
資料開發基本都是從陌生到熟悉,但是寫多了就會發現各種好用的工具/函式,也會發現各種坑,本文分享了作者從拿到資料到資料開發到資料監控的一些實操經驗,寫在前面
各種join的用法篇
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
read zhule_b;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-- better way to perform join, select small range of data first.
SELECT A.*, B.*
FROM
(SELECT * FROM A WHERE ds='20180101') A
JOIN
(SELECT * FROM B WHERE ds='20180101') B
ON a.key = b.key;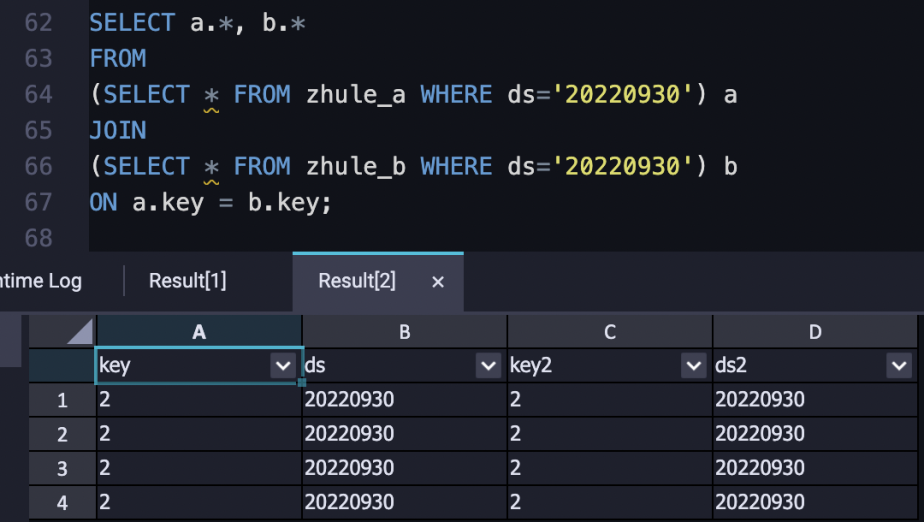
-
The left table in a LEFT OUTER JOIN operation must be a large table.
-
The right table in a RIGHT OUTER JOIN operation must be a large table.
-
MAPJOIN cannot be used in a FULL OUTER JOIN operation.
-
The left or right table in an INNER JOIN operation can be a large table.
SELECT /*+ MAPJOIN(b) */
a.*
FROM test_a a
JOIN test_b b
ON a.user_key = b.user_key
;
//就是在sql陳述句前加一個標記說這是mapjoin,把小表別名寫在括號里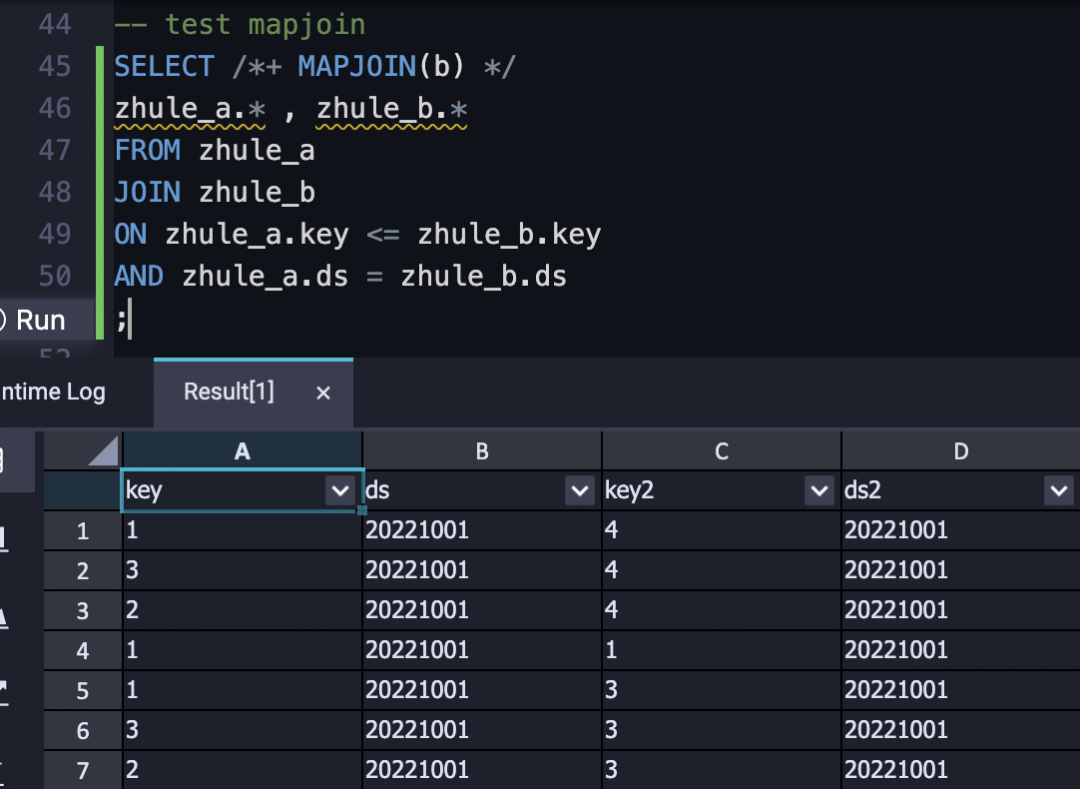
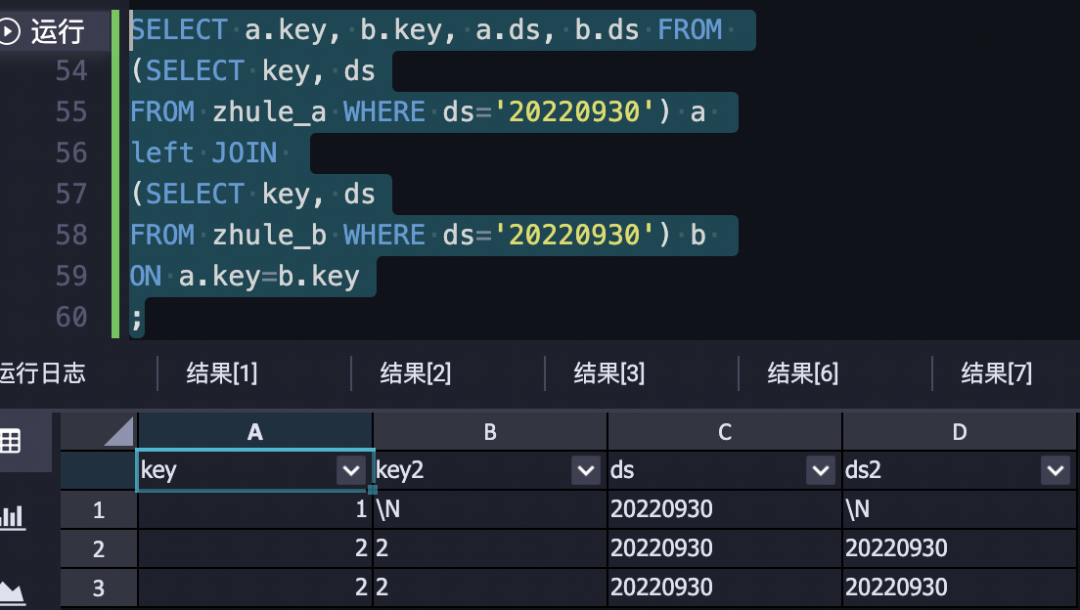
Left Join
-
一定要保留左表的內容是,可以選擇用left join,例如加入key_attrs
-
Right Join和Left Join沒有本質區別,建議定義好左表后都利用Left Join來執行
