
本文將從以下五部分切入,講述日志系統的演進之路:攜程日志的背景和現狀、如何搭建一套日志系統、從 ElasticSearch 到 Clickhouse 存盤演進、日志3.0重構及未來計劃,
一、日志背景及現狀
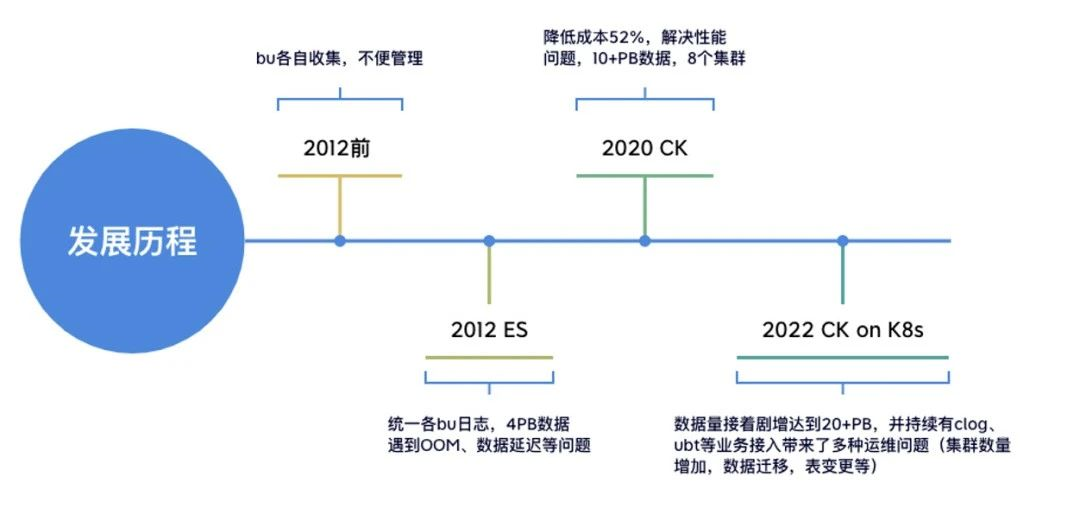
圖1
2012年以前,攜程的各個部門日志自行收集治理(如圖1),這樣的方式缺乏統一標準,不便治理管控,也更加消耗人力和物力,
從2012年開始,攜程技術中心推出基于 ElasticSearch 的日志系統,統一了日志的接入、ETL、存盤和查詢標準,隨著業務量的增長,資料量膨脹到 4PB 級別,給原來的 ElasticSearch 存盤方案帶來不少挑戰,如 OOM、資料延遲及負載不均等,此外,隨著集群規模的擴大,成本問題日趨敏感,如何節省成本也成為一個新的難題,
2020年初,我們提出用 Clickhouse 作為主要存盤引擎來替換 ElasticSearch 的方案,該方案極大地解決了 ElasticSearch 集群遇到的性能問題,并且將成本節省為原來的48%,2021年底,日志平臺已經累積了20+PB 的資料量,集群也達到了數十個規模(如圖2),
2022年開始,我們提出日志統一戰略,將公司的 CLOG 及 UBT 業務統一到這套日志系統,預期資料規模將達到 30+PB,同時,經過兩年多的大規模應用,日志集群累積了各種各樣的運維難題,如集群數量激增、資料遷移不便及表變更例外等,因此,日志3.0應運而生,該方案落地了類分庫分表設計、Clickhouse on Kubernetes、統一查詢治理層等,聚焦解決了架構和運維上的難題,并實作了攜程 CLOG 與 ESLOG 日志平臺統一,
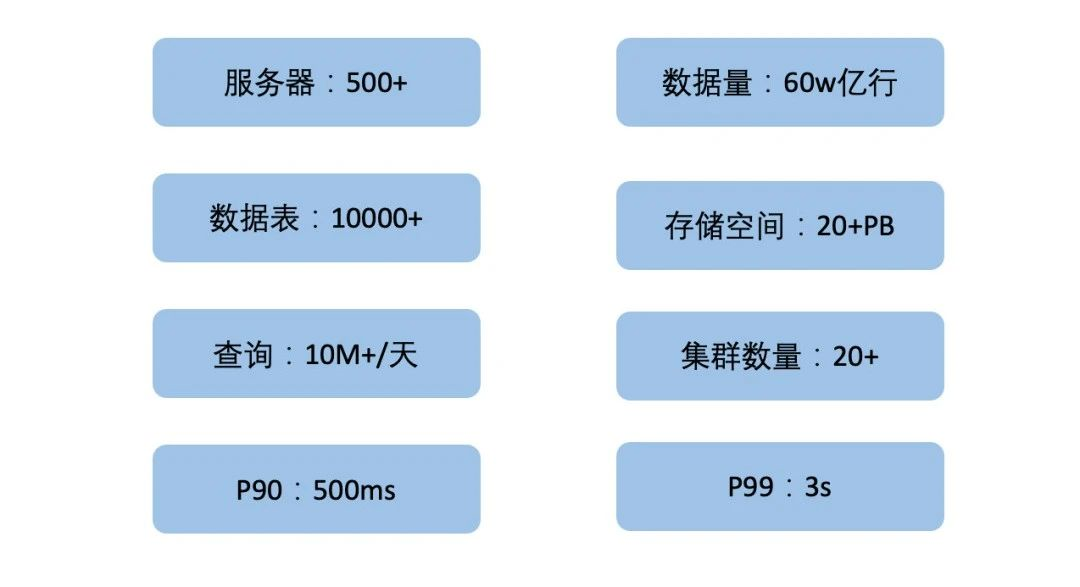
圖2
二、如何搭建日志系統
2.1 架構圖
從架構圖來看(如圖3),整個日志系統可以分為:資料接入、資料 ETL、資料存盤、資料查詢展示、元資料管理系統和集群管理系統,
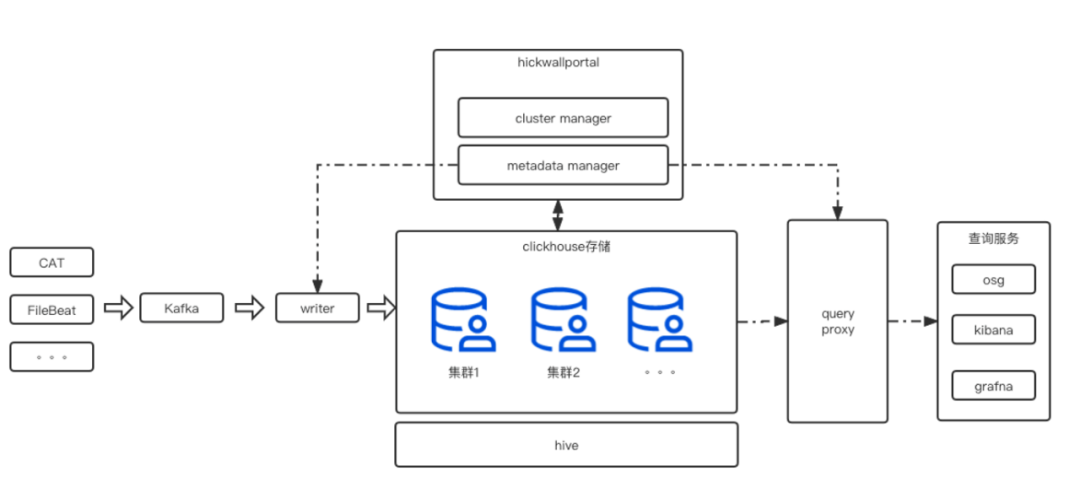
圖3
2.2 資料接入
資料接入主要有兩種方式:
