目錄
- 想想我們漏了什么
- 回顧
- 補回
- 集群的建立
- 集群發現機制
- 組態檔
- 健康狀態
- 補充:
- 小節總結
- 分片的管理
- 梳理
- 分片的均衡分配
- 主副分片的排斥
- 容錯性:
- 資料路由
- 對于集群健康狀態的影響
- 小節總結:
- 請求的處理
- 提供服務
- 協調節點cordination node
- 請求分發的負載均衡
- 補充:
- 小節總結
- 檔案的元資料
- 檔案的資料型別
- 資料型別
- 補充:
- mapping
- dynamic mapping
- 舉例:
- 創建mapping
- 修改mapping
- 查看mapping
- keyword
- mapping對分詞的影響
- 補充:
- 小節總結:
- dynamic mapping
- 相關度分數
- TF演算法
- IDF演算法
- Field-length norm演算法,
- 三種演算法的綜合:
- score計算API
- 小節總結
- 分詞器
- 常見的內置分詞器:
- 分詞示例
- 修改分詞器
- 中文分詞器
- 如何安裝
- 使用
- 補充:
- 小節總結:
- 檔案的ID
想想我們漏了什么
這篇文章已經是第四篇了,前面很多都只是講了基礎的使用,沒有講到內層的原理,所以這里就要補一下原理知識了,
回顧
先回顧一下我們前面學過了什么,再想想我們漏了什么,
第一篇我們認識了ElasticSearch,大概知道了ElasticSearch的作用--搜索,也了解了一些倒排索引和分詞器的知識(需要補充),然后學習了如何搭建環境(需要補充一下關于基礎的集群知識),然后講了一些基礎的ElasticSearch概念(重新講述,加深了解),
第二篇講了索引和檔案的CRUD,講創建索引的時候,沒有講mapping,講檔案的時候沒有講檔案的資料型別和元資料,這些都需要補充,
第三篇講了檔案的搜索,主要是語法方面的問題,但相關度分數是怎么計算出來的,我們并沒有講,
補回
所以下面將對前面漏了的基礎知識進行補充:
- Json檔案的資料格式?【我們之前只會弄一個簡單的json,而不知道里面有什么區別】
- 集群的基礎認識?【我們之前說了ElasticSearch是一個分布式的系統,但我們之前只講了如何啟動,如何使用kibana操作ElasticSearch,并沒有講ElasticSearch的集群式怎么建立的】
- 節點是怎么提供服務的?【我們之前只知道直接發請求,這個請求ElasticSearch是怎么處理的,我們并不知道】
- 索引的mapping?【之前創建索引的時候,沒有說清楚mapping,mapping受檔案的資料型別影響,mapping影響查詢方式和分詞方式】
- 相關度分數score是怎么算出來的?【我們知道score是相關度分數,但我們并不知道這個是怎么算出來的】
- 分詞器的原理【第一篇講了一點,現在加深】
集群的建立
我們說了,ElasticSearch是分布式的,但我們之前只說了如何啟動ElasticSearch,然后使用Kibana操作ElasticSearch,并沒有講ElasticSearch的集群式如何建立的,所以下面將會講一下集群的知識,但如何管理集群會單獨做成一篇來講,
集群發現機制
首先,每一個ElasticSearch服務端就是一個集群節點,當我們啟動一個elasticsearch時,就相當于啟動了一個集群節點,
那么,多個節點之間如何建立聯系呢?當我們啟動一個節點的時候,這個節點會自動創建一個集群,集群的名稱默認為elasticsearch,當我們再次啟動一個節點的時候,它首先會嘗試尋找名稱為elasticsearch的集群,然后加入其中,(所有的都是先嘗試尋找,沒有再自己創建),【集群名稱可以自行配置,下面講】
當節點加入到集群中后,這個集群就算是建立起來了,
組態檔
上面講了集群名稱可以自行配置,下面講一下怎么配置,
ElasticSearch的組態檔是config/elasticsearch.yml,里面有以下幾個配置項:
【左邊是配置項,右邊是值,修改配置也就是修改右邊的值】
- 集群名稱:
cluster.name: my-application - 索引存盤位置:
path.data: /path/to/data - 日志存盤位置:
path.logs: /path/to/logs - 系結的IP地址:
network.host: 192.168.0.1 - 系結的http埠:
http.port: 9200 - 是否允許使用通配符來標識索引:
action.destructive_requires_name,true為禁止,
健康狀態
當集群建立后,我們可以使用命令來查看集群狀態:
GET /_cluster/health:以json方式顯示集群狀態

GET /_cat/health?v:行列式顯示集群狀態

回傳結果決議:- epoch:時間戳
- timestamp:時間
- cluster:集群名
- status:狀態
- 集群狀態決議看下面,
- node.total:集群中的節點數
- node.data:集群中的資料節點數
- shards:集群中總的分片數量
- pri:主分片數量
- relo:副本分片數量
- init:初始化中的分片數?【不確定,英文是這樣的:number of initializing nodes 】
- unassign:沒有被分配的分片的數量
- pending_tasks:待處理的任務數
- max_task_wait_time:最大任務等待時間
- activeds_percent:active的分片數量
集群狀態決議:
集群狀態受當前的primary shared和replica shared的數量影響,
當每個索引的primary shared和replica shared都是active的時候,狀態為green;【什么是active?shard是位于節點上的,一個shard被分配到了運行的節點上,那么此時就是active的,如果shard沒有分配到節點上,那么就是inactive】
當每個索引的primary shared都是active的,但replica shared不完全是active的時候,狀態為yellow;
當每個索引的primary shared不完全是active的時候,此時發生了資料丟失,狀態為red,
為什么現在是yellow?
