重入exipre),這種方案是放大的思想,一放大就又有上邊提到過的一個問題:expire太大怎么辦,參考上邊,
5-5、重入鎖的方法中直接執行 unlock?考慮重入次數
A執行緒執行一共需要500ms,執行中需要呼叫 x()方法,x()方法中有一個重入鎖,執行用了 50ms,然后執行完后,x()方法的 finally{} 塊中將鎖進行釋放,
為啥能釋放掉?因為秘鑰我有,匹配成功了我就直接釋放了,
這當然是有問題的,所以我們要通過鎖重入次數來進行釋放鎖時候的判斷,也就是說上鎖的時候需要多維護一個 key來保存當前鎖的重入次數,如果執行釋放鎖時,先進行重入次數 -1,-1后如果是0,可以直接 del,如果>0,說明還有重入的鎖在,不能直接 del,
5-6 考慮如何存盤鎖的屬性(鎖的key 重入次數key 最大超時時間key)?
目前為止,算上上一步中設定最大超時時間的key,加上這一步重入次數的key,加上鎖本身的key,已經有3個key,需要注意的事情是,這三個key的超時時間是都要設定的!為什么?假如說重入次數的 key沒有設定超時時間,服務A節點中在一個JVM中重入了5次后,呼叫一次 RPC服務,RPC服務中同樣重入鎖,此時,鎖重入次數是 6,這個時候A服務宕機,就意味著無論怎樣,這把鎖不可能釋放了,這個分布式鎖提供的完整能力,全線不可用了!
所以,這幾個 key是要設定超時時間的!怎么設定?我上一個鎖要維護這么多 key的超時時間?太復雜了吧,多則亂,則容易出問題,怎么辦?我們想一下,是不是最大超時時間的 key和重入次數的 key,都附屬于鎖,它們都是鎖的屬性,如果鎖不在了,談它們就毫無意義,這個時候用什么存盤呢?redis的 hash資料結構,就可以做,key是鎖,里邊的 hashKey分別是鎖的屬性, hashValue是屬性值,超時時間只設定鎖本身 key就可以了,這個時候,我們的鎖的資料結構就要改變一下了,
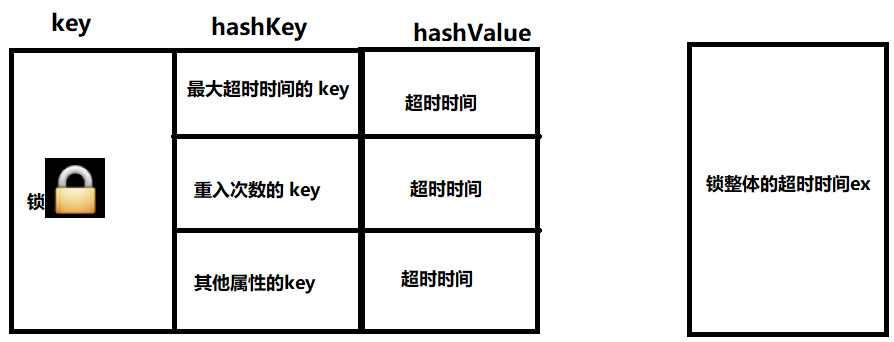
6、如何解決過期時間確定和業務執行時長不確定性的問題:看門狗機制
3-2中設定超時時間那里,我們預估鎖方法執行時間是 200ms,我們放大 5倍后,設定超時時間是 1s(過期時間確定),假想一下,如果生產環境中,鎖方法中的 IO操作,極端情況下超時嚴重,比方說 IO就消耗了 2s(業務執行時長不確定),那就意味著,在這次 IO還沒有結束的時候,我這把鎖已經到期釋放掉了,就意味著別的執行緒趁虛而入,分布式鎖崩潰!
