
前言:最近幾年用MYSQL資料庫挺多的,發現了一些非常有用的小玩意,今天拿出來分享到大家,希望對你會有所幫助,1.group_concat
在我們平常的作業中,使用group by進行分組的場景,是非常多的,
比如想統計出用戶表中,名稱不同的用戶的具體名稱有哪些?
具體sql如下:
select name from `user`group by name;
但如果想把name相同的code拼接在一起,放到另外一列中該怎么辦呢?
答:使用group_concat函式,
例如:
select name,group_concat(code) from `user`group by name;
執行結果:
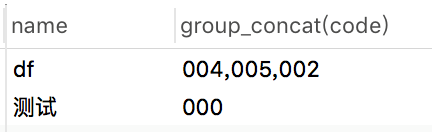
使用group_concat函式,可以輕松的把分組后,name相同的資料拼接到一起,組成一個字串,用逗號分隔,
2.char_length
有時候我們需要獲取字符的長度,然后根據字符的長度進行排序,
MYSQL給我們提供了一些有用的函式,比如:char_length,
通過該函式就能獲取字符長度,
獲取字符長度并且排序的sql如下:
select * from brand where name like '%蘇三%' order by char_length(name) asc limit 5;
執行效果如圖所示:
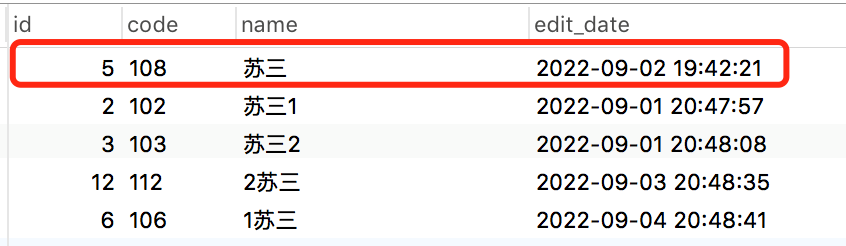
name欄位使用關鍵字模糊查詢之后,再使用char_length函式獲取name欄位的字符長度,然后按長度升序,
3.locate
有時候我們在查找某個關鍵字,比如:蘇三,需要明確知道它在某個字串中的位置時,該怎么辦呢?
答:使用locate函式,
使用locate函式改造之后sql如下:
select * from brand where name like '%蘇三%' order by char_length(name) asc, locate('蘇三',name) asc limit 5,5;
執行結果:
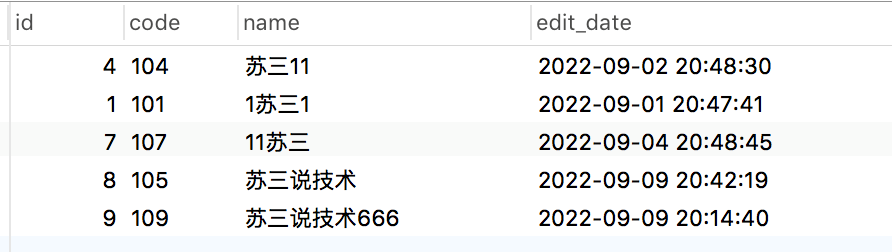
先按長度排序,小的排在前面,如果長度相同,則按關鍵字從左到右進行排序,越靠左的越排在前面,
除此之外,我們還可以使用:instr和position函式,它們的功能跟locate函式類似,在這里我就不一一介紹了,感興趣的小伙伴可以找我私聊,
4.replace
我們經常會有替換字串中部分內容的需求,比如:將字串中的字符A替換成B,
這種情況就能使用replace函式,
例如:
update brand set name=REPLACE(name,'A','B') where id=1;
這樣就能輕松實作字符替換功能,
也能用該函式去掉前后空格:
update brand set name=REPLACE(name,' ','') where name like ' %';update brand set name=REPLACE(name,' ','') where name like '% ';
使用該函式還能替換json格式的資料內容,真的非常有用,
5.now
時間是個好東西,用它可以快速縮小資料范圍,我們經常有獲取當前時間的需求,
在MYSQL中獲取當前時間,可以使用now()函式,例如:
select now() from brand limit 1;
回傳結果為下面這樣的:
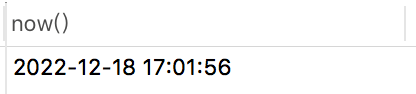
它會包含年月日時分秒,
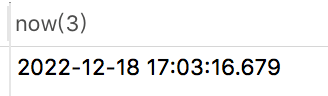
