Apache Hudi 是一款開源的資料湖解決方案,它能夠幫助企業更好地管理和分析海量資料,支持高效的資料更新和查詢,并提供多種資料壓縮和存盤格式以及索引功能,從而為企業資料倉庫實踐提供更加靈活和高效的資料處理方式,
在金融領域,企業可以使用 Hudi 來處理大量需要實時查詢和更新的金融交易資料,在電商業務中,企業可以使用 Hudi 來跟蹤訂單資料,以及對訂單進行實時更新和查詢,在物流和供應鏈管理中,Hudi 可以幫助企業實時處理和更新大量的物流資料,保證資料的一致性和可靠性,
作為一站式大資料基礎軟體的袋鼠云數堆疊,基于 Apache Hudi 為客戶提供了存量資料遷移、資料入湖、檔案治理等完整支持能力,在這個程序中,積累了一些 Hudi 性能優化的經驗,希望通過本文與大家分享交流,
Hudi 原理簡析
Apache Hudi 是一個開源的資料湖解決方案,它是基于 Hadoop 和 Spark 的技術堆疊構建而成,并且拓展到了 Flink、 Trino 等多種計算引擎,Apache Hudi 的主要目的是提供一個高效、可擴展且可靠的資料湖解決方案,用于管理和處理大規模的資料集,
Hudi 的核心實作是通過將資料集合劃分為多個資料檔案,并為每個資料檔案維護一個資料版本和索引資訊,來支持增量資料更新和查詢操作,如下圖所示,當用戶需要對資料進行更新時,Hudi 會將更新的資料寫入一個新的資料檔案中,并通過寫時復制(copy-on-write)操作,將原始資料檔案中的資料記錄復制到新的資料檔案中,并在新的資料檔案中更新對應的資料記錄,
同時,Hudi 會更新資料版本和索引資訊,以便用戶可以根據資料版本和唯一識別符號來訪問最新的資料記錄,當用戶需要查詢資料時,Hudi 會使用索引資訊來定位資料記錄,并回傳最新的資料記錄,
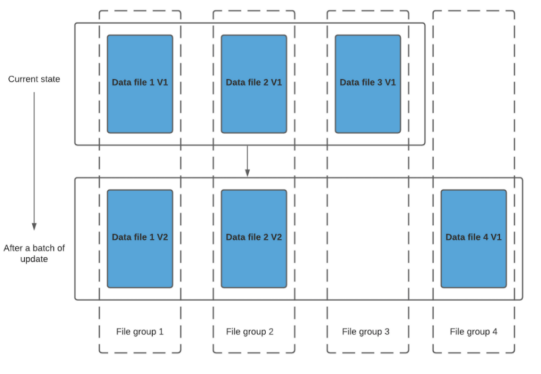
在 Hudi 的 merge on read 模式中,更新操作是通過在查詢時將原始資料和更新資料進行合并來實作的,具體來說,當有新的資料要被寫入時,Hudi 會將新資料追加寫入到一個新的日志檔案中,并在元資料檔案中記錄新檔案的資訊,當查詢資料時,Hudi 會將所有資料檔案進行合并,生成一個視圖,然后對視圖進行查詢,
由于 Hudi 只需要在查詢時將需要更新的資料進行合并,而不需要在寫入時進行合并,因此可以避免寫入時的性能開銷,從而實作快速的更新操作,
Apache Hudi 在寫入資料時創建一個新版本,而讀取資料時通過將所有版本的資料進行合并來生成一個視圖,在視圖中,每個資料記錄只出現一次,并且是最新的版本,這樣可以保證讀操作只會涉及到視圖中的資料,而不會對原始資料進行修改,從而實作了讀寫分離,
通過多版本實作并發控制,Hudi 可以在保證資料一致性的前提下,提高讀操作的性能,同時也保證了資料的可靠性和可擴展性,
Hudi 優化實踐
下面介紹基于袋鼠云數堆疊的實踐經驗,所做的 Hudi 性能優化,
支持多索引
Hudi 將資料集合劃分為多個資料檔案,并為每個資料檔案維護一個資料版本和索引資訊,來支持增量資料更新和查詢操作,通過構建索引就可以利用生成的元資料快速定位查詢所需資料的位置,如下圖所示,這樣可以減少甚至避免從檔案系統中掃描或者讀取不必要的資料,減少 IO 的開銷,大大提升查詢效率,Hudi 已經支持幾種不同的索引技術,并且還在不斷地改進和添加更多的索引實作,
袋鼠云數堆疊支持用戶在創建 Hudi 表時就設定想要使用的索引型別,包括 SIMPLE、BLOOM FILTER、BUCKET 等型別,在寫入程序中,Hudi 會將索引資訊寫入到 parquet 檔案或者外部存盤中,在讀取時應用程式根據這些資訊進行比較判斷,跳過不必要的資料檔案,
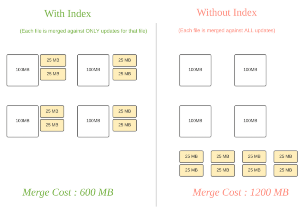
Hudi 在0.11.0版本引入了 MetadataTable 這種多模式索引,利用 MetadataTable 匯總元資料資訊,應用程式可以避免檔案系統呼叫檔案 Listing 操作(這在物件存盤中是非常耗時的),還可以避免直接讀取 parquet 檔案中的 footer 資訊,能夠大幅提升查詢性能,
袋鼠云數堆疊支持用戶在建表時就開啟多模式索引,在寫入資料的同時將檔案的索引資訊也寫入 MetadataTable,數堆疊還支持以異步的方式構建 MetadataTable,保證寫入仍然處于低延遲的狀態,再由后臺的應用程式離線生成 MetadataTable 以提升讀取性能,
由于 MetadataTable 依賴 base 檔案記錄的 column stats/bloomfilter 等資訊,因此 merge on read 模式下沒有辦法將 log 檔案的資訊保存到 MetadataTable 中,開源框架上沒有利用它實作進行檔案過濾,
