前言和官方檔案
前言:
MongoDB中涉及到陣列欄位的查詢和更新很常用,抽空把自己開發作業中常遇到的場景拿出來并結合官方檔案小結一下,
有說的不對的地方,歡迎指出交流探討,也希望這篇筆記能夠幫到你,
可以轉載,但請注明出處,
之前自己寫的SpringBoot整合MongoDB的聚合查詢操作,感興趣的可以點擊查閱,
https://www.cnblogs.com/zaoyu/p/springboot-mongodb.html
官方檔案:
$elemMatch: https://www.mongodb.com/docs/manual/reference/operator/query/elemMatch/
$update: https://www.mongodb.com/docs/manual/reference/operator/update/positional/#mongodb-update-up.-
測驗環境: MongoDB 5.0.9
一、Array(陣列)相關的Query(查詢)
官方定義和語法格式
陣列的查詢多數情況結合$elemMatch運算子一起查詢,也可以不使用, 下面分別是兩種情況的演示說明,
1.1 是直接查詢,不使用$elemMatch, 1.2是帶$elemMatch的查詢,
具體語法格式見1.1 和1.2開頭,
1.1 直接查詢 (普通的find)
就是直接 db.collection.find({queryExpression})
以官方提供的Demo來說明
// 1. 插入多條資料 db.inventory.insertMany([ { item: "journal", qty: 25, tags: ["blank", "red"], dim_cm: [ 14, 21 ] }, { item: "notebook", qty: 50, tags: ["red", "blank"], dim_cm: [ 14, 21 ] }, { item: "paper", qty: 100, tags: ["red", "blank", "plain"], dim_cm: [ 14, 21 ] }, { item: "planner", qty: 75, tags: ["blank", "red"], dim_cm: [ 22.85, 30 ] }, { item: "postcard", qty: 45, tags: ["blue"], dim_cm: [ 10, 15.25 ] } ]);
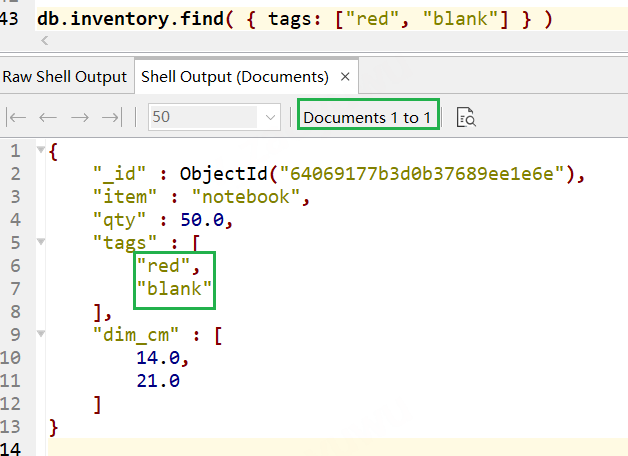
// 2.1 陣列元素完全匹配查詢(值、值的個數、順序,都要完全一致才回傳), // 這個陳述句就是查找tags陣列下只且只有red/blank兩個值的元素,且順序要為red、blank, db.inventory.find( { tags: ["red", "blank"] } ) // 結果可見下圖
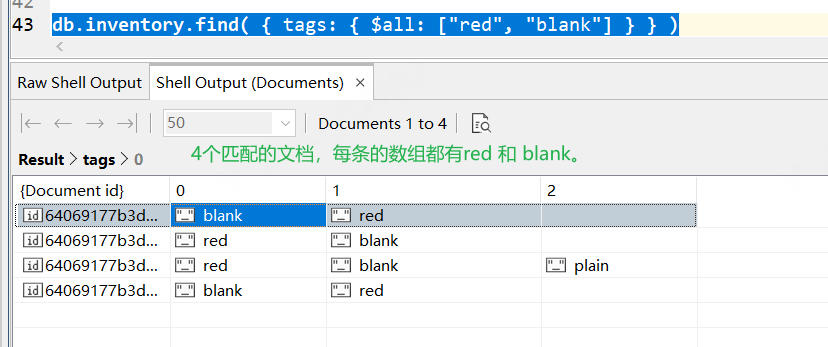
// 2.2 陣列元素部分匹配查詢(只要陣列元素中的值,部分值匹配要查詢的條件,就可以回傳,無關順序), 要使用 $all 運算子 // 這個陳述句意思是說,查找tags陣列中,只要元素值里面有red和blank(注意,是多個條件同時存在),就回傳,無關順序, db.inventory.find( { tags: { $all: ["red", "blank"] } } ) // 結果可見下圖
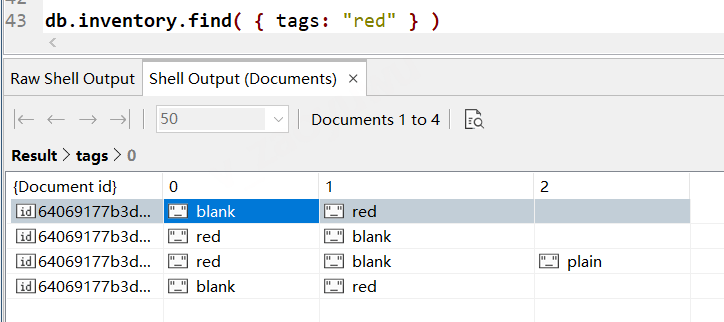
// 2.3 陣列元素單個值匹配和范圍查找 // 比如查找元素中包含某個值的檔案,或者元素中存在位于查找范圍區間的值的檔案, // 2.3.1 這個是查找元素中存在red值的檔案,注意,這里不像上面的完全匹配或者部分匹配時使用中括號,而是直接把值帶進去, db.inventory.find( { tags: "red" } ) // 2.3.2 這個是查找陣列元素中存在符合區間范圍的值的元素(類似部分匹配),一般會傳入$gt/$lt/$gte/$lte/$ne/$eq之類的匹配范圍運算子 // 這里是查找 dim_cm陣列中,存在大于25的值的元素, db.inventory.find( { dim_cm: { $gt: 25 } } ) 2.3.1和2.3.2結果見下圖 當然也可以使用多條件匹配查詢,就是下文要講到的$elemMatch查詢, 大概格式和說明如下,比如 db.inventory.find( { dim_cm: { $elemMatch: { $gt: 22, $lt: 30 } } } ) 說明要查找dim_cm中存在元素值大于22小于30的檔案, 具體看下文,
