TensorFlow 2.4 正式發布!隨著對分布式訓練和混合精度提供更多支持,加入新的 Numpy 前端及用于監控和診斷性能瓶頸的工具,這個版本的亮點在于推出新功能,以及對性能和擴展方面的增強,
tf.distribute 的新增功能
引數服務器策略
在版本 2.4 中,實驗性引入了 tf.distribute 模塊的支持,可通過 ParameterServerStrategy 和自定義訓練回圈對 Keras 模型進行異步訓練,與 MultiWorkerMirroredStrategy 一樣,ParameterServerStrategy 是一種多作業器資料并行策略;但其梯度更新方式為異步執行,
引數服務器訓練集群包含作業節點和引數服務器,系統會在引數服務器上創建變數,然后作業節點會在每個步驟中進行讀取和更新,變數的讀取和更新會在各作業節點上獨立進行,同時無需采取任何同步操作,由于作業節點互不依賴,因此該策略具有作業器容錯的優勢,并會在使用搶占式服務器時有所助益,
如要開始使用此策略,請查閱引數服務器訓練教程,此教程介紹了如何設定 ParameterServerStrategy,并說明了如何使用 ClusterCoordinator 類來創建資源、調度函式和處理任務失敗,
多作業節點鏡像策略
MultiWorkerMirroredStrategy 多作業節點鏡像策略 已順利度過實驗階段,現已成為穩定 API 的組成部分,與單個作業節點副本 MirroredStrategy 一樣,MultiWorkerMirroredStrategy 通過同步資料并行化實作分布式訓練,但利用 MultiWorkerMirroredStrategy,您可以在多臺機器上進行訓練,且每臺機器可以都搭載多個 GPU,
在同步訓練中,每個作業節點會在輸入資料的不同片段上計算正向和反向傳遞次數,并且在每個步驟結束時匯總梯度,對于這種稱為 All Reduce 的匯總, MultiWorkerMirroredStrategy 會使用集合運算保持變數同步,集合運算是 TensorFlow 圖表中的單個算子,可以根據硬體、網路拓撲和張量大小在 TensorFlow 運行時中自動選擇 All Reduce 演算法,集合運算還可實作其他集合運算,例如廣播和 All Gather,
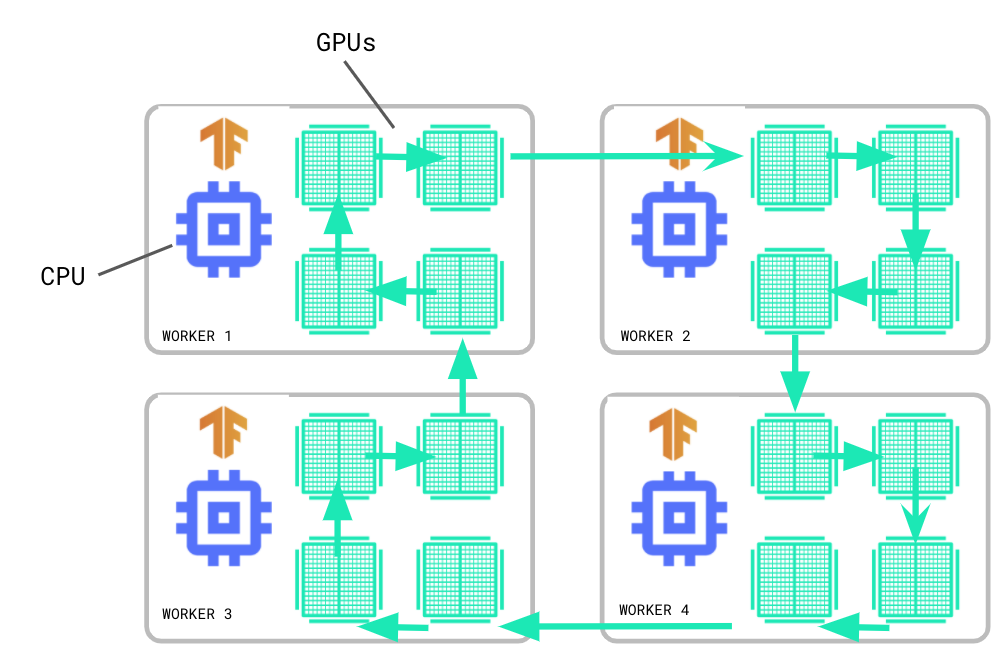
如要開始使用 MultiWorkerMirroredStrategy,請查閱使用 Keras 進行多作業器訓練教程,該教程已更新了有關資料集分片、保存/加載使用分布策略訓練的模型,以及使用 BackupAndRestore 回呼進行故障恢復的詳細資訊,
如果您不熟悉分布式訓練,并希望了解入門方法,或者有興趣在 Google 云端平臺 (GCP) 上進行分布式訓練,請參閱本博文,以獲取關于關鍵概念和步驟的介紹,
Keras 的相關更新
混合精度
在 TensorFlow 2.4 中,Keras 混合精度 API 已順利度過實驗階段,現已成為穩定的 API,大多數 TensorFlow 模型使用的是 float32 dtype;但也存在使用更少記憶體的低精度型別(如 float16),混合精度指在同一模型中通過使用 16 位和 32 位浮點型別,以加快訓練速度,該 API 可使模型在 GPU 上性能提高 3 倍,在 TPU 上提高 60%,
