匯入Maven依賴
<dependencies>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.6</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.2.5</version>
</dependency>
<!-- 使用mr程式操作hbase 資料的匯入 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.2.5</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.5</version>
</dependency>
<!-- phoenix 鳳凰 用來整合Hbase的工具 -->
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.6</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<!-- bind to the packaging phase -->
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
獲取hbase的連接,list出所有的表
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
/**
* Hbase的java客戶端連接hbase的時候,只需要連接zookeeper的集群
* 就可以找到你Hbase集群的位置
* 核心的物件:
* Configuration:HbaseConfiguration.create();
* Connection:ConnectionFactory.createConnection(conf);
* table:conn.getTable(TableName.valueOf("tb_b")); 對表進行操作 DML
* Admin:conn.getAdmin();操作Hbase系統DDL,對名稱空間等進行操作
*/
public class ConnectionDemo {
public static void main(String[] args) throws Exception {
//獲取到hbase的組態檔物件
Configuration conf = HBaseConfiguration.create();
//針對組態檔設定zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//創建hbase的連接物件
Connection conn = ConnectionFactory.createConnection(conf);
//獲取到操作hbase的物件
Admin admin = conn.getAdmin();
//呼叫api獲取到所有的表
TableName[] tableNames = admin.listTableNames();
//獲取到哪個命名空間下的所有的表
TableName[] doits = admin.listTableNamesByNamespace("doit");
for (TableName tableName : doits) {
byte[] name = tableName.getName();
System.out.println(new String(name));
}
conn.close();
}
}
獲取到所有的命名空間
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
/**
* Hbase的java客戶端連接hbase的時候,只需要連接zookeeper的集群
* 就可以找到你Hbase集群的位置
* 核心的物件:
* Configuration:HbaseConfiguration.create();
* Connection:ConnectionFactory.createConnection(conf);
* Admin:conn.getAdmin();操作Hbase系統DDL,對名稱空間等進行操作
*/
public class NameSpaceDemo {
public static void main(String[] args) throws Exception {
//獲取到hbase的組態檔物件
Configuration conf = HBaseConfiguration.create();
//針對組態檔設定zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//創建hbase的連接物件
Connection conn = ConnectionFactory.createConnection(conf);
//獲取到操作hbase的物件
Admin admin = conn.getAdmin();
//獲取到命名空間的描述器
NamespaceDescriptor[] namespaceDescriptors = admin.listNamespaceDescriptors();
for (NamespaceDescriptor namespaceDescriptor : namespaceDescriptors) {
//針對描述器獲取到命名空間的名稱
String name = namespaceDescriptor.getName();
System.out.println(name);
}
conn.close();
}
}
創建一個命名空間
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.protobuf.generated.HBaseProtos;
import java.util.Properties;
/**