// 2.1的查詢結果
// 2.2的查詢結果
// 2.3.1 的查詢結果
// 2.3.2 的查詢結果

以上就是基本的陣列查詢,如果涉及到嵌套陣列(就是陣列里面嵌套著物件),無非是在查詢條件那里使用物件形式或者多層級欄位來查詢,
比如存在這樣的資料:{ item: "journal", instock: [ { warehouse: "A", qty: 5 }, { warehouse: "C", qty: 15 } ] } .... 這里為了省事,就列一個,
instock陣列欄位存盤著物件
// 示例查詢陳述句,意思是說查詢instock陣列中的元素存在等于 { warehouse: "A", qty: 5 } 的檔案, db.inventory.find( { "instock": { warehouse: "A", qty: 5 } } ) // 意思是說查詢instock陣列中元素物件中的qty 存在大于等于20的檔案, db.inventory.find( { 'instock.qty': { $lte: 20 } } )
官方的說明、Demo地址: https://www.mongodb.com/docs/manual/tutorial/query-array-of-documents/
1.2 使用$elemMatch運算子查詢,本文側重該方式,
官方說明:The $elemMatch operator matches documents that contain an array field with at least one element that matches all the specified query criteria.
就是說$elemMatch是用來查詢陣列欄位的,如果陣列欄位中有至少1個元素匹配查詢規則,則查詢出來這個陣列,
// 官方標準語法 { <field>: { $elemMatch: { <query1>, <query2>, ... } } } // field是陣列欄位名,在$elemMatch中傳入查詢條件,可多個,用逗號隔開,
舉例說明
// 先插入資料 db.scores.insertMany( [ { _id: 1, results: [ 82, 85, 88 ] }, { _id: 2, results: [ 75, 88, 89 ] } ] ) // 來個最基本的$elemMatch使用演示 // 陳述句說明,查找 results陣列中存在大于等于80且小于85的元素的檔案,(只要元素中有一個匹配,那么這個元素所在的陣列的檔案就會回傳) db.scores.find( { results: { $elemMatch: { $gte: 80, $lt: 85 } } } ) // 回傳結果, { "_id" : 1, "results" : [ 82, 85, 88 ] } // 說明: _id=2的資料,沒有任何一個元素值在80~85之間,所以不回傳,
上面是簡單的陣列結構的查詢,
下面演示下元素為物件的資料的查詢,
// 1. 插入資料 db.survey.insertMany( [ { "_id": 1, "results": [ { "product": "abc", "score": 10 }, { "product": "xyz", "score": 5 } ] }, { "_id": 2, "results": [ { "product": "abc", "score": 8 }, { "product": "xyz", "score": 7 } ] }, { "_id": 3, "results": [ { "product": "abc", "score": 7 }, { "product": "xyz", "score": 8 } ] }, { "_id": 4, "results": [ { "product": "abc", "score": 7 }, { "product": "def", "score": 8 } ] } ] ) // 查詢演示, 這里是查詢results中元素含有 { product: "xyz", score: { $gte: 8 } --- 也就是product = xyz, score ≥ 8的元素, 只要陣列中含有匹配的元素,該陣列所在的檔案回傳, db.survey.find( { results: { $elemMatch: { product: "xyz", score: { $gte: 8 } } } } ) // 查詢結果 --- 可以看到 product = xyz, score≥8,所以這條 id=3的檔案被回傳, { "_id" : 3, "results" : [ { "product" : "abc", "score" : 7 }, { "product" : "xyz", "score" : 8 } ] } // 補充,只要陣列中的元素有至少一個匹配查詢規則($elemMatch中的條件),那么該陣列所在的檔案就回傳,不管陣列中其他的元素怎樣,
