我有一個這樣的資料框:
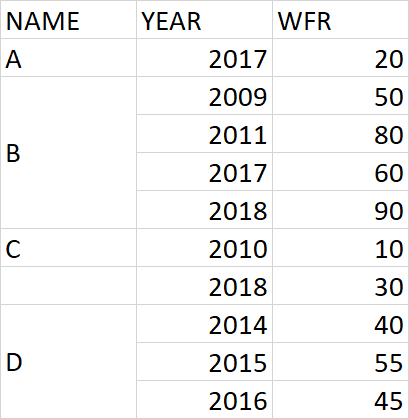
我想為每個 NAME 取 2009-2015 年之間的 WFR 平均值,并將其用于每個 NAME 的所有年份。任何的想法?謝謝
如何設定
data = {'NAME': ['A', 'B', 'B', 'B', 'B', 'C', 'C', 'D', 'D', 'D'],
'YEAR': [2017, 2009, 2011, 2017, 2018, 2010, 2018, 2014, 2015, 2016],
'WFR': [20, 50, 80, 60, 90, 10, 30, 40, 55, 45]}
df = pd.DataFrame(data)
uj5u.com熱心網友回復:
groupby_mean在過濾器年份之后使用然后映射每個名稱的平均值:
tmp = df.loc[df['YEAR'].between(2009, 2015)].groupby('NAME')['WFR'].mean()
df['MEAN'] = df['NAME'].map(tmp)
輸出:
>>> df
NAME YEAR WFR MEAN
0 A 2017 20 NaN
1 B 2009 50 65.0
2 B 2011 80 65.0
3 B 2017 60 65.0
4 B 2018 90 65.0
5 C 2010 10 10.0
6 C 2018 30 10.0
7 D 2014 40 47.5
8 D 2015 55 47.5
9 D 2016 45 47.5
>>> tmp
NAME
B 65.0
C 10.0
D 47.5
Name: WFR, dtype: float64
設定:
data = {'NAME': ['A', 'B', 'B', 'B', 'B', 'C', 'C', 'D', 'D', 'D'],
'YEAR': [2017, 2009, 2011, 2017, 2018, 2010, 2018, 2014, 2015, 2016],
'WFR': [20, 50, 80, 60, 90, 10, 30, 40, 55, 45]}
df = pd.DataFrame(data)
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/350811.html
上一篇:根據一行值洗掉多行