我有一個簡單的資料框,其中一列 SIZE 是分類值(SMALL、MEDIUM、LARGE),另一列 VALUE 是整數。當我創建作為 SIZE 函式的 VALUE 散點圖時,X 軸上顯示的類別順序將發生變化,具體取決于資料框中第一行的 SIZE。我確保告訴 Pandas SIZE 類別值的明確“排序”。
要查看此操作,請使用以下代碼片段
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({'SIZE': ['MEDIUM', 'MEDIUM', 'LARGE', 'SMALL', 'LARGE', 'LARGE'],
'VALUE': [1, 2, 3, 4, 5, 6]})
# Convert to categorical data type and define the order
df['SIZE'] = pd.Categorical(df['SIZE'], categories=['SMALL', 'MEDIUM', 'LARGE'], ordered=True)
print(df.dtypes)
print(df)
print(df.SIZE.describe)
這會產生以下輸出:
SIZE category
VALUE int64
dtype: object
SIZE VALUE
0 MEDIUM 1
1 MEDIUM 2
2 LARGE 3
3 SMALL 4
4 LARGE 5
5 LARGE 6
<bound method NDFrame.describe of 0 MEDIUM
1 MEDIUM
2 LARGE
3 SMALL
4 LARGE
5 LARGE
Name: SIZE, dtype: category
Categories (3, object): ['SMALL' < 'MEDIUM' < 'LARGE']>
看到這里,似乎一切都很好。但是當我繪制使用
fig, ax = plt.subplots()
ax.scatter(df.SIZE, df.VALUE)
我得到一個圖表,其中 X 軸上的第一個類別是“中”,而不是“小”。
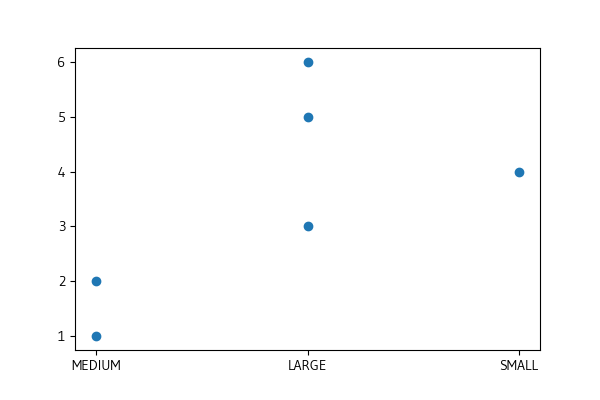
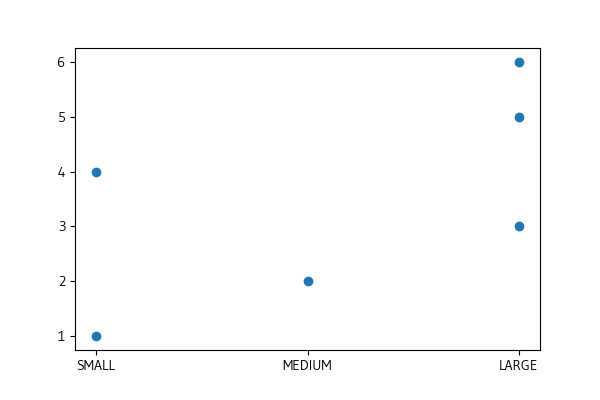
如果我只是將第一行的 SIZE 更改為“SMALL”,即
df = pd.DataFrame({'SIZE': ['SMALL', 'MEDIUM', 'LARGE', 'SMALL', 'LARGE', 'LARGE'],
'VALUE': [1, 2, 3, 4, 5, 6]})
并重新運行其余的代碼,我將得到一個具有正確順序的圖形。
我顯然錯過了 Matplotlib 中的一些細微差別。我使用的是 Matplotlib 3.4.3 和 Pandas 1.3.4。
uj5u.com熱心網友回復:
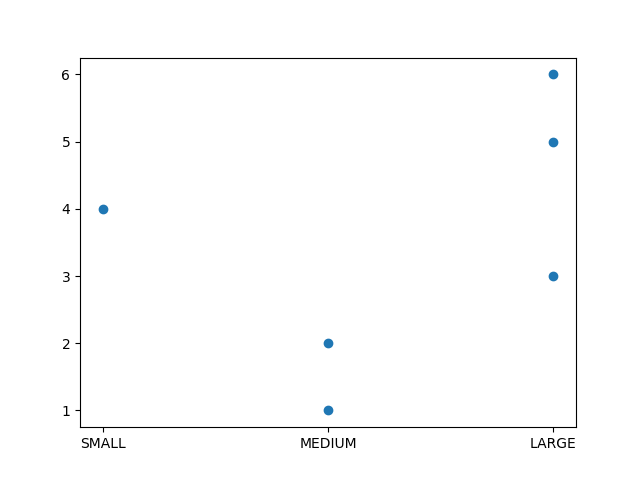
Matplotlib 不關心 dtype Categorical。您應該首先按SIZE以下方式對資料框進行排序:
fig, ax = plt.subplots()
df = df.sort_values('SIZE')
ax.scatter(df.SIZE, df.VALUE)
plt.show()
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/396825.html
標籤:Python 熊猫 matplotlib
下一篇:一列中的幾個框[Boxplot]