摘要:本文主要通過實體講解如何通過gs_cpuwatcher.sh 腳本尋找CPU占用高陳述句,
本文分享自華為云社區《GaussDB(DWS) gs_cpuwatcher.sh 腳本如何尋找CPU占用高陳述句》,作者:fighttingman,
【工具名稱】
gs_cpuwatcher
【功能描述】
1.尋找集群內節點占用CPU高的陳述句
【使用場景】
- CPU sys使用率高
- 業務整體慢
【引數說明】
無
【使用方法】
- 直接后臺執行命令
nohup sh gs_cpuwatcher.sh > cpuwatcher.log 2>&1 &
執行之前注意事項:
- 使用omm用戶(線下)或者Ruby用戶(線上)執行
- 將腳本放到一個磁盤空間充足的目錄執行,防止把磁盤空間占滿,腳本監控會產生日志,占用磁盤空間,磁盤空間最好大于20G
- 監控完之后kill這個監控行程,防止忘記這個腳本造成監控日志一直上漲,腳本默認保留3天的日志
- 腳本只有在行程的cpu使用率大于100(多核累加和)的時候才會進行查詢cpu高的陳述句
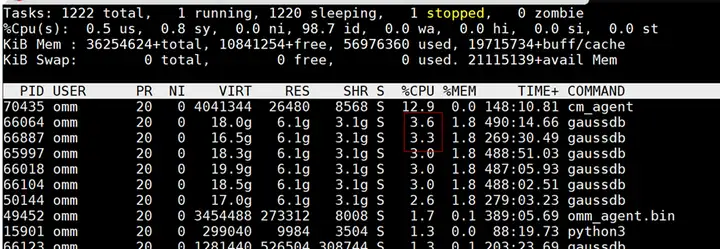
【最佳實踐&結果分析】
執行監控命令之后,檢查當前目錄生成的監控日志

查看日志cpu_watch_xxx.log日志,里邊有記錄占用CPU高的陳述句
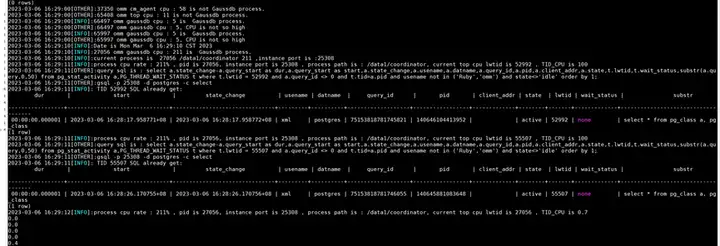
日志里邊記錄了cpu占用高的陳述句,例如上圖中select * from pg_class a, pg_class,腳本默認截取sql的前50個字符,可以對截取字串進行修改,需要修改腳本

欄位解釋:
- dur :執行時長
- start:sql的起始時間
- state_change:sql狀態改變時間
- usename:用戶名稱
- datname:連的資料庫名稱
- query_id:sql的唯一標識id
- pid:執行緒id
- client_addr:客戶端連的ip
- state:sql的執行狀態
- lwtid:執行緒小號
- wait_status:等待視圖中的等待狀態欄位
- substr:sql欄位
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/549470.html
標籤:其他
下一篇:hadoop學習記錄