-
如果右表有重復資料的情況,那么最終left join的結果會有重復
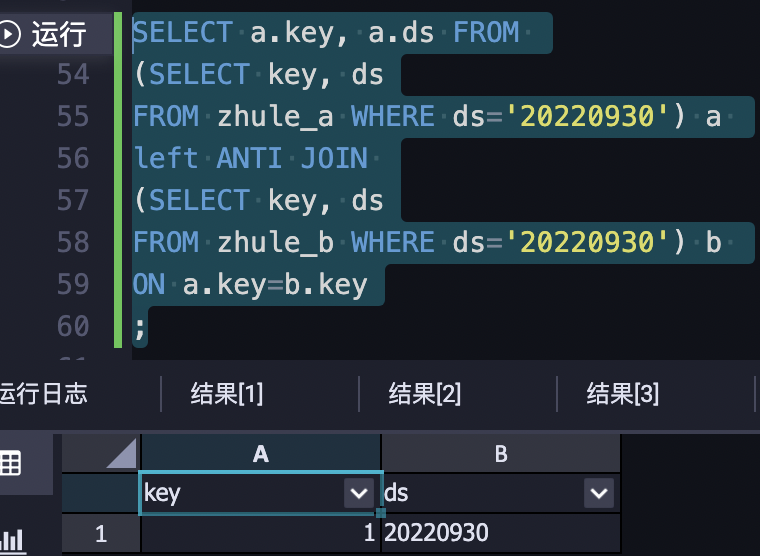
Left Semi Join
-
當右表沒有重復資料時,和Join是一致的,只會保留相同的列下來
-
left semi join并不會回傳右表B中的任何資料,所以你沒法在where條件中指定關于右表B的任何篩選條件,下面得例子能夠有更加清晰的對比(例子參考于開源論壇):
employee (2 columns - e_id and e_name)
10, Tom
20, Jerry
30, Emily
employee_department_mapping (2 columns - e_id and d_name)
10, IT
10, Sales
20, HR
-- inner join results
SELECT e.e_id, e.e_name, d.d_name FROM
employee e INNER JOIN employee_department_mapping d
on e.e_id = d.e_id
-- results
10, Tom, IT
10, Tom, Sales
20, Jerry, HR
-- left semi join results
SELECT e.e_id, e.e_name, d.d_name FROM
employee e LEFT SEMI JOIN employee_department_mapping d
on e.e_id = d.e_id
-- results
10, Tom, IT
20, Jerry, HR
-
最好用的場景就是找出兩表的差異部分;
-
演算法日常調度時可以用于每日新增修改商品的提取,將關鍵欄位放到ON條件中就行
Full Join
-
在有增刪改情況下更新下游最新資料時,非常好用,但是知道的人比較少
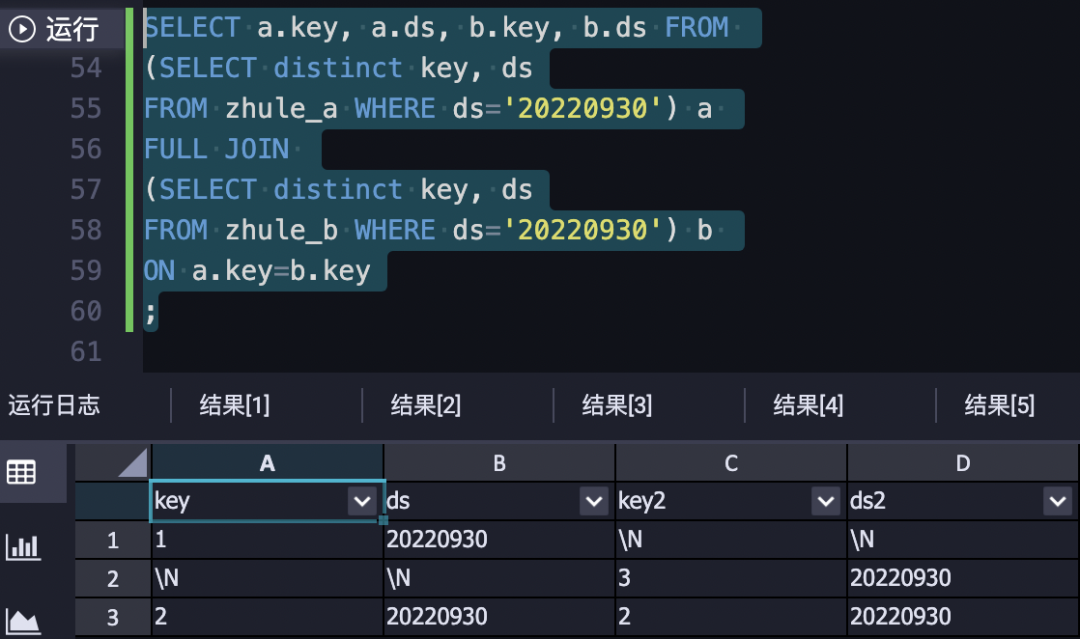
SELECT COALESCE(a.main_image_url,b.main_image_url) AS main_image_url
,COALESCE(a.embedding,b.embedding) AS embedding
FROM today_feat a
FULL JOIN yest_feat b
