文章目錄
- 前言
- Ozone Streaming的實作背景:Ratis Streaming
- Ozone Streaming方式寫程序
- 參考資料
前言
在Ozone目前資料寫出的程序,是基于從物件檔案的block,再從block到chunk粒度進行資料的寫出的,每次Ozone寫完一個chunk后,對應著會觸發一次write chunk的RPC call,當我們寫入的資料檔案物件很大的時候,程序中將會涉及到很多次write chunk PRC的操作呼叫,這個RPC call的頻繁呼叫意味著相應更多的transaction的發生,對于Ozone Datanode里使用Raft協議做資料一致性同步程序的影響而言,則意味著更多的raft log需要被apply以及對應Ratis snapshot的take操作也會變得更加頻繁,在一定程度上,這會影響到Datanode節點本身的資料寫出操作,最近社區提出了利用Ratis Streaming的特性來優化Ozone資料寫出的流程,本文筆者來簡單聊聊Ozone Streaming這種全新方式的資料寫出程序,目前此功能處于有一個初步的設計方案階段,
Ozone Streaming的實作背景:Ratis Streaming
首先我們來聊聊Ozone Streaming的一個大的背景,Ozone Streaming想法的提出源自于Ratis Streaming特性,Ratis Streaming,顧名思義,指的是能用流的方式將資料寫出去而不是通過傳統RPC模式,將資料一點一點寫出去,
在Ratis Streaming功能中,除了其能夠減少資料寫程序中的RPC數,還有另外一個改進是它使用了netty作為底層流原理的實作,能夠做到資料傳輸程序中的的zero buffer copy的功效,同時在streaming方式的資料寫出程序里,寫出操作是在一個流里進行的,因此不會涉及到頻繁的流關閉操作,
目前Ratis Streaming功能分為了2個階段的實作:
一階段:實作無transaction創建的流資料寫出程序
二階段:資料Pipeline寫出的方式的優化,從原來的Leader到Follower的start-topology結構變為純線型的Pipeline處理模式,
這部分細節可參考RATIS-979上設計檔案的描述,
Ozone Streaming方式寫程序
在上文部分已經提到過,現有Ozone寫程序存在著transaction操作過多導致的一些性能效率上的問題,而且目前從Ozone Client寫資料傳輸到最終Datanode上,存在著大量的buffer資料的拷貝開銷,另外由于Ozone目前支持了multi