為什么要分庫分表
- 用戶請求量太大
單服務器TPS、記憶體、IO都是有上限的,需要將請求打散分布到多個服務器 ,
- 單庫資料量太大
單個資料庫處理能力有限;單庫所在服務器的磁盤空間有限;單庫上的操作IO有瓶頸 ,
- 單表資料量太大
查詢、插入、更新操作都會變慢,在加欄位、加索引、機器遷移都會產生高負載,影響服務,
拆分方式
垂直拆分
- 垂直分庫
微服務架構時,業務切割得足夠獨立,資料也按照業務切分,不同業務的資料存入不同的庫中,
- 垂直分表
表中欄位太多且包含大欄位,可將這張大表拆分為多張表,
水平拆分
- 水平分庫
將單張表的資料切分到多個服務器上去,每個服務器具有相應的庫與表,只是表中資料集合不同,
- 水平分庫規則
不跨庫、不跨表,保證同一類的資料都在同一個服務器上面,
- 水平分表
針對資料量巨大的單張表(比如訂單表),按照規則把一張表的資料切分到多張表里面去,
- 水平分表規則
- RANGE
- 時間:按照年、月、日去切分,例如order_2022、order_202203、order_20220301
- 地域:按照省或市去切分,例如order_beijing、order_shanghai、order_chengdu
- 大小:從0到1000000一個表,例如1000001-2000000放一個表,每100萬放一個表
- HASH
- 用戶ID取模
- 站內信
- 用戶維度:用戶只能看到發送給自己的訊息,其他用戶是不可見的,這種情況下是按照
- 用戶ID hash分庫,在用戶查看歷史記錄翻頁查詢時,所有的查詢請求都在同一個庫內
- 用戶表
- 范圍法:以用戶ID為劃分依據,將資料水平切分到兩個資料庫實體,如:1到1000W在 一張表,1000W到2000W在一張表,這種情況會出現單表的負載較高
- 按照用戶ID HASH盡量保證用戶資料均衡分到資料庫中
...
面臨的問題
由于資料存盤在不同的庫和表中,也帶來了其他方面的一些問題,如下:
- ID主鍵怎么生成?
- 資料怎么保持一致?
- 資料庫怎么擴容?
- 業務層代碼怎么改造?
分頁排序、事務問題、跨表跨庫join問題等,
解決方案
主鍵選擇
- UUID:本地生成,不依賴資料庫,缺點就是作為主鍵性能太差
- SNOWFLAKE:雪花演算法
資料一致性
- 強一致性:XA協議
- 最終一致性:TCC、saga、Seata
資料庫擴容
- 成倍增加資料節點,實作平滑擴容
- 成倍擴容以后,表中的部分資料請求已被路由到其他節點上面,可以清理掉
業務層改造
- 基于代理層方式:Mycat、Sharding-Proxy、MySQL Proxy
- 基于應用層方式:Sharding-jdbc
跨庫跨表join問題
- 全域表(字典表):基礎資料/配置資料,所有庫都拷貝一份
- 欄位冗余:可以使用欄位冗余就不用join查詢了
- 系統層組裝:可以在業務層分別查詢出來,然后組裝起來,邏輯較復雜
中間件之ShardingSphere
簡介
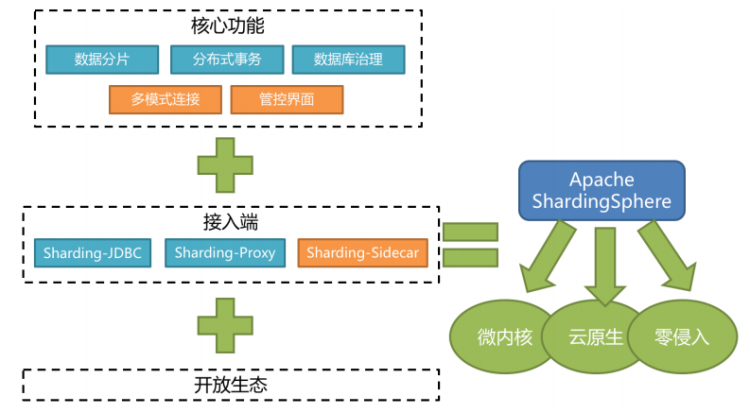
Apache ShardingSphere是一款開源的分布式資料庫中間件組成的生態圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(規劃中)這3款相互獨立的產品組成, 他們均提供標準化的資料分片、分布式事務和資料庫治理功能,可適用于如Java同構、異構語言、容器、云原生等各種多樣化的應用場景,
ShardingSphere定位為關系型資料庫中間件,旨在充分合理地在分布式的場景下利用關系型資料庫的計算和存盤能力,而并非實作一個全新的關系型資料庫,
