1. 背景
已知資料集為:
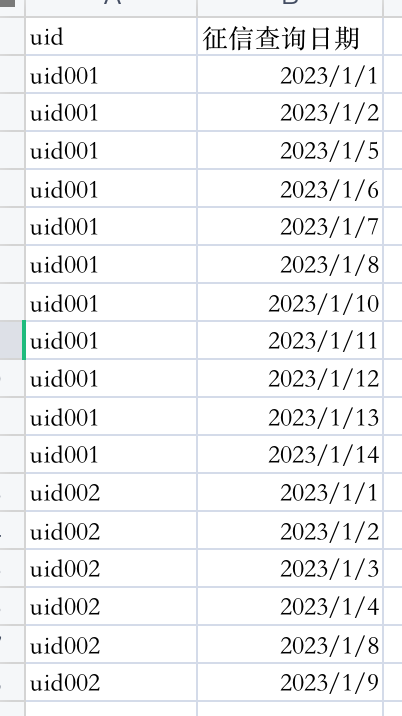
目的:
計算每個uid的連續活躍天數,并且每一段活躍期內的開始時間和結束時間
2. 步驟
第一步:處理資料集
處理資料集,使其滿足每個uid每個日期只有一條資料,
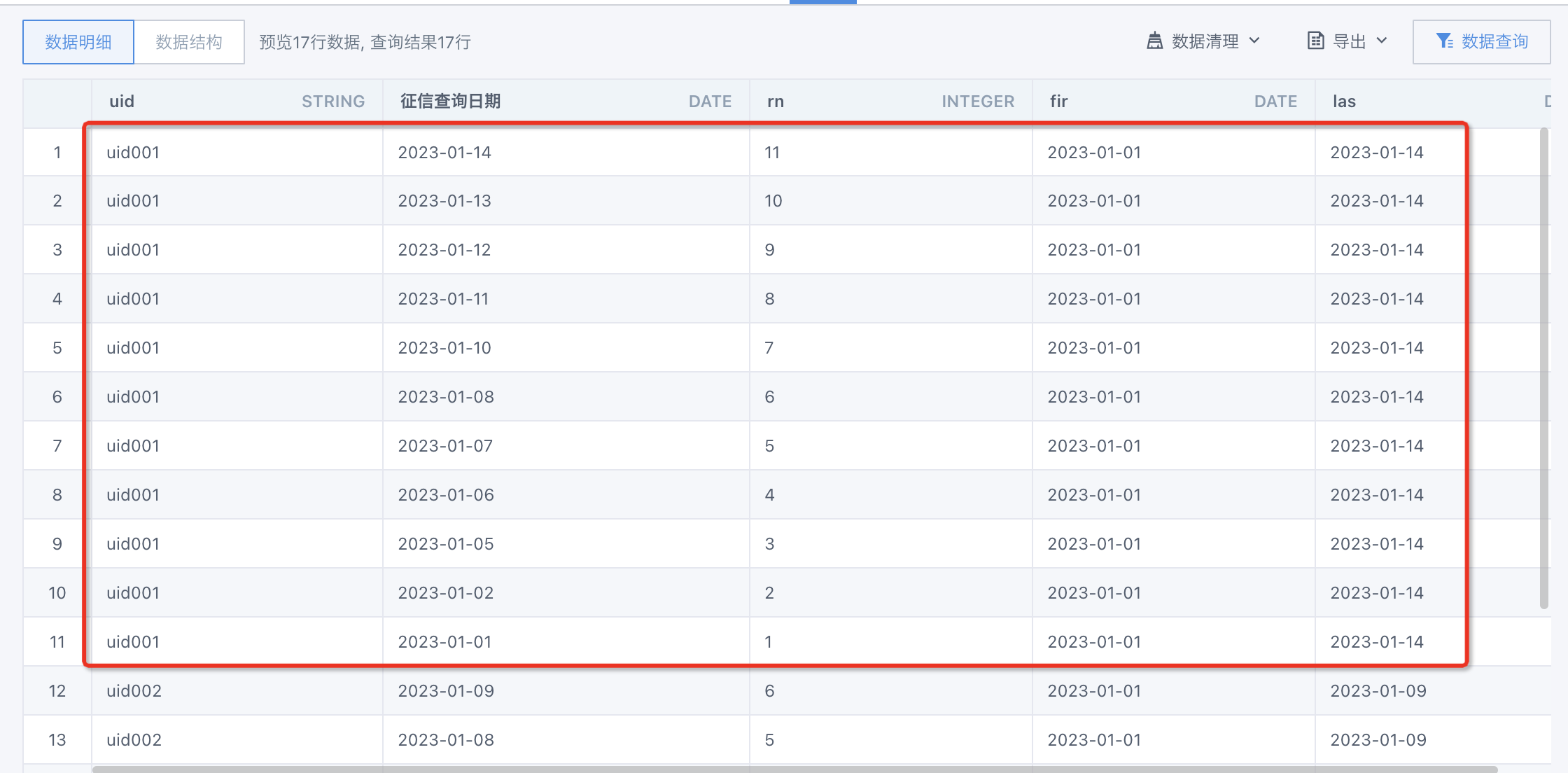
第二步:以uid為主鍵,按照日期進行排序,計算row_number.