ON a.main_image_url = b.main_image_url其中full jion的效果如下,正好滿足new,old,updated feature的更新,配合COALESCE很絲滑:
合理設定Mapper和Reducepriority
set odps.instance.priority
set odps.sql.mapper.split.size
-- original sql
CREATE TABLE if not EXISTS tmp_zhl_test LIFECYCLE 1 AS
SELECT sig, venture, seller_id, COUNT(product_id) as cnt
FROM sku_main_image_sig
WHERE LENGTH(sig) > 10 --some bad cases may have weird sigs like '#NEXT#'
GROUP BY sig, venture, seller_id
HAVING cnt>2
;
set odps.sql.reducer.instances
set odps.sql.mapper(reducer).memory
在Python UDF中使用第三方庫
Upload&Call Package
-
需要下載第三方庫的安裝包xxx.whl,可以直接下載到自己的電腦上面,這樣可以在離線環境驗證多個版本的一致性(下面介紹),一般來說我們需要去看安裝包需要的python版本號以及兼容機器環境,一般來說都是cp37-cp37m or py2.py3-none-any在中間,然后末尾是x86_64的安裝包;
-
本地直接將xxx.whl轉換為xxx.zip,利用命令「mv xxx.whl xxx.zip」就行
-
將zip資源檔案上傳到ODPS對應的環境
-
在你的UDF中,利用下面的代碼指定資源包的路徑和參考(直接copy就行)
def include_package_path(res_name, lib_name):
archive_files = get_cache_archive(res_name)
dir_names = sorted([os.path.dirname(os.path.normpath(f.name)) for f in archive_files