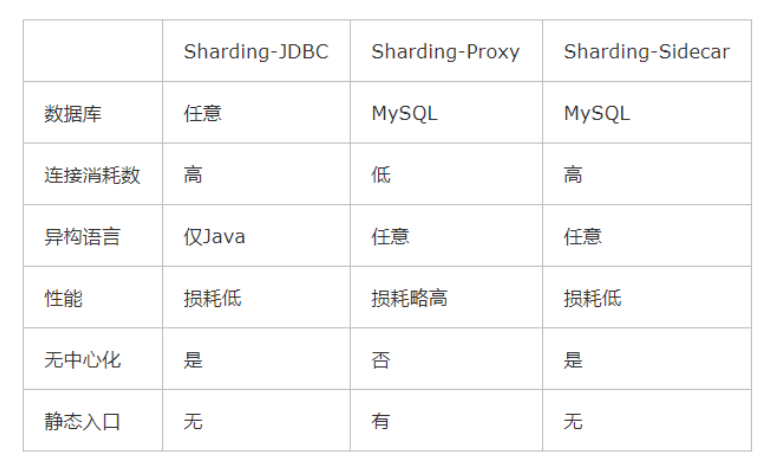
Sharding-JDBC:被定位為輕量級Java框架,在Java的JDBC層提供的額外服務,以jar包形式使用,
Sharding-Proxy:被定位為透明化的資料庫代理端,提供封裝了資料庫二進制協議的服務端版本,用于完成對異構語言的支持,
Sharding-Sidecar:被定位為Kubernetes或Mesos的云原生資料庫代理,以DaemonSet的形式代理所有對資料庫的訪問,
Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar三者區別如下:
Sharding-JDBC
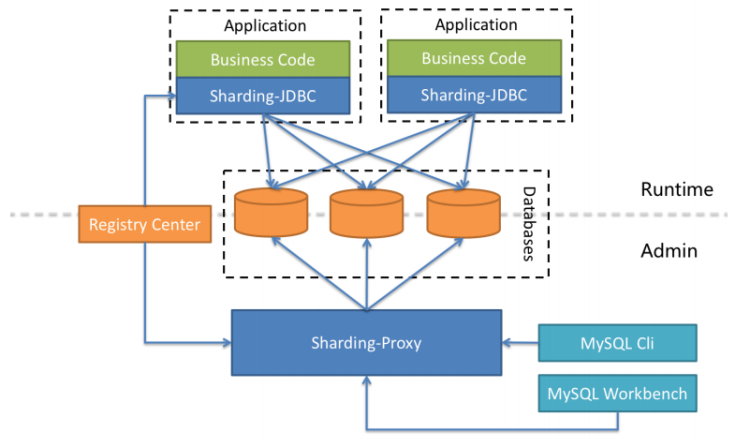
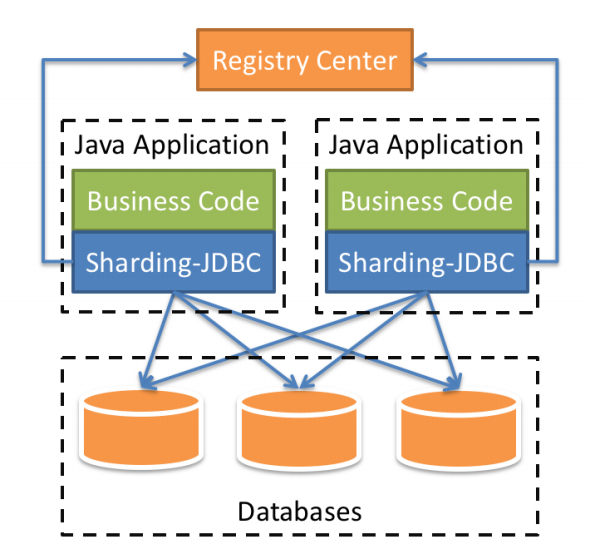
Sharding-JDBC定位為輕量級Java框架,在Java的JDBC層提供的額外服務, 它使用客戶端直連資料庫,以jar包形式提供服務,無需額外部署和依賴,可理解為增強版的JDBC驅動,完全兼容JDBC和各種ORM框架的用,
- 適用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC,
- 基于任何第三方的資料庫連接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等,
- 支持任意實作JDBC規范的資料庫,目前支持MySQL,Oracle,SQLServer和PostgreSQL,
Sharding-JDBC主要功能:
- 資料分片
- 分庫、分表
- 讀寫分離
- 分片策略
- 分布式主鍵
- 分布式事務
- 標準化的事務介面
- XA強一致性事務
- 柔性事務
- 資料庫治理
- 配置動態化
- 編排和治理
- 資料脫敏
- 可視化鏈路追蹤
Sharding-JDBC 使用程序
- 引入maven依賴
<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>${latest.release.version}</version> </dependency>
- 規則配置
Sharding-JDBC可以通過Java,YAML,Spring命名空間和Spring Boot Starter四種方式配置,開發者可根據場景選擇適合的配置方式,
- 創建DataSource
通過ShardingDataSourceFactory工廠和規則配置物件獲取ShardingDataSource,然后即可通過DataSource選擇使用原生JDBC開發,或者使用JPA, MyBatis等ORM工具,
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap,
shardingRuleConfig, props);
資料分片
核心概念
表概念
- 真實表
資料庫中真實存在的物理表,例如b_order0、b_order1
- 邏輯表
在分片之后,同一類表結構的名稱(總成),例如b_order,
- 資料節點
在分片之后,由資料源和資料表組成,例如ds0.b_order1
- 系結表
指的是分片規則一致的關系表(主表、子表),例如b_order和b_order_item,均按照order_id分片,則此兩個表互為系結表關系,系結表之間的多表關聯查詢不會出現笛卡爾積關聯,可以提升關聯查詢效率,