raft功能后,一個Datanode可以被包含在多個raft group組里,這樣使得當一個Datanode成為多個raft leader時,這個節點會表現出一定的熱點瓶頸的現象,
但是現在在Ratis Streaming方式下,我們可以通過流的方式進行資料的寫出了,然后在前面流資料結束的時候,進行最后一次的block的commit操作,此程序圖如下所示:
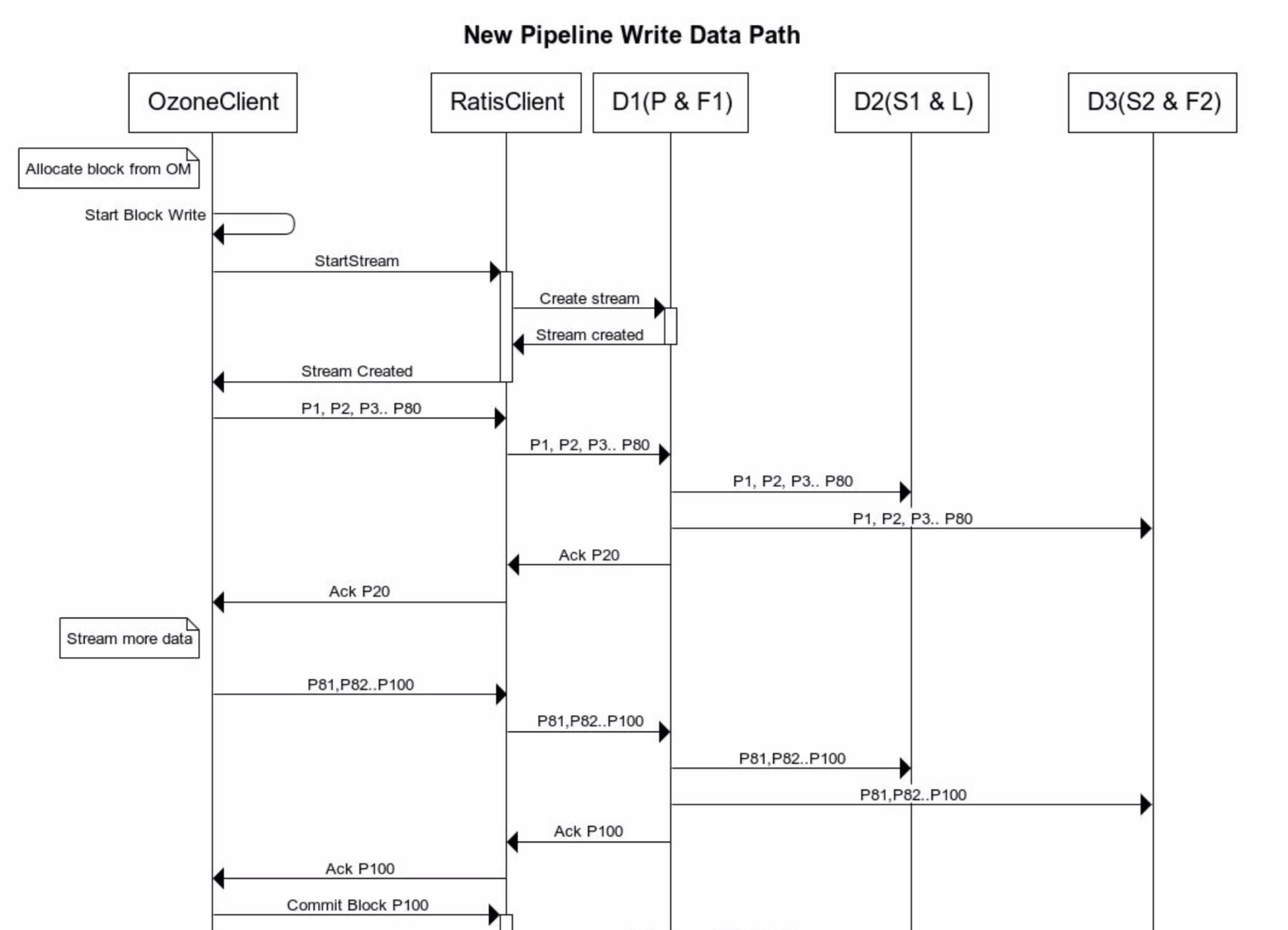
此圖第一部分階段為資料流寫出的程序,每次資料傳輸以packet為單位,進行依次資料的寫出,當client每次收到所有packet資料寫出ack結果之后,才能繼續寫出下一個packet的資料,
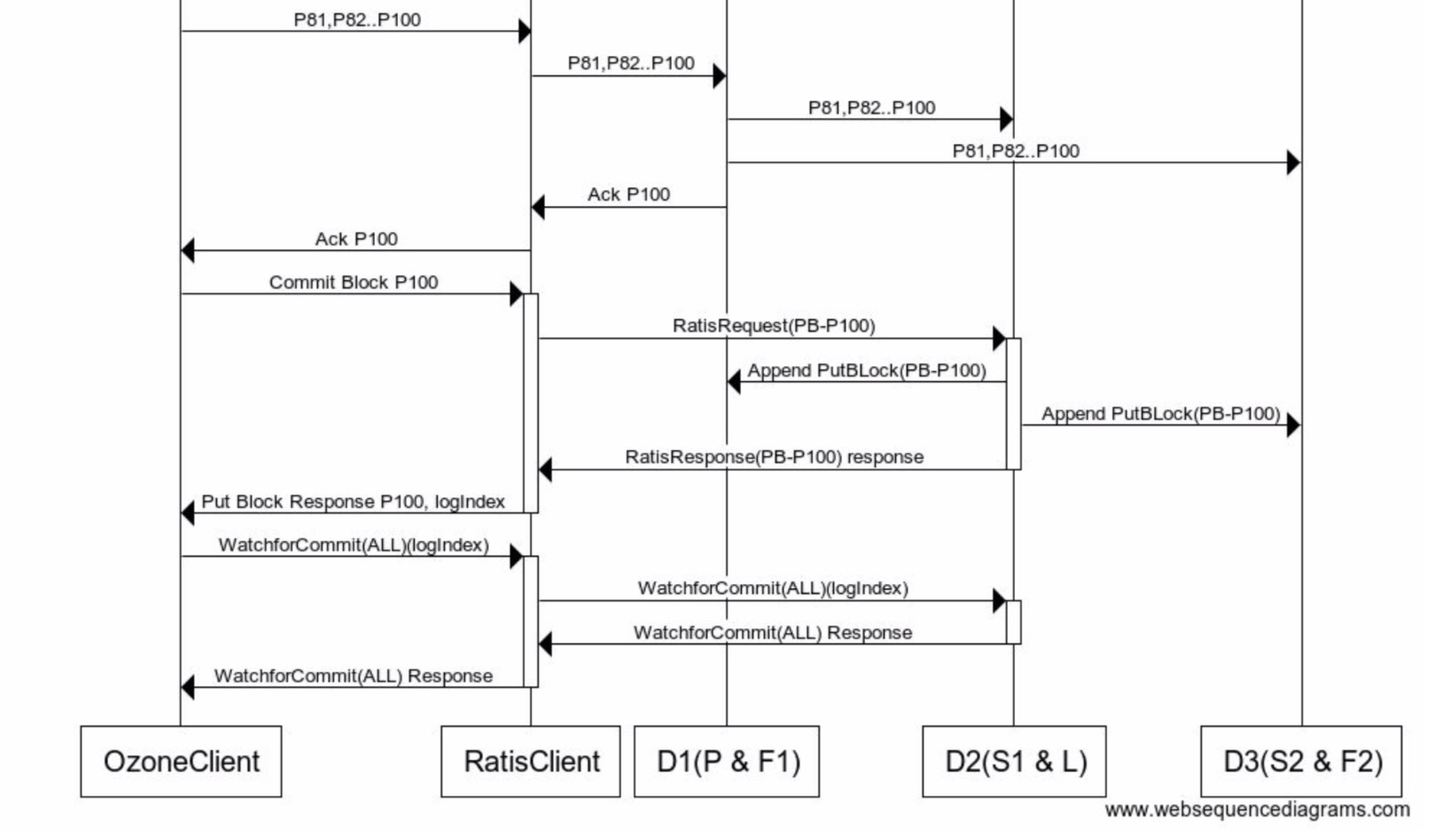
當所有packet資料都寫出去之后,則再進行最后block的提交的程序,在此程序中才會有transaction的發生,這種流式方式的資料寫出比之前通過每次小批量資料的RPC資料寫出的方式減少了很多的transaction的發生和處理,
但這里還是有可能遇到流資料寫出失敗的情況,比如沒有收到全部節點的ack回復等等,這個時候我們需要讓它怎么做呢?
