1、如果你使用root用戶進行安裝, vi /etc/profile 即可 系統變數
2、如果你使用普通用戶進行安裝, vi ~/.bashrc 用戶變數
export HADOOP_HOME=/export/servers/hadoop-2.8.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
同步組態檔
[root@jiang01 servers]# vi /etc/profile
[root@jiang01 servers]#
[root@jiang01 servers]# xrsync.sh /etc/profile
=========== jiang02 : /etc/profile ===========
命令執行成功
=========== jiang03 : /etc/profile ===========
命令執行成功
[root@jiang01 servers]#
重繪配置各個機器配置:
source /etc/profile
修改下面各個組態檔:


<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href=https://www.cnblogs.com/ideajiang/p/"configuration.xsl"?><!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file.--><!-- Put site-specific property overrides in this file. --><configuration> <!-- 指定hdfs的nameservice為ns1 --> <property> <name>fs.defaultFS</name> <value>hdfs://myha01/</value> </property> <!-- 指定hadoop臨時目錄 --> <property> <name>hadoop.tmp.dir</name> <value>/export/servers/hadoop-2.8.5/hadoopDatas/tempDatas</value> </property> <!-- 指定zookeeper地址 --> <property> <name>ha.zookeeper.quorum</name> <value>jiang01:2181,jiang02:2181,jiang03:2181</value> </property></configuration>core-site.xml
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href=https://www.cnblogs.com/ideajiang/p/"configuration.xsl"?><!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file.--><!-- Put site-specific property overrides in this file. --><configuration> <!--指定hdfs的nameservice為ns1,需要和core-site.xml中的保持一致 --> <property> <name>dfs.nameservices</name> <value>myha01</value> </property> <!-- ns1下面有兩個NameNode,分別是nn1,nn2 --> <property> <name>dfs.ha.namenodes.myha01</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.myha01.nn1</name> <value>jiang01:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.myha01.nn1</name> <value>jiang01:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.myha01.nn2</name> <value>jiang02:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.myha01.nn2</name> <value>jiang02:50070</value> </property> <!-- 指定NameNode的元資料在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://jiang01:8485;jiang02:8485;jiang03:8485/myha01</value> </property> <!-- 指定JournalNode在本地磁盤存放資料的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/hadoop-2.8.5/journal</value> </property> <!-- 開啟NameNode失敗自動切換 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失敗自動切換實作方式 --> <property> <name>dfs.client.failover.proxy.provider.myha01</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔離機制 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔離機制時需要ssh免登陸 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_dsa</value> </property></configuration>hdfs-site.xml
<?xml version="1.0"?><!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file.--><configuration> <!-- Site specific YARN configuration properties --><!-- 開啟RM高可靠 --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 指定RM的cluster id --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yrc</value> </property> <!-- 指定RM的名字 --> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- 分別指定RM的地址 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>jiang02</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>jiang03</value> </property> <!-- 指定zk集群地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>jiang01:2181,jiang02:2181,jiang03:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property></configuration>yarn-site.xml