b_order:b_order0、b_order1 b_order_item:b_order_item0、b_order_item1 select * from b_order o join b_order_item i on(o.order_id=i.order_id) where o.order_id in (10,11);
如果不配置系結表關系,采用笛卡爾積關聯,會生成4個SQL
select * from b_order0 o join b_order_item0 i on(o.order_id=i.order_id) where o.order_id in (10,11); select * from b_order0 o join b_order_item1 i on(o.order_id=i.order_id) where o.order_id in (10,11); select * from b_order1 o join b_order_item0 i on(o.order_id=i.order_id) where o.order_id in (10,11); select * from b_order1 o join b_order_item1 i on(o.order_id=i.order_id) where o.order_id in (10,11);
如果配置系結表關系,生成2個SQL
select * from b_order0 o join b_order_item0 i on(o.order_id=i.order_id) where o.order_id in (10,11); select * from b_order1 o join b_order_item1 i on(o.order_id=i.order_id) where o.order_id in (10,11);
- 廣播表
在使用中,有些表沒必要做分片,例如字典表、省份資訊等,因為他們資料量不大,而且這種表可能需要與海量資料的表進行關聯查詢,廣播表會在不同的資料節點上進行存盤,存盤的表結構和資料完全相同,
- 邏輯索引
某些資料庫(如:PostgreSQL)不允許同一個庫存在名稱相同索引,某些資料庫(如:MySQL)則允許只要同一個表中不存在名稱相同的索引即可, 邏輯索參考于同一個庫不允許出現相同索引名稱的分表場景,需要將同庫不同表的索引名稱改寫為索引名 + 表名,改寫之前的索引名稱成為邏輯索引,
分片鍵
用于分片的資料庫欄位,是將資料庫(表)水平拆分的關鍵欄位,例:將訂單表中的訂單主鍵的尾數取模分片,則訂單主鍵為分片欄位, SQL中如果無分片欄位,將執行全路由,性能較差, 除了對單分片欄位的支持,ShardingSphere也支持根據多個欄位進行分片,
分片演算法(ShardingAlgorithm)
通過分片演算法將資料分片,支持通過=、BETWEEN和IN分片,
目前提供4種分片演算法,由于分片演算法和業務實作緊密相關,因此并未提供內置分片演算法,而是通過分片策略將各種場景提煉出來,提供更高層級的抽象,并提供介面讓應用開發者自行實作分片演算法,
- 精確分片演算法
對應PreciseShardingAlgorithm,用于處理使用單一鍵作為分片鍵的=與IN進行分片的場景,需要配合StandardShardingStrategy使用,
- 范圍分片演算法
對應RangeShardingAlgorithm,用于處理使用單一鍵作為分片鍵的BETWEEN AND進行分片的場景,需要配合StandardShardingStrategy使用,
- 復合分片演算法