帶$elemMatch和不帶的查詢對比
// 不帶$elemMatch 查找results.product不等于xyz的檔案,是要全部元素做匹配,如果有一個元素不匹配,那條資料所在的檔案就不回傳, db.survey.find( { "results.product": { $ne: "xyz" } } ) // 回傳結果 { "_id" : 4, "results" : [ { "product" : "abc", "score" : 7 }, { "product" : "def", "score" : 8 } ] } // 帶$elemMatch db.survey.find( { "results": { $elemMatch: { product: { $ne: "xyz" } } } } ) // 回傳結果,說明,因為是要查找陣列results中存在元素product != xyz的檔案,只要有一個元素的product != xyz,那么這個元素所在的陣列的檔案就會回傳, 下面 id=1\2\3的第一個元素都為abc, != xyz, 所以回傳,哪怕第二個元素的product == xyz, { "_id" : 1, "results" : [ { "product" : "abc", "score" : 10 }, { "product" : "xyz", "score" : 5 } ] } { "_id" : 2, "results" : [ { "product" : "abc", "score" : 8 }, { "product" : "xyz", "score" : 7 } ] } { "_id" : 3, "results" : [ { "product" : "abc", "score" : 7 }, { "product" : "xyz", "score" : 8 } ] } { "_id" : 4, "results" : [ { "product" : "abc", "score" : 7 }, { "product" : "def", "score" : 8 } ] }
可以看到對于陣列的查詢,帶$elemMatch和不帶,區別很大, 通常情況下,一般會用$elemMatch,但有時候也會視實際需求來選擇,
看完了如何查詢,現在可以進入第二步——如何更新,因為update()里面有兩個主要引數,一個是query, 一個是set,
db.collection.updateOne(<filter>, <update>, <options>) filter就是query陳述句, update就是set陳述句,還有一個引數配置,
二、Array(陣列)相關的Update(更新)
1. 官方定義和語法格式
// 官方標準語法定義 db.collection.update( <query>, // 要更新的檔案的查詢陳述句 <update>, // 要更新的內容 { upsert: <boolean>, // 可選,true時開啟,存在則更新,否則新增,默認為False, multi: <boolean>, // 可選, true時開啟,批量更新符合條件的檔案,否則只更新第一條符合條件的檔案,默認false, writeConcern: <document>, // 可選,寫入策略,比如writeConcern:{w:1}, w:1 是默認的writeConcern,表示資料寫入到Primary就向客戶端發送確認, 這個一般可以先不管,除非有需要再去專門看,否則不帶此引數, collation: <document>, // 可選,根據不同的語言定制排序規則,比如{collation: {locale: "zh"}} 代表檔案處理時,按照中文拼音排序規則來排序處理, 默認情況下,是按照欄位值的普通的二機制字串來排序, 可以先忽略, arrayFilters: [ <filterdocument1>, ... ], // 可選,這個對于陣列欄位的更新很有用,尤其是只需要更新陣列中的符合條件的個別元素, 等下下文會有使用演示, hint: <document|string>, // 可選, 