原文鏈接:袋鼠云數堆疊基于CBO在Spark SQL優化上的探索
一、Spark SQL CBO選型背景
Spark SQL的優化器有兩種優化方式:一種是基于規則的優化方式(Rule-Based Optimizer,簡稱為RBO);另一種是基于代價的優化方式(Cost-Based Optimizer,簡稱為CBO),
1、RBO是傳統的SQL優化技術
RBO是發展比較早且比較成熟的一項SQL優化技術,它按照制定好的一系列優化規則對SQL語法運算式進行轉換,最終生成一個最優的執行計劃,RBO屬于一種經驗式的優化方法,嚴格按照既定的規則順序進行匹配,所以不同的SQL寫法直接決定執行效率不同,且RBO對資料不敏感,在表大小固定的情況下,無論中間結果資料怎么變化,只要SQL保持不變,生成的執行計劃就都是固定的,
2、CBO是RBO改進演化的優化方式
CBO是對RBO改進演化的優化方式,它能根據優化規則對關系運算式進行轉換,生成多個執行計劃,在根據統計資訊(Statistics)和代價模型(Cost Model)計算得出代價最小的物理執行計劃,
3、 CBO與RBO優勢對比
● RBO優化例子
下面我們來看一個例子:計算t1表(大小為:2G)和t2表(大小為:1.8G)join后的行數
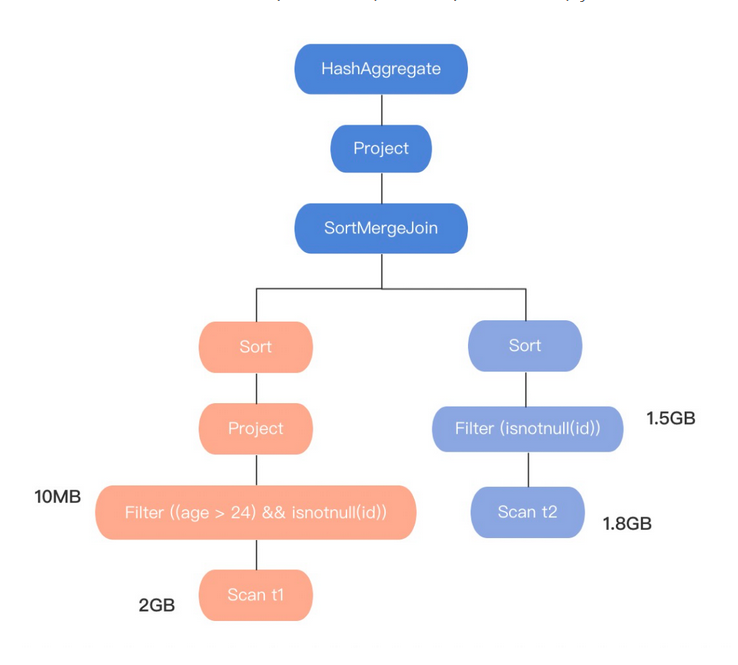
上圖是:
SELECT COUNT(t1.id) FROM t1 JOIN t2 ON t1.id = t2.id WHERE t1.age > 24
基于RBO優化后生成的物理執行計劃圖,在圖中我們可以看出,執行計劃最后是選用SortMergeJoin ⑴ 進行兩個表join的,
在Spark中,join的實作有三種:
1.Broadcast Join
2.ShuffleHash Join
3.SortMerge Join
ShuffleHash Join和SortMerge Join都需要shuffle,相對Broadcast Join來說代價要大很多,如果選用Broadcast Join則需要滿足有一張表的大小是小于等于
spark.sql.autoBroadcastJoinThreshold 的大小(默認為10M),
而我們再看,上圖的執行計劃t1表,原表大小2G過濾后10M,t2表原表大小1.8G過濾后1.5G,這說明RBO優化器不關心中間資料的變化,僅根據原表大小進行join的選擇了SortMergeJoin作為最終的join,顯然這得到的執行計劃不是最優的,
● CBO優化例子
而使用CBO優化器得到的執行計劃圖如下:
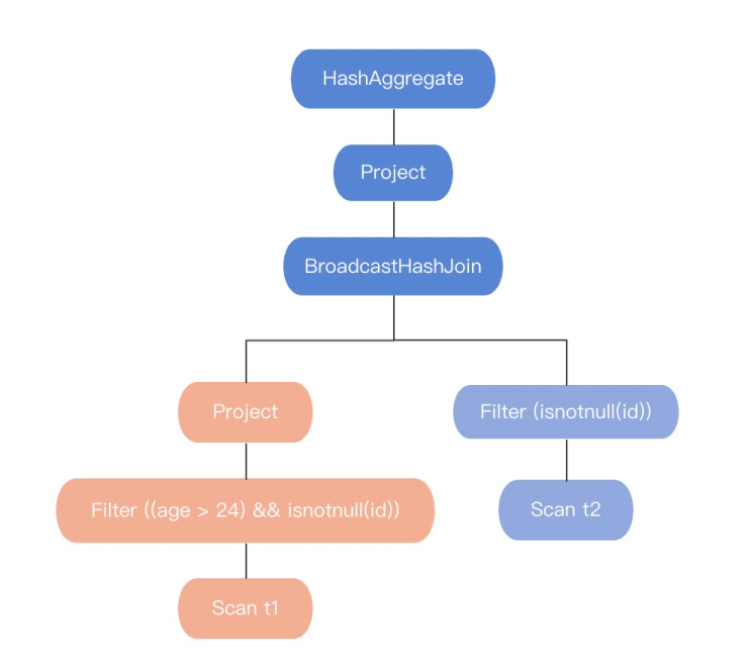
我們不難看出,CBO優化器充分考慮到中間結果,感知到中間結果的變化滿足能Broadcast Join的條件,所以生成的最終執行計劃會選擇Broadcast Join來進行兩個表join,