當我們第一次啟動的時候,kibana會默認為我們創建一個名為kibana的索引,這個索引的primary shard和replica shard都為1,由于此時只有一個節點,所以會優先分配primary shard,而忽略replica shard(不要忘了基于備份的安全性的shard排斥考慮:主分片和副本分片不能位于同一個節點上),所以此時就符合了“每個索引的primary shared都是active的,但replica shared不全是active的”,所以此時是yellow.
你可以嘗試啟動多一個elasticsearch節點來調整狀態,【當然,我覺得你學到這里了,此時replica shard的數量可能已經變了,所以這里只啟動多一個可能已經不夠了,具體的下面“分片的管理”講】
補充:
- 集群的知識還有很多,這里講集群只是講了個開頭,對于深層的集群管理并沒有涉及,將留到后面集群管理篇講,
小節總結
上面講了當啟動了一個elasticsearch之后,這個節點先尋找集群,沒有的話就自己創建一個,然后后續的其他節點也會加入這個節點,從而自動實作了自動集群化部署,
分片的管理
之前講了一些分片的知識,但并沒有具體用到,可能有些人已經忘了這個概念,這里重新講一下,
梳理
檔案的資料是存盤到索引中的,而索引的資料是存盤在分片上的,而分片是位于節點上的,
分片shard有主分片primary shard和復制分片replica shard兩種,其中主分片是主要存盤的分片,可以進行讀寫操作;副本分片是主分片的備份,可以進行讀操作(不支持寫操作),
查詢可以在主分片或副本分片上進行查詢,這樣可以提供查詢效率,【但資料的修改只發生在主分片上,】
分片是面向索引的,分片上的資料屬于同一個索引,在我們創建索引的時候,可以指定主分片和副本分片的數量,默認是5個主分片,5個副本分片,
索引的replica shard的數量可以修改,但primary shard的數量不可以修改,【一個Primary Shard可以有多個Replica Shard,默認創建是1個,】
修改replica shard數量:
PUT /douban/_settings
{
"number_of_replicas":1
}
為了保證資料的不丟失,通常來說Replica Shard不能與其對應的Primary Shard處于同一個節點中,【因為萬一這個節點損壞了,那么存盤在這個節點上的原資料(primary shard)和備份資料(replica shard)就全部丟失了】,但是可以和其他primary shard的replica shard放在一起
replica shard是primary shard的副本分片,負責承載一定的讀請求,當primary shard都掛掉后,其中一個replica shard會變成primary shard來維持寫功能,
分片的均衡分配
分片是分配到節點上的,但它會默認地均衡分配,
所謂均衡分配,以情況舉例:【priX代表主分片XX,repX代表副本分片XX】
1.索引有1個priA,1個repA,但當前只有一個節點A,那么priA分配到A節點;repA沒有分配,優先分配主分片,
2.索引有1個priA,1個repA,當前有兩個節點A和B,那么priA分配到A節點;repA分配到B節點(priA分配到B節點也有可能),
3.索引當前有2個priA,4個repA,有3個節點,那么現在每臺節點上有兩個分片(但要考慮主分片不能與自己的副本分片同在一個節點上,在下面的“ 主副分片的排斥”中由一個例子),
【當后續新增節點的時候,會自動再次重新均衡分配,】
主副分片的排斥
考慮到備份的安全性,不應該讓主分片和副本分片位于一個節點上,不然可能完全丟失資料,(比如你為了避免丟失鑰匙,你給你家的門準備兩條鑰匙,你有一個錢包和一個背包,結果你把兩條鑰匙都放到錢包中,某天你錢包丟了,于是你回不了家了,,,所以你應該把鑰匙分開放,)
對應的排斥情況就是:
1.索引有1個priA,1個repA,但當前只有一個節點A,那么priA分配到A節點;repA沒有分配,
2.索引有1個priA,1個repA,當前有兩個節點A和B,那么priA分配到A節點;repA分配到B節點(priA分配到B節點也有可能),
【請注意,主分片與副本分片不能在一起,但副本分片和副本分片能存放在一起】
在上面的“分片的均衡分配”沒有提到主副分片的排斥的問題,下面再舉一個例子【下述的分配結果還有可能是其他的】:
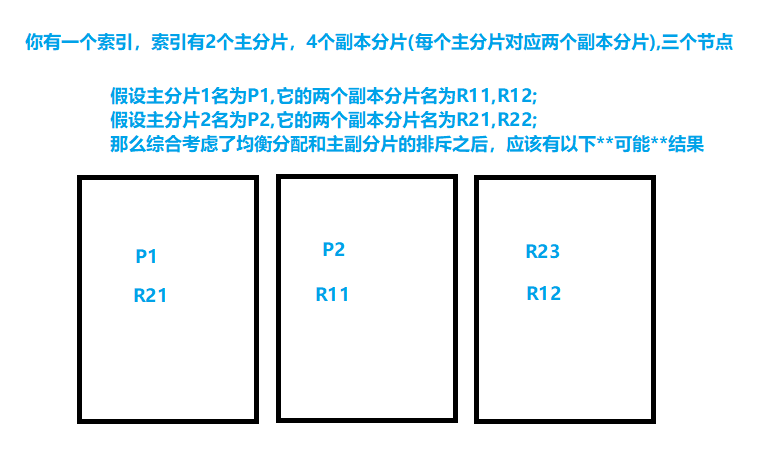
容錯性:
既然提到了備份的安全性,那么就不得不提一下容錯性了,節點是有可能宕機的,宕機后,那么這個節點的資料起碼會暫時性的丟失,那么對于不同情況下,最多可以宕機多少個節點呢?下面舉例:【pri = x代表主分片數量為X,rep是副本分片】
1.如果你只有一個節點,那么容錯性為0,你不能宕機,宕機不完全意味著資料完全丟失,但暫停服務還是有的,
2.如果你有兩個節點,pri = 2,rep = 2,那么此時分片分配應該是[P1R2, P2R1],此時容錯性為一個,因為某個節點上有完整的兩個分片的資料【此處一提,假設丟失了P2R1,那么R1R2中的R2會升級成primary shard來保持寫功能】
3.后面的自己嘗試算一下吧!要綜合均衡分片和排斥性來考慮,
資料路由
每一個document會存盤到唯一的一個primary shared和其副本分片replica shard 中,我們是怎么根據ID來知道這個document存盤在哪個分片的呢?