第一種是使用公司框架 TripLog 接入到訊息中間件 Kafka(Hermes協議)(如圖4),

圖4
第二種是用戶使用 Filebeat/Logagent/Logstash 或者寫程式自行上報資料到 Kafka(如圖5),再通過 GoHangout 寫入到存盤引擎中,
圖5
2.3 資料傳輸ETL(GoHangout)
GoHangout 是仿照 Logstash 做的一個開源應用(Github鏈接),用于把資料從 Kafka 消費并進行 ETL,最終輸出到不同的存盤介質(Clickhouse、ElasticSearch),其中資料處理 Filter 模塊包含了常見的 Json 處理、Grok 正則匹配和時間轉換等一系列的資料清理功能(如圖6),GoHangout 會將資料 Message 欄位中的 num 資料用正則匹配的方式提取成單獨欄位,
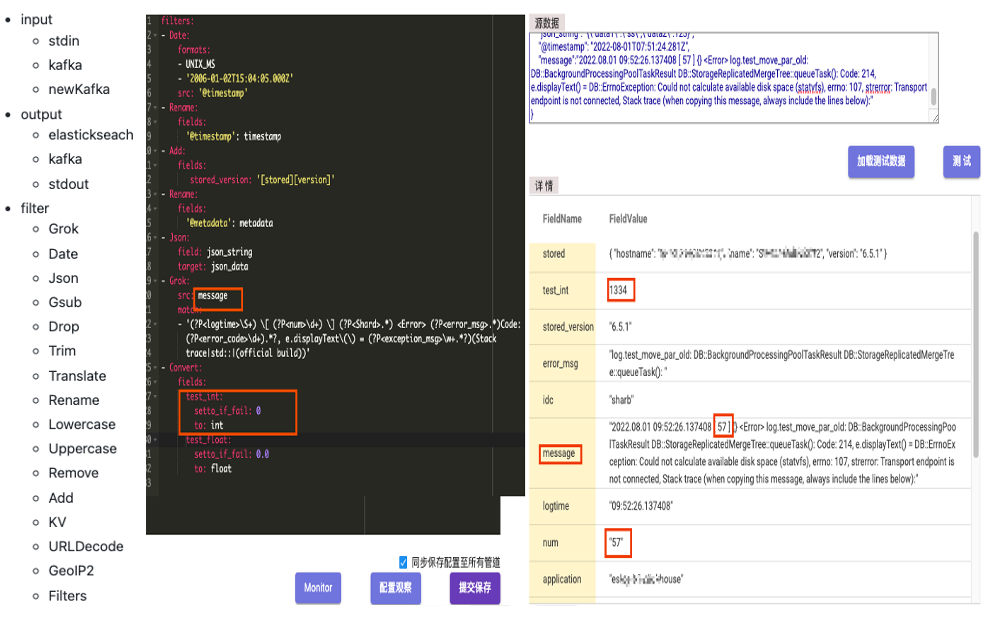
圖6
2.4 ElasticSearch 資料存盤
早期2012年第一版,我們使用 ElasticSearch 作為存盤引擎,ElasticSearch 存盤主要由 Master Node、Coordinator Node、Data Node 組成(如圖7),Master 節點主要負責創建或洗掉索引,跟蹤哪些節點是集群的一部分,并決定哪些分片分配給相關的節點;Coordinator 節點主要用于處理請求,負責路由請求到正確的節點,如創建索引的請求需要路由到 Master 節點;Data 節點主要用于存盤大量的索引資料,并進行增刪改查,一般對機器的配置要求比較高,
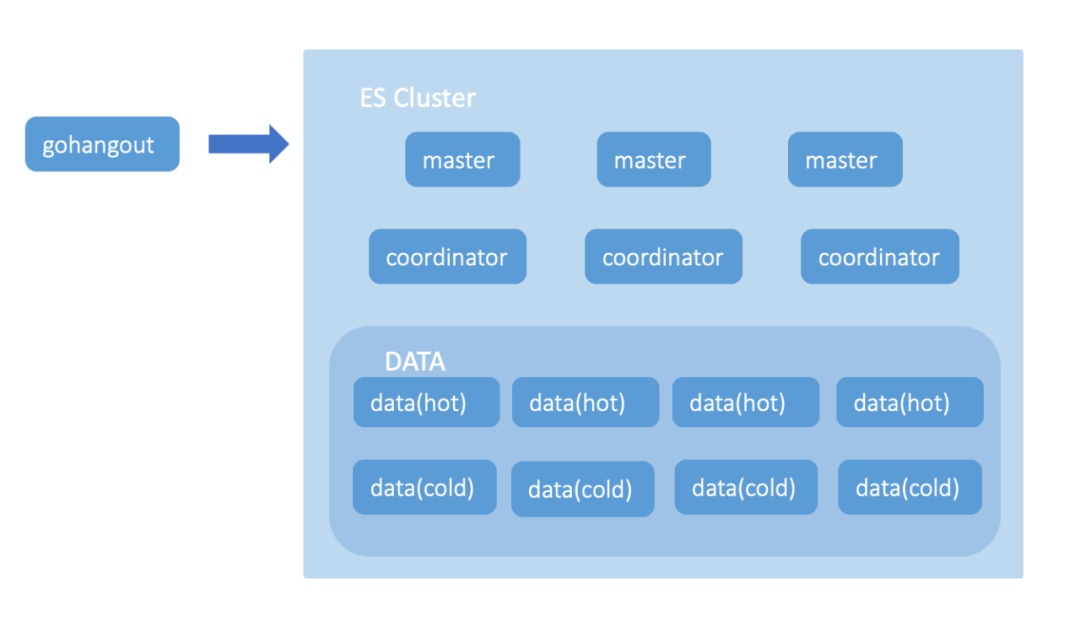
圖7
2.5 資料展示
資料展示方面我們使用了 Elastic Stack 家族的 Kibana(如圖8),Kibana 是一款適合于 ElasticSearch 的資料可視化和管理工具,提供實時的直方圖、線形圖、餅狀圖和表格等,極大地方便日志資料的展示,
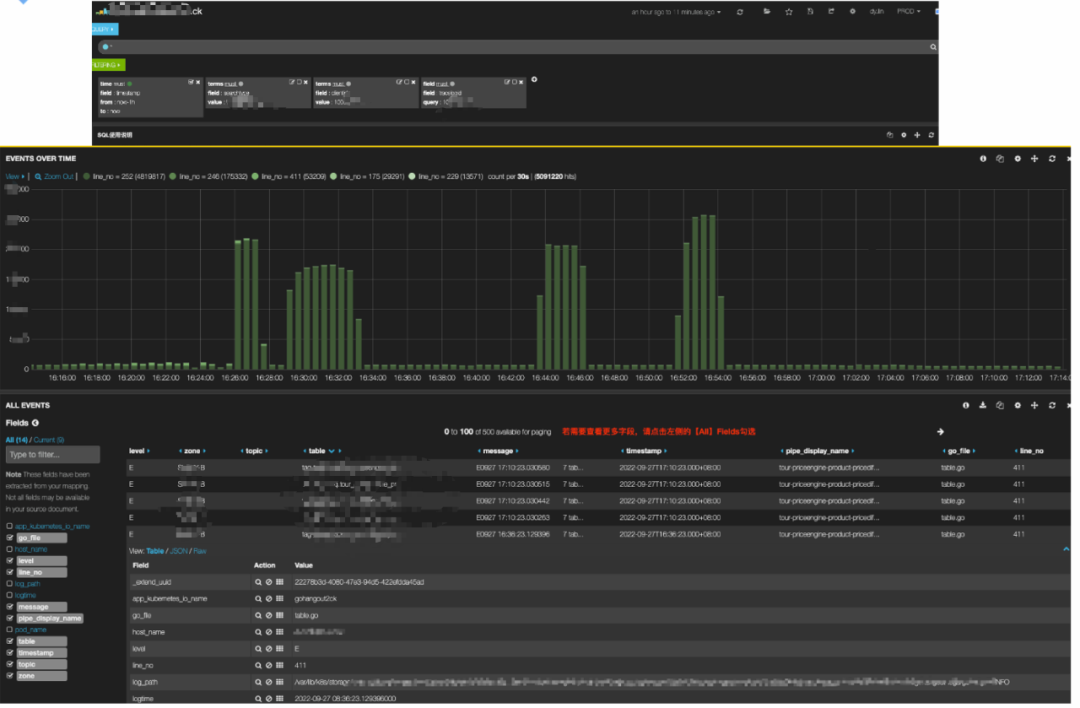
圖8
2.6 表元資料管理平臺
