簡介: 由阿里云云效主辦的2021年第3屆83行代碼挑戰賽已經收官,超2萬人圍觀,近4000人參賽,85個團隊組團來戰,大賽采用游戲闖關玩兒法,融合元宇宙科幻和劇本殺元素,讓一眾開發者玩得不亦樂乎,
其中大賽第二題,號稱魔鬼演算法題,攔住諸多代碼好漢,
我們請來了第二題的出題人,劉力華(阿里云云效代碼平臺),為大家系統揭秘,從設計到攻略,還有優秀代碼決議供大家參考,
賽題設計
我設計的第二關是希望能考察參賽者的基礎演算法、資料結構的能力,
設計來源
本賽題采用的是字串前綴匹配演算法,引數者需要先通過OSS獲取待匹配的資料集,然后參賽者需要從中找出與指定前綴字串相匹配的字串資料,為什么會選擇該演算法呢?源于近期我在使用我們自己的開發插件時,它能夠當我在代碼搜索的輸入框中輸入Java API關鍵詞時,可以自動提供API名稱的補全提示,受該功能模塊啟發,因此希望設計一個題目讓參賽者實作一個Java API名稱的前綴匹配演算法,
此處打個廣告:我們的插件是阿里云智能編碼插件,現已上架JetBrains插件市場,可以在IntelliJ IDEA中通過搜索Alibaba Cloud AI Coding Assistant下載使用,插件包含了代碼智能補全及代碼示例搜索功能,讓開發者更快速、行云流水的完成編碼,
整個賽題的設計難點在于如何讓本賽題具備一定的挑戰性,但又保證一定的通關率,該賽題在外部題庫有類似的演算法題,屬于中等難度,所以中等難度能提高一定的通過率,為了避免參賽者通過Java的String.startsWith及雙回圈就直接通過,所以增大了評測的資料量,但是為了控制賽題難度,評測的資料集分為幾十萬的小資料集以及幾百萬的大資料集,只要能較好的解決小資料集問題,就能通過該賽題,
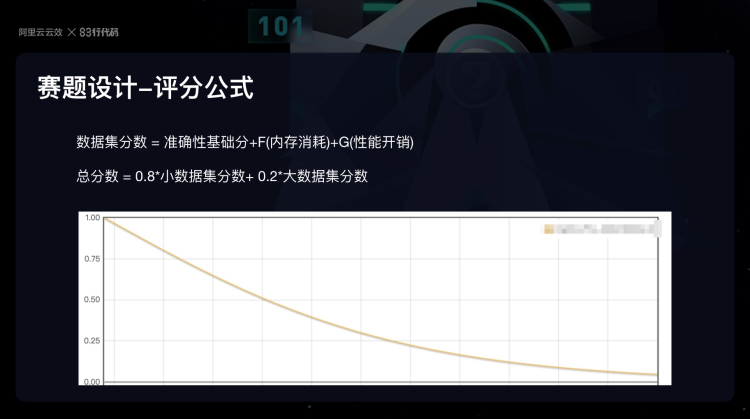
評分系統