● 其他優勢
其實除了刻板的執行導致不能得到最優解的問題,RBO還有學習成本高的問題:開發人員需要熟悉大部分優化規則,否則寫出來的SQL性能可能會很差,
● CBO是數堆疊Spark SQL 優化的更佳選擇
相對于RBO,CBO無疑是更好的選擇,它使Spark SQL的性能提升上了一個新臺階,Spark作為數堆疊平臺底層非常重要的組件之一,承載著離線開發平臺上大部分任務,做好Spark的優化也將推動著數堆疊在使用上更加高效易用,所以數堆疊選擇CBO做研究探索,由此進一步提高數堆疊產品性能,
二、Spark SQL CBO實作原理
Spark SQL中實作CBO的步驟分為兩大部分,第一部分是統計資訊收集,第二部分是成本估算:
1、統計資訊收集
統計資訊收集分為兩個部分:第一部分是原始表資訊統計、第二部分是中間算子的資訊統計,
1)原始表資訊統計
Spark中,通過增加新的SQL語法ANALYZE TABLE來用于統計原始表資訊,原始表統計資訊分為表級別和列級別兩大類,具體的執行如下所示:
● 表級別統計資訊
通過執行 ANALYZE TABLE table_name COMPUTE STATISTICS 陳述句來收集,統計指標包括estimatedSize解壓后資料的大小、rowCount資料總條數等,
● 列級別統計資訊
通過執行 ANALYZE TABLE table_name COMPUTE STATISTICS FOR COLUMNS column-name1, column-name2, …. 陳述句來收集,
列級別的資訊又分為基本列資訊和直方圖,基本列資訊包括列型別、Max、Min、number of nulls, number of distinct values, max column length, average column length等,直方圖描述了資料的分布,Spark默認沒有開啟直方圖統計,需要額外設定引數:spark.sql.statistics.histogram.enabled = true,
原始表的資訊統計相對簡單,推算中間節點的統計資訊相對就復雜一些,并且不同的算子會有不同的推算規則,在Spark中算子有很多,有興趣的同學可以看Spark SQL CBO設計檔案:
https://issues.apache.org/jira/secure/attachment/12823839/Spark_CBO_Design_Spec.pdf
2)中間算子的資訊統計
我們這里以常見的filter算子為例,看看推算算子統計資訊的程序,基于上一節的SQL SELECT COUNT(t1.id) FROM t1 JOIN t2 ON t1.id = t2.id WHERE t1.age > 24生成的語法樹來看下t1表中包含大于運算子 filter節點的統計資訊,
圖片
在這里需要分三種情況考慮:
第一種