表元資料管理平臺是用戶接入日志系統的入口,我們將每個 Index/ Table 都定義為一個Scenario(如圖9),我們通過平臺配置并管理 Scenario 的一些基礎資訊,如:TTL、歸屬、權限、ETL 規則和監控日志等,
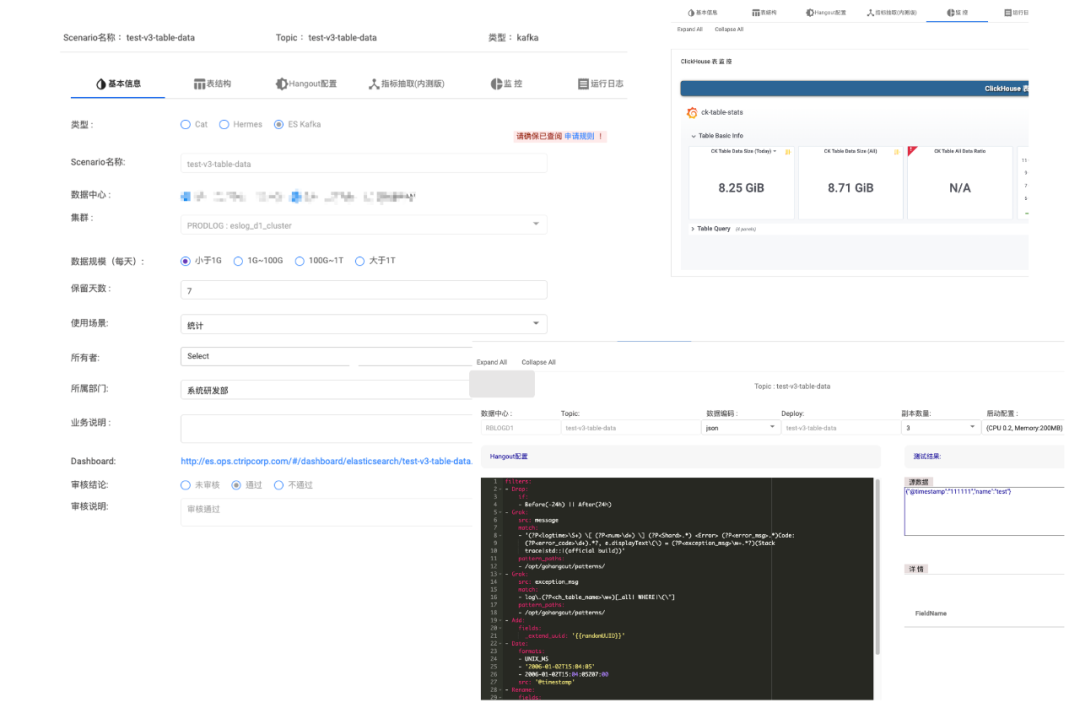
圖9
三、 從Elasticsearch到Clickhouse
我們將會從背景、Clickhouse 簡介、ElasticSearch 對比和解決方案四方面介紹日志從 ElasticSearch 到 Clickhouse 的演程序序,2020年初,隨著業務量的增長,給 ElasticSearch 集群帶來了不少難題,主要體現在穩定性、性能和成本三個方面,
(1)穩定性上:
ElasticSearch 集群負載高,導致較多的請求 Reject、寫入延遲和慢查詢,
每天 200TB 的資料從熱節點搬遷到冷節點,也有不少的性能損耗,
節點間負載不均衡,部分節點單負載過高,影響集群穩定性,
大查詢導致 ElasticSearch 節點 OOM,
(2)性能上:
ElasticSearch的吞吐量也達到瓶頸,
查詢速度受到整體集群的負載影響,
(3)成本上:
倒排索引導致資料壓縮率不高,
大文本場景性價比低,無法保存長時間資料,
3.1 Clickhouse 簡介與 Elasticsearch 對比
Clickhouse 是一個用于聯機分析(OLAP)的列式資料庫管理系統(DBMS),Yandex 在2016年開源,使用 C++ 語法開發,是一款PB級別的互動式分析資料庫,包含了以下主要特效:列式存盤、Vector、Code Generation、分布式、DBMS、實時OLAP、高壓縮率、高吞吐、豐富的分析函式和 Shared Nothin g架構等,
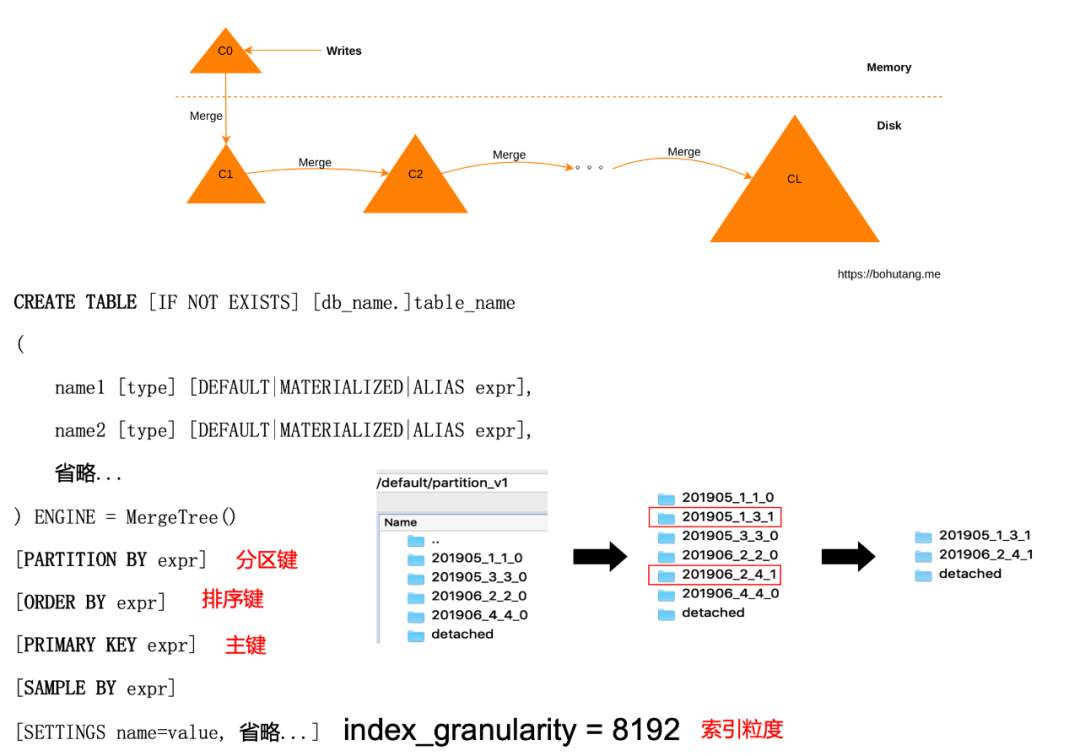
圖10
Clickhouse采用的是 SQL 的互動方式,非常方便上手,接下來,我們將簡單介紹一下 Clickhouse 的類 LSM、排序鍵、磁區鍵特效,了解 Clickhouse 的主要原理,