我們要做的是一把分布式鎖,想要的目的是同一時刻只有一個執行緒持有鎖,作為服務而言,這個鎖現在不管是被哪個執行緒上鎖成功了,我服務應該保證這個執行緒執行的安全性,怎么辦?鎖續命(看門狗機制),什么意思,一旦這把鎖出現了上鎖操作,就意味著這把鎖開始投入使用,這時我的服務中需要有一個 daemon執行緒定時去守護我的鎖的安全性,怎么守護?比如說鎖超時時間設定的是 1s,那么我這個定時任務是每隔 300ms去 redis服務端做一次檢查,如果我還持有,你就給我續命,就像 session會話的活躍機制一樣,看個例子,我上鎖時候超時時間設定的是 1s,實際方法執行時間是 3s,這中間我的定時執行緒每隔 300ms就會去把這把鎖的超時時間重新設定為 1s,每隔 300ms一次,成功將鎖續命成功,
public class RedisLockIdleThreadPool {
private String threadAddLife_lua = "if redis.call(\"exists\", KEYS[1]) == 1\n" +
"then\n" +
" return redis.call(\"expire\", KEYS[1], ARGV[1])\n" +
"else\n" +
" return 0\n" +
"end";
private volatile ScheduledExecutorService scheduledThreadPool;
public RedisLockIdleThreadPool() {
if (scheduledThreadPool == null) {
synchronized (this) {
if (scheduledThreadPool == null) {
scheduledThreadPool = Executors.newSingleThreadScheduledExecutor(); // 我這樣創建執行緒池是為了代碼的易讀性,大家務必使用ThreadPoolExecutor去創建
scheduledThreadPool.scheduleAtFixedRate(() -> {
addLife();
}, 0, 300, TimeUnit.MILLISECONDS);
}
}
}
}
private void addLife() {
// ... 省略jedis的初始化程序
List<byte[]> keys = Arrays.asList(RedisLock.lock_key.getBytes());
List<byte[]> args = Arrays.asList(String.valueOf(1).getBytes());
jedis.eval(threadAddLife_lua.getBytes(), keys, args);
}
}
這就行嗎?還不行!
為啥?想一下,如果每個服務中都像這樣去續命鎖,假如說A服務還在執行程序中的時候,還沒有執行完,就是說還沒有手動釋放鎖的時候,宕機,此時 redis中鎖還在有效期,服務B 也一直在續命這把鎖,此時這把鎖一直在續命,但是 B的這個續命一直續的是 A當時設的鎖,這不是扯嗎?我自己在不斷續命,導致我的服務上一直獲取不到鎖,實際上 A已經宕機了呀!該釋放了,不應該去續命了,這不是我服務 B該干的活!
續命的前提是,得判斷是不是當前行程持有的鎖,也就是我們的 APP_ID,如果不是就不進行續命,
續命鎖的 lua腳本發生改變,如下:
THREAD_ADD_LIFE("local v=redis.call(\"get\", KEYS[1]) \n" + // get key
"if v==false \n" + // 如果不存在key,讀出結果v是false
"then \n" + // 不存在不處理
"else \n" +
" local match = string.find(v, ARGV[1]) \n" + // 存在,判斷是否能和APP_ID匹配,匹配不上時match是nil
" if match==\"nil\" \n" +
" then \n" +
" else \n" +
" return redis.call(\"expire\", KEYS[1], ARGV[2]) \n" + // 匹配上了回傳的是索引位置,如果匹配上了意味著就是當前行程占有的鎖,就延長時間
" end \n" +
"end")
6-1 鎖在我手里,我掛了,這... 沒救,只能等待鎖超時釋放
即便設定了一個很合理的 expire,比如 10s,但是線上如果真出現了A節點剛拿到鎖就宕機了,那其他節點也只能干等10s,之后才能拿到鎖,主要還是業務能不能接受,而如果是 To C的業務中,大部分場景無法接受的,因為可能會導致用戶流失,所以我們需要另外一個監控服務,定時去監控 redis中鎖的獲得者的健康狀態,如果獲取者超過n次無法通信,由監控服務負責將鎖摘除掉,讓別的執行緒繼續去獲取到鎖去干活,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/543940.html
標籤:其它
下一篇:sql語氣查詢去重的兩種方法、sql的模糊查詢、sql中的日期函式、mysql字串截取之substring_index、sql中字串的切割、截取、洗掉、替換、計算字串長度函式、回傳某個日期之間的解法