我正在處理 csv 檔案。
我想創建一個連續更新的序列平均值。前任;
我想輸出串列中每個單獨值的平均值
list; [a, b, c, d, e, f]
formula:
(a)/1= ?
(a b)/2=?
(a b c)/3=?
(a b c d)/4=?
(a b c d e)/5=?
(a b c d e f)/6=?
展示:
如果我有一個清單; [1, 4, 7, 4, 19]
我的輸出應該是; [1, 2.5, 4, 4, 7]
解釋;
(1)/1=1
(1 4)/2=2.5
(1 4 7)/3=4
(1 4 7 4)/4=4
(1 4 7 4 19)/5=7
至于我的python檔案,它是一個簡單的代碼:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('somecsvfile.csv')
x = [] #has to be a list of 1 to however many rows are in the "numbers" column, will be a simple [1, 2, 3, 4, 5] etc...
#x will be used to divide the numbers selected in y to give us z
y = df[numbers]
z = #new dataframe derived from the continuous average of y
plt.plot(x, z)
plt.show()
如果需要 numpy,那沒問題。
uj5u.com熱心網友回復:
您可以使用cumsum獲取累積總和,然后除以獲取運行平均值。
x = np.array([1, 4, 7, 4, 19])
np.cumsum(x)/range(1,len(x) 1)
print (z)
輸出:
[1. 2.5 4. 4. 7. ]
uj5u.com熱心網友回復:
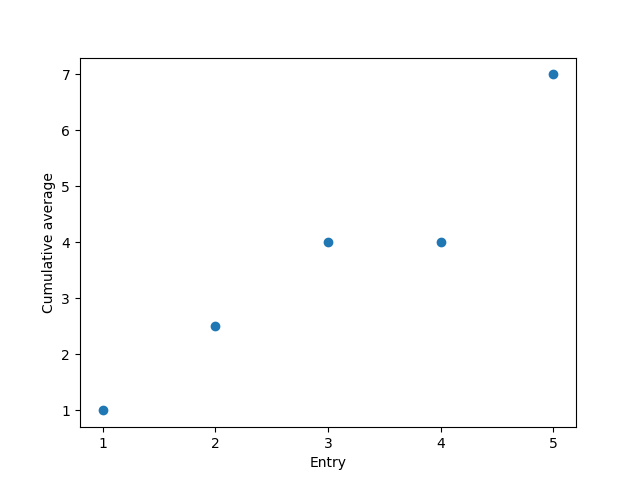
但正如奧古斯托所指出的,您也可以將整個內容放入DataFrame. 為他的方法添加更多內容:
n = [1, 4, 7, 4, 19]
df = pd.DataFrame(n, columns = ['numbers',])
#augment the index so it starts at 1 like you want
df.index = np.arange(1, len(df) 1)
# create a new column for the cumulative average
df = df.assign(cum_avg = df['numbers'].expanding().mean())
# numbers cum_avg
# 1 1 1.0
# 2 4 2.5
# 3 7 4.0
# 4 4 4.0
# 5 19 7.0
# plot
df['cum_avg'].plot(linestyle = 'none',
marker = 'o',
xticks = df.index,
xlabel = 'Entry',
ylabel = 'Cumulative average')
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/366859.html
標籤:Python 熊猫 文件 matplotlib