首先,用戶每批寫入的資料會根據其排序鍵進行排序,并寫入一個新的檔案夾(如201905_1_1_0),我們稱為 Part C0(如圖10),隨后,Clickhouse 會定期在后臺將這些 Part 通過歸并排序的方式進行合并排序,使得最終資料生成一個個資料順序且空間占用較大的 Part,這樣的方式從磁盤讀寫層面上看,能充分地把原先磁盤的隨機讀寫巧妙地轉化為順序讀寫,大大提升系統的吞吐量和查詢效率,同時列式存盤+順序資料的存盤方式也為資料壓縮率提供了便利,201905_1_1_0與201905_3_3_0合并為201905_1_3_1就是一個經典的例子,
另外,Clickhouse 會根據磁區鍵(如按月磁區)對資料進行按月磁區,05、06月的資料被分為了不同的檔案夾,方便快速索引和管理資料,
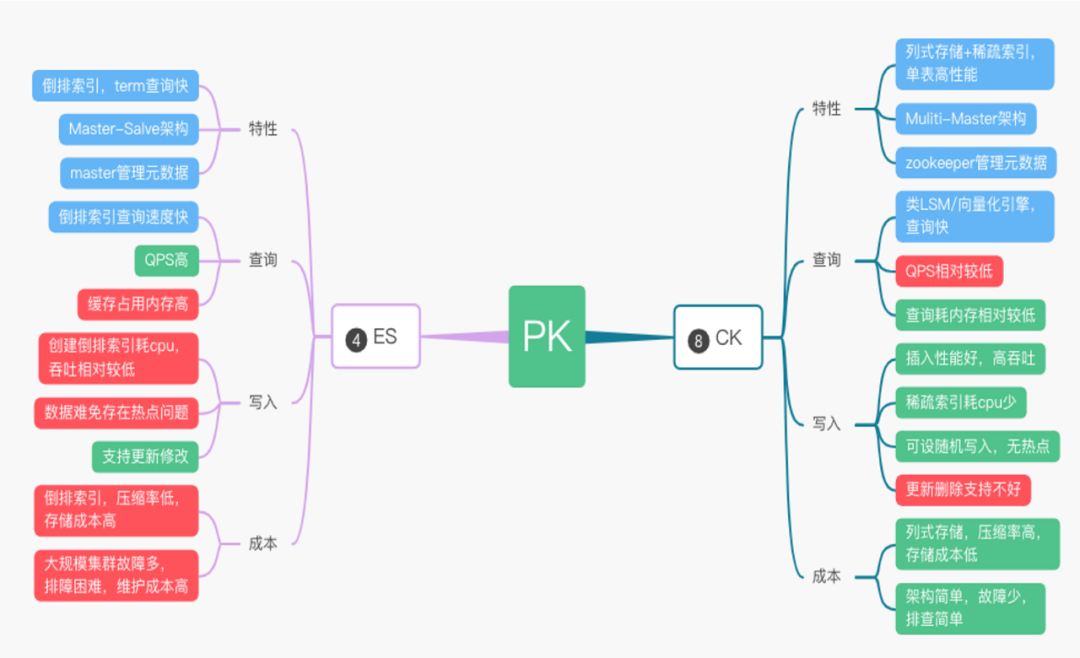
圖11
我們看中了 Clickhouse 的列式存盤、向量化、高壓縮率和高吞吐等特效(如圖11),很好地滿足了我們當下日志集群對性能穩定性和成本的訴求,于是,我們決定用Clickhouse來替代原本 ElasticSearch 存盤引擎的位置,
3.2 解決方案
有了存盤引擎后,我們需要實作對用戶無感知的存盤遷移,這主要涉及了以下的作業內容(如圖12):自動化建表、GoHangout 修改、Clickhouse 架構設計部署和 Kibana 改造,
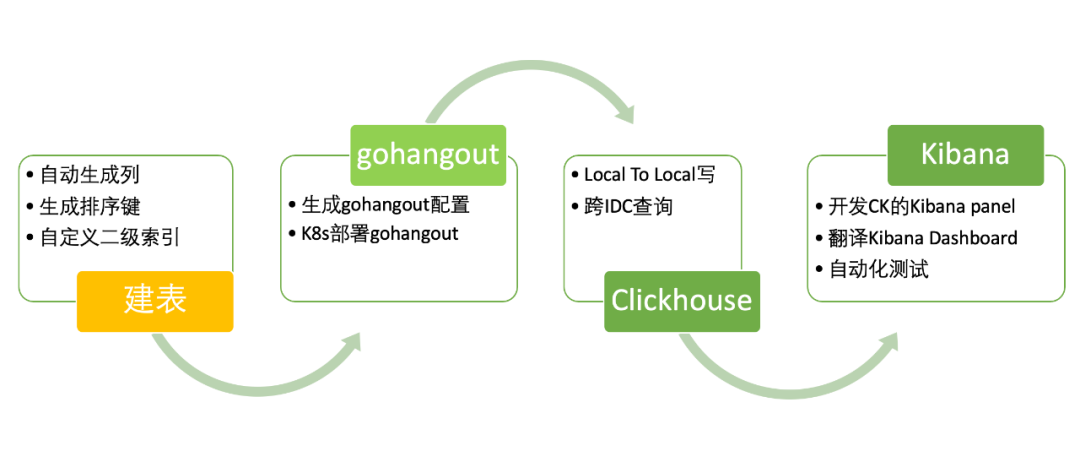
圖12
(1)庫表設計
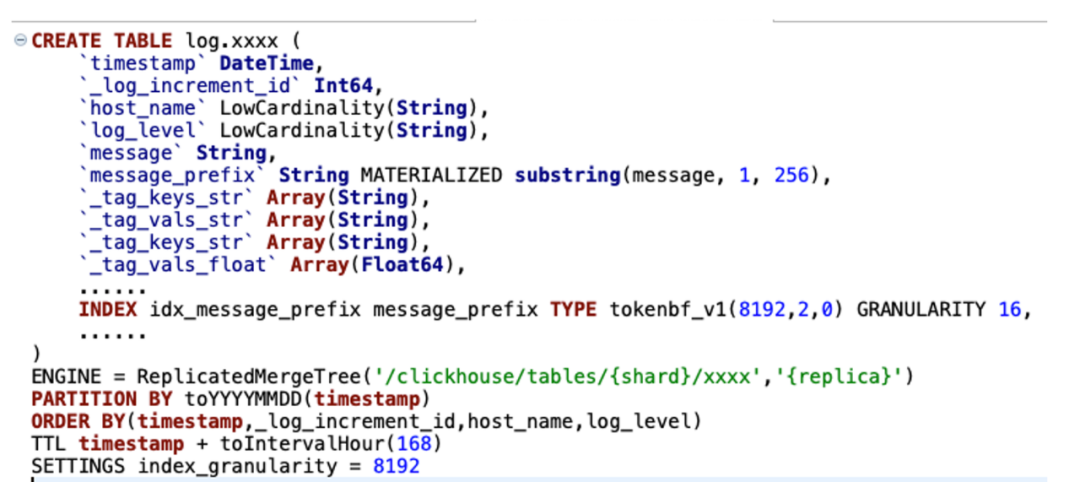
圖13
我們對ck在日志場景落地做了很多細節的優化(如圖13),主要體現在庫表設計:
我們采用雙 list 的方式來存盤動態變化的 tags(當然最新的版本22.8,也可以用map和新特性的 json 方式),
按天磁區和時間排序,用于快速定位日志資料,
Tokenbf_v1 布隆過濾用于優化 term 查詢、模糊查詢,
_log_increment_id 全域唯一遞增 id,用于滾動翻頁和明細資料定位,
ZSTD 的資料壓縮方式,節省了40%以上的存盤成本,
(2)Clickhouse 存盤設計