SELECT uid
,`征信查詢日期`
,ROW_NUMBER() OVER(PARTITION BY uid ORDER BY `征信查詢日期` ASC) AS `rn`
,first_value(`征信查詢日期`)over(PARTITION BY uid ORDER BY `征信查詢日期` ASC) `fir`
,first_value(`征信查詢日期`)over(PARTITION BY uid ORDER BY `征信查詢日期` desc) `las`
FROM input
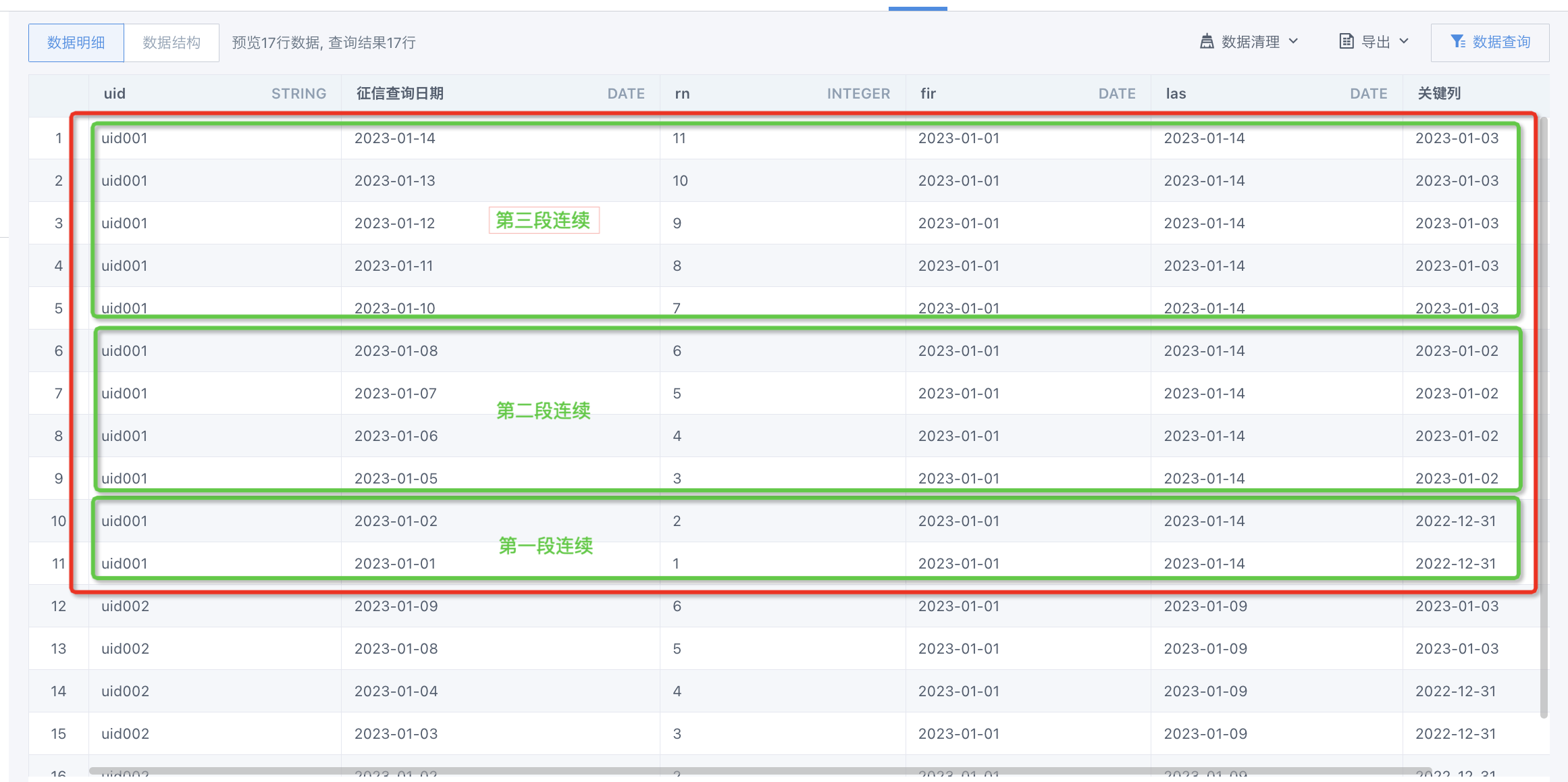
兩個關鍵點:
- 序號rn可以看做一直活躍的情況下,活躍日期最大值和活躍日期最小值之間的天數差,那么,日期最大值與日期最小值之差如果不等于序號,就表明中間有不連續,
- 用'征信查詢日期' - rn 可以計算一列"關鍵列",連續時間段內,它的關鍵列值是一樣的
select *,DATE_SUB(`征信查詢日期`,`rn`) as `關鍵列` from (
SELECT uid
,`征信查詢日期`
,ROW_NUMBER() OVER(PARTITION BY uid ORDER BY `征信查詢日期` ASC) AS `rn`
,first_value(`征信查詢日期`)over(PARTITION BY uid ORDER BY `征信查詢日期` ASC) `fir`
,first_value(`征信查詢日期`)over(PARTITION BY uid ORDER BY `征信查詢日期` desc) `las`
FROM input)
第三步:以uid和關鍵列作為主鍵,
select uid, `關鍵列`,count(*) as `連續活躍天數`, min(`征信查詢日期`) as `活躍開始時間`, max(`征信查詢日期`) as `活躍結束時間` from (
select *, DATE_SUB(`征信查詢日期`,`rn`) as `關鍵列` from (
SELECT uid
,`征信查詢日期`
,ROW_NUMBER() OVER(PARTITION BY uid ORDER BY `征信查詢日期` ASC) AS `rn`
,first_value(`征信查詢日期`)over(PARTITION BY uid ORDER BY `征信查詢日期` ASC) `fir`
,first_value(`征信查詢日期`)over(PARTITION BY uid ORDER BY `征信查詢日期` desc) `las`
FROM input
) )group by uid, `關鍵列`

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/549930.html
標籤:MySQL
上一篇:給技術新人的ODPS優化建議
下一篇:qrtz表初始化腳本_mysql