我有一個這樣的資料框
| ID | 執行時間 | 報告時間 |
|---|---|---|
| 101 | 13:05。 | 15.02。 |
| 121 | 14.05。 | 16.10。 |
| 101 | 14.20。 | 15.02。 |
如果 ID 和報告時間相同,我想歸檔行。即結果資料幀應該是
| ID | 報告時間 |
|---|---|
| 101 | 15.02。 |
| 121 | 16.10。 |
我嘗試使用 groupby 無濟于事。
uj5u.com熱心網友回復:
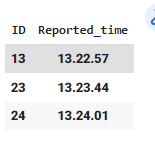
d = {'ID': ['13', '13','23', '24'], 'Reported_time': ['13.22.57', '13.22.57','13.23.44', '13.24.01']}
df = pd.DataFrame(data=d)
df2=df.groupby(['ID','Reported_time']).nunique()
df2
結果:
uj5u.com熱心網友回復:
你只需要distinct():
>>> from datar.all import f, tibble, distinct
>>> df = tibble(
... ID=[101, 121, 101],
... **{
... "Performed Time": ["13:05.", "14.05.", "14.20."],
... "Reported Time": ["15.02.", "16.10.", "15.02."]
... }
... )
>>>
>>> df >> distinct(f.ID, f["Reported Time"])
ID Reported Time
<int64> <object>
0 101 15.02.
1 121 16.10.
我是datarPython 中資料操作語法的作者,它封裝了 pandas API,現在還支持 modin。
uj5u.com熱心網友回復:
df[["ID", "Reported Time"]].drop_duplicates()
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/451434.html
上一篇:拆分和堆疊多值列