如果你還想回傳毫秒,可以使用now(3),例如:
select now(3) from brand limit 1;
回傳結果為下面這樣的:
使用起來非常方便好記,
6.insert into ... select
在作業中很多時候需要插入資料,
傳統的插入資料的sql是這樣的:
INSERT INTO `brand`(`id`, `code`, `name`, `edit_date`) VALUES (5, '108', '蘇三', '2022-09-02 19:42:21');
它主要是用于插入少量并且已經確定的資料,但如果有大批量的資料需要插入,特別是是需要插入的資料來源于,另外一張表或者多張表的結果集中,
這種情況下,使用傳統的插入資料的方式,就有點束手無策了,
這時候就能使用MYSQL提供的:insert into ... select語法,
例如:
INSERT INTO `brand`(`id`, `code`, `name`, `edit_date`) select null,code,name,now(3) from `order` where code in ('004','005');
這樣就能將order表中的部分資料,非常輕松插入到brand表中,
7.insert into ... ignore
不知道你有沒有遇到過這樣的場景:在插入1000個品牌之前,需要先根據name,判斷一下是否存在,如果存在,則不插入資料,如果不存在,才需要插入資料,
如果直接這樣插入資料:
INSERT INTO `brand`(`id`, `code`, `name`, `edit_date`) VALUES (123, '108', '蘇三', now(3));
肯定不行,因為brand表的name欄位創建了唯一索引,同時該表中已經有一條name等于蘇三的資料了,
執行之后直接報錯了:

這就需要在插入之前加一下判斷,
當然很多人通過在sql陳述句后面拼接not exists陳述句,也能達到防止出現重復資料的目的,比如:
INSERT INTO `brand`(`id`, `code`, `name`, `edit_date`) select null,'108', '蘇三',now(3) from dual where not exists (select * from `brand` where name='蘇三');
這條sql確實能夠滿足要求,但是總覺得有些麻煩,那么,有沒有更簡單的做法呢?
答:可以使用insert into ... ignore語法,
例如:
INSERT ignore INTO `brand`(`id`, `code`, `name`, `edit_date`) VALUES (123, '108', '蘇三', now(3));
這樣改造之后,如果brand表中沒有name為蘇三的資料,則可以直接插入成功,
但如果brand表中已經存在name為蘇三的資料了,則該sql陳述句也能正常執行,并不會報錯,因為它會忽略例外,回傳的執行結果影響行數為0,它不會重復插入資料,
8.select ... for update
MYSQL資料庫自帶了悲觀鎖,它是一種排它鎖,根據鎖的粒度從大到小分為:表鎖、間隙鎖和行鎖,
在我們的實際業務場景中,有些情況并發量不太高,為了保證資料的正確性,使用悲觀鎖也可以,
比如:用戶扣級訓分,用戶的操作并不集中,但也要考慮系統自動贈送積分的并發情況,所以有必要加悲觀鎖限制一下,防止出現積分加錯的情況發生,
這時候就可以使用MYSQL中的select ... for update語法了,
例如:
begin;select * from `user` where id=1 for update;