本賽題的打分系統基于函式計算設計,系統會隨機選擇一個小規模資料集和一個大規模資料集,并依次串行運行參賽者的代碼,并針對這兩個資料集對參賽者撰寫的代碼從準確性、性能開銷、記憶體消耗維度進行評估,
賽題攻略
OSS資料獲取
本賽題的資料集存盤在OSS中,所以需要參賽者通過OSS的SDK進行資料的獲取,參賽者可以通過代碼注釋中的檔案鏈接去學習OSS SDK如何使用,也可以通過近期發布的阿里云智能編碼插件(Cosy)快速查看OSS SDK的示例代碼,
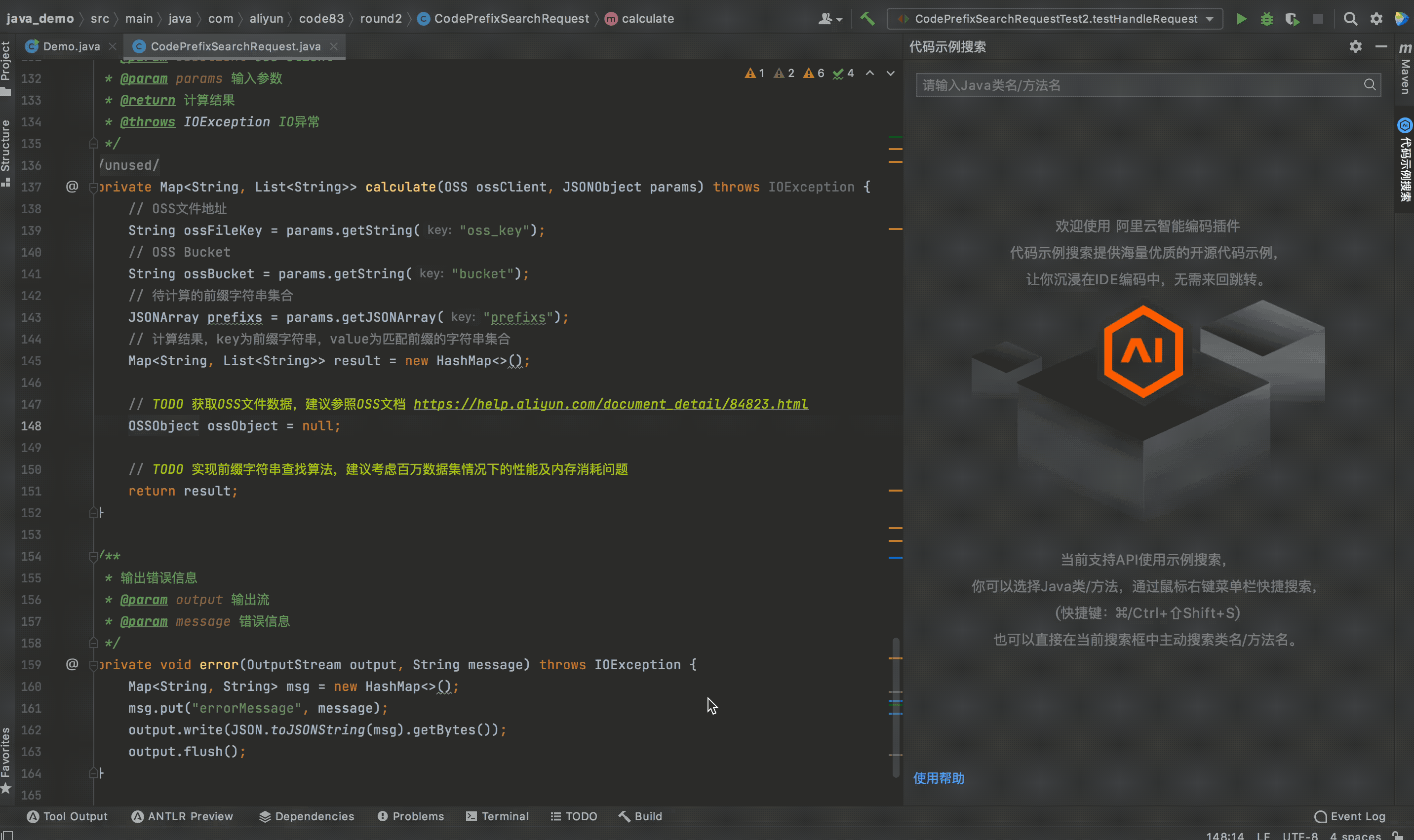
如上圖所示,如果參賽者想知道OSSObject的資料如何獲取,可以在該API上右鍵點擊“查看代碼示例”,智能編碼插件就能快速查找出實作OSS資料獲取相關的代碼示例,參賽者只需要選擇性復制并修改部分代碼即可,
此外,開發者也能通過代碼智能補全功能,通過選擇整行的代碼補全結果,快速的撰寫出獲取OSS資料的代碼,如下圖所示,

演算法攻略
該賽題的解題方法是比較多樣化的,參賽者采用的方法主要分為以下幾種,
第一種:自己實作演算法及資料結構
賽題攻略中提到了Trie Tree,一個較為基礎的資料結構,一個較好的Trie Tree也能夠通關本賽題,但是Trie Tree的性能開銷及記憶體消耗也都是比較大的,可以考慮Trie Tree的諸多變種,比如Double Array Trie,用雙陣列去節省空間,比如Radix Tree及其諸多變種,通過減少樹的深度去壓縮Trie Tree的記憶體占用,為了對比各種Trie Tree實作的效果,這里參考《MergedTrie: Efficient textual indexing》論文的相關評測資料,



還有很多參賽者通過減少雙層回圈的次數、減少前綴匹配的性能開銷等方法,也同樣獲得了較高的分數,
第二種,使用JDK內置的資料結構
