各位看官大家好,今天給大家分享的又是一篇實戰文章,希望大家能夠喜歡,
目前「袋鼠云客戶資料洞察平臺」標簽服務的群組按種類劃分,可以分為三大類,分別是實時群組、動態群組以及靜態群組,如果按創建方式劃分則有兩種,分別是通過圈群的方式創建以及通過上傳本地檔案進行維度匹配的方式創建得到本地群組,其中本地群組屬于靜態群組,
除了本地群組外的其他群組目前都是采用圈群的方式生成匹配 SQL,然后執行相應的 SQL 得到相應查詢維度的資料并入庫到群組表,這種方式比較方便,可以快速得到一個用戶期望的群組,
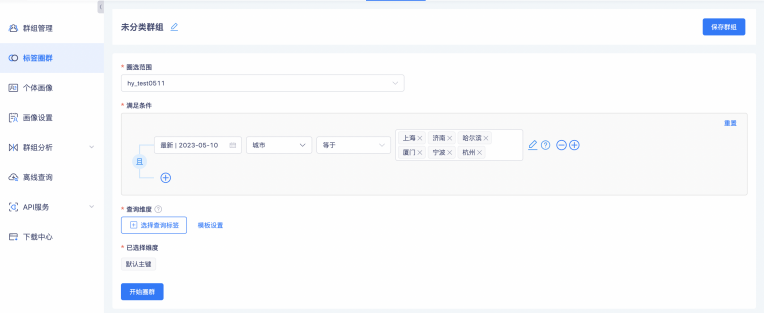
但是有那么一種場景,假設想要設定的條件很分散,通過圈群配置的時候比較復雜,那么只能通過上傳檔案的方式進行匹配,這就需要用戶上傳本地檔案,通過指定匹配維度的方式來生成本地群組,
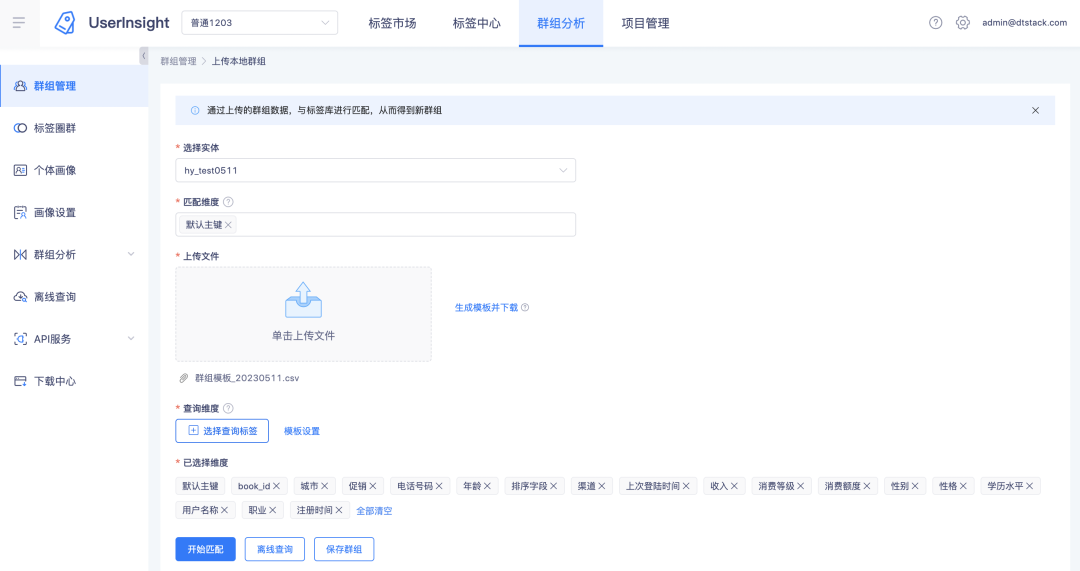