if '.dist_info' not in f.name], key=lambda v: len(v))
for dir_name in dir_names:
if dir_name.endswith(lib_name):
sys.path.insert(0, os.path.dirname(dir_name))
break
elif os.path.exists(os.path.join(dir_name, lib_name + '.py')):
sys.path.insert(0, os.path.abspath(dir_name))
break
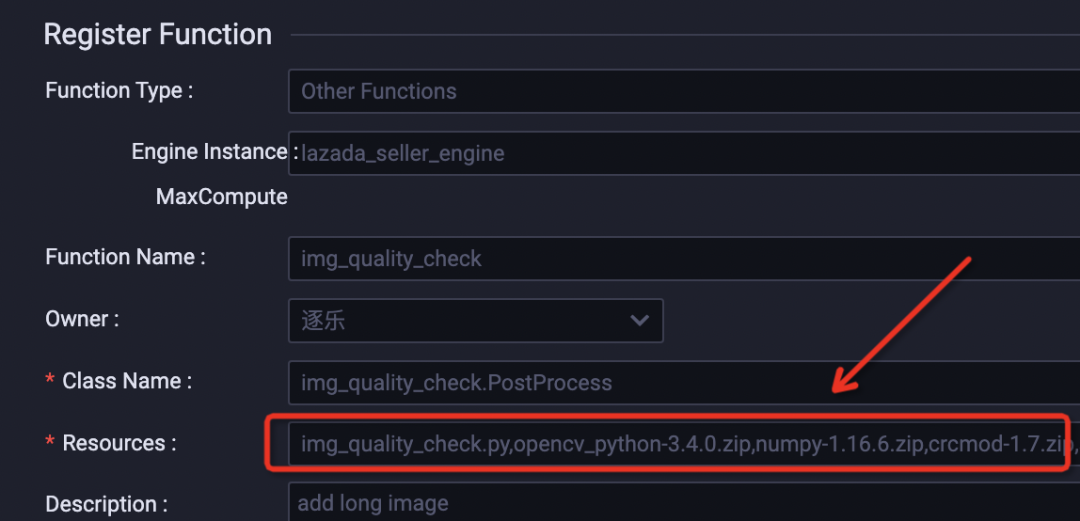
class PostProcess(BaseUDTF):
def __init__(self):
include_package_path('opencv_python-3.4.0.zip','cv2')
include_package_path('numpy-1.16.6.zip','numpy')-
python UDF寫完后,就可以在創建函式里面的Resources里直接將你的資源名寫進去,這樣在流程啟動后,你的資源才會被有效呼叫起來,
-
python UDF默認的版本是2.x的,如果你的python版本是3.x,那么需要在ODPS運行前加入下面的指令;同時,部分功能是需要打開沙箱的,所以如果報錯的話,可以加入第二行的沙箱命令,
set odps.sql.python.version = cp37; --use python 3.7, default is 2.x version
set odps.isolation.session.enable = true;
Solve Compatibility Issue
-
在本地可以用類似conda的工具搭建一個虛擬環境
-
在本地用pip或者conda install來安裝你需要的三方庫
-
查詢你下載的三方庫以及依賴庫的版本,比如python-opencv的話可以列印cv2.__version__
-
把對應版本的xxx.whl包按照上面的方法現在下來并且上傳到ODPS資源中進行依賴
發布任務時的一些額外建議
-
發布任務配置時,可以靈活使用exclude和extra來去掉或添加你想要的依賴,其中exclude可以去掉你中間產出的臨時表,而extra可以幫你增加雖然不在代碼里但是希望依賴的上游表(這在匯總不同上游表資料寫入下游對應磁區并且希望同時產出下游資料時很有用),