過濾條件常數值大于max(t1.age),回傳結果為0;
第二種
過濾條件常數值小于min(t1.age),則全部回傳;
第三種
過濾條件常數介于min(t1.age)和max(t1.age)之間,當沒有開啟直方圖時過濾后統計資訊的公式為after_filter = (max(t1.age) - 過濾條件常數24)/(max(t1.age) – min(t1.age)) * before_filter,沒有開啟直方圖則默認任務資料分布是均勻的;當開啟直方圖時過濾后統計資訊公式為after_filter = height(>24) / height(All) * before_filter,然后將該節點min(t1.age)等于過濾條件常數24,
2、成本估算
介紹完如何統計原始表的統計資訊和如何計算中間算子的統計資訊,有了這些資訊后就可以計算每個節點的代價成本了,
在介紹如何計算節點成本之前我們先介紹一些成本引數的含義,如下:
Hr: 從 HDFS 讀取 1 個位元組的成本
Hw: 從 HDFS 寫1 個位元組的成本
NEt: 在 Spark 集群中通過網路從任何節點傳輸 1 個位元組到 目標節點的平均成本
Tr: 資料總條數
Tsz: 資料平均大小
CPUc: CPU 成本
計算節點成本會從IO和CPU兩個維度考慮,每個算子成本的計算規則不一樣,我們通過join算子來舉例說明如何計算算子的成本:
假設join是Broadcast Join,大表分布在n個節點上,那么CPU代價和IO代價計算公式分別如下:
CPU Cost=小表構建Hash Table的成本 + 大表探測的成本 = Tr(Rsmall) * CPUc + (Tr(R1) + Tr(R2) + … + Tr(Rn)) * n * CPUc
IO Cost =讀取小表的成本 + 小表廣播的成本 + 讀取大表的成本 = Tr(Rsmall) * Tsz(Rsmall) * Hr + n * Tr(Rsmall) * Tsz(Rsmall) * NEt + (Tr(R1)* Tsz(R1) + … + Tr(Rn) * Tsz(Rn)) * Hr
但是無論哪種算子,成本計算都和參與的資料總條數、資料平均大小等因素直接相關,這也是為什么在這之前要先介紹如何統計原表資訊和推算中間算子的統計資訊,
每個算子根據定義的規則計算出成本,每個算子成本相加便是整個執行計劃的總成本,在這里我們可以考慮一個問題,最優執行計劃是列舉每個執行計劃一個個算出每個的總成本得出來的嗎?顯然不是的,如果每個執行計劃都計算一次總代價,那估計黃花菜都要涼了,Spark巧妙的使用了動態規劃的思想,快速得出了最優的執行計劃,
三、數堆疊在Spark SQL CBO上的探索
了解完Spark SQL CBO的實作原理之后,我們來思考一下第一個問題:大資料平臺想要實作支持Spark SQL CBO優化的話,需要做些什么?