如要使用混合精度 API,您必須使用 Keras 層和優化工具,但無需使用其他 Keras 類,例如模型或損失,如果您對如何利用此 API 實作性能優化頗有興趣,請查閱混合精度教程,
優化工具
此版本支持重構 tf.keras.optimizers.Optimizer 類,使 model.fit 或自定義訓練回圈的用戶能夠撰寫任何適用于優化工具的訓練代碼,現所有內置的 tf.keras.optimizer.Optimizer 子類均可支持使用 gradient_transformers 和 gradient_aggregator 引數,您可借此輕松定義自定義梯度轉換,
通過重構,您現在可以在撰寫自定義訓練回圈時將損失張量直接傳遞給 Optimizer.minimize:
tape = tf.GradientTape()
with tape:
y_pred = model(x, training=True)
loss = loss_fn(y_pred, y_true)
# 如下所示,在使用損失“張量”時,您可以在“tf.GradientTape”中進行傳遞,
optimizer.minimize(loss, model.trainable_variables, tape=tape)
此類更改旨在使 Model.fit 和自定義訓練回圈都能擺脫優化工具細節的限制,從而使您無需修改,即可撰寫任何適用于優化工具的訓練代碼,
函式式 API 模型構建的內部改進
最后,在 Keras 中,TensorFlow 2.4 可支持對 Keras Functional API 內部主要結構的重構,從而可降低函式式模型構建的記憶體消耗并簡化觸發邏輯,開展此類重構操作還能夠確保 TensorFlowOpLayers 行為可預測,并可與 CompositeTensor 型別的簽名一起使用,
隆重推出 tf.experimental.numpy
TensorFlow 2.4 以 tf.experimental.numpy 形式,實驗性引入了對 NumPy API 子集的支持,您可借此模塊,運行由 TensorFlow 加速的 NumPy 代碼,由于此 API 基于 TensorFlow 構建而成,因此可支持訪問所有 TensorFlow API,與 TensorFlow 實作無縫互操作,并會通過編譯和自動矢量化開展優化,例如,TensorFlow ND 陣列可以與 NumPy 函式進行互動,同樣地,TensorFlow NumPy 函式也可以接受包括 tf.Tensor 和 np.ndarray 在內的不同型別的輸入,
import tensorflow.experimental.numpy as tnp ```
# 在輸入流水線中使用 NumPy 代碼
dataset = tf.data.Dataset.from_tensor_slices(
tnp.random.randn(1000, 1024)).map(
lambda z: z.clip(-1,1)).batch(100)