4.2 版本后新增的東西 強制某個欄位使用索引, 盡管mongodb會自動優化處理,但為了避免某個欄位沒有使用索引,可以強制指定, let: <document> // 可選, 5.0 版本后新增的東西 一個變數定義選項,可以讓命令的可讀性得到提升, } ) // 上面的let 選項,如下是一個簡易示例, 假設有這幾條資料 db.cakeFlavors.insertMany( [ { _id: 1, flavor: "chocolate" }, { _id: 2, flavor: "strawberry" }, { _id: 3, flavor: "cherry" } ] ) // 執行下述陳述句,用了let 分別定義了 targetFlavor變數,值為cherry, newFlavor變數,值為 orange, 在前面的 query/update 中,對應的匹配值和新的set的值,是用了let中定義的變數名來占位, db.cakeFlavors.update( { $expr: { $eq: [ "$flavor", "$$targetFlavor" ] } }, [ { $set: { flavor: "$$newFlavor" } } ], { let : { targetFlavor: "cherry", newFlavor: "orange" } } ) 上面的意思就是查找flalvor等于targetFlavor(let中定義的變數)的值(也就是cherry)的檔案,然后把flavor的值更新成 newFlavor(let中定義的變數)的值(即 orange),
除了上面標準語法,還有updateOne--更新符合條件的第一條;updateMany--更新多條,replaceOne--替換符合條件的一條, 引數和上面的一樣,不贅述,
- db.collection.updateOne(<filter>, <update>, <options>)
- db.collection.updateMany(<filter>, <update>, <options>)
- db.collection.replaceOne(<filter>, <update>, <options>)
2. 陣列更新運算子(Array Update Operators)
要正確、熟悉地實作針對陣列的更新,需要了解學習以下幾個陣列更新運算子,
- $ 占位符,只更新符合條件的檔案的陣列欄位中的第一個匹配的元素, 下文有demo,
- $[] 占位符,和$的區別是更新符合條件的檔案的陣列欄位中的所有元素,
- $[<identifier>] 也是占位符,但是只更新符合條件的檔案的陣列中的指定元素(符合某個條件), 要和update中的第三個引數中的可選項 arrayFilters配合使用,
- $addToSet,添加元素到一個陣列,確保不重復(set),如果陣列中沒有一模一樣的元素,可以插入,如果有,則無法插入,
- $pop 洗掉陣列第一個或者最后一個元素,
- $pull 洗掉陣列中所有符合指定條件的元素,
- $push 添加一個元素到陣列中,
- $pullAll 洗掉陣列中的所有元素,
3. 舉例
基于上述的陣列欄位的查詢,以及update語法,我們可以開始做基于陣列的更新操作演示了,非陣列欄位的更新,請讀者自行找官方檔案參考學習,此處不贅述,
3.1 $ 占位符
用于只更新符合條件的檔案中的第一個匹配的元素,
// 讓我們先插入一些資料 db.students.insertMany( [ { "_id" : 1, "grades" : [ 85, 80, 80 ] }, { "_id" : 2, "grades" : [ 88, 90, 92 ] }, { "_id" : 3, "grades" : [ 85, 100, 90 ] } ] ) // 注意,這里用的updateOne,只更新一條, // 查找_id=1, grades陣列中有80的檔案,把grades中第一個匹配的元素(就是值為80)替換成 82 db.students.updateOne( { _id: 1, grades: 80 }, { $set: { "grades.$" : 82 } } ) // 更新完畢后,可以看到id=1的資料中的grades,第一個80變成82了,后面的80沒變, 這就是$,代表占位匹配的第一個元素位置(不是陣列的第一個元素), { "_id" : 1, "grades" : [ 85, 82, 80 ] } { "_id" : 2, "grades" : [ 88, 90, 92 ] } { "_id" : 3, "grades" : [ 85, 100, 90 ] } // 有人說,如果我要更新所有grades含有 90的陣列的第一個匹配元素呢?