* Hbase的java客戶端連接hbase的時候,只需要連接zookeeper的集群
* 就可以找到你Hbase集群的位置
* 核心的物件:
* Configuration:HbaseConfiguration.create();
* Connection:ConnectionFactory.createConnection(conf);
* Admin:conn.getAdmin();操作Hbase系統DDL,對名稱空間等進行操作
*/
public class CreateNameSpaceDemo {
public static void main(String[] args) throws Exception {
//獲取到hbase的組態檔物件
Configuration conf = HBaseConfiguration.create();
//針對組態檔設定zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//創建hbase的連接物件
Connection conn = ConnectionFactory.createConnection(conf);
//獲取到操作hbase的物件
Admin admin = conn.getAdmin();
//獲取到命名空間描述器的構建器
NamespaceDescriptor.Builder spaceFromJava = NamespaceDescriptor.create("spaceFromJava");
//當然還可以給命名空間設定屬性
spaceFromJava.addConfiguration("author","robot_jiang");
spaceFromJava.addConfiguration("desc","this is my first java namespace...");
//拿著構建器構建命名空間的描述器
NamespaceDescriptor build = spaceFromJava.build();
//創建命名空間
admin.createNamespace(build);
conn.close();
}
}
創建帶有多列族的表
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.protobuf.generated.TableProtos;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.Map;
import java.util.Set;
/**
* Hbase的java客戶端連接hbase的時候,只需要連接zookeeper的集群
* 就可以找到你Hbase集群的位置
* 核心的物件:
* Configuration:HbaseConfiguration.create();
* Connection:ConnectionFactory.createConnection(conf);
* Admin:conn.getAdmin();操作Hbase系統DDL,對名稱空間等進行操作
*/
public class CreateTableDemo {
public static void main(String[] args) throws Exception {
//獲取到hbase的組態檔物件
Configuration conf = HBaseConfiguration.create();
//針對組態檔設定zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//創建hbase的連接物件
Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin();
//獲取到操作hbase操作表的物件
TableDescriptorBuilder java = TableDescriptorBuilder.newBuilder(TableName.valueOf("java"));
//表添加列族需要集合的方式
ArrayList<ColumnFamilyDescriptor> list = new ArrayList<>();
//構建一個列族的構造器
ColumnFamilyDescriptorBuilder col1 = ColumnFamilyDescriptorBuilder.newBuilder("f1".getBytes(StandardCharsets.UTF_8));
ColumnFamilyDescriptorBuilder col2 = ColumnFamilyDescriptorBuilder.newBuilder("f2".getBytes(StandardCharsets.UTF_8));
ColumnFamilyDescriptorBuilder col3 = ColumnFamilyDescriptorBuilder.newBuilder("f3".getBytes(StandardCharsets.UTF_8));
//構建列族
ColumnFamilyDescriptor build1 = col1.build();
ColumnFamilyDescriptor build2 = col2.build();
ColumnFamilyDescriptor build3 = col3.build();
//將列族添加到集合中去
list.add(build1);
list.add(build2);
list.add(build3);
//給表設定列族
java.setColumnFamilies(list);
//構建表的描述器
TableDescriptor build = java.build();
//創建表
admin.createTable(build);
conn.close();
}
}
向表中添加資料
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.Arrays;