ElasticSearch會自動根據document的id值來進行計算,最終得出一個小于分片數量的數值,這個數值就是分片在ElasticSearch中的序號,最終得出應該存盤到哪個分片上,
類似原理舉例,假設我現在有4個主分片,那么我給它們標序號0,1,2,3,現在進來一個ID為15的資料,我經過一系列計算之后,15入參之后假設得到243這個數值,然后我們使用243來對4求余,余數是3,所以就把這個資料放在序號為3的分片上,
依據這個原理,存盤資料的時候就知道把資料放在哪個分片上;讀取資料的時候也知道從哪個分片上讀取資料,
【稍微提一下,在ElasticSearch全文搜索完成之后,此時內部得到的是ID組成的陣列,內部再會根據ID來查找資料】
對于集群健康狀態的影響
上面說了,集群狀態受當前的primary shared和replica shared的數量影響,
- 當每個索引的primary shared和replica shared都是active的時候,狀態為green;
- 當每個索引的primary shared都是active的,但replica shared不完全是active的時候,狀態為yellow;
- 當每個索引的primary shared不完全是active的時候,此時發生了資料丟失,狀態為red,
現在學會了“分片的均衡分配”和“主副分片的排斥”后,你應該能分析出要啟動多少個節點才能改變集群的健康狀態,
下面舉個例子,以變green為例:
當前節點中只有一個索引A,索引A當前有2個priA,4個repA,那么此時需要兩個節點才可以變green,
一個的時候就不說了,此時所有副本分片都inactive;兩個節點的時候,由于每個主分片有兩個副本分片,此時的分配是[P1-R11-R12,P2-R21-R22]
小節總結:
本節重新講了主分片和副本分片的功能,主分片和副本分片都有存盤資料的功能,一個索引的資料平分到多個主分片上,副本分片拷貝對應主分片的資料;然后講了ElasticSearch對于分片的自動均衡分配,和主分片和副本分片不能存盤在一起的問題,然后講了ElasticSearch如何根據ID來判斷資料存盤在哪個分片上,最后講了節點上分片的分配對于集群健康狀態的影響,
請求的處理
提供服務
- 節點是提供服務的單位,請求是發到節點上的,
- 節點接收到請求后,會對請求進行處理:
- 讀請求:
- 當接受讀請求,如果是根據ID來獲取資料的讀請求,那么它會選擇有這個ID的資料的分片來獲取資料(可以根據ID來判斷該分片上是否有這份資料);如果是搜索類的請求,首先會根據索引表來搜索,得出相關檔案的ID,然后根據ID從這個索引的相關分片來獲取資料(如果有2個pri,2個rep,那么搜索的分片可能是p1r2、p2r1、p1p2,r1r2,只要能完整地獲取索引的所有資料即可),
- 寫請求:
- 當接收寫請求,節點會選擇根據ID來計算應該把這個資料存盤到哪個主分片上,然后通過主分片來修改資料,主分片修改完成后,會將資料同步到副本分片上,【由于存在一個同步程序,同步完成之前,某個分片上可能不存在剛剛插入的資料,但概率較小,因為同步是極快的(NRT)】
- 讀請求:
- 【再次提醒,主分片有讀和寫的能力,副本分片只可以讀,所以資料的更新都發生在主分片上】
協調節點cordination node
索引的資料是存盤在節點上的,當一個請求發到節點上的時候,可能這個節點上并沒有這個索引的資料,那么這個時候就需要把請求轉發給另一個節點了,這時候原本的節點就是一個“協調節點”,
請求分發的負載均衡
一個索引存盤在多個主分片和副本分片上,索引的資料會平均分配到每一個主分片中,然后每一個副本分片拷貝對應主分片的資料,
對于資料存盤,資料是存盤在分片上的,而分片位于節點上,在上面說了分片會均衡分配到每一個節點上,這樣也保證了節點上的資料量是平均的,除此之外,對于讀取某一個主分片及其副本分片上的資料的時候,會使用輪詢演算法來將讀請求平均分配(大概意思就是,假設現在對于主分片1有三個副本分片,那么總數為4,假設分別編號1、2、3、4,那么可能地,第一次請求交給了1,那么第二次請求要交給2,第三次要交給3,,,以此類推,超過4則從頭開始),
補充:
- 除了上面的內容,還有一些與集群比較相關的內容,比如某節點宕機后會發生什么,這些會留到集群管理篇再講,
小節總結
本節簡單說了一下讀寫操作的流程,ID類的讀請求直接根據ID來查找檔案,搜索類的讀請求先搜索索引表,再根據ID來查找檔案;寫資料請求會根據ID來計算應該把這個資料存盤到哪個主分片上,然后通過主分片來修改資料;最后講了一下對于請求分發的負載均衡,一方面通過資料量的平均分配來均衡,一方面使用輪詢演算法來降低單個分片的處理壓力,
檔案的元資料
你在查詢檔案的時候,你可能看到回傳結果中有如下的內容:
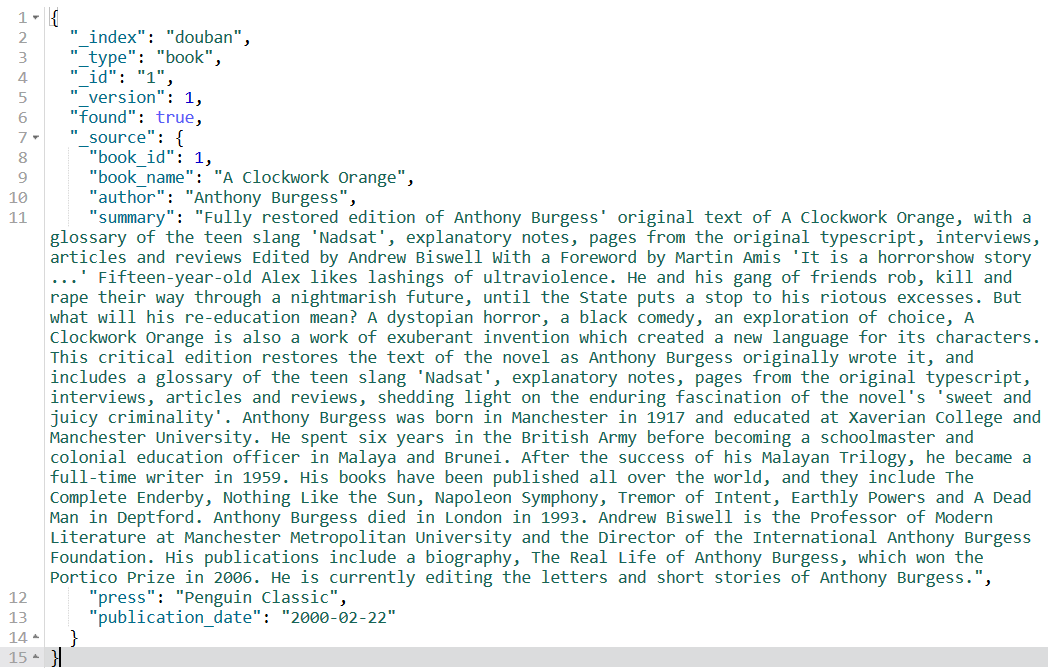