請看下面陳述句, // 使用update,開啟批量更新( {multi:true}), 查找grades存在90的檔案,并把每個檔案中的第一個90替換成82. db.students.update( { grades: 90 }, { $set: { "grades.$" : 82 } }, {multi:true} ) // 執行后的結果 { "_id" : 1, "grades" : [ 85, 82, 80 ] } { "_id" : 2, "grades" : [ 88, 82, 92 ] } { "_id" : 3, "grades" : [ 85, 100, 82] }
上面是比較簡單的普通陣列,如果陣列存盤的是物件呢? 同理的,看代碼
// 先執行一下把Students的資料清空 db.students.remove({}) // 插入帶物件的陣列資料 db.students.insertMany( [ {"_id" : 4, "grades" : [ { "grade" : 80, "mean" : 75, "std" : 8 }, { "grade" : 85, "mean" : 90, "std" : 6 }, { "grade" : 85, "mean" : 85, "std" : 8 } ] }, { "_id": 5, "grades": [ { "grade": 80, "mean": 75, "std": 8 }, { "grade": 85, "mean": 90, "std": 5 }, { "grade": 90, "mean": 85, "std": 3 } ] } ]) // 執行updateOne db.students.updateOne( { _id: 4, "grades.grade": 85 }, { $set: { "grades.$.std" : 10 } } )
可以看到,成功更新1條,
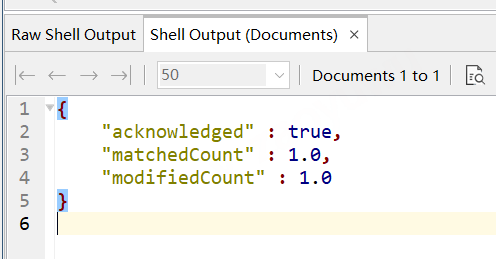
查看結果如下圖, 物件陣列的操作也一樣的, 只更新第一個匹配的元素,
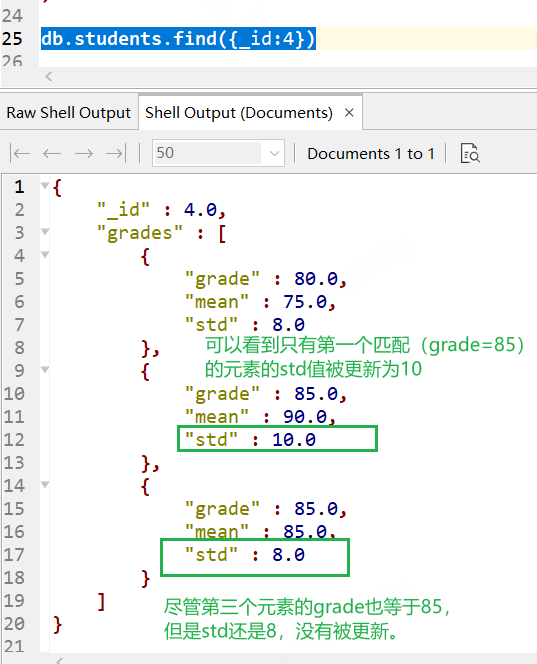
上面的例子,沒有使用$elemMatch作為匹配查詢條件,你要用也可以, 自己嘗試,
3.2 $[] 占位符
和$的區別是更新符合條件的檔案的陣列欄位中的所有元素,
// 還是一樣,先清空下資料 db.students.remove({}) // 插入演示資料 db.students.insertMany( [ { "_id" : 1, "grades" : [ { "grade" : 80, "mean" : 75, "std" : 8 }, { "grade" : 85, "mean" : 90, "std" : 6 }, { "grade" : 85, "mean" : 85, "std" : 8 } ] }, { "_id" : 2, "grades" : [ { "grade" : 90, "mean" : 75, "std" : 8 }, { "grade" : 87, "mean" : 90, "std" : 5 }, { "grade" : 85, "mean" : 85, "std" : 6 } ] } ] ) // 更新所有grades陣列中含有grade大于80的檔案,使用grades.$[].std表示更新每個匹配檔案中的所有元素的std欄位值, 這里是統一改成10, db.students.updateMany( {"grades":{$elemMatch:{"grade": {$gt:80}}}}, { $set: { "grades.$[].std" : 10 } }, ) 結果看下圖
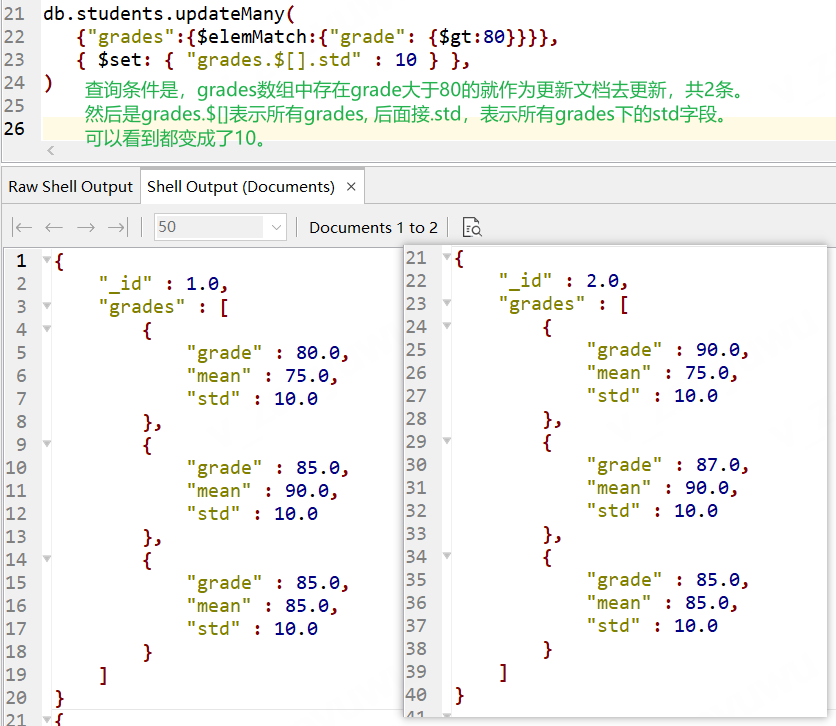
假如你要處理的陣列欄位不是一個物件,只是字串或者數字,$[]后面不需要接下級欄位, 如下參考代碼,
db.students.updateMany( {"grades":{$elemMatch:{"grade": {$gt:80}}}}, { $set: { "grades.$[]" : "隨便你寫個值" } }, // 這里grades 假設是一個字串陣列, )
寫到這里,我們已經分別用$、$[] 實作對第一個匹配的元素、符合條件的所有檔案下的所有元素做更新,
有讀者可能會問,那么我想只更新檔案下的部分元素呢?比如我只想把陣列中的grade大于等于87的元素的std換成 22呢?