對應ComplexKeysShardingAlgorithm,用于處理使用多鍵作為分片鍵進行分片的場景,包含多個分片鍵的邏輯較復雜,需要應用開發者自行處理其中的復雜度,需要配合ComplexShardingStrategy使用,
- Hint分片演算法
對應HintShardingAlgorithm,用于處理使用Hint行分片的場景,需要配合HintShardingStrategy使用,
分片策略
包含分片鍵和分片演算法,由于分片演算法的獨立性,將其獨立抽離,真正可用于分片操作的是分片鍵 + 分片演算法,也就是分片策略,目前提供5種分片策略,
- 標準分片策略
對應StandardShardingStrategy,提供對SQL陳述句中的=, IN和BETWEEN AND的分片操作支持,StandardShardingStrategy只支持單分片鍵,提供PreciseShardingAlgorithm和RangeShardingAlgorithm兩個分片演算法,PreciseShardingAlgorithm是必選的,用于處理=和IN的分片,RangeShardingAlgorithm是可選的,用于處理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND將按照全庫路由處理,
- 復合分片策略
對應ComplexShardingStrategy,復合分片策略,提供對SQL陳述句中的=, IN和BETWEEN AND的分片操作支持,ComplexShardingStrategy支持多分片鍵,由于多分片鍵之間的關系復雜,因此并未進行過多的封裝,而是直接將分片鍵值組合以及分片運算子透傳至分片演算法,完全由應用開發者實作,提供最大的靈活度,
- 行運算式分片策略
對應InlineShardingStrategy,使用Groovy的運算式,提供對SQL陳述句中的=和IN的分片操作支持,只支持單分片鍵,對于簡單的分片演算法,可以通過簡單的配置使用,從而避免繁瑣的Java代碼開發,如: t_user_$->{u_id % 8} 表示t_user表根據u_id模8,而分成8張表,表名稱為t_user_0到t_user_7,
- Hint分片策略
對應HintShardingStrategy,通過Hint而非SQL決議的方式分片的策略,
- 不分片策略
對應NoneShardingStrategy,不分片的策略,
分片策略配置
對于分片策略存有資料源分片策略和表分片策略兩種維度,兩種策略的API完全相同,
- 資料源分片策略
用于配置資料被分配的目標資料源,
- 表分片策略
用于配置資料被分配的目標表,由于表存在與資料源內,所以表分片策略是依賴資料源分片策略結果的,
流程剖析
ShardingSphere的3個產品的資料分片主要流程是完全一致的, 核心由SQL決議 => 執行器優化 => SQL路由 => SQL改寫 => SQL執行 => 結果歸并的流程組成,
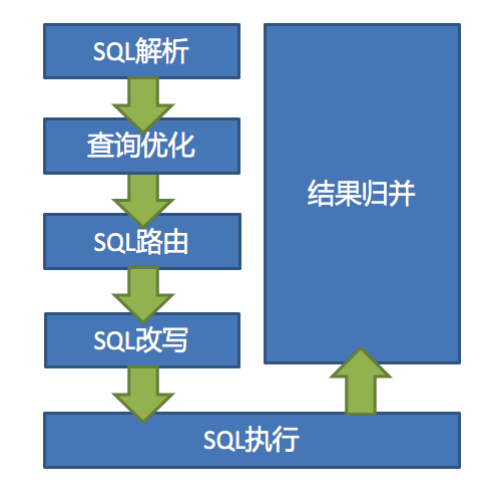
- SQL決議
分為詞法決議和語法決議, 先通過詞法決議器將SQL拆分為一個個不可再分的單詞,再使用語法決議器對SQL進行理解,并最終提煉出決議背景關系, 決議背景關系包括表、選擇項、排序項、分組項、聚合函式、分頁資訊、查詢條件以及可能需要修改的占位符的標記,
- 執行器優化
合并和優化分片條件,如OR等,
- SQL路由
根據決議背景關系匹配用戶配置的分片策略,并生成路由路徑,目前支持分片路由和廣播路由,
- SQL改寫
將SQL改寫為在真實資料庫中可以正確執行的陳述句,SQL改寫分為正確性改寫和優化改寫,
- SQL執行
通過多執行緒執行器異步執行,