//業務邏輯處理
update `user` set score=score-1 where id=1;commit;
這樣在一個事務中使用for update鎖住一行記錄,其他事務就不能在該事務提交之前,去更新那一行的資料,
需要注意的是for update前的id條件,必須是表的主鍵或者唯一索引,不然行鎖可能會失效,有可能變成表鎖,
9.on duplicate key update
通常情況下,我們在插入資料之前,一般會先查詢一下,該資料是否存在,如果不存在,則插入資料,如果已存在,則不插入資料,而直接回傳結果,
在沒啥并發量的場景中,這種做法是沒有什么問題的,但如果插入資料的請求,有一定的并發量,這種做法就可能會產生重復的資料,
當然防止重復資料的做法很多,比如:加唯一索引、加分布式鎖等,
但這些方案,都沒法做到讓第二次請求也更新資料,它們一般會判斷已經存在就直接回傳了,
這種情況可以使用on duplicate key update語法,
該語法會在插入資料之前判斷,如果主鍵或唯一索引不存在,則插入資料,如果主鍵或唯一索引存在,則執行更新操作,
具體需要更新的欄位可以指定,例如:
INSERT INTO `brand`(`id`, `code`, `name`, `edit_date`) VALUES (123, '108', '蘇三', now(3))on duplicate key update name='蘇三',edit_date=now(3);
這樣一條陳述句就能輕松搞定需求,既不會產生重復資料,也能更新最新的資料,
但需要注意的是,在高并發的場景下使用on duplicate key update語法,可能會存在死鎖的問題,所以要根據實際情況酌情使用,
10.show create table
有時候,我們想快速查看某張表的欄位情況,通常會使用desc命令,比如:
desc `order`;
結果如圖所示:
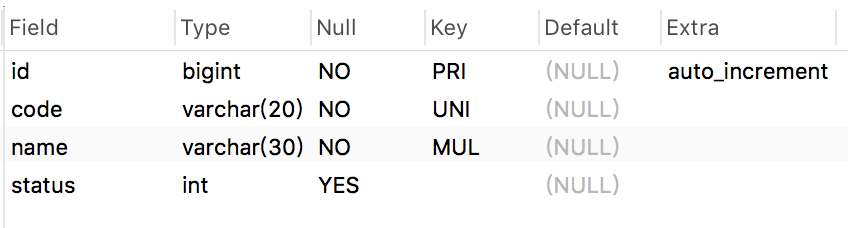
確實能夠看到order表中的欄位名稱、欄位型別、欄位長度、是否允許為空,是否主鍵、默認值等資訊,
但看不到該表的索引資訊,如果想看創建了哪些索引,該怎么辦呢?
答:使用show index命令,
比如:
show index from `order`;
也能查出該表所有的索引:

但查看欄位和索引資料呈現方式,總覺得有點怪怪的,有沒有一種更直觀的方式?
答:這就需要使用show create table命令了,
例如:
show create table `order`;
執行結果如圖所示:

其中Table表示表名,Create Table就是我們需要看的建表資訊,將資料展開:圖片我們能夠看到非常完整的建表陳述句,表名、欄位名、欄位型別、欄位長度、字符集、主鍵、索引、執行引擎等都能看到,
非常直接明了,
11.create table ... select
有時候,我們需要快速備份表,
通常情況下,可以分兩步走:
-
創建一張臨時表
-
將資料插入臨時表
創建臨時表可以使用命令:
create table order_2022121819 like `order`;
創建成功之后,就會生成一張名稱叫:order_2022121819,表結構跟order一模一樣的新表,只是該表的資料為空而已,
接下來使用命令:
insert into order_2022121819 select * from `order`;
執行之后就會將order表的資料插入到order_2022121819表中,也就是實作資料備份的功能,
但有沒有命令,一個命令就能實作上面這兩步的功能呢?