好問題,對于這種需求,要使用第三種占位符 $[<identifier>],
3.3 $[<identifier>]
注意:$[<identifier>] 通常情況下是要和 arrayFilters 一起使用的,語法格式如下
db.collection.updateMany( { <query conditions> }, // 查詢條件 { <update operator>: { "<array>.$[<identifier>]" : value } }, // 更新內容 { arrayFilters: [ { <identifier>: <condition> } ] } // 陣列過濾條件 )
請看代碼,
// 先清空下資料 db.students.remove({}) // 插入資料 db.students.insertMany( [ { "_id" : 1, "grades" : [ 95, 92, 90 ] }, { "_id" : 2, "grades" : [ 98, 100, 102 ] }, { "_id" : 3, "grades" : [ 95, 110, 100 ] } ] ) // 使用$[<identifier>] 更新 // 查詢所有,把grades中≥100的值全部換成333, db.students.updateMany( { }, { $set: { "grades.$[element]" : 333 } }, { arrayFilters: [ { "element": { $gte: 100 } } ] } ) 注意: identifier的名稱可以是任意,但是$set和arrayFilters中的名稱要一致, 執行后的資料結果如下,
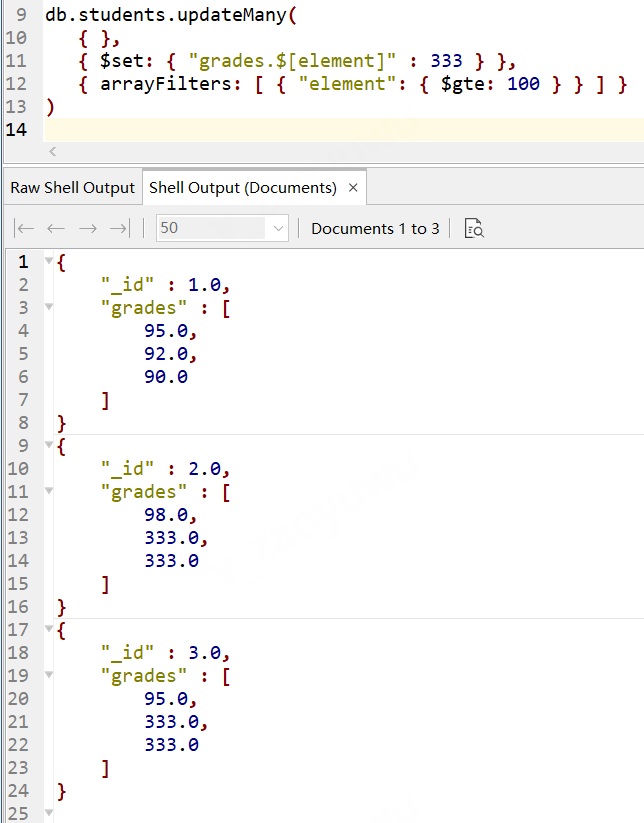
可以看到,上面只更新了匹配的檔案中的符合arrayFilters條件的元素,
有人又問,你這是一個簡單的陣列,可以演示下物件陣列嗎? 可以,看代碼,
// 還是先清空資料 db.students.remove({}) // 插入資料 db.students.insertMany( [ { "_id" : 1, "grades" : [ { "grade" : 80, "mean" : 75, "std" : 5 }, { "grade" : 85, "mean" : 100, "std" : 4 }, { "grade" : 85, "mean" : 100, "std" : 5 } ] }, { "_id" : 2, "grades" : [ { "grade" : 90, "mean" : 100, "std" : 5 }, { "grade" : 87, "mean" : 100, "std" : 3 }, { "grade" : 85, "mean" : 100, "std" : 4 } ] } ] ) // 查詢所有,把所有grades中的grade ≥ 85的元素中的mean更新為111 db.students.updateMany( { }, { $set: { "grades.$[elem].mean" : 111 } }, { arrayFilters: [ { "elem.grade": { $gte: 85 } } ] } ) 注意: arrayFilters的elem要和set中的$[elem]中的elem一致, 是一個識別符號, 可以任意,但要一致, 執行后結果如下圖