/**
* 注意:put資料需要指定往哪個命名空間的哪個表的哪個rowKey的哪個列族的哪個列中put資料,put的值是什么
*/
public class PutDataDemo {
public static void main(String[] args) throws Exception {
//獲取到hbase的組態檔物件
Configuration conf = HBaseConfiguration.create();
//針對組態檔設定zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//創建hbase的連接物件
Connection conn = ConnectionFactory.createConnection(conf);
Admin admin = conn.getAdmin();
//指定往哪一張表中put資料
Table java = conn.getTable(TableName.valueOf("java"));
//創建put物件,設定rowKey
Put put = new Put("rowkey_001".getBytes(StandardCharsets.UTF_8));
put.addColumn("f1".getBytes(StandardCharsets.UTF_8),"name".getBytes(StandardCharsets.UTF_8),"xiaotao".getBytes(StandardCharsets.UTF_8));
put.addColumn("f1".getBytes(StandardCharsets.UTF_8),"age".getBytes(StandardCharsets.UTF_8),"42".getBytes(StandardCharsets.UTF_8));
Put put1 = new Put("rowkey_002".getBytes(StandardCharsets.UTF_8));
put1.addColumn("f1".getBytes(StandardCharsets.UTF_8),"name".getBytes(StandardCharsets.UTF_8),"xiaotao".getBytes(StandardCharsets.UTF_8));
put1.addColumn("f1".getBytes(StandardCharsets.UTF_8),"age".getBytes(StandardCharsets.UTF_8),"42".getBytes(StandardCharsets.UTF_8));
Put put2 = new Put("rowkey_003".getBytes(StandardCharsets.UTF_8));
put2.addColumn("f1".getBytes(StandardCharsets.UTF_8),"name".getBytes(StandardCharsets.UTF_8),"xiaotao".getBytes(StandardCharsets.UTF_8));
put2.addColumn("f1".getBytes(StandardCharsets.UTF_8),"age".getBytes(StandardCharsets.UTF_8),"42".getBytes(StandardCharsets.UTF_8));
java.put(Arrays.asList(put,put1,put2));
conn.close();
}
}
get表中的資料
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import java.nio.charset.StandardCharsets;
/**
* 注意:put資料需要指定往哪個命名空間的哪個表的哪個rowKey的哪個列族的哪個列中put資料,put的值是什么
*/
public class GetDataDemo {
public static void main(String[] args) throws Exception {
//獲取到hbase的組態檔物件
Configuration conf = HBaseConfiguration.create();
//針對組態檔設定zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//創建hbase的連接物件
Connection conn = ConnectionFactory.createConnection(conf);
//指定往哪一張表中put資料
Table java = conn.getTable(TableName.valueOf("java"));
Get get = new Get("rowkey_001".getBytes(StandardCharsets.UTF_8));
// get.addFamily("f1".getBytes(StandardCharsets.UTF_8));
get.addColumn("f1".getBytes(StandardCharsets.UTF_8),"name".getBytes(StandardCharsets.UTF_8));
Result result = java.get(get);
boolean advance = result.advance();
if(advance){
Cell current = result.current();
String family = new String(CellUtil.cloneFamily(current));
String qualifier = new String(CellUtil.cloneQualifier(current));
String row = new String(CellUtil.cloneRow(current));