答:用create table ... select命令,
例如:
create table order_2022121820 select * from `order`;
執行完之后,就會將order_2022121820表創建好,并且將order表中的資料自動插入到新創建的order_2022121820中,
一個命令就能輕松搞定表備份,
12.explain
很多時候,我們優化一條sql陳述句的性能,需要查看索引執行情況,
答:可以使用explain命令,查看mysql的執行計劃,它會顯示索引的使用情況,
例如:
explain select * from `order` where code='002';
結果:

通過這幾列可以判斷索引使用情況,執行計劃包含列的含義如下圖所示:
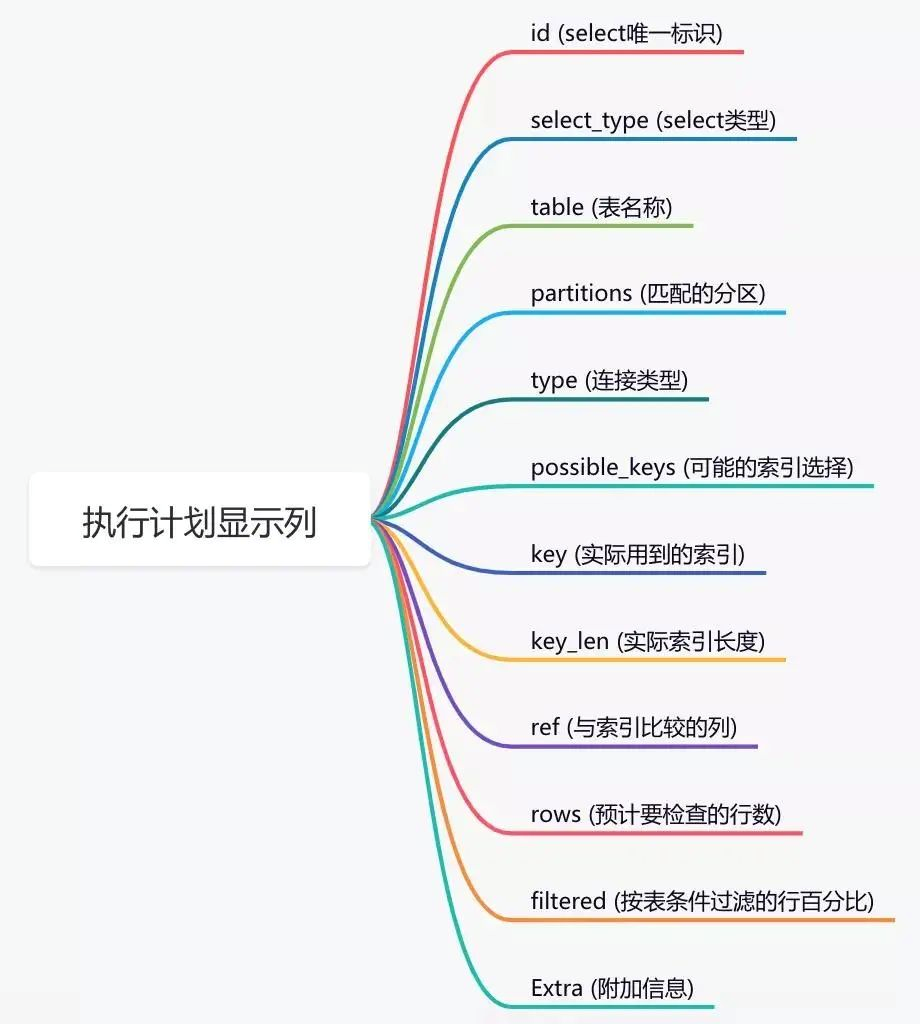
說實話,sql陳述句沒有走索引,排除沒有建索引之外,最大的可能性是索引失效了,
下面說說索引失效的常見原因:
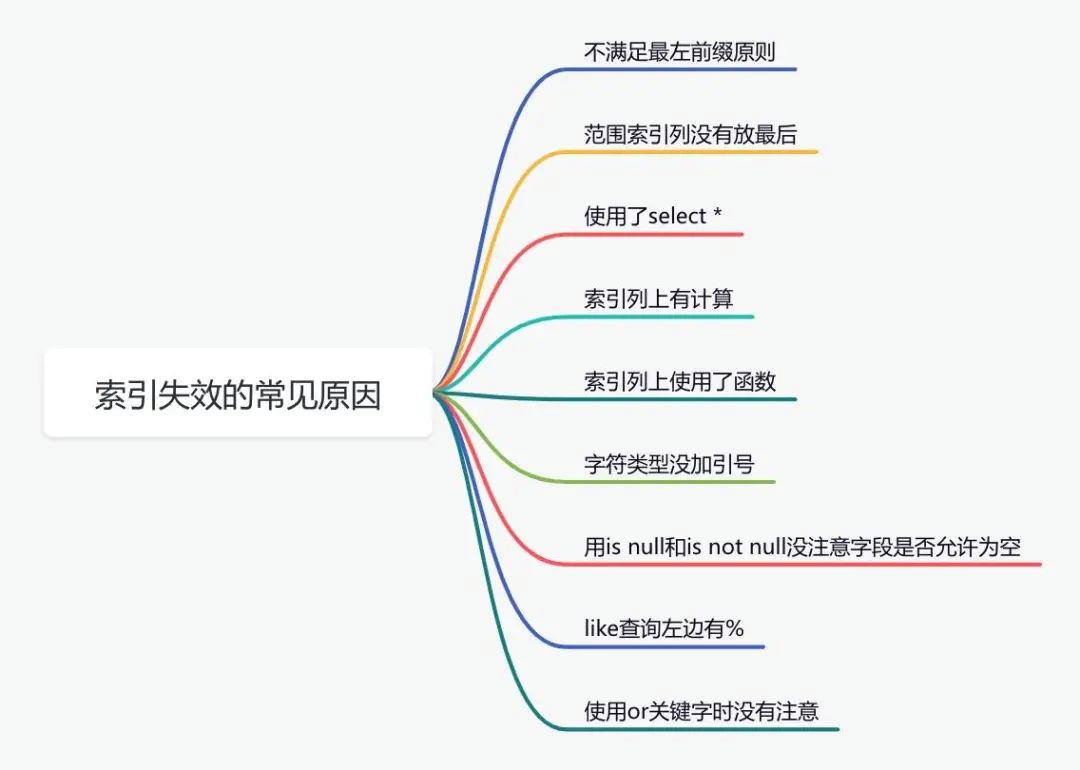
如果不是上面的這些原因,則需要再進一步排查一下其他原因,
13.show processlist
有些時候我們線上sql或者資料庫出現了問題,比如出現了資料庫連接過多問題,或者發現有一條sql陳述句的執行時間特別長,
這時候該怎么辦呢?
答:我們可以使用show processlist命令查看當前執行緒執行情況,
如圖所示:
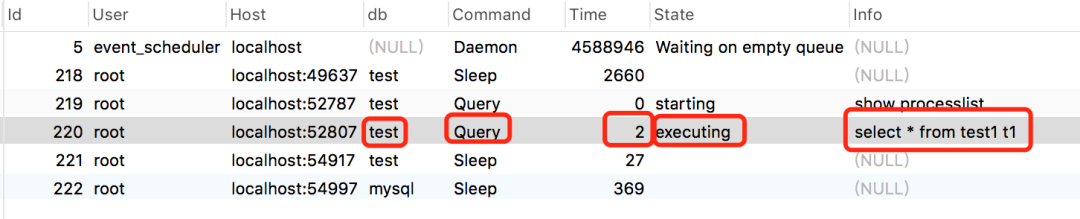