上面的幾個前綴有_的就是元資料,
_index:代表當前document存放到哪個index中,_type:代表當前document存放在index的哪個type中,_id:代表document的唯一標識,與index和type一起,可以唯一標識和定位一個document,【在前面我們都是手動指定的,其實可以不手動指定,那樣會隨機產生要給唯一的字串作為ID】_version:是當前document的版本,這個版本用于標識這個document的“更新次數”(新建、洗掉、修改都會增加版本)_source:回傳的結果是查詢出來的當前存盤在索引中的完整的document資料,之前在搜索篇中講到了,我們可以使用_source來指定回傳docuemnt的哪些欄位,
元資料與具體的檔案資料無關,每一個檔案都有這些資料,
檔案的資料型別
對于web中的json,資料格式主要有字串、數值、陣列和{}這幾種,
比如:
{
"name": "neo",
"age": 18,
"tool": ["clothes", "computer", "gun"],
"gf": {
"feature": "beauty"
}
}
ElasticSearch并不是這樣的,因為它要考慮分詞,就算是字串,它也要考慮里面的資料是不是日期型別的,日期型別通常不會分詞,
資料型別
ElasticSearch主要有以下這幾種資料型別:
- 字符類:
- text:是存盤字串的型別,在elasticsearch中存盤會分詞的字串資料一般用text
- keyword:也是存盤字串的型別,在elasticsearch中用于存盤不會分詞的、結構化的字串資料
string:string在5.x之前可以使用,現在已被text和keyword取代,
- 整數型別:
- integer
- long
- short
- byte
- 浮點數型別:
- double
- float
- 日期型別:date
- 布爾型別:boolean
- 陣列型別:array
- 物件型別:object
【除了上述的型別之外,還有一些例如half_float、scaled_float、binary、ip等等型別,由于不是非常基礎的內容,所以這里不講,有興趣的可以自查,】
補充:
- 資料型別本身是沒有多少重要的知識點,重要的是與資料型別緊密相關的mapping,因為mapping存盤的就是索引的結構資訊,下面小節將講述mapping,
mapping
mapping負責維護index中檔案的結構,包括檔案的欄位名、欄位資料型別、分詞器、欄位是否進行分詞等,這些屬性會對我們的搜索造成影響,
dynamic mapping
在前面,其實我們都沒有定義過mapping,直接就是插入資料了,其實這時候ElasticSearch會幫我們自動定義mapping,這個mapping會依據檔案的資料來自動生成,
此時,如果資料是字串的,會認為是text型別,并且默認進行分詞;如果資料是日期型別類(字串里面的資料是日期格式的),那么這個欄位會認為是date型別的,是不分詞的;如果資料是整數,那么這個欄位會認為是long型別的資料;如果資料是小數,那么這個欄位會認為是float型別的;如果是true或者false,會認為是boolean型別的,
舉例:
我們插入以下資料【如果你用了這個索引,那么可以自定義一個索引,避免我隨意創建的資料污染了你的測驗資料】:
PUT /test/person/1
{
"name":"suke",
"age":18,
"tall":178.5,
"birthdate":"2018-01-01"
}
然后查看索引,其中mapping定義了我們剛剛定義的欄位的資訊:
GET /test

創建mapping
【之前在第二篇中有提到,可以通過查看索引來查看mapping】
語法:
【[]代表里面的內容是可選的,非必須的】
PUT /index/
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
},
"mappings": {
"type名": {
"properties": {
"欄位名": {
"type": "資料型別",
// 是否索引,不索引則不將這個欄位列入索引表,無法對這個欄位進行搜索
["index": "是否索引,值為true或者fasle",]
// 是否新舊keyword保留原始資料
["fields": {
"keyword": {
"type": "keyword",【這個是保留原始資料采用的資料型別,也可以使用text,一般用keyword】
"ignore_above": 256【超過多少字符就忽略,不建立keyword】
}
},]
// (選擇什么分詞器來對這個欄位進行分詞)
["analyzer": "分詞器名稱"
,]
}
}
}
}
}