--exclude input or output tables (especially those tmp tables)--@exclude_input=lsiqg_iqc_sku_product_detection_result--@exclude_output=lsmp_sku_image_url_bizdate
-- include input or output tables (especially those separate venture tables)--@extra_input=lsiqg_iqc_sku_product_detection_result--@extra_output=lsmp_sku_image_url_bizdate-
如果在SQL代碼程序中你需要使用臨時表來過渡中間產出的資料(避免SQL嵌套過于嚴重,影響運行效率),建議一定在臨時表中加入一個時間戳,ex. lsiqg_iqc_input_tmp_${bizdate}不然在補資料或者遇到任務堵塞兩個任務同時在調度時,或產生overwrite的一系列問題, -
如果存在上游表存在多個磁區,但是每個磁區處理邏輯一樣的話(比如不同國家的磁區表處理邏輯其實一樣),非常建議在第一步里就把不同磁區表的資料匯總起來,可以重新增加一個磁區(如venture)來存放融合后的資料,如下示例:
INSERT OVERWRITE TABLE sku_main_image_sig PARTITION (ds = '${bizdate}',venture)
SELECT id
,image_url
,venture
FROM (
SELECT id
,image_url
,'ID' AS venture
FROM auction_image_id
WHERE ds = MAX_PT('auction_image_id')
UNION
SELECT id
,image_url
,'PH' AS venture
FROM auction_image_ph
WHERE ds = MAX_PT('auction_image_ph')
UNION
SELECT id
,image_url
,'VN' AS venture
FROM auction_image_vn