從執行結果中,我們可以查看當前的連接狀態,幫助識別出有問題的查詢陳述句,
-
id 執行緒id
-
User 執行sql的賬號
-
Host 執行sql的資料庫的ip和端號
-
db 資料庫名稱
-
Command 執行命令,包括:Daemon、Query、Sleep等,
-
Time 執行sql所消耗的時間
-
State 執行狀態
-
info 執行資訊,里面可能包含sql資訊,
如果發現了例外的sql陳述句,可以直接kill掉,確保資料庫不會出現嚴重的問題,
14.mysqldump
有時候我們需要匯出MYSQL表中的資料,
這種情況就可以使用mysqldump工具,該工具會將資料查出來,轉換成insert陳述句,寫入到某個檔案中,相當于資料備份,
我們獲取到該檔案,然后執行相應的insert陳述句,就能創建相關的表,并且寫入資料了,這就相當于資料還原,
mysqldump命令的語法為:mysqldump -h主機名 -P埠 -u用戶名 -p密碼 引數1,引數2.... > 檔案名稱.sql
備份遠程資料庫中的資料庫:
mysqldump -h 192.22.25.226 -u root -p123456 dbname > backup.sql
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/14-required-skills-in-MySQL.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/546005.html
標籤:其他
上一篇:認識一下SQL的視窗函式