JDK內置資料結構的性能也是比較高的,部分參賽者使用了TreeSet進行排序,然后通過用subSet方法就能直接獲取匹配的前綴字串資料,該方式比較簡單快捷,且代碼量較小,
參賽代碼SHOW
參賽者對本賽題的解法諸多,由于篇幅限制,本文章只展示四位參賽者的代碼片段,
參賽者代碼片段一
該解法通過String.substring方法去截取字串不同長度的前綴,并將截取的前綴直接從result的Map中進行查找,該方法無需像String.startsWith逐一進行字符的比較,所以效率會有較大提升,使用這種解法的參賽者比較多,還有部分參賽者會對截取的長度進行限制,比如事先統計前綴字串的最短及最長的長度,只需遍歷生成該長度范圍內的前綴即可,
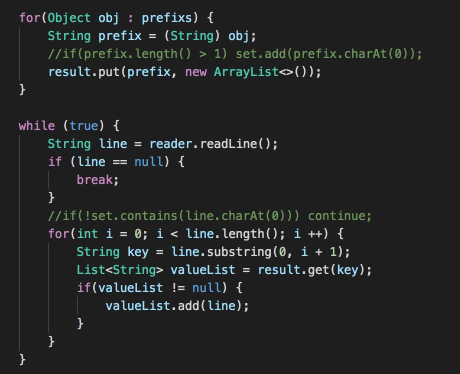
參賽者代碼片段二
該解法會先排除超出前綴字串最短及最長長度范圍的資料,然后對資料集進行排序,隨后遍歷待匹配的前綴字串串列,為每個前綴字串通過二分查找計算資料集中,與其匹配位置的陣列上界及下界,然后將該范圍內的資料抽取出來即可,

參賽者代碼片段三
該解法與排序方法類似,使用了JDK內置的TreeSet進行排序,然后通過TreeSet.subSet方法截取與前綴字串匹配的資料,
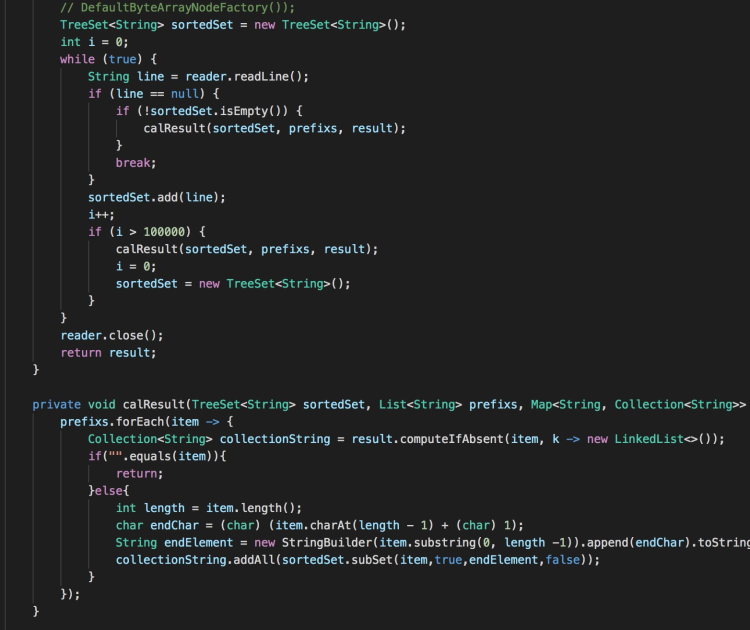
部分參賽者為了提高挑戰性,放棄使用TreeSet,自己實作了相關的排序及查找方法
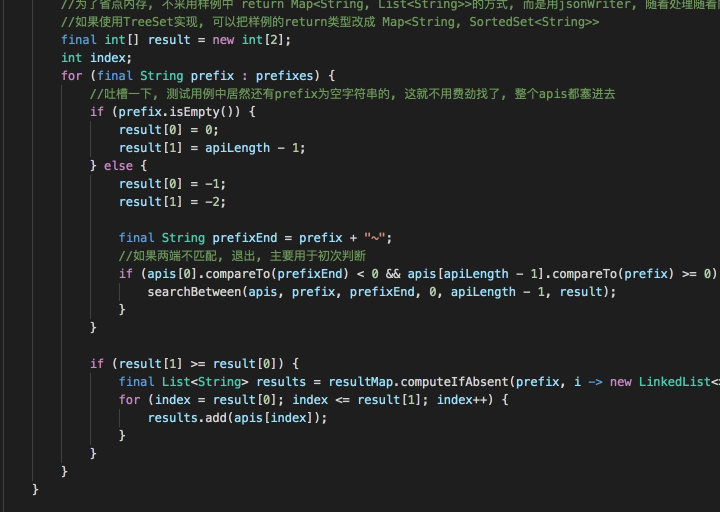
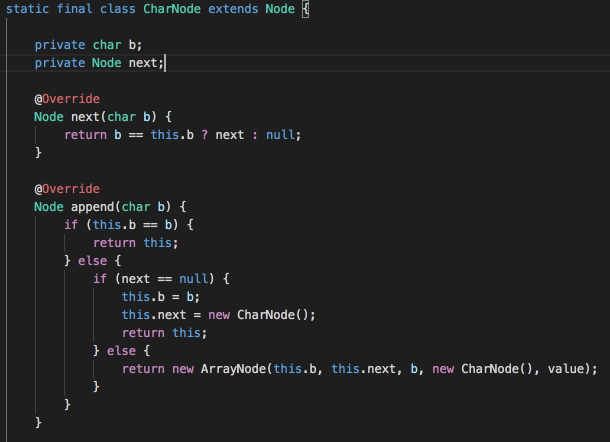
參賽者代碼片段四
這是排名第一的參賽者的代碼,該參賽者對Trie樹進行了優化,使用CharNode、ArrayNode減少部分存盤消耗,其中ArrayNode中通過shift存盤偏移量,陣列的下標位置加上shift偏移量即為字符的ASCII碼,