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href=https://www.cnblogs.com/ideajiang/p/"configuration.xsl"?><!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file.--><!-- Put site-specific property overrides in this file. --><configuration> <!-- 指定mr框架為yarn方式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property></configuration>mapred-site.xml
[root@jiang01 servers]# hadoop versionHadoop 2.8.5Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8Compiled by jdu on 2018-09-10T03:32ZCompiled with protoc 2.5.0From source with checksum 9942ca5c745417c14e318835f420733This command was run using /export/servers/hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.jar[root@jiang01 servers]#查看hadoop版本
啟動zk
[root@jiang01 servers]# [root@jiang01 servers]# xcall.sh jps -l============= jiang01 : jps -l ============10262 org.apache.zookeeper.server.quorum.QuorumPeerMain10571 sun.tools.jps.Jps命令執行成功============= jiang02 : jps -l ============10162 sun.tools.jps.Jps9991 org.apache.zookeeper.server.quorum.QuorumPeerMain命令執行成功============= jiang03 : jps -l ============2275 org.apache.zookeeper.server.quorum.QuorumPeerMain2436 sun.tools.jps.Jps命令執行成功[root@jiang01 servers]# xcall.sh zkServer.sh status============= jiang01 : zkServer.sh status ============ZooKeeper JMX enabled by defaultUsing config: /export/servers/zookeeper-3.4.14/bin/../conf/zoo.cfgMode: follower命令執行成功============= jiang02 : zkServer.sh status ============ZooKeeper JMX enabled by defaultUsing config: /export/servers/zookeeper-3.4.14/bin/../conf/zoo.cfgMode: leader命令執行成功============= jiang03 : zkServer.sh status ============ZooKeeper JMX enabled by defaultUsing config: /export/servers/zookeeper-3.4.14/bin/../conf/zoo.cfgMode: follower命令執行成功[root@jiang01 servers]#啟動zk
在你配置的各個journalnode節點啟動該行程
[root@jiang01 servers]# [root@jiang01 servers]# xcall.sh hadoop-daemon.sh start journalnode============= jiang01 : hadoop-daemon.sh start journalnode ============starting journalnode, logging to /export/servers/hadoop-2.8.5/logs/hadoop-root-journalnode-jiang01.out命令執行成功============= jiang02 : hadoop-daemon.sh start journalnode ============starting journalnode, logging to /export/servers/hadoop-2.8.5/logs/hadoop-root-journalnode-jiang02.out命令執行成功============= jiang03 : hadoop-daemon.sh start journalnode ============starting journalnode, logging to /export/servers/hadoop-2.8.5/logs/hadoop-root-journalnode-jiang03.out命令執行成功[root@jiang01 servers]#啟動journalnode
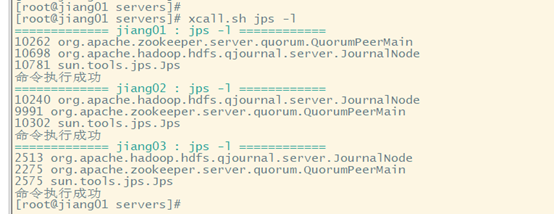
先選取一個namenode(jiang01)節點進行格式化
[root@jiang01 servers]# hadoop namenode -formatView Code
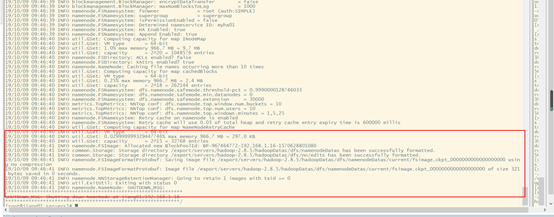
格式化zkfc,只能在nameonde節點進行
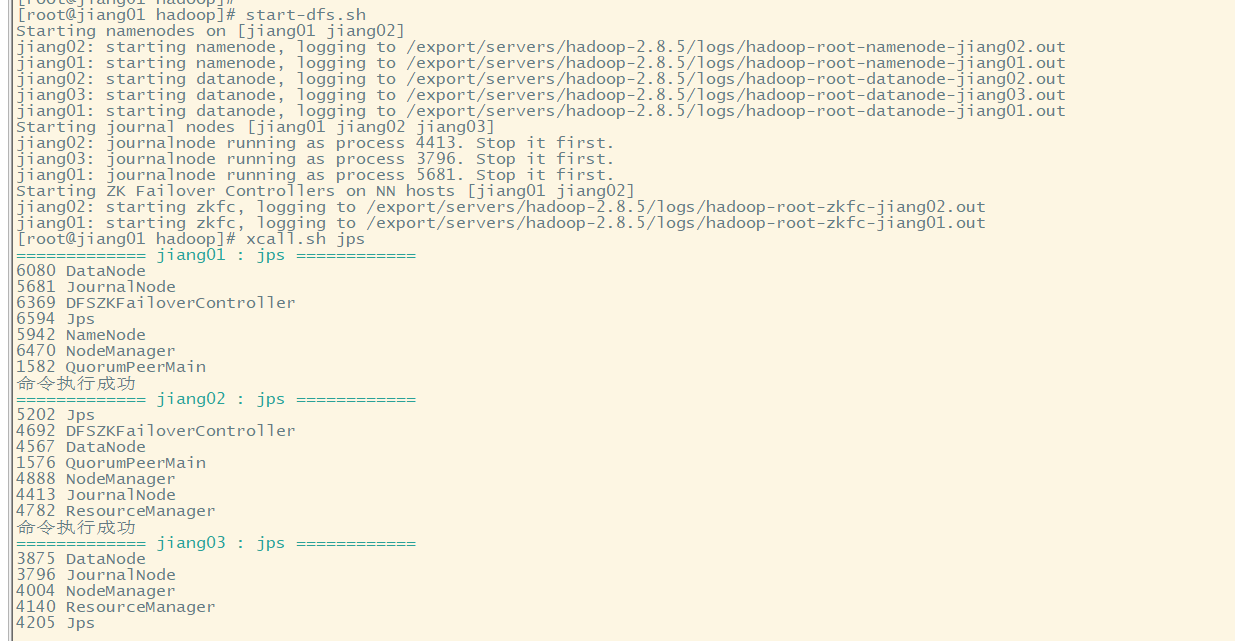
主節點上面啟動 dfs檔案系統:
[root@jiang01 dfs]# start-dfs.sh
jiang002啟動yarm
[root@jiang02 mapreduce]# start-yarn.shstarting yarn daemonsstarting resourcemanager, logging to /export/servers/hadoop-2.8.5/logs/yarn-root-resourcemanager-jiang02.outjiang03: starting nodemanager, logging to /export/servers/hadoop-2.8.5/logs/yarn-root-nodemanager-jiang03.outjiang01: starting nodemanager, logging to /export/servers/hadoop-2.8.5/logs/yarn-root-nodemanager-jiang01.outjiang02: starting nodemanager, logging to /export/servers/hadoop-2.8.5/logs/yarn-root-nodemanager-jiang02.out[root@jiang02 mapreduce]#View Code