如果用戶上傳的本地檔案很小,那么比較簡單,按單個檔案直接上傳決議即可,如果用戶上傳的檔案很大,有50M,那么就需要采用分片的方式進行上傳,本文和大家分享一下這兩種檔案上傳的代碼實作,
小檔案上傳的實作
小檔案上傳的主要流程包括將檔案上傳到服務器,并獲得檔案的編碼格式,檔案上傳完畢后,異步決議檔案并得到本地群組,
將檔案上傳到 HDFS 并保存原始檔案到 SFTP,上傳到 HDFS 之后,通過 SQL 來與物體對應的大寬表進行資料匹配,最終生成本地群組,

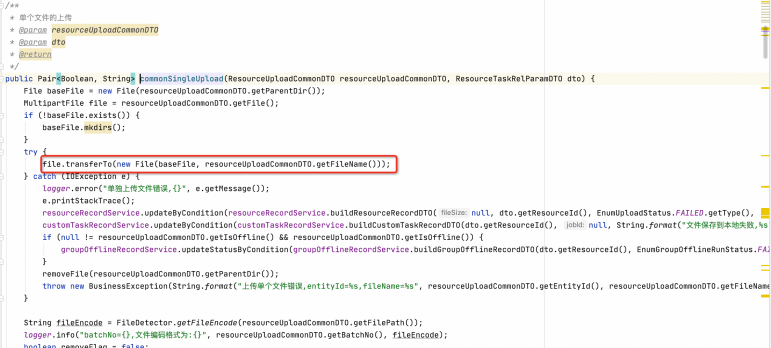
小檔案直接上傳即可,代碼如下,上傳完成后,獲取檔案的編碼格式,用于后續的檔案決議,
大檔案上傳的實作
前端將大檔案按指定大小分片,并計算原始檔案的 md5 和每個分片檔案的 md5,分別用于檔案校驗以及分片檔案斷點續傳,介面入參代碼設計如下:

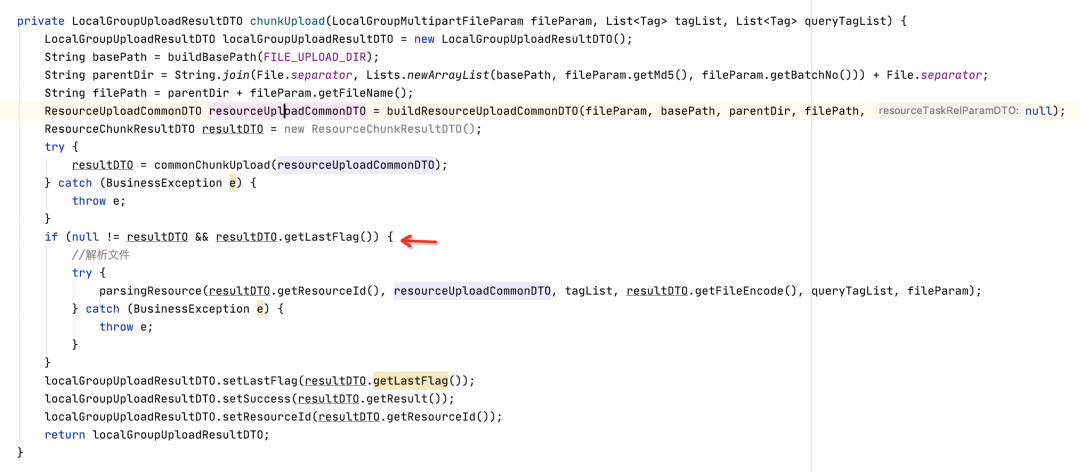
大檔案分片實作部分核心代碼如下:
分片檔案重新在服務器整合為一個大檔案的整體代碼如下:
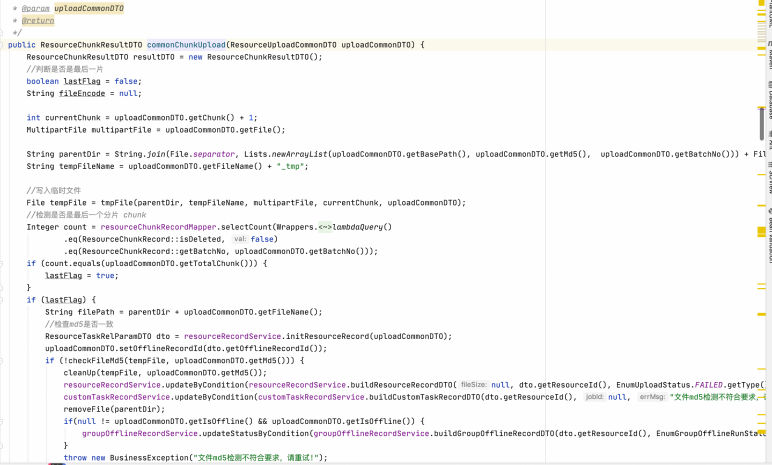

單個分片的資料接收并寫入代碼如下:

當檢測到上傳的檔案是最后一個分片檔案的時候,待分片資料寫入完成后,需要對服務器上的檔案進行 md5 校驗來保證檔案資料的一致性,
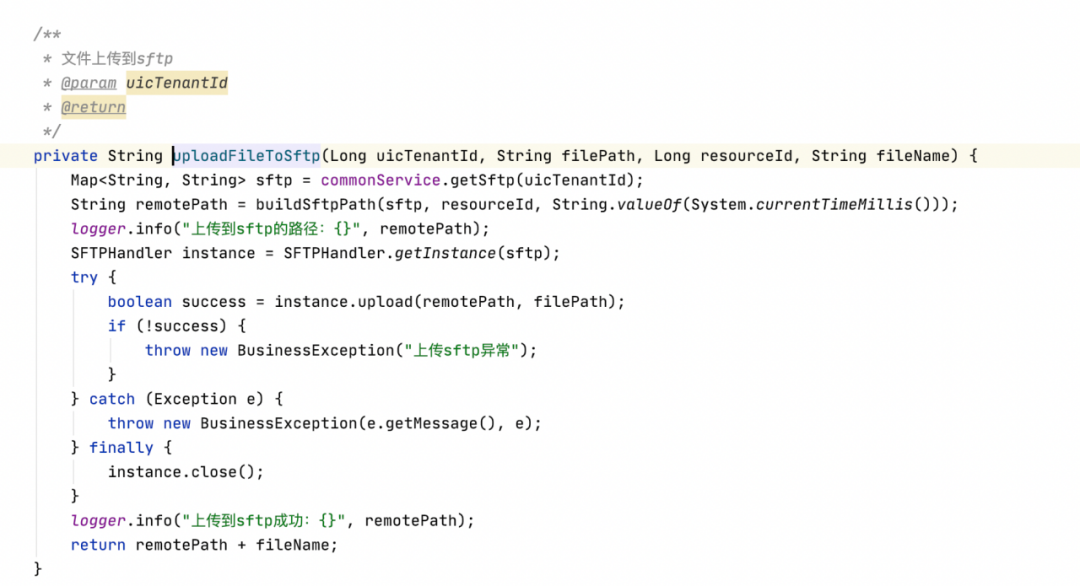
當檔案上傳到服務器完成后,需要將檔案上傳到 HDFS 以及SFTP,代碼如下:

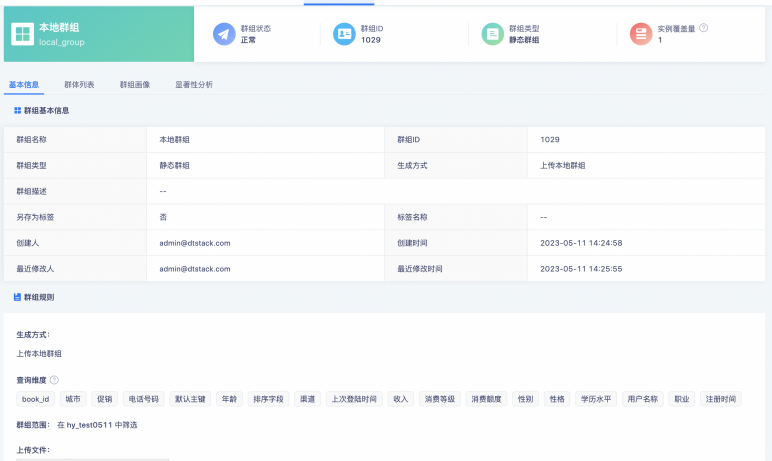
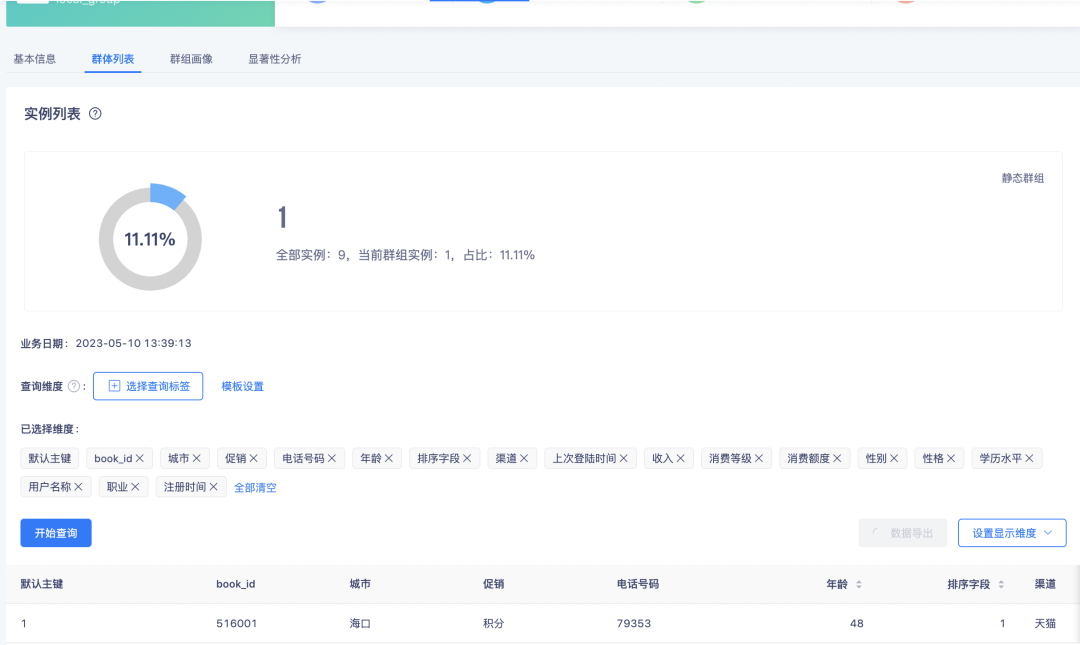
最終得到的本地群組如下:
《數堆疊產品白皮書》:https://www.dtstack.com/resources/1004?src=https://www.cnblogs.com/DTinsight/archive/2023/06/14/szsm
《資料治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=https://www.cnblogs.com/DTinsight/archive/2023/06/14/szsm
想了解或咨詢更多有關袋鼠云大資料產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠云官網:https://www.dtstack.com/?src=https://www.cnblogs.com/DTinsight/archive/2023/06/14/szbky
同時,歡迎對大資料開源專案有興趣的同學加入「袋鼠云開源框架釘釘技術qun」,交流最新開源技術資訊,qun號碼:30537511,專案地址:https://github.com/DTStack
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/555229.html
標籤:其他
下一篇:返回列表