但考慮到 base 檔案和 log 檔案共用相同的 fileId,袋鼠云技術團隊在數堆疊內部進行了改造:通過 MetadataTable 獲取到 base 檔案之后,再根據 fileId 進行 log 檔案過濾,避免不必要讀取,經過驗證,這種改動能夠使得 merge on read 模式具備和 copy on write 模式相同的過濾效果,
優化檔案布局
在大資料存盤中,檔案布局優化是一種重要的性能優化技術,其主要目的是在資料寫入時將資料按照一定的規則布局到存盤介質中,以提高資料讀取和處理的效率,檔案布局優化可以采用多種方式,如時間戳排序、磁區排序和合并檔案等方式,
Hudi 提供了一種名為 Clustering 的檔案布局優化方法,可以借此將小檔案合并成較大的檔案以減少查詢引擎需要掃描的檔案總數,或者利用空間填充曲線之類的概念來適應資料湖布局并減少查詢讀取的資料量,利用 Clustering,可以將具有相同查詢特征的資料放到相鄰的幾個檔案內,在查詢時再根據索引資訊進行過濾,能夠有效減少需要讀取的檔案數量,降低計算成本,
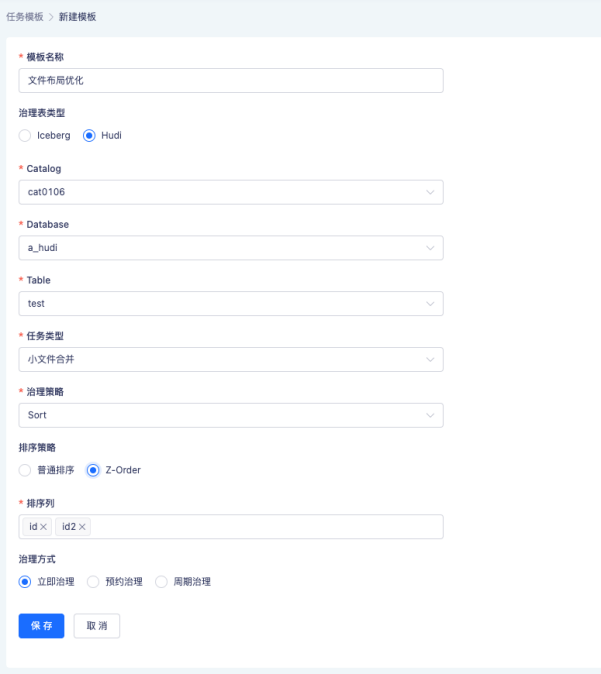
袋鼠云數堆疊提供了可視化頁面以方便用戶對檔案布局進行調整,用戶可以根據需要自由設定排序策略、排序欄位、過濾條件等,如下圖所示,應用程式會周期性地在后臺根據配置對檔案進行優化,因為 Hudi 采用多版本組織檔案,用戶不需要擔心優化任務會影響正在運行的讀取任務,在優化完成后新的讀取任務即可享受到新的布局帶來的效率提升,
探索新特性
在落地 Hudi 的程序中,袋鼠云數堆疊也在積極跟蹤實踐社區的新功能新特性,
在 Hudi 0.13.0 中,Hudi 實作了“優化記錄負載處理”的特性,通過設定 hoodie.datasource.write.record.merger.impls=org.apache.hudi.HoodieSparkRecordMerger 和 hoodie.logfile.data.block.format=parquet 兩個引數避免了額外的復制和反序列化,在寫入操作的整個生命周期內以統一的方式處理記錄,
袋鼠云數堆疊測驗和引入了這項特性,經過驗證,更新性能相比上一版本有了約20%的提升,符合社區的描述,另外,數堆疊還參考了 Hudi 0.13.0 引入的 disruptor 無鎖訊息佇列寫入資料的新特性,通過設定 hoodie.write.executor.type = DISRUPTOR 和 hoodie.write.executor.disruptor.wait.strategy = BUSY_SPIN_WAIT 引數,結合前述的優化配置,更新性能整體提升了30%以上,
總結
Apache Hudi 的優勢在于支持增量資料處理,具有良好的資料一致性和可靠性,同時提供多種性能優化技術,能夠提高資料處理和查詢的效率,具有良好的性能和可擴展性,
袋鼠云數堆疊團隊在落地 Hudi 的程序中,驗證了 Hudi 的多種索引,應用了檔案組織優化功能,總結了常用的調優引數,為推動企業資料湖建設,提供可靠、高效、可擴展的資料湖解決方案積累了不少經驗,能夠幫助企業更好地管理和分析資料,提高業務決策的精度和效率,
《數堆疊產品白皮書》:https://www.dtstack.com/resources/1004?src=https://www.cnblogs.com/DTinsight/p/szsm
《資料治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=https://www.cnblogs.com/DTinsight/p/szsm
想了解或咨詢更多有關袋鼠云大資料產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠云官網:https://www.dtstack.com/?src=https://www.cnblogs.com/DTinsight/p/szbky
同時,歡迎對大資料開源專案有興趣的同學加入「袋鼠云開源框架釘釘技術qun」,交流最新開源技術資訊,qun號碼:30537511,專案地址:https://github.com/DTStack
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/555795.html
標籤:大數據
上一篇:ClickHouse(14)ClickHouse合并樹MergeTree家族表引擎之VersionedCollapsingMergeTree詳細決議
下一篇:返回列表