String value = https://www.cnblogs.com/paopaoT/p/new String(CellUtil.cloneValue(current));
System.out.println(row+","+family+","+qualifier+","+value);
}
conn.close();
}
}
scan表中的資料
package com.doit.day01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
import java.util.Iterator;
/**
* 注意:put資料需要指定往哪個命名空間的哪個表的哪個rowKey的哪個列族的哪個列中put資料,put的值是什么
*/
public class ScanDataDemo {
public static void main(String[] args) throws Exception {
//獲取到hbase的組態檔物件
Configuration conf = HBaseConfiguration.create();
//針對組態檔設定zk的集群地址
conf.set("hbase.zookeeper.quorum","linux01:2181,linux02:2181,linux03:2181");
//創建hbase的連接物件
Connection conn = ConnectionFactory.createConnection(conf);
//指定往哪一張表中put資料
Table java = conn.getTable(TableName.valueOf("java"));
Scan scan = new Scan();
scan.withStartRow("rowkey_001".getBytes(StandardCharsets.UTF_8));
scan.withStopRow("rowkey_004".getBytes(StandardCharsets.UTF_8));
ResultScanner scanner = java.getScanner(scan);
Iterator<Result> iterator = scanner.iterator();
while (iterator.hasNext()){
Result next = iterator.next();
while (next.advance()){
Cell current = next.current();
String family = new String(CellUtil.cloneFamily(current));
String row = new String(CellUtil.cloneRow(current));
String qualifier = new String(CellUtil.cloneQualifier(current));
String value = https://www.cnblogs.com/paopaoT/p/new String(CellUtil.cloneValue(current));
System.out.println(row+","+family+","+qualifier+","+value);
}
}
conn.close();
}
}
洗掉一行資料
package com.doit.day02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
public class _12_洗掉一行資料 {
public static void main(String[] args) throws IOException {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","linux01");
Connection conn = ConnectionFactory.createConnection(conf);
Table java = conn.getTable(TableName.valueOf("java"));
Delete delete = new Delete("rowkey_001".getBytes(StandardCharsets.UTF_8));
java.delete(delete);
}
}
資料存盤
行式存盤
傳統的行式資料庫將一個個完整的資料行存盤在資料頁中
列式存盤
列式資料庫是將同一個資料列的各個值存放在一起
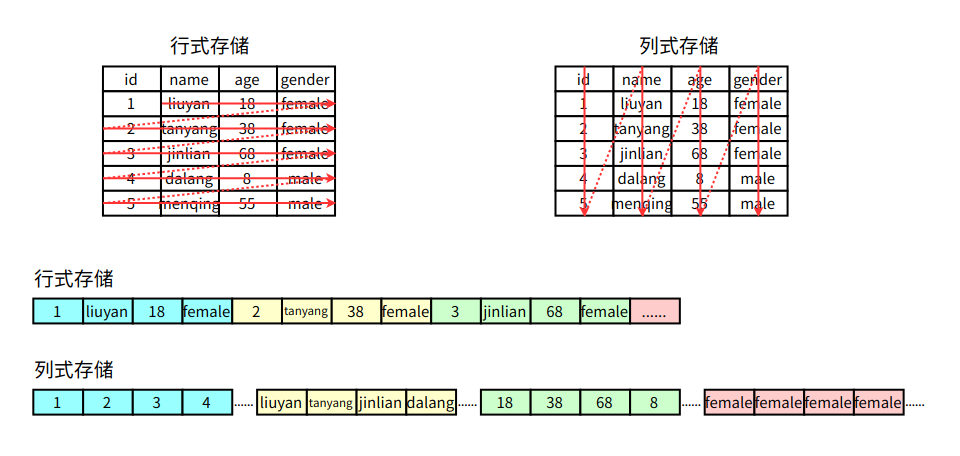
傳統行式資料庫的特性如下:
- 資料是按行存盤的,
- 沒有索引的查詢使用大量I/O,比如一般的資料庫表都會建立索引,通過索引加快查詢效率,
- 建立索引和物化視圖需要花費大量的時間和資源,
- 面對查詢需求,資料庫必須被大量膨脹才能滿足需求,
列式資料庫的特性如下:
- 資料按列存盤,即每一列單獨存放,
- 資料即索引,
- 只訪問查詢涉及的列,可以大量降低系統I/O,
- 每一列由一個執行緒來處理,即查詢的并發處理性能高,
- 資料型別一致,資料特征相似,可以高效壓縮,比如有增量壓縮、前綴壓縮演算法都是基于列存盤的型別定制的,所以可以大幅度提高壓縮比,有利于存盤和網路輸出資料帶寬的消耗,
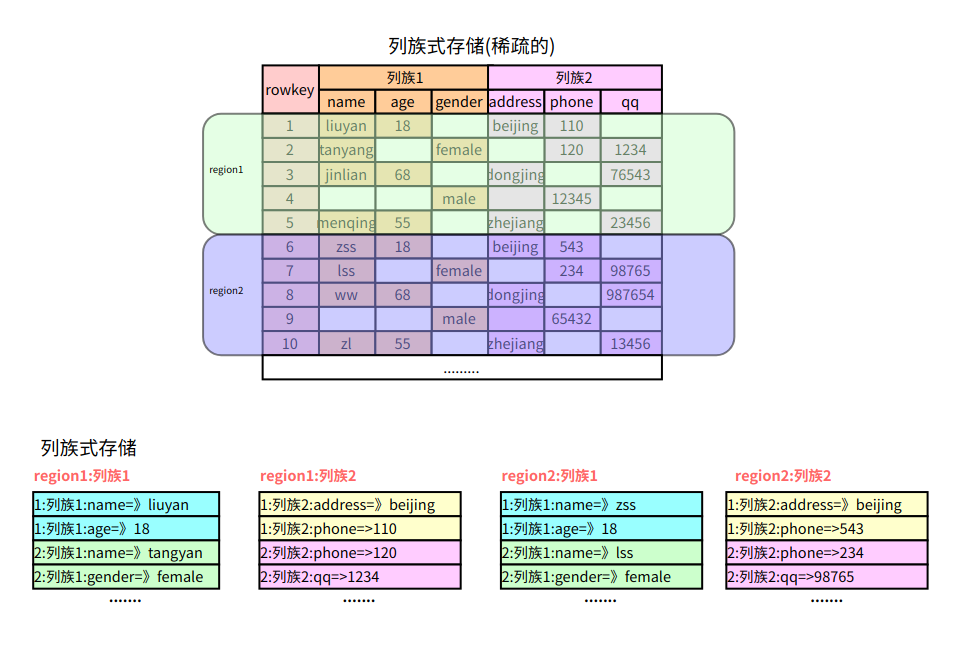
列族式存盤
列族式存盤是一種非關系型資料庫存盤方式,按列而非行組織資料,它的資料模型是面向列的,即把資料按照列族的方式組織,將屬于同一列族的資料存盤在一起,每個列族都有一個唯一的識別符號,一般通過列族名稱來表示,它具有高效的寫入和查詢性能,能夠支持極大規模的資料
- 如果一個表有多個列族, 每個列族下只有一列, 那么就等同于列式存盤,
- 如果一個表只有一個列族, 該列族下有多個列, 那么就等同于行式存盤.