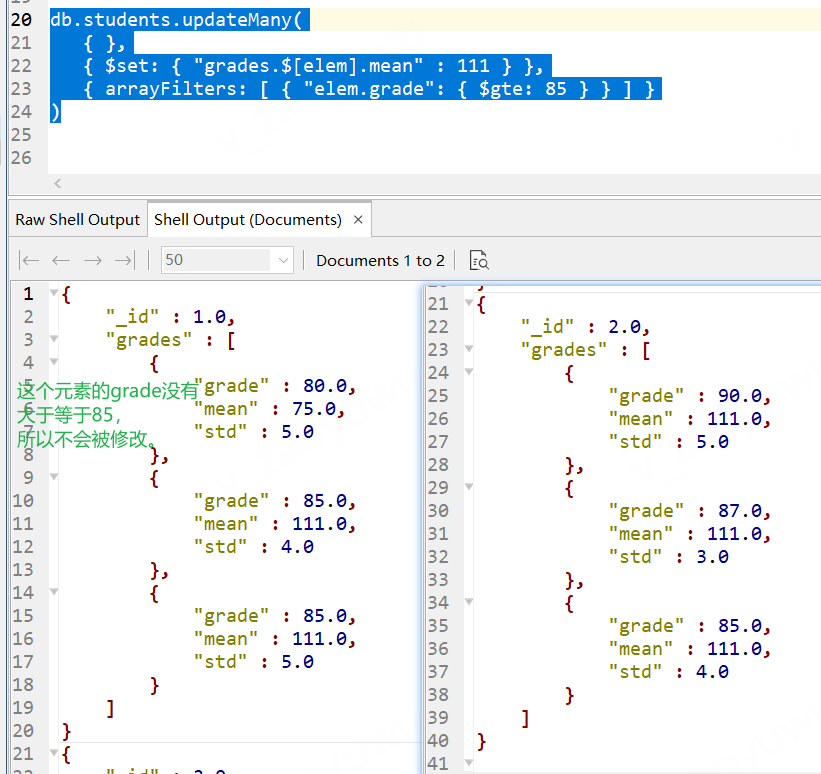
講到這里,對于陣列欄位中的元素編輯基本上可以滿足開發需求,再小結下,
- $ : 更新檔案中匹配的第一個元素
- $[] : 更新檔案中所有元素
- $[<identifier>] : 條件更新
除了上面3個占位符,mongodb 陣列中的更新還有幾個運算子($addToSet, $pop, $pull, $push, $pullAll),下面逐一介紹,
$addToSet
AddToSet
// 語法格式:
{ $addToSet: { <field1>: <value1>, ... } } // 欄位名:值
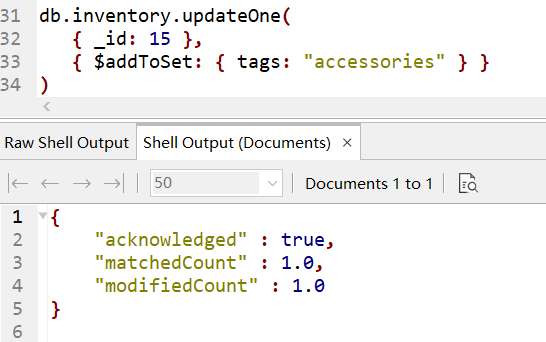
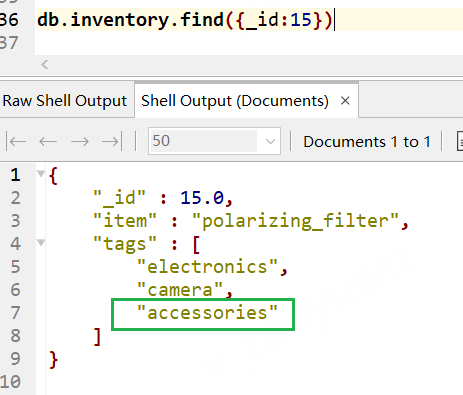
// 插入一條演示資料 db.inventory.insertOne( { _id: 1, item: "polarizing_filter", tags: [ "electronics", "camera" ] } ) // 使用addToSet 添加一個元素到Tags中, db.inventory.updateOne( { _id: 1 }, { $addToSet: { tags: "accessories" } } )
可以看到 accessories 作為元素追加到了tags陣列中
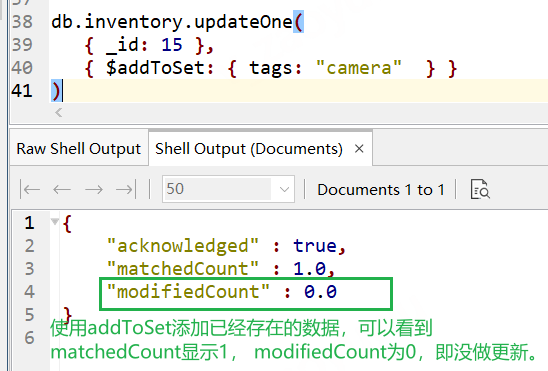
當要插入的元素已經存在,可以看到modified是0,也就是沒更新,
$pop
// 作用,洗掉陣列中的第一個或者最后一個元素,
// 語法格式 { $pop: { <field>: <-1 | 1>, ... } } 其中 -1, 1 分別代表陣列的第一個元素和最后一個元素 // 插入資料 db.students.insertOne( { _id: 1, scores: [ 8, 9, 10 ] } ) // 洗掉scores陣列的第一個元素(-1) db.students.updateOne( { _id: 1 }, { $pop: { scores: -1 } } ) // 再次查看 結果如下 { _id: 1, scores: [ 9, 10 ] } 可以看到第一個元素 8 已經被刪掉,
$push
// 作用: 把一個元素加入到陣列中,
// 語法
{ $push: { <field1>: <value1>, ... } }
// 插入資料
db.students.insertMany( [
{ _id: 2, scores: [ 45, 78, 38, 80, 89 ] } ,
{ _id: 3, scores: [ 46, 78, 38, 80, 89 ] } ,
{ _id: 4, scores: [ 47, 78, 38, 80, 89 ] }
] )
// 批量更新,對每個檔案都往scores中追加一個元素 95.
db.students.updateMany(
{ },
{ $push: { scores: 95 } }
)
// 再次查詢 結果
[
{ _id: 1, scores: [ 44, 78, 38, 80, 89, 95 ] },