WHERE ds = MAX_PT('auction_image_vn')
UNION
SELECT id
,image_url
,'SG' AS venture
FROM auction_image_sg
WHERE ds = MAX_PT('auction_image_sg')
UNION
SELECT id
,image_url
,'MY' AS venture
FROM auction_image_my
WHERE ds = MAX_PT('auction_image_my')
UNION
SELECT id
,image_url
,'TH' AS venture
FROM auction_image_th
WHERE ds = MAX_PT('auction_image_th')
) union_table
;-
對于重要的資料表,一定要設定監控,防止資料丟失、不正常產出等問題,具體的方法又可以分兩類:
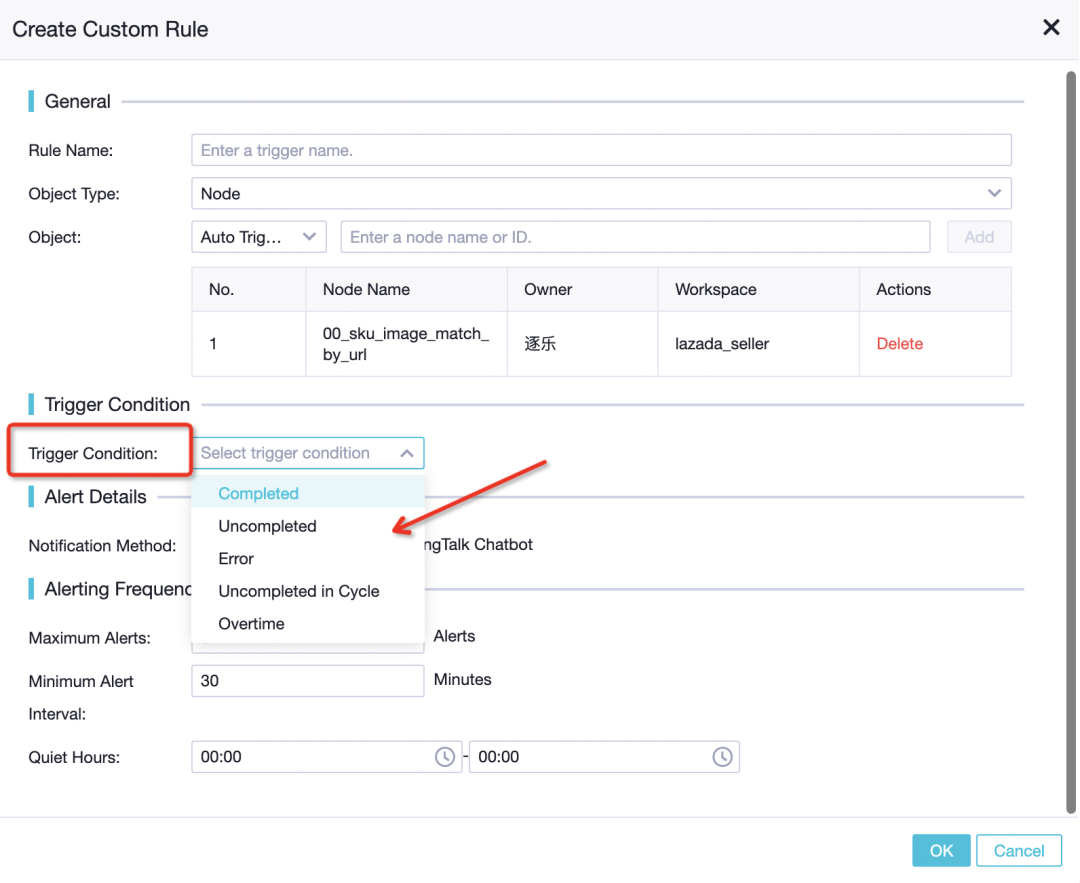
-
設定任務基線(baseline)來保證任務優先級,這樣調度的時間更有保障
-
設定warning的短信/電話或者DQC的監控規則來具體監控資料
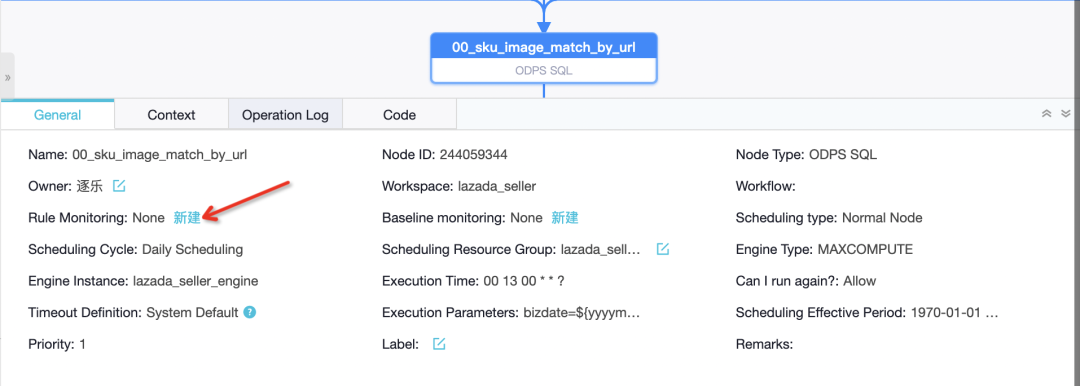
簡單的任務可以直接在任務中心查看詳情中設定:
寫在最后
-
拿到資料第一時間驗證資料的重復性,有效性;如果是組內問題就反饋,上游鏈路問題就自己過濾;
-
寫完資料的每一部分都先驗證合理性,這樣會提高最終資料的成功率;
-
一般節點上線后,會主動去觀察3-4天,確保輸出是符合預期的(如果會發現應該穩定的資料反而猛然增加or減少,那很可能是資料邏輯有問題);
-
定義合理的資料監控,可以避免資料為空,資料波動過大,資料欄位不合理等問題;
Enjoy Data Engineering!!
作者|周慧玲(逐樂)
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/ODPS-optimization-suggestions-for-technical-newcomers.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/549929.html
標籤:MySQL
下一篇:sql 連續活躍天數