- 結果歸并
將多個執行結果集歸并以便于通過統一的JDBC介面輸出,結果歸并包括流式歸并、記憶體歸并和使用裝飾者模式的追加歸并這幾種方式,
SQL使用規范
支持項
路由至單資料節點時,目前MySQL資料庫100%全兼容,其他資料庫完善中,
路由至多資料節點時,全面支持DQL、DML、DDL、DCL、TCL,支持分頁、去重、排序、分組、聚合、關聯查詢(不支持跨庫關聯),
- SELECT主陳述句
SELECT select_expr [, select_expr ...] FROM table_reference [, table_reference ...] [WHERE where_condition] [GROUP BY {col_name | position} [ASC | DESC]] [ORDER BY {col_name | position} [ASC | DESC], ...] [LIMIT {[offset,] row_count | row_count OFFSET offset}]
- select_expr
* | [DISTINCT] COLUMN_NAME [AS] [alias] | (MAX | MIN | SUM | AVG)(COLUMN_NAME | alias) [AS] [alias] | COUNT(* | COLUMN_NAME | alias) [AS] [alias]
- table_reference
tbl_name [AS] alias] [index_hint_list] | table_reference ([INNER] | {LEFT|RIGHT} [OUTER]) JOIN table_factor [JOIN ON conditional_expr | USING (column_list)] |
不支持項
不支持CASE WHEN、HAVING、UNION (ALL)
- 支持分頁子查詢,但其他子查詢有限支持,無論嵌套多少層,只能決議至第一個包含資料表的子查詢,一旦在下層嵌套中再次找到包含資料表的子查詢將直接拋出決議例外,
例如,以下子查詢可以支持:
SELECT COUNT(*) FROM (SELECT * FROM b_order o)
以下子查詢不支持:
SELECT COUNT(*) FROM (SELECT * FROM b_order o WHERE o.id IN (SELECT id FROM b_order WHERE status = ?))
簡單來說,通過子查詢進行非功能需求,在大部分情況下是可以支持的,比如分頁、統計總數等;而通過子查詢實作業務查詢當前并不能支持,
- 由于歸并的限制,子查詢中包含聚合函式目前無法支持,
- 不支持包含schema的SQL,因為ShardingSphere的理念是像使用一個資料源一樣使用多數據源,因此對SQL的訪問都是在同一個邏輯schema之上,
- 當分片鍵處于運算運算式或函式中的SQL時,將采用全路由的形式獲取結果,
例如下面SQL,create_time為分片鍵:
SELECT * FROM b_order WHERE to_date(create_time, 'yyyy-mm-dd') = '2020-05-05';
由于ShardingSphere只能通過SQL字面提取用于分片的值,因此當分片鍵處于運算運算式或函式中時,ShardingSphere無法提前獲取分片鍵位于資料庫中的值,從而無法計算出真正的分片值,
分頁查詢
完全支持MySQL和Oracle的分頁查詢,SQLServer由于分頁查詢較為復雜,區域分支持.