在設計檔案中的做法是,提前進行block資料的提交來結束此流資料的寫出,以上次成功ack回復時資料寫出的大小作為提交的length,這種失敗處理方式至少能保證當前streaming寫出的資料都是正確的,此失敗程序處理圖如下所示:
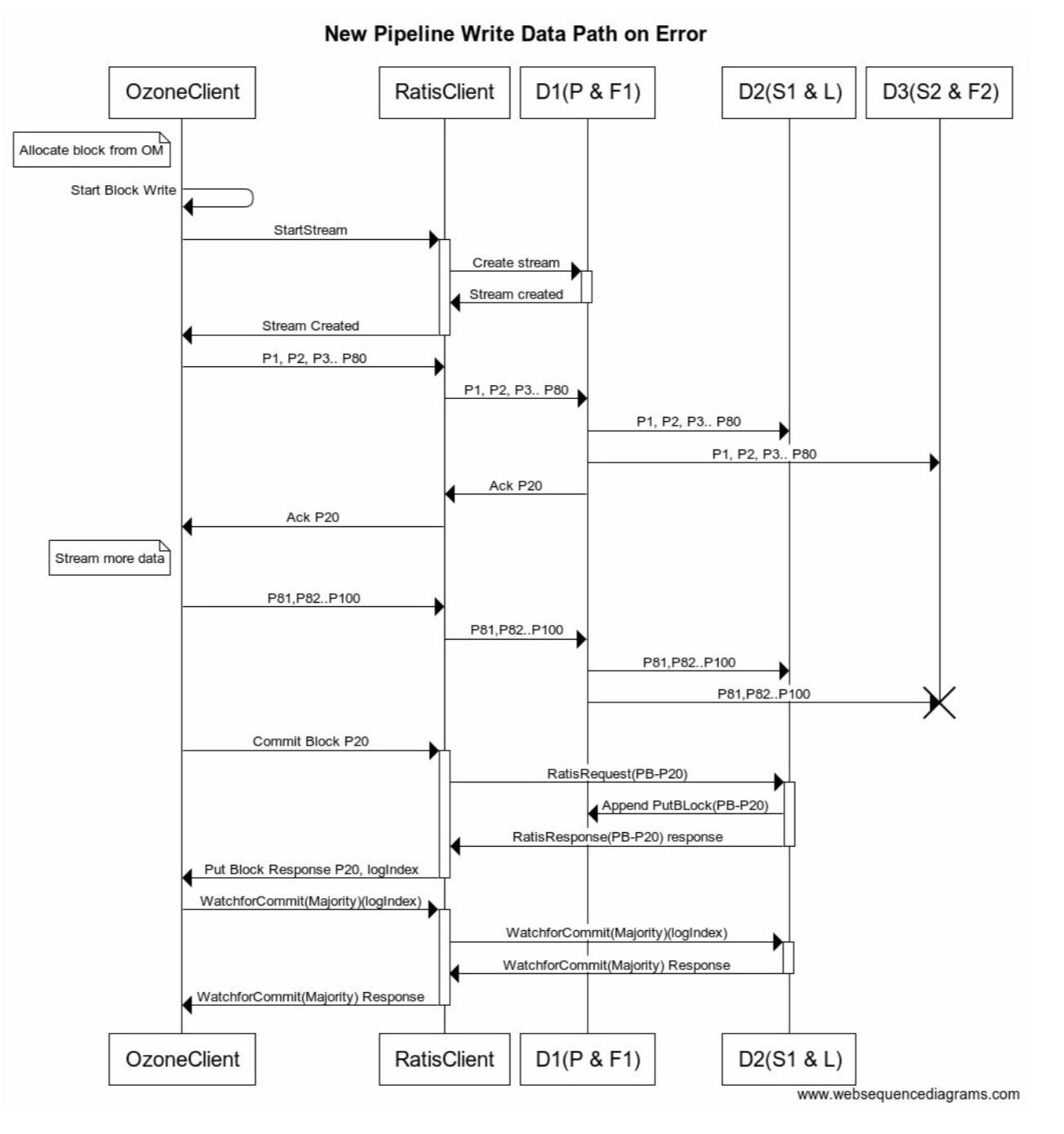
以上就是本文簡單介紹的Ozone Streaming方式的資料寫程序的新設計,設計細節可參閱JIRA HDDS-4454,
參考資料
[1].https://issues.apache.org/jira/browse/HDDS-4454
[2].https://issues.apache.org/jira/browse/RATIS-979
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/241462.html
標籤:AI
上一篇:我好像用了一個假云