【內容補充:在舊版中,index的值有not_analyzed這樣的值,現在只有true或false,它的原意是不分詞,現在是不索引,在舊版中,不分詞則會保留原始資料,在新版中使用keyword來保留原始資料】
舉例:
1.創建一個mapping,只定義資料型別:【定義了每個欄位的資料型別后,插入資料的時候并沒有說要嚴格遵循,資料型別的作用是提前宣告欄位的資料型別,例如在之前第二篇說type的時候,就提到了多個type中的欄位其實都會匯總到mapping中,如果不提前宣告,那么可能導致因為使用dynamic mapping而使得資料型別定義出錯,比如在type1中birthdate欄位】
> 第二篇中這樣說的:當我們直接插入document的時候,如果不指定document的資料結構,那么ElastciSearch會基于dynamic mapping來自動幫我們宣告每一個欄位的資料型別,比如"content":"hello world!"會被宣告成字串型別,"post_date":"2017-07-07"會被認為是date型別,如果我們首先在一個type中宣告了content為字串型別,再在另外一個type中宣告成日期型別,這會報錯,因為對于index來說,這個content已經被宣告成字串型別了,
PUT /test0101
{
"settings": {
"index":{
"number_of_shards":3,
"number_of_replicas":1
}
},
"mappings": {
"person":{
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"birthdate":{
"type":"date"
}
}
}
}
}
2.設定某個欄位不進行索引【設定后,你可以嘗試對這個欄位搜索,會報錯!】
PUT /test0102
{
"settings": {
"index":{
"number_of_shards":3,
"number_of_replicas":1
}
},
"mappings": {
"person":{
"properties": {
"name":{
"type": "text",
"index": "false"
},
"age":{
"type": "long"
},
"birthdate":{
"type":"date"
}
}
}
}
}
測驗:
PUT /test0102/person/1
{
"name":"Paul Smith",
"age":18,
"birthdate":"2018-01-01"
}
GET /test0102/person/_search
{
"query": {
"match": {
"name": "Paul"
}
}
}
3.給某個欄位增加keyword
PUT /test0103
{
"settings": {
"index":{
"number_of_shards":3,
"number_of_replicas":1
}
},
"mappings": {
"person":{
"properties": {
"name":{
"type": "text",
"index": "false",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age":{
"type": "long"
},
"birthdate":{
"type":"date"
}
}
}
}
}
測驗:
PUT /test0103/person/1
{
"name":"Paul Smith",
"age":18,
"birthdate":"2018-01-01"
}
【注意這里是不能使用name來搜索的,要使用name.keyword來搜索,而且keyword是對原始資料進行**不分詞**的搜索的,所以你搜單個詞是找不到的,】
GET /test0103/person/_search
{
"query": {
"match": {
"name.keyword": "Paul Smith"
}
}
}
修改mapping
mapping只能新增欄位,不能修改原有的欄位,
// 給索引test0103的型別person新增一個欄位height
PUT /test0103/_mapping/person
{
"properties": {
"height":{
"type": "float"
}
}
}
查看mapping
1.之前說過了,可以通過查看索引來查看mapping:GET /index,例如GET /test0103/_mapping
2.通過GET /index/_mapping,例子:GET /test0103/_mapping
3.你也可以附加type來查看指定type包裹的mapping,GET /test0103/_mapping/person
keyword
上面定義mapping的時候有定義一個keyword,這是什么?有什么用?