并且該參賽者在輸出資料時沒有將字串存盤到字串陣列中,而是定義了ByteBuf,在輸出時直接以JSON字串形式存盤到位元組陣列中,
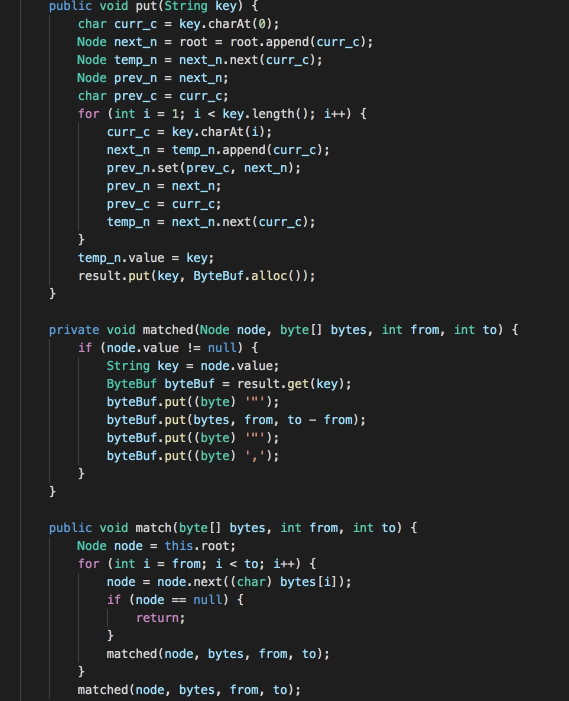
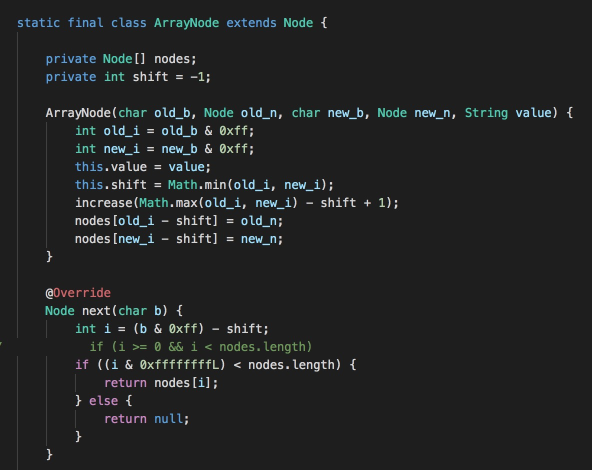
總結
盡管很多參賽者在這一關遇到了較多困難,尤其是在處理大規模資料集時,但正因為如此,我們也發現很多選手并不止步于通關,他們會努力嘗試不同的解法、不斷地優化演算法,哪怕只是提升了0.01分,這一點對我們團隊的觸動也是很大的,賽事后我們也反思了一些做得不夠好的地方,比如IDE評分欄缺少記憶體消耗、性能開銷等具體數字的展示,導致部分參賽者不知道實際的記憶體消耗,后續我們會對這些細節點上進行優化,如果大家有好的想法及建議,歡迎反饋給我們!
看完攻略如果你還想體驗賽題,依然可以前往https://code83.ide.aliyun.com,我們目前仍然開放給大家進行體驗,
最后,歡迎大家試用智能編碼插件:https://developer.aliyun.com/tool/cosy,它作為一款AI開發插件,擁有強大的代碼智能補全、代碼示例搜索等功能,讓開發行云流水般編碼,事半功倍地完成開發作業,你可以在IntelliJ IDEA或JetBrains插件市場中搜索Alibaba Cloud AI Coding Assistant或Cosy,使用中如果有任何問題或建議都可以反饋到Github Issues中,我們會認真傾聽你的聲音,
大賽目前全部關卡開放體驗,域名地址:https://code83.ide.aliyun.com/,歡迎你來,
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/374010.html
標籤:其他
上一篇:喵跑跑需求分析