- 性能瓶頸
查詢偏移量過大的分頁會導致資料庫獲取資料性能低下,以MySQL為例:
SELECT * FROM b_order ORDER BY id LIMIT 1000000, 10
這句SQL會使得MySQL在無法利用索引的情況下跳過1000000條記錄后,再獲取10條記錄,其性能可想而知, 而在分庫分表的情況下(假設分為2個庫),為了保證資料的正確性,SQL會改寫為:
SELECT * FROM b_order ORDER BY id LIMIT 0, 1000010
即將偏移量前的記錄全部取出,并僅獲取排序后的最后10條記錄,這會在資料庫本身就執行很慢的情況下,進一步加劇性能瓶頸, 因為原SQL僅需要傳輸10條記錄至客戶端,而改寫之后的SQL則會傳輸1,000,010 * 2的記錄至客戶端,
- ShardingSphere的優化
ShardingSphere進行了以下2個方面的優化,
- 首先,采用流式處理 + 歸并排序的方式來避免記憶體的過量占用,
- 其次,ShardingSphere對僅落至單節點的查詢進行進一步優化,
- 分頁方案優化
由于LIMIT并不能通過索引查詢資料,因此如果可以保證ID的連續性,通過ID進行分頁是比較好的解決方案:
SELECT * FROM b_order WHERE id > 1000000 AND id <= 1000010 ORDER BY id
或通過記錄上次查詢結果的最后一條記錄的ID進行下一頁的查詢
SELECT * FROM b_order WHERE id > 1000000 LIMIT 10
其它功能
- Inline行運算式
InlineShardingStrategy:采用Inline行運算式進行分片的配置,
Inline是可以簡化資料節點和分片演算法配置資訊,主要是解決配置簡化、配置一體化,
- 語法格式
行運算式的使用非常直觀,只需要在配置中使用${ expression }或$->{ expression }標識行運算式即可,例如:
${begin..end} 表示范圍區間
${[unit1, unit2, unit_x]} 表示列舉值
行運算式中如果出現多個${}或$->{}運算式,整個運算式結果會將每個子運算式結果進行笛卡爾(積)組合,例如,以下行運算式:
${['online', 'offline']}_table${1..3}
$->{['online', 'offline']}_table$->{1..3}
最侄訓決議為:
online_table1, online_table2, online_table3,
offline_table1, offline_table2, offline_table3
- 資料節點配置
對于均勻分布的資料節點,如果資料結構如下:
db0
├── b_order2
└── b_order1
db1
├── b_order2
└── b_order1
用行運算式可以簡化為:
db${0..1}.b_order${1..2}
或者
db$->{0..1}.b_order$->{1..2}
對于自定義的資料節點,如果資料結構如下:
db0
├── b_order0
└── b_order1
db1
├── b_order2
├── b_order3
└── b_order4
用行運算式可以簡化為:
db0.b_order${0..1},db1.b_order${2..4}
- 分片演算法配置
行運算式內部的運算式本質上是一段Groovy代碼,可以根據分片鍵進行計算的方式,回傳相應的
真實資料源或真實表名稱,
ds${id % 10}
或者
ds$->{id % 10}
結果為:ds0、ds1、ds2... ds9
- 分布式主鍵
ShardingSphere不僅提供了內置的分布式主鍵生成器,例如UUID、SNOWFLAKE,還抽離出分布式主鍵生成器的介面,方便用戶自行實作自定義的自增主鍵生成器,
- 內置主鍵生成器
- UUID :采用UUID.randomUUID()的方式產生分布式主鍵,
- SNOWFLAKE :在分片規則配置模塊可配置每個表的主鍵生成策略,默認使用雪花演算法,生成64bit的長整型 資料,
- 自定義主鍵生成器
- 自定義主鍵類,實作ShardingKeyGenerator介面
- 按SPI規范配置自定義主鍵類
在Apache ShardingSphere中,很多功能實作類的加載方式是通過SPI注入的方式完成的,
注意:在resources目錄下新建META-INF檔案夾,再新建services檔案夾,然后新建檔案的名字為org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator,打開檔案,復制自定義主鍵類全路徑到檔案中保存,
- 自定義主鍵類應用配置
#對應主鍵欄位名
spring.shardingsphere.sharding.tables.t_book.key-generator.column=id
#對應主鍵類getType回傳內容
spring.shardingsphere.sharding.tables.t_book.key-generator.type=LAGOUKEY
讀寫分離
讀寫分離是通過主從的配置方式,將查詢請求均勻的分散到多個資料副本,進一步的提升系統的處理能力,
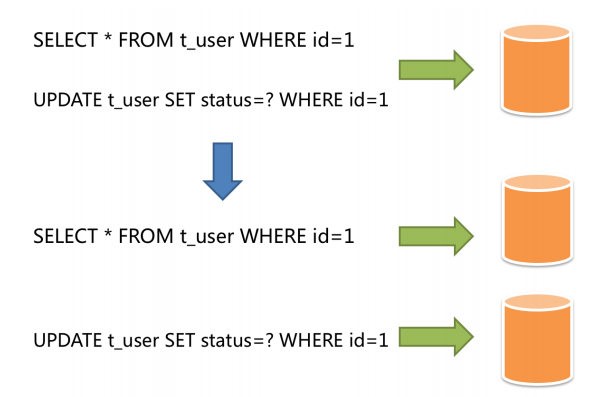
- 主從架構:讀寫分離,目的是高可用、讀寫擴展,主從庫內容相同,根據SQL語意進行路由,
- 分庫分表架構:資料分片,目的讀寫擴展、存盤擴容,庫和表內容不同,根據分片配置進行路由,
將水平分片和讀寫分離聯合使用,能夠更加有效的提升系統性能,
下圖展現了將分庫分表與讀寫分離一同使用時,應用程式與資料庫集群之間的復雜拓撲關系,
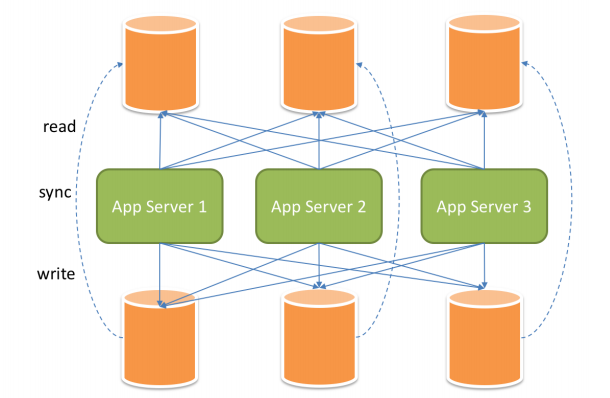
讀寫分離雖然可以提升系統的吞吐量和可用性,但同時也帶來了資料不一致的問題,包括多個主庫之間 的資料一致性,以及主庫與從庫之間的資料一致性的問題, 并且,讀寫分離也帶來了與資料分片同樣的 問題,它同樣會使得應用開發和運維人員對資料庫的操作和運維變得更加復雜,
讀寫分離應用方案
在資料量不是很多的情況下,我們可以將資料庫進行讀寫分離,以應對高并發的需求,通過水平擴展從 庫,來緩解查詢的壓力,如下:
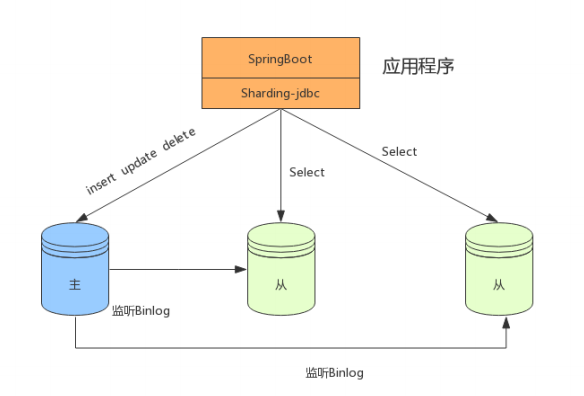
分表+讀寫分離
在資料量達到500萬的時候,這時資料量預估千萬級別,我們可以將資料進行分表存盤,
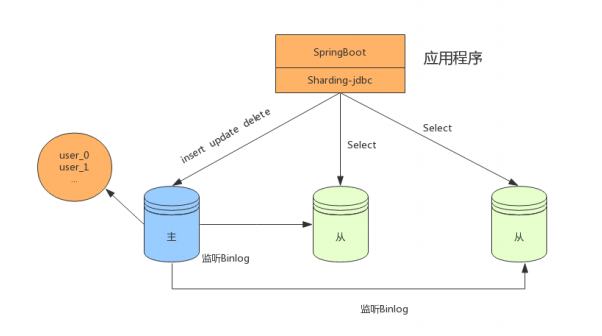
分庫分表+讀寫分離