ElasticSearch對于一些型別的欄位,例如text型別的欄位,默認是會進行分詞的,但如果我們并不想分詞呢?一些資料我們想要非常精確地查找,并且只找到我們搜索的資料的時候,這個欄位是不應該分詞的,那么我們可以使用keyword來存盤完整的原有的資料,keyword會作為一個索引詞,然后我們針對欄位.keyword來搜索,【例子上面已經舉例了】理論上,這個不分詞的欄位的資料應該是比較簡短的,太長的話可能就沒有必要不分詞了,所以在定義keyword的時候還可以提供
"ignore_above": 數值來限制超過多少個字符就不使用原有資料創建keyword.
現在版本中,對于默認分詞的欄位,現在會默認附加一個keyword,
mapping對分詞的影響
1.資料型別的影響:
以date和text型別存盤的“日期”型別的資料的分詞差異化為例:
date和string這兩者都是使用雙引號包裹的,與其他數值型的不分詞的資料型別不一樣,所以以他們兩個為例,
PUT /test0104
{
"settings": {
"index":{
"number_of_shards":3,
"number_of_replicas":1
}
},
"mappings": {
"test":{
"properties": {
"post_date":{
"type": "text"
},
"birthdate":{
"type":"date"
}
}
}
}
}
PUT /test0104/test/1
{
"post_date":"2019-09-30",
"birthdate":"2018-08-29"
}
PUT /test0104/test/2
{
"post_date":"2018-09-30",
"birthdate":"2017-08-29"
}
PUT /test0104/test/3
{
"post_date":"2017-09-30",
"birthdate":"2016-08-29"
}
//測驗1:結果是ID:1
GET /test0104/test/_search
{
"query": {
"match": {
"post_date": "2019"
}
}
}
// 測驗2:結果是ID=1,2,3的檔案,理論上text存盤的日期格式的沒有分詞區別
GET /test0104/test/_search
{
"query": {
"match": {
"post_date": "30"
}
}
}
//測驗3:結果無,【單搜索08或2017,2018,2016也是無,】
GET /test0104/test/_search
{
"query": {
"match": {
"birthdate": "29"
}
}
}
//測驗4, 結果是ID=2的檔案
GET /test0104/test/_search
{
"query": {
"match": {
"birthdate": "2017-08-29"
}
}
}
2.不索引的影響:
不索引的時候不會進行分詞,甚至不能用于搜索,【低版本對于properties中的index設定不一樣,5.x以下是不分詞,5.x以上是不索引,不索引就不可以用于搜索】
3.keyword的影響:
keyword適用于不分詞的搜索的情況,在keyword中的資料不會分詞,
4.其他:
mapping還可以設定分詞器來使用不同的分詞器來分詞,
// 你可以使用格式類似如下的代碼來測驗mapping中某個欄位的分詞結果,如果是不允許分詞的,則會報Analysis requests are only supported on tokenized fields錯誤,
GET /test0104/_analyze
{
"field": "post_date",
"text": "2017-09-30"
}
補充:
- dynamic mapping策略是關于自動創建mapping的策略,定義了遇上某某資料的時候把它當作什么型別,比如可以定義存入"2017-09-30"的時候認為是text而不是date,這些內容可能會留到后面再講,也有可能后面再補充到這里,
- 復合資料型別比較特殊,可能會留到后面再講,也有可能后面再補充到這里,
小節總結:
本節介紹了什么是mapping,mapping負責管理索引的資料結構和欄位的分詞等一些配置,在直接存盤資料的時候,會dynamic mapping;然后介紹了如何創建mapping,如何修改mapping,如何查看mapping;然后介紹了keyword這個保留原資料的一個特殊的欄位,
相關度分數
相關度分數的具體演算法我們其實并不需要關心,但可能還是需要大概了解一下計算的方式,
為什么說不需要關心呢?因為實際上相關度是由索引詞直接決定的,分析好哪些是用于搜索的詞就可以大致分析出相關度排序了,
當然,這只是大概的,因為內部可能因為索引詞的重復性問題會降低某個詞的score,但差距一般不會太大,
- 在我們進行搜索的時候,你可以看到一個score,這個就是相關度分數,在默認排序中相關度分數最高的會被排在最前面,這個分數是ElasticSearch根據你搜索的內容,使用內部演算法計算出的一個數值,
- 內部演算法主要是指TF演算法和IDF演算法,
TF演算法
TF演算法,全稱Term frequency,索引詞頻率演算法,
意義就像它的名字,會根據索引詞的頻率來計算,索引詞出現的次數越多,分數越高,
例子如下:
搜索
hello
有兩份檔案:A檔案:hello world!,B檔案:hello hello hello
結果是B檔案的score大于A檔案,搜索
hello world
有兩份檔案:A檔案:hello world!,B檔案:hello,are you ok?
結果是A檔案的score大于B檔案,要根據索引詞來綜合考慮,
IDF演算法
IDF演算法全稱Inverse Document Frequency,逆文本頻率,
搜索文本的詞在整個索引的所有檔案中出現的次數越多,這個詞所占的score的比重就越低,
例子如下:
搜索
hello world,其中索引中hello出現次數1000次,world出現100次,
有三份檔案:A檔案hello,are you ok?,B檔案The world is interesting!,C檔案hello world!
結果是:C>B>A
由于hello出現頻率高,所以單個hello得到的score比不上world,
Field-length norm演算法,
- 這個演算法elasticsearch并沒有單獨列出來,但也有生效,
- field越長,相關度就越低,資料長度會拉低相關度,
例子如下:
搜索
hello world!
有兩份檔案:A檔案hello world!,B檔案hello world,I'm xxx!