Clickhouse 集群主要由查詢集群、多個資料集群和 Zookeeper 集群組成(如圖14),查詢集群由相互獨立的節點組成,節點不存盤資料是無狀態的,資料集群則由Shard組成,每個 Shard 又涵蓋了多個副本 Replica,副本之間是主主的關系(不同于常見的主從關系),兩個副本都可以用于資料寫入,互相同步資料,而副本之間的元資料一致性則有 Zookeeper 集群負責管理,
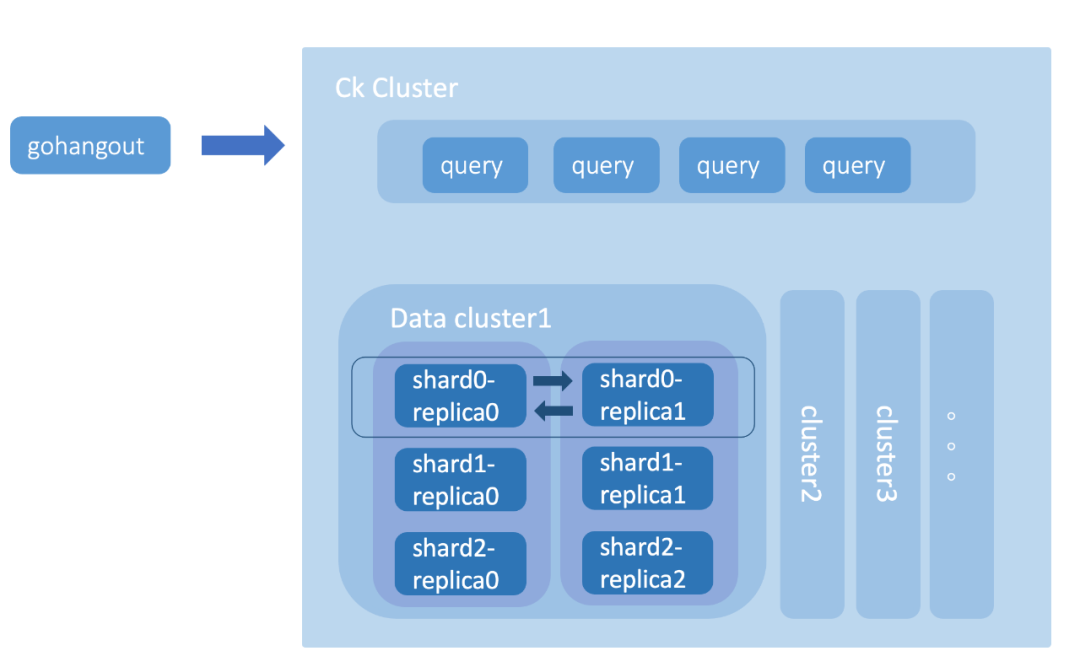
圖14
(3)資料展示
為了實作用戶無感知的存盤切換,我們專門實作了 Kibana 對 Clickhouse 資料源的適配并開發了不同的資料 panel(如圖15),包括:chhistogram、chhits、chpercentiles、chranges、chstats、chtable、chterms 和 chuniq,通過 Dashboard 腳本批量生產替代的方式,我們快速地實作了原先 ElasticSearch 的 Dashboard 的遷移,其自動化程度達到95%,同時,我們也支持了使用 Grafana 的方式直接配置 SQL 來生成日志看板,
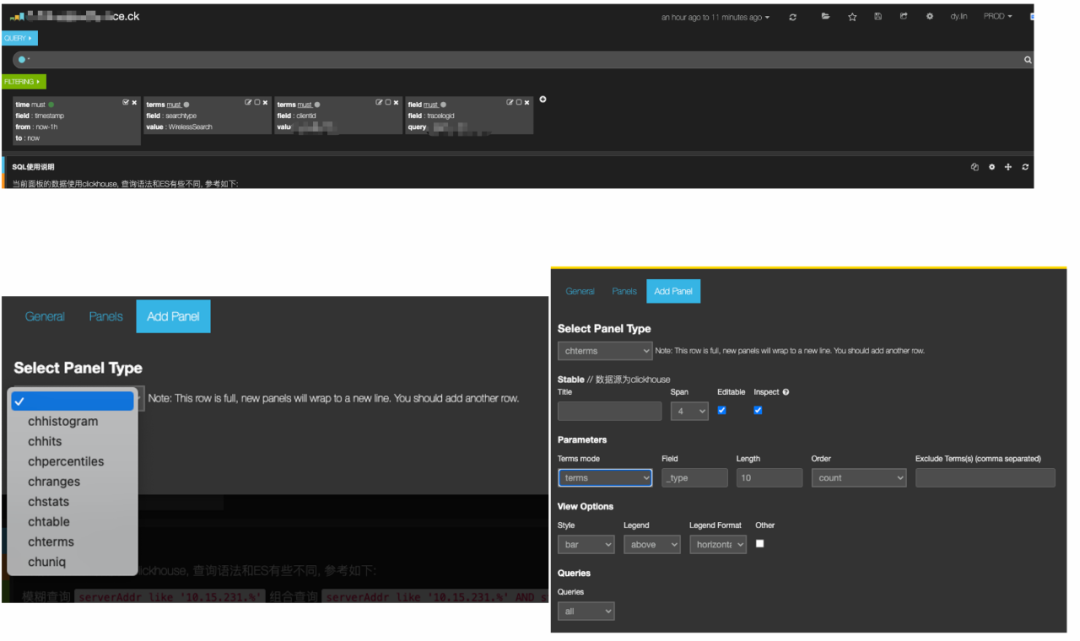
圖15
(4)集群管理平臺
為了更好地管理 Clickhouse 集群,我們也做了一整套界面化的 Clickhouse 運維管理平臺,該平臺覆寫了日常的 shard 管理、節點生成、系結/解綁、權重修改、DDL 管理和監控告警等治理工具(如圖16),

圖16
3.3 成果
遷移程序自動化程度超過95%,基本實作對用戶透明,
存盤空間節約50+%(如圖17),用原有ElasticSearch的服務器支撐了4倍業務量的增長,
查詢速度比ElasticSearch快4~30倍,查詢P90小于300ms,P99小于1.5s,
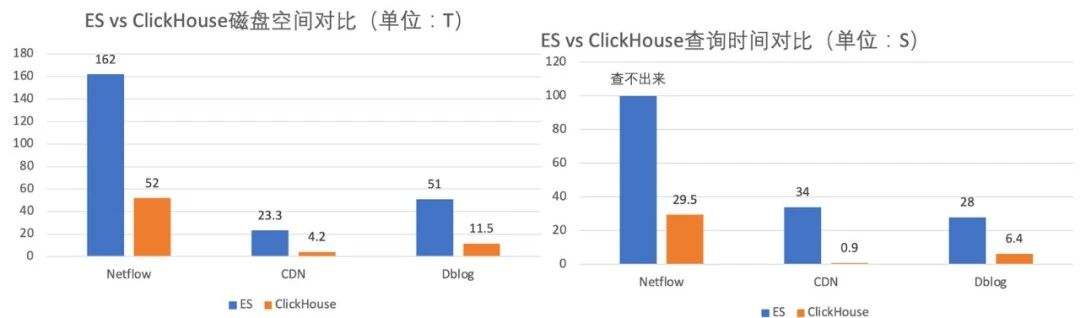
圖17
四、日志3.0構建
時間來到2022年,公司日志規模再進一步增加到 20+PB,同時,我們提出日志統一戰略,將公司的 CLOG 及 UBT 業務統一到這套日志系統,預期資料規模將達到 30+PB,另外,經過兩年多的大規模應用,日志系統也面臨了各種各樣的運維難題,