{ _id: 2, scores: [ 45, 78, 38, 80, 89, 95 ] },
{ _id: 3, scores: [ 46, 78, 38, 80, 89, 95 ] },
{ _id: 4, scores: [ 47, 78, 38, 80, 89, 95 ] }
]
$pull
// 作用:洗掉陣列中的指定元素(通過查詢條件),
// 注意和 $pullAll的區別, pullAll是洗掉所有指定值元素, pull是傳入查詢條件,洗掉符合條件的元素,
// 語法格式 { $pull: { <field1>: <value|condition>, <field2>: <value|condition>, ... } } // 插入資料 db.stores.insertMany( [ { _id: 1, fruits: [ "apples", "pears", "oranges", "grapes", "bananas" ], vegetables: [ "carrots", "celery", "squash", "carrots" ] }, { _id: 2, fruits: [ "plums", "kiwis", "oranges", "bananas", "apples" ], vegetables: [ "broccoli", "zucchini", "carrots", "onions" ] } ] ) // 刪掉fruits中所有apples, oranges元素,刪掉vegatables中所有carrots元素, db.stores.updateMany( { }, { $pull: { fruits: { $in: [ "apples", "oranges" ] }, vegetables: "carrots" } } ) // 執行后結果 { _id: 1, fruits: [ 'pears', 'grapes', 'bananas' ], vegetables: [ 'celery', 'squash' ] }, { _id: 2, fruits: [ 'plums', 'kiwis', 'bananas' ], vegetables: [ 'broccoli', 'zucchini', 'onions' ] }
$pullAll
請注意和$pull的區別
// 作用,傳入指定值,洗掉陣列中元素為指定值的所有元素,和$pull的區別是,pull是依賴于傳入的查詢條件,洗掉匹配查詢條件的元素, // 語法格式 { $pullAll: { <field1>: [ <value1>, <value2> ... ], ... } } // 插入資料 db.survey.insertOne( { _id: 1, scores: [ 0, 2, 5, 5, 1, 0 ] } ) // 執行 db.survey.updateOne( { _id: 1 }, { $pullAll: { scores: [ 0, 5 ] } } ) // 洗掉 0,5的元素,再次查詢,結果如下 { "_id" : 1, "scores" : [ 2, 1 ] }
希望這篇文章能幫到大家,有錯漏之處,歡迎指正,
完,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/546143.html
標籤:其他