結果是:A>B
三種演算法的綜合:
(下面屬于理論分析,并不真實這樣計算)
TF演算法針對在Field中,索引詞出現的頻率;
IDF演算法針對在整個索引中的索引詞出現的頻率;
Field-length norm演算法針對Field的長度,
那么可以這樣分析,由于Field-length norm演算法并不直接針對score,所以它是最后起作用的,它理論上類似于一個除數,而TF和IDF是平等的,IDF計算出每一個索引詞的score量,TF來計算整個檔案中索引詞的score的加和,
也就是如下的計算:
1.IDF:計算索引詞的單位score,比如hello=0.1,world=0.2,
2.TF:計算整個檔案的sum(score),hello world!I'm xxx.得到0.1+0.2=0.3
3.Field-length norm:將sum(score)/對應Field的長度,得出的結果就是score,
score計算API
elasticsearch提供了測驗計算score的API,語法類似如下:
GET /index/type/_search?explain=true
{
"query": {
"match": {
"搜索欄位": "搜索值"
}
}
}
例子:
GET /douban/book/_search?explain=true
{
"query": {
"match": {
"book_name": "Story"
}
}
}
回傳結果資料決議:
_explanation是score的原因,_explanation的格式是先列出分數,然后detail部分解釋分數,內層也是,

小節總結
這節介紹了相關度分數的計算方式,可以大致了解一下score是怎么得出來得,TF是索引詞頻率演算法,是對索引詞分數的加和;IDF是基于整個索引對每個索引詞的計算分數;Field-length用于降低資料長的檔案的相關度分數,
分詞器
什么是分詞器?
分詞器負責對document進行處理,以提高搜索效率,
分詞器通常由分解器tokenizer和詞元過濾器token filter組成,分詞器對資料的分詞處理:為了提高索引的效率,ElasticSearch會資料進行處理,處理方式主要有字符過濾、詞轉換、詞拆分
字符過濾:過濾一些特殊字符,例如&、||、html標簽,因為這些詞通常搜索意義不大,詞轉換:把一些意義相同的詞統一轉成一個詞,(同詞義轉換)比如mom,mother統一轉成mom;(大小寫轉換)he,He統一歸為He;還處理一些詞意義不大的詞(停用詞清除),比如英文的“the”,“to”,這些詞使用頻率很高,但沒有具體意義,
詞拆分:進行資料的拆分,拆分成詞,比如把
good morning,mom拆分成good,morining,mom,另外,詞拆分并不完全是按照資料的最小單位分解的,某一些分詞器會把一些詞進行組合,因為一些詞的組合起來才有索引的意義,比如中文的一些詞通常要組合起來才有意義,比如“大”和“家”要組成“大家”才有比較具體的意義,這是為了確保索引詞的最小單位是有意義的(比如英文mom的最小單位是m,o,m,內部的分詞器要能夠區分出mom整個是有意義的才可以確保是采用mom作為索引,而不是采用m和o,也正是因為這個問題,所以英文分詞器不能用于中文分詞器),【分詞器有很多個,默認的分詞器是不能適當對中文資料分詞的,它只能把一個個資料按最小的單位拆分,因為英文分詞器不能分清楚怎么把詞拆分才有意義,由于配置分詞器是一個較為靠后的知識點,所以前期將以英文資料為測驗資料,】
常見的內置分詞器:
每一個分詞器的都有一些自己的規則,比如一些分詞器會把a當成停用詞,有些則不會;有些分詞器會去掉標點符號,有些則不會;有些分詞器能識別英文詞,但識別不了中文詞,要按需要來選擇分詞器,
- 標準分詞器standard analyzer:最基礎的分詞器,可以把詞進行拆分、
- 簡單分詞器simple analyzer:分詞、做字符過濾、不做詞轉換,
- 空格分詞器whitespace analyzer:僅僅根據空格來劃分詞,不會做字符過濾也不會做詞轉換,
- 英文分詞器english:根據英文標準來分詞,進行字符過濾,進行詞轉換(去除英文中的停用詞(a,the),同義詞轉換等)
- 小寫lowercase tokenizer:把英文全轉成小寫再分詞
- 字母分詞器letter tokenizer:根據字母來分詞
分詞示例
可以使用下面的格式的命令來測驗不同分詞器的分詞效果:
GET /_analyze
{
"analyzer": "分詞器",
"text": "要測驗的文本"
}
// 舉例:
GET /_analyze
{
"analyzer": "simple",
"text": "I am a little boy,I have 5$.dogs,long-distance,<html></html>"
}
示例:
原句:I am a little boy,I have 5$.dogs,long-distance,<html></html>
- 標準分詞器standard analyzer:
i,am,a,little,boy,i,have,5,dogs,long,distance,html,html【對于拆分成同一個詞的,會形成同一個索引詞】【這個分詞器,做了小寫、去掉特殊字符等操作】 - 簡單分詞器simple analyzer:
i,am,a,little,boy,i,have,dogs,long,distance,html,html【這個分詞器做了小寫、去掉特殊字符和數字等操作】 - 空格分詞器whitespace analyzer:
I,am,a,little,boy,I,have,5$.dogs,long-distance,<html></html>【根據空格分詞】 - 英文分詞器英文分詞器english::
i,am,littl,boi,i,have,5,dog,long,distanc,html,html【語言分詞器會比較特殊,會做一部分的形式轉換,有些時候會盲目地切分單詞,比如er和e這些常見后綴,會被切掉,所以little變成了littl,】
可能有人不是很懂分詞器的作用,這里再次重談一下:
如果使用的分詞器是standard,那你輸入的loves會認為是loves,loved會認為是loved;
而english會把loves認為是love,loved認為是love.