(1) 性能與功能痛點
單集群規模太大,Zookeeper 性能達到瓶頸,導致 DDL 超時例外,
當表資料規模較大時,洗掉欄位,容易超時導致元資料不一致,
用戶索引設定不佳導致查詢慢時,重建排序鍵需要洗掉歷史資料,重新建表,
查詢層缺少限流、防呆和自動優化等功能,導致查詢不穩定,
(2) 運維痛點
表與集群嚴格系結,集群磁盤滿后,只能通過雙寫遷移,
集群搭建依賴 Ansible,部署周期長(數小時),
Clickhouse 版本與社區版本脫節,目前集群的部署模式不便版本更新,
面對這樣的難題,我們在2022年推出了日志3.0改造,落地了集群 Clickhouse on Kubernetes、類分庫分表設計和統一查詢治理層等方案,聚焦解決了架構和運維上的難題,最終,實作了統一攜程 CLOG 與 ESLOG 兩套日志系統,
4.1 ck on k8s
我們使用 Statefulset、反親和、Configmap 等技術實作了 Clickhouse 和 Zookeeper 集群的 Kubernetes 化部署,使得單集群交付時間從2天優化到5分鐘,同時,我們統一了部署架構,將海內外多環境部署流程標準化,這種方式顯著地降低了運維成本并釋放人力,更便利的部署方式有益于單個大集群的切割,我們將大集群劃分為多個小集群,解決了單集群規模過大導致 Zookeeper 性能瓶頸的問題,
4.2 類分庫分表設計
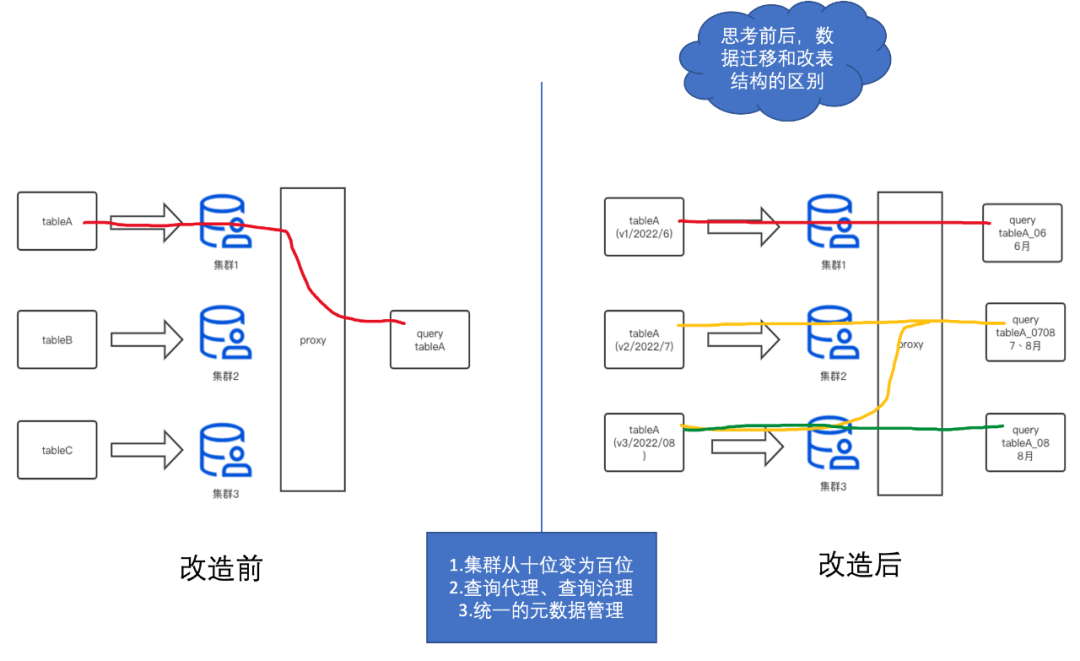
圖18
(1)資料跨如何跨集群
假設我們有三個資料集群1、2、3和三個表A、B、C(如圖18),在改造之前,我們單張表(如A)只能坐落在一個資料集群1中,這樣的設計方式,導致了當集群1磁盤滿了之后,我們沒有辦法快速地將表A資料搬遷到磁盤相對空閑的集群2中,我們只能用雙寫的方式將表A同時寫入到集群1和集群2中,等到集群2的資料經過了TTL時間(如7天)后,才能將表A從資料集群1中洗掉,這樣,對我們的集群運維管理帶來了極大的不方便和慢回應,非常耗費人力,