jiang03啟動:resourcemanager
[root@jiang03 hadoopDatas]# yarn-daemon.sh start resourcemanagerstarting resourcemanager, logging to /export/servers/hadoop-2.8.5/logs/yarn-root-resourcemanager-jiang03.outView Code
hadoop wordcount程式啟動:
1 cd /export/servers/hadoop-2.8.5/share/hadoop/mapreduce/
2 生成資料檔案:
touch word.txtecho "hello world" >> word.txtecho "hello hadoop" >> word.txtecho "hello hive" >> word.txt
3 創建hadoop 檔案目錄
hdfs dfs -mkdir -p /work/data/input
4 向hadoop上傳資料檔案
hdfs dfs -put ./word.txt /work/data/input
5 計算例子
hadoop jar hadoop-mapreduce-examples-2.8.5.jar wordcount /work/data/input /work/data/output
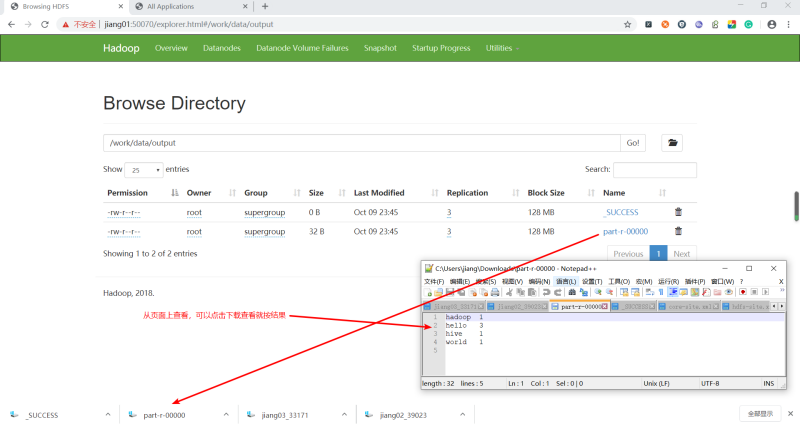
6 查看結果:
[root@jiang01 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.8.5.jar wordcount /work/data/input /work/data/output19/10/09 11:44:48 INFO input.FileInputFormat: Total input files to process : 119/10/09 11:44:48 INFO mapreduce.JobSubmitter: number of splits:119/10/09 11:44:48 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1570635804389_000119/10/09 11:44:48 INFO impl.YarnClientImpl: Submitted application application_1570635804389_000119/10/09 11:44:48 INFO mapreduce.Job: The url to track the job: http://jiang02:8088/proxy/application_1570635804389_0001/19/10/09 11:44:48 INFO mapreduce.Job: Running job: job_1570635804389_000119/10/09 11:45:00 INFO mapreduce.Job: Job job_1570635804389_0001 running in uber mode : false19/10/09 11:45:00 INFO mapreduce.Job: map 0% reduce 0%19/10/09 11:45:11 INFO mapreduce.Job: map 100% reduce 0%19/10/09 11:45:20 INFO mapreduce.Job: map 100% reduce 100%19/10/09 11:45:20 INFO mapreduce.Job: Job job_1570635804389_0001 completed successfully19/10/09 11:45:21 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=54 FILE: Number of bytes written=321397 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=139 HDFS: Number of bytes written=32 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=8790 Total time spent by all reduces in occupied slots (ms)=6229 Total time spent by all map tasks (ms)=8790 Total time spent by all reduce tasks (ms)=6229 Total vcore-milliseconds taken by all map tasks=8790 Total vcore-milliseconds taken by all reduce tasks=6229 Total megabyte-milliseconds taken by all map tasks=9000960 Total megabyte-milliseconds taken by all reduce tasks=6378496 Map-Reduce Framework Map input records=3 Map output records=6 Map output bytes=60 Map output materialized bytes=54 Input split bytes=103 Combine input records=6 Combine output records=4 Reduce input groups=4 Reduce shuffle bytes=54 Reduce input records=4 Reduce output records=4 Spilled Records=8 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=199 CPU time spent (ms)=1320 Physical memory (bytes) snapshot=325742592 Virtual memory (bytes) snapshot=4161085440 Total committed heap usage (bytes)=198316032 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=36 File Output Format Counters Bytes Written=32View Code
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/5537.html
標籤:其它
上一篇:〈四〉ElasticSearch的認識:基礎原理的補充
下一篇:關于SQL優化