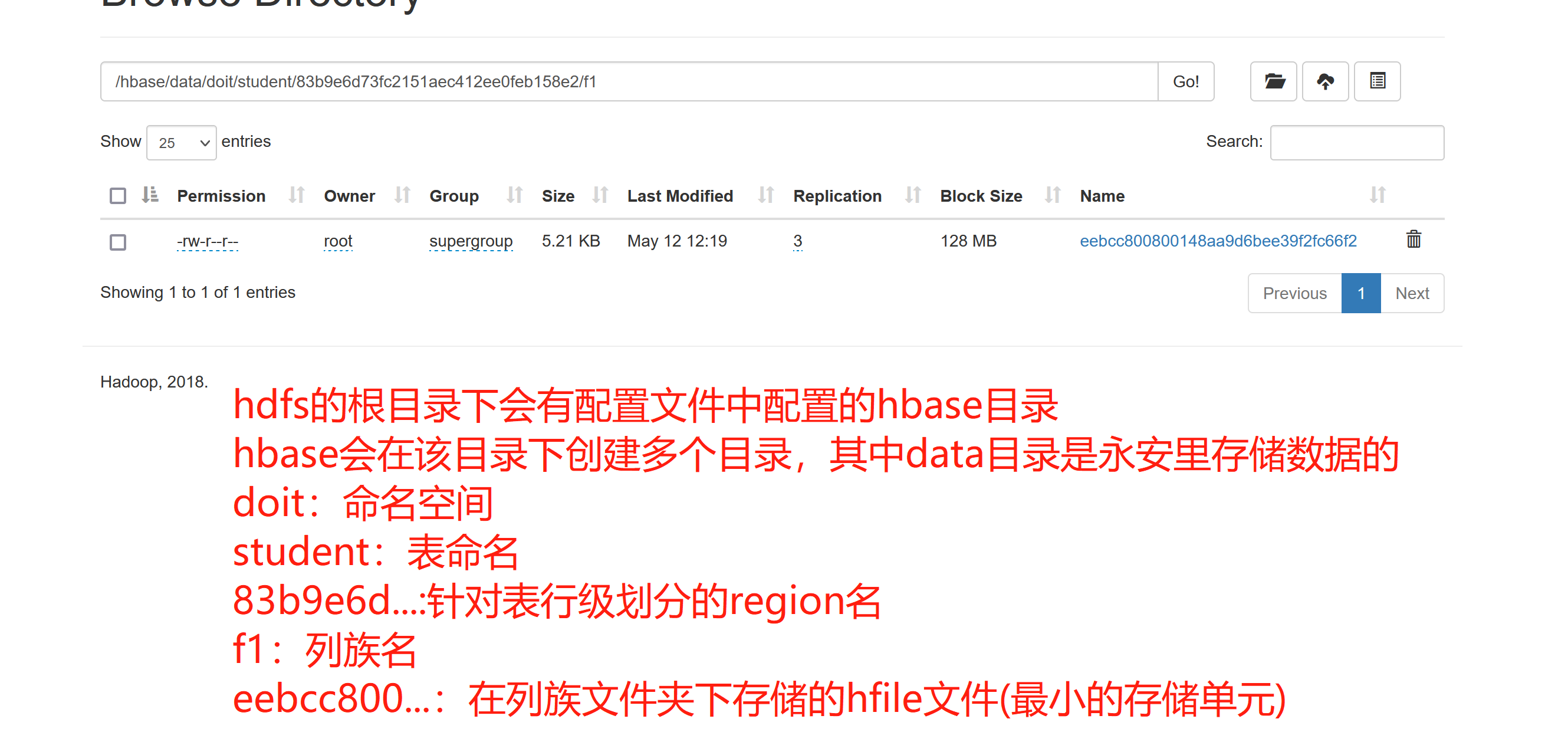
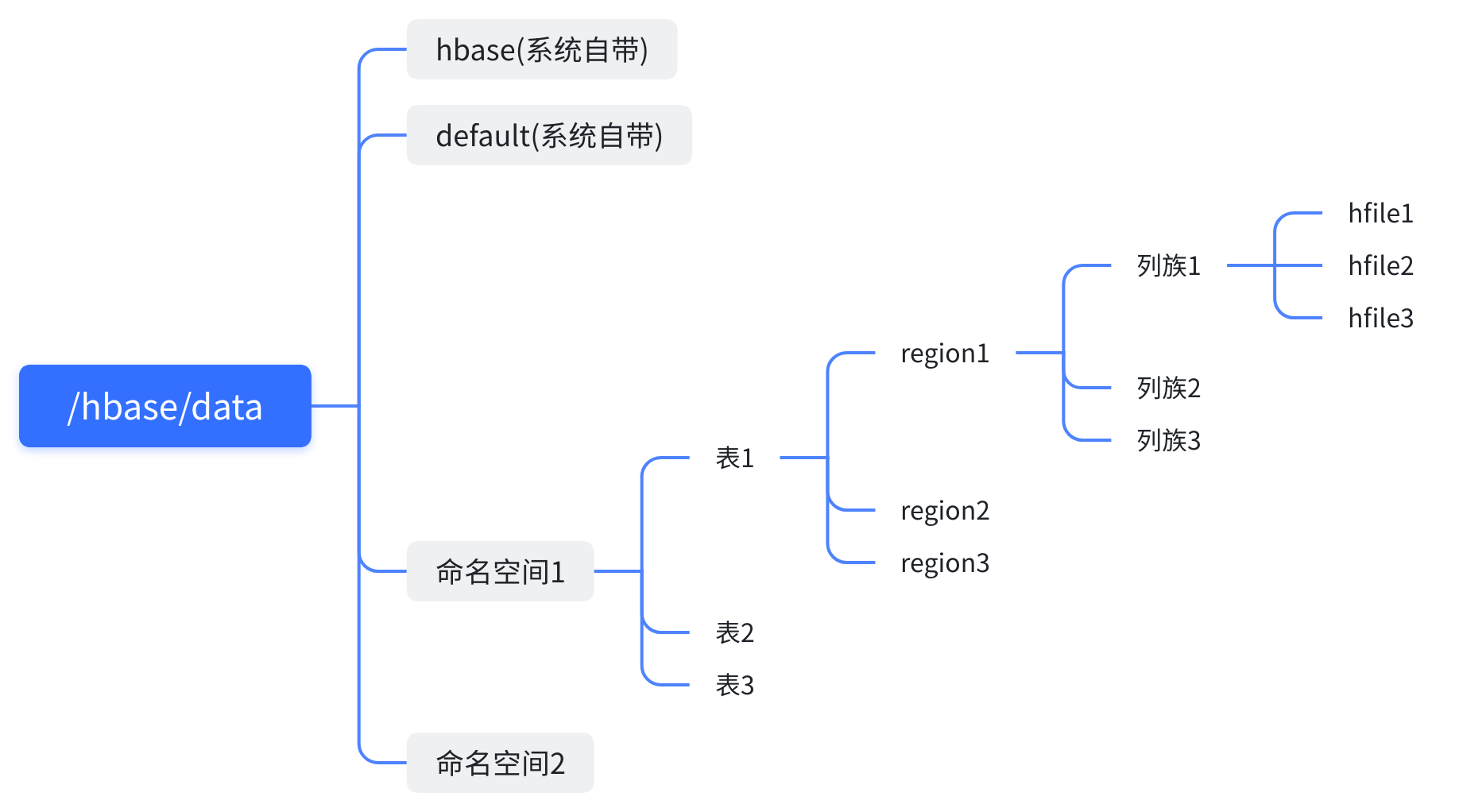
hbase的存盤路徑:
在conf目錄下的hbase-site.xml檔案中配置了資料存盤的路徑在hdfs上
<property>
<name>hbase.rootdir</name>
<value>hdfs://linux01:8020/hbase</value>
</property>
hdfs上的存盤路徑:
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/555023.html
標籤:大數據
下一篇:返回列表