所以在english分詞器中,loves和loved的搜索用的是love的索引詞搜索,而standard中用的是loves和loved的索引詞,從搜索效率來說,english的搜索才是我們想要的,它比較靈活,
而且有些分詞器會幫你把詞組合起來,比如“中國人”這個詞不該被拆分成“中”“國”“人”】
修改分詞器
修改分詞器就是修改mapping中的analyzer,mapping中某個欄位一但創建就不能針對這個欄位修改,所以只能洗掉再修改或新增,
PUT /test0106
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"test":{
"properties": {
"content":{
"type": "text",
"analyzer": "standard"
},
"detail":{
"type": "text",
"analyzer": "english"
}
}
}
}
}
中文分詞器
在前面,我們都是使用英文作為欄位的資料,因為ElasticSearch默認情況下無法很好地對中文進行分詞,它默認只能一個個字地分詞,所以它會把“中國人”這個詞拆分成“中”“國”“人”,
所以我們需要使用“插件”來對ElasticSearch來進行擴展,
我們常用的中文分詞器就是IK分詞器,
如何安裝
1.去github上下載IK的zip檔案,下載的插件版本要與當前使用的elasticsearch版本一致,比如你是elasticsearch6.2.3,就下載6.2.3的【對于沒有自己版本的,這時候可能需要下載新的elasticsearch,有些人說可以通過修改pom.xml來強行適配,但還是存在一些問題的,】,github-IK
2.把zip檔案中的elasticsearch檔案夾解壓到elasticsearch安裝目錄\plugins中,并且重命名檔案夾為ik-analyzer
3.然后重啟elasticsearch
使用
IK分詞器提供了兩種分詞器ik_max_word和ik_smart
- ik_max_word: 會將文本做最細粒度的拆分,比如
北京天安門廣場會被拆分為北京,京,天安門廣場,天安門,天安,門,廣場,會嘗試各種在IK中可能的組合; - ik_smart: 會做最粗粒度的拆分,比如會將
北京天安門廣場拆分為北京,天安門廣場, - 一般都會使用ik_max_word,只有在某些確實只需要最粗粒度的時候才使用ik_smart,
// 測驗一:比較標準分詞器和IK分詞器的區別:
// 結果:標準分詞器只會一個個字地拆分
GET /_analyze
{
"analyzer": "standard",
"text": "北京天安門廣場"
}
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "北京天安門廣場"
}
GET /_analyze
{
"analyzer": "ik_smart",
"text": "北京天安門廣場"
}
// 測驗二:給某個欄位的mapping配置分詞器為ik_max_word,插入測驗資料,并進行搜索
PUT /test0107
{
"mappings": {
"test": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
PUT /test0107/test/1
{
"content":"北京天安門廣場"
}
PUT /test0107/test/2
{
"content":"上海世博會"
}
PUT /test0107/test/3
{
"content":"北京鳥巢"
}
PUT /test0107/test/4
{
"content":"上海外灘"
}
// 開始搜索:
GET /test0107/test/_search
{
"query": {
"match": {
"content": "北京"
}
}
}
GET /test0107/test/_search
{
"query": {
"match": {
"content": "鳥巢"
}
}
}
GET /test0107/test/_search
{
"query": {
"match": {
"content": "世博會"
}
}
}
// 這條搜索是搜索不出結果的,因為分詞的結果沒有“京”字
GET /test0107/test/_search
{
"query": {
"match": {
"content": "北"
}
}
}
補充:
- 上面說了“分詞器通常由分解器tokenizer和詞元過濾器token filter組成,”,所以其實我們也可以自己通過組合分解器和過濾器來成形成一個分詞器,這里有興趣自查的,【有可能后面某天會補充】
- 上面提到了中文分詞器,其實這已經涉及到了“插件”的內容了,這個內容會后面的篇章再講,
小節總結:
本節重新解釋了分詞器的作用(字符過濾,詞轉換,詞拆分),介紹了幾種常見的內置的分詞器(standard,english這些),并舉了一些分詞的例子,以及如何修改欄位的分詞器(mapping的analyzer),最后還介紹了怎么安裝支持中文分詞的ik分詞器,
檔案的ID
檔案的ID其實是可以不指定的,不指定的時候會隨機生成唯一的一串字串,

手動指定和不指定的區別:
手動指定通常適用于一些將資料庫的資料轉存到ElasticSearch的場景,因為這時候ID有特殊意義,讓資料庫的資料與ElasticSearch的資料關聯起來,(有時候可能需要同時查資料庫和ElasticSearch,那么可以直接根據資料庫中的ID來查ElasticSearch中的資料),
不指定的時候(這時候通常ID是沒有特殊意義的),ElasticSearch會自動地幫我們生成一個ID值,自動生成的ID長度為20個字符,這個ID它能確保是不會重復的,就算是在分布式并發情況下也不會發生沖突,【由于此時的ID是隨機字串,所以根據ID來查詢資料會比較麻煩】
這里講的還是比較偏應用方面的基礎知識,后面可能還會補充偏底層的一些基礎知識,比如底層寫入流程和NRT這些,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/5536.html
標籤:其它