在前文實作原理中我們提到,Spark SQL CBO的實作分為兩步,第一步是統計資訊收集,第二步是成本估算,而統計資訊收集又分為兩步:第一步的原始表資訊統計、第二步中間算子的資訊統計,到這里我們找到了第一個問題的答案:平臺中需要先有原始表資訊統計的功能,
第一個問題解決后,我們需要思考第二個問題:什么時候進行表資訊統計比較合適?針對這個問題,我們初步設想了三種解決資訊統計的方案:
● 在每次SQL查詢前,先進行一次表資訊統計
這種方式得到的統計資訊比較準確,經過CBO優化后得出的執行計劃也是最優的,但是資訊統計的代價最大,
● 定期重繪表統計資訊
每次SQL查詢前不需要進行表資訊統計,因為業務資料更新的不確定性,所以這種方式進行SQL查詢時得到的表統計資訊可能不是最新的,那么CBO優化后得到的執行計劃有可能不是最優的,
● 在變更資料的業務方執行資訊統計
這種方式對于資訊統計的代價是最小的,也能保證CBO優化得到的執行計劃是最優的,但是對于業務代碼的侵入性是最大的,
不難看出三種方案各有利弊,所以進行表資訊統計的具體方案取決于平臺本身的架構設計,
基于數堆疊平臺建設數倉的結構圖如下圖所示:
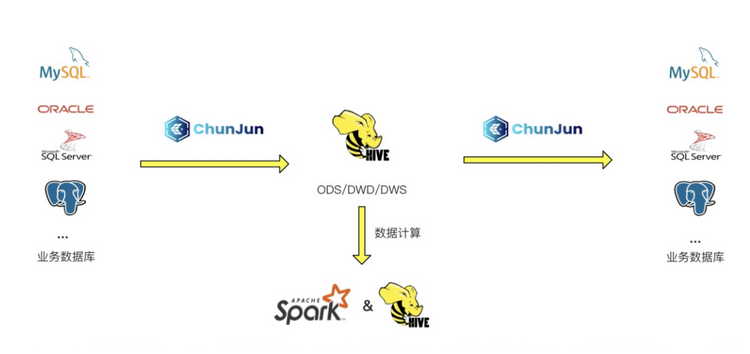
首先通過ChunJun將業務資料庫資料采集到Hive ODS層
然后通過Hive或者Spark進行資料處理
最后通過ChunJun將Hive庫的資料寫入到業務資料庫用于業務處理
從結構圖可看出數堆疊有用到Hive、Spark和ChunJun三個組件,并且這三個組件都會讀寫Hive, 數堆疊多個子產品(如離線平臺和實時平臺)也都有可能對Hive進行讀寫,所以如果基于方案3來做成本是非常高的,
方案1本身代價就已經較大,每次查詢前都進行一次資訊統計,資訊統計的時間是要算在本次查詢耗時中的,如果表資料量比較大增加的時間可能是十幾分鐘甚至更久,
綜合考慮,我們選用了更靈活合理的方案2來進行表資訊統計,雖然Spark SQL運行時得到的統計資訊可能不是最新的,但是總體相比較RBO來說還是有很大的性能提升,
接下來就為大家分享,數堆疊是如何如何統計收集原表資訊統計:
我們在離線平臺專案管理頁面上添加了表資訊統計功能,保證了每個專案可以根據專案本身情況配置不同的觸發策略,觸發策略可配置按天或者按小時觸發,按天觸發支持配置到從當天的某一時刻觸發,從而避開業務高峰期,配置完畢后,到了觸發的時刻離線平臺就會自動以專案為單位提交一個Spark任務來統計專案表資訊,
在數堆疊沒有實作CBO支持之前,Spark SQL的優化只能通過調整Spark本身的引數實作,這種調優方式很高的準入門檻,需要使用者比較熟悉Spark的原理,數堆疊CBO的引入大大降低了使用者的學習門檻,用戶只需要在Spark Conf中開啟
CBO-spark.sql.cbo.enabled=true
然后在對應專案中配置好表資訊統計就可以做到SQL優化了,
四、未來展望
在CBO優化方面持續投入研究后,Spark SQL CBO整體相比較RBO而言已經有了很大的性能提升,但這并不說明整個作業系統就沒有優化的空間了,已經拿到的進步只會鼓舞我們繼續進行更深層次的探索,努力往前再邁一步,
完成對CBO的初步支持探索后,數堆疊把目光看向了Spark 3.0 版本引入的新特性——AQE(Adaptive Query Execution),
AQE是動態CBO的優化方式,是在CBO基礎上對SQL優化技術又一次的性能提升,如前文所說,CBO目前的計算對前置的原始表資訊統計是仍有依賴的,而且資訊統計過時的情況會給CBO帶來不小的影響,
如果在運行時動態的優化 SQL 執行計劃,就不再需要像CBO那樣需要提前做表資訊統計,數堆疊正在針對這一個新特性進行,相信不久的將來我們就能引入AQE,讓數堆疊在易用性高性能方面更上一層樓,希望小伙伴們保持關注,數堆疊愿和大家一起成長,
原文來源:VX公眾號“數堆疊研習社”
袋鼠云開源框架釘釘技術交流群(30537511),歡迎對大資料開源專案有興趣的同學加入交流最新技術資訊,開源專案庫地址:https://github.com/DTStack
轉載請註明出處,本文鏈接:https://www.uj5u.com/gongcheng/498917.html
標籤:其他