于是,我們設計一套類分庫分表的架構,來實作表A在多個集群1、2、3之間來回穿梭,我們可以看到右邊改造后,表A以時間節點作為分庫分表的切換點(這個時間可以是精確到秒,為了好理解,我們這里以月來舉例),我們將6月份的資料寫入到集群1、7月寫到集群2、8月寫到集群3,當查詢陳述句命中6月份資料時,我們只查詢集群1的資料;當查詢陳述句命中7月和8月的資料,我們就同時查詢集群2和集群3的資料,
我們通過建立不同分布式表的方式實作了這個能力(如:分布式表tableA_06/tableA_07/tableA_08/tableA_0708,分布式表上的邏輯集群則是是集群1、2、3的組合),這樣,我們便解決了表跨集群的問題,不同集群間的磁盤使用率也會趨于平衡,
(2)如何修改排序鍵不洗掉歷史資料
非常巧妙的是,這種方式不僅能解決磁盤問題,Clickhouse 分布式表的設計只關心列的名稱,并不關心本地資料表的排序鍵設定,基于這種特性,我們設計表A在集群2和集群3使用不一樣的排序鍵,這樣的方式也能夠有效解決初期表A在集群2排序鍵設計不合理的問題,我們通過在集群3上重新建立正確的排序鍵,讓其對新資料生效,同時,表A也保留了舊的7月份資料,舊資料會在時間的推移一下被TTL清除,最終資料都使用了正確的排序鍵,
(3)如何解決洗掉大表欄位導致元資料不一致
更美妙的是,Clickhouse 的分布式表設計并不要求表A在7月和8月的元資料欄位完全一致,只需要有公共部分就可以滿足要求,比如表A有在7月有11個欄位,8月份想要洗掉一個棄用的欄位,那么只需在集群3上建10個欄位的本地表A,而分布式表 tableA_0708 配置兩個表共同擁有的10個欄位即可(這樣查分布式表只要不查被洗掉的欄位就不會報錯),通過這種方式,我們也巧妙地解決了在資料規模特別大的情況下(單表百TB),洗掉欄位導致常見的元數據不一致問題,
(4)集群升級
同時,這種多版本集群的方式,也能方便地實作集群升級迭代,如直接新建一個集群4來存盤所有的09月的表資料,集群4可以是社區最新版本,通過這種迭代的方式逐步實作全部集群的升級,
4.3 元資料管理
為了實作上述的功能,我們需要維護好一套完整的元資料資訊,來管理表的創建、寫入和 DDL(如圖19),該元資料包含每個表的版本定義、每個版本資料的資料歸屬集群和時間范圍等,
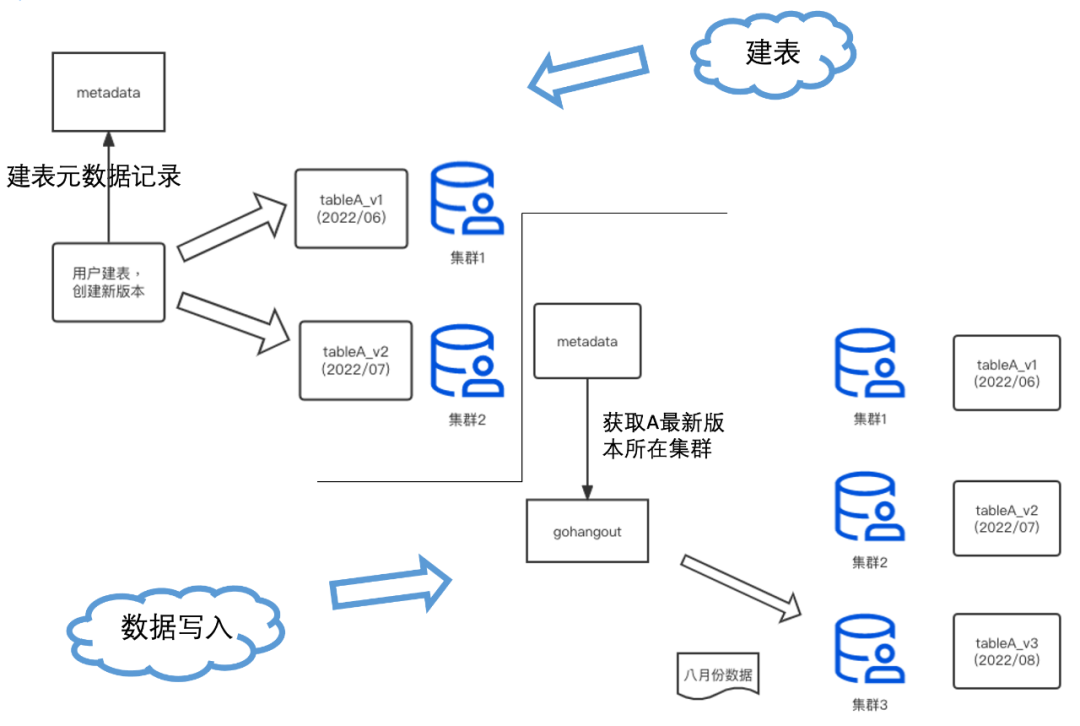