在資料量繼續擴大,這時可以考慮分庫分表,將資料存盤在不同資料庫的不同表中,如下:
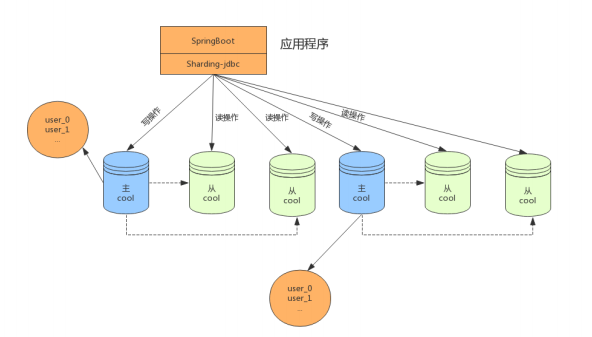
透明化讀寫分離所帶來的影響,讓使用方盡量像使用一個資料庫一樣使用主從資料庫集群,是ShardingSphere讀寫分離模塊的主要設計目標,
主庫、從庫、主從同步、負載均衡
核心功能
- 提供一主多從的讀寫分離配置,僅支持單主庫,可以支持獨立使用,也可以配合分庫分表使用獨立使用讀寫分離,支持SQL透傳,不需要SQL改寫流程
- 同一執行緒且同一資料庫連接內,能保證資料一致性,如果有寫入操作,后續的讀操作均從主庫讀取,
- 基于Hint的強制主庫路由,可以強制路由走主庫查詢實時資料,避免主從同步資料延遲,
不支持項
- 主庫和從庫的資料同步
- 主庫和從庫的資料同步延遲
- 主庫雙寫或多寫
- 跨主庫和從庫之間的事務的資料不一致,建議在主從架構中,事務中的讀寫均用主庫操作,
主從復制原理
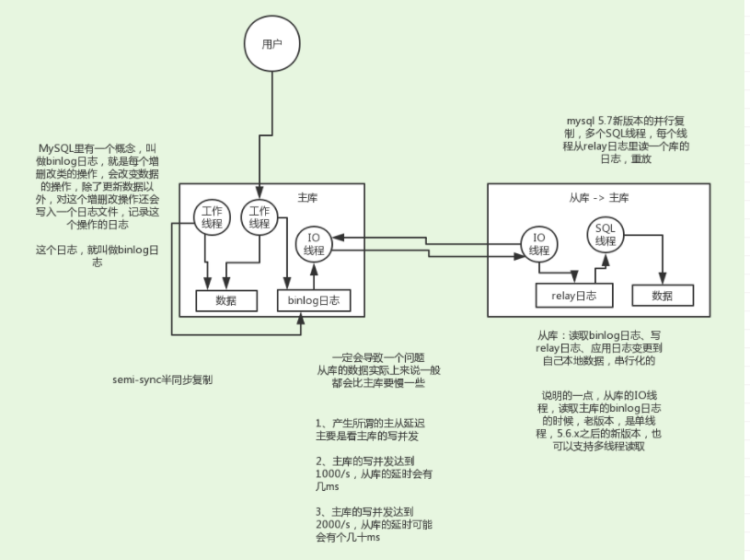
MySQL里有一個概念,叫binlog日志,就是每個增刪改類的操作,會改變資料的操作,除了更新資料以外,對這個增刪改操作還會寫入一個日志檔案,記錄這個操作的日志,
主庫將變更寫binlog日志,然后從庫連接到主庫之后,從庫有一個IO執行緒,將主庫的binlog日志拷貝到自己本地,寫入一個中繼日志中,接著從庫中有一個SQL執行緒會從中繼日志讀取binlog,然后執行binlog日志中的內容,也就是在自己本地再次執行一遍SQL,這樣就可以保證自己跟主庫的資料是一樣的,
這里有一個非常重要的一點,就是從庫同步主庫資料的程序是串行化的,也就是說主庫上并行的操作,在從庫上會串行執行,所以這就是一個非常重要的點了,由于從庫從主庫拷貝日志以及串行執行SQL的特點,在高并發場景下,從庫的資料一定會比主庫慢一些,是有延時的,所以經常出現,剛寫入主庫的資料可能是讀不到的,要過幾十毫秒,甚至幾百毫秒才能讀取到,
而且這里還有另外一個問題,就是如果主庫突然宕機,然后恰好資料還沒同步到從庫,那么有些資料可能在從庫上是沒有的,有些資料可能就丟失了,
所以mysql實際上在這一塊有兩個機制,一個是半同步復制,用來解決主庫資料丟失問題;一個是并行復制,用來解決主從同步延時問題,
這個所謂半同步復制,semi-sync復制,指的就是主庫寫入binlog日志之后,就會將強制此時立即將資料同步到從庫,從庫將日志寫入自己本地的relay log之后,接著會回傳一個ack給主庫,主庫接收到至少一個從庫的ack之后才會認為寫操作完成了,
所謂并行復制,指的是從庫開啟多個執行緒,并行讀取relay log中不同庫的日志,然后并行重放不同庫的日志,這是庫級別的并行,
官方檔案地址:https://shardingsphere.apache.org/document/legacy/3.x/document/cn/overview/
作者:donleo123 出處:https://www.cnblogs.com/donleo123/ 本文如對您有幫助,還請多推薦下此文,如有錯誤歡迎指正,相互學習,共同進步,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/549469.html
標籤:其他