圖19
4.4 統一查詢治理層
(1)Antlr4 的 SQL 決議
在查詢層,我們基于 Antlr4 技術,將用戶的查詢 SQL 決議成 AST 樹,通過 AST 樹,我們能夠快速地獲得 SQL 的表名、過濾條件、聚合維度等(如圖20),我們拿到這些資訊后,能夠非常方便地對 SQL 實時針對性的策略,如:資料統計、優化改寫和治理限流等,
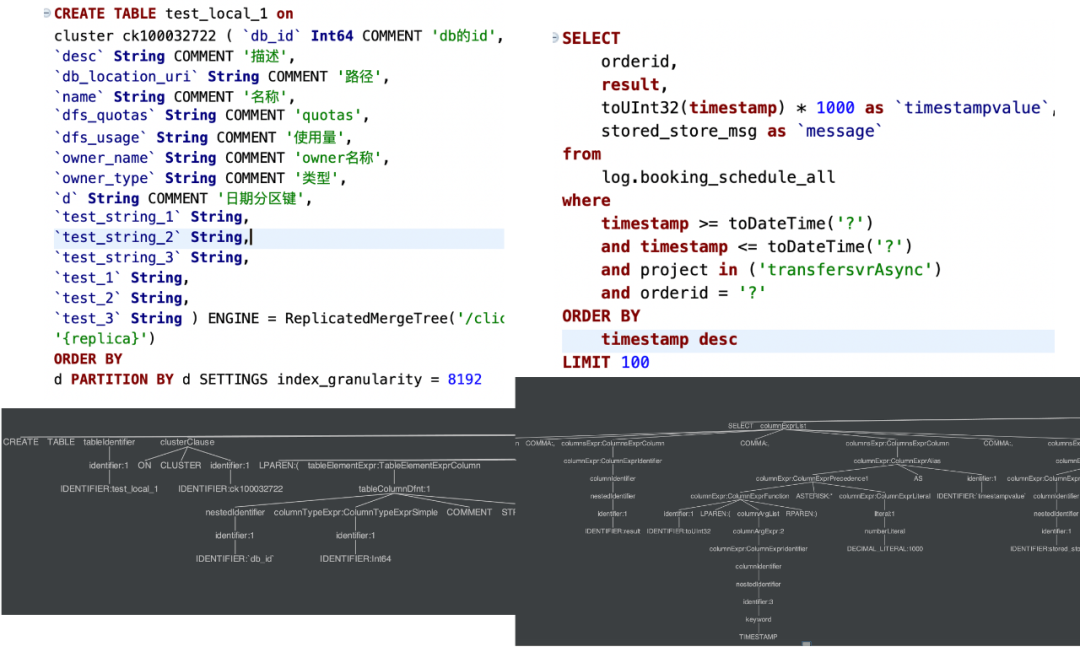
圖20
(2)查詢代理層
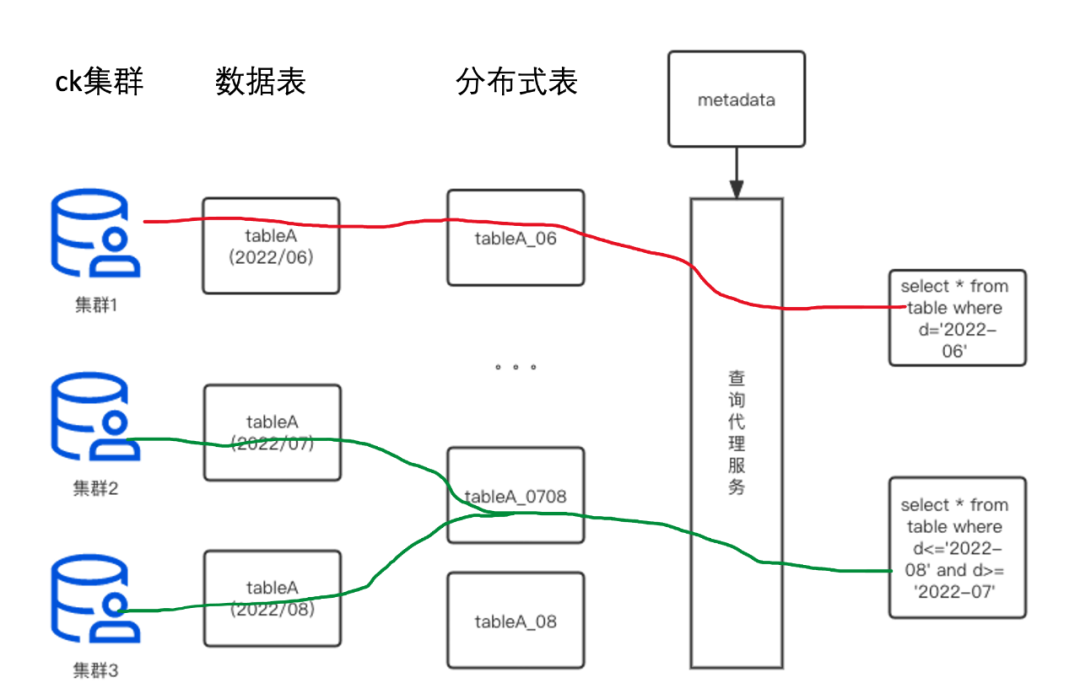
圖21
我們對所有用戶的SQL查詢做了一層統一的查詢網關代理(如圖21),該程式會根據元資料資訊和策略對用戶的 SQL 進行改寫,實作了精準路由和性能優化等功能,同時,該程式會記錄每次查詢的明細背景關系,用于對集群的查詢做統一化治理,如:QPS 限制、大表掃描限制和時間限制等拒絕策略,來提高系統的穩定性,
五、未來計劃
通過日志3.0的構建,我們重構了日志系統的整體架構,實作集群 Kubernetes 化管理,并成功地解決了歷史遺留的 DDL 例外、資料跨集群讀寫、索引重構優、磁盤治理和集群升級等運維難題,2022年,日志系統成果地支撐了公司 CLOG 與 UBT 業務的資料接入,集群資料規模達到了30+PB,
當然,攜程的日志系統演進也不會到此為止,我們的系統在功能、性能和治理多方面還有不少改善的空間,在未來,我們將進一步完善日志統一查詢治理層,精細化地管理集群查詢與負載;推出日志預聚合功能,對大資料量的查詢場景做加速,并支持 AI智能告警;充分地運用云上能力,實作彈性混合云,低成本支撐節假日高峰;推到日志產品在攜程系各個公司的使用覆寫等,讓我們一起期待下一次的日志升級,
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/The-evolution-of-Ctrip-10-year-log-system-governance.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/546256.html
標籤:大數據