# 通過 NumPy 代碼計算梯度
def grad(x, wt):
with tf.GradientTape() as tape:
tape.watch(wt)
output = tnp.dot(x, wt)
output = tf.sigmoid(output)
return tape.gradient(tnp.sum(output), wt)
您可以查閱 TensorFlow 指南上的 NumPy API,了解更多關于使用此 API 的資訊,
全新性能分析器工具
TensorFlow Profiler 中的多作業器支持
TensorFlow Profiler 是一套用于評估 TensorFlow 模型訓練性能和資源消耗情況的工具,TensorFlow Profiler 可幫助您了解模型中算子的硬體資源消耗、診斷瓶頸并最終加快訓練速度,
之前版本的TensorFlow Profiler 支持監控多 GPU、單主機訓練作業,在現在 2.4 版本中,您可以分析 MultiWorkerMirroredStrategy 訓練作業的性能,例如,您可以使用采樣模型 API 來執行按需分析,并連接到 MultiWorkerMirroredStrategy 作業節點上正在使用的同一服務器埠:
# 在模型運行之前啟動性能分析器服務器,
tf.profiler.experimental.server.start(6009)
# 在此處插入模型代碼……
# 例如,您的作業器 IP 地址是 10.0.0.2、10.0.0.3、10.0.0.4,然后您
# 希望執行 2 秒鐘的性能分析,性能分析資料將
# 保存至 Google Cloud Storage 路徑“your_tb_logdir”,
tf.profiler.experimental.client.trace(
'grpc://10.0.0.2:6009,grpc://10.0.0.3:6009,grpc://10.0.0.4:6009',
'gs://your_tb_logdir',
2000)
或者,您可以通過向 Capture Profile(捕獲分析結果)工具提供作業節點地址來使用 TensorBoard 組態檔插件,
分析完成后,您可以使用新的 Pod Viewer 工具選擇一個訓練步驟,并查閱所有作業節點的分步時間類別細分,
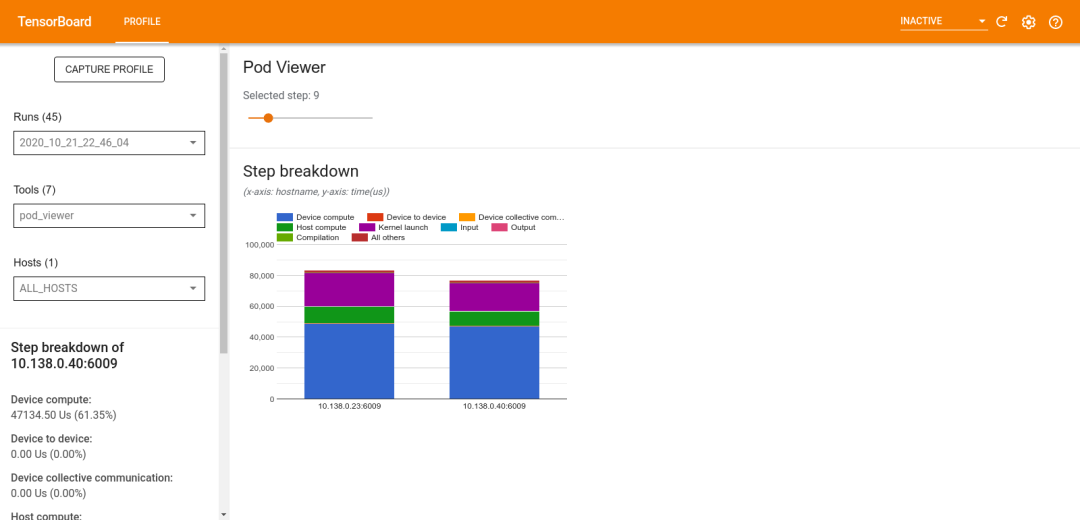
有關如何使用 TensorFlow Profiler 的更多資訊,請查閱新發布的 GPU 性能指南,此指南介紹了您在對模型訓練作業進行性能分析時可能遇到的常見情況,并提供了除錯作業流程來幫助您優化性能,無論您是使用單個 GPU、多個 GPU 還是使用多臺機器進行訓練,均可從中受益,
TFLite Profiler
在 2.4 版本中,您亦可在 Android 中啟用對 TFLite 內部結構的跟蹤,現在,您可以使用 Android 版 TFLite Profiler 來識別性能瓶頸,TFLite 性能評估指南介紹了如何使用 Android Studio CPU 性能分析器和系統跟蹤應用添加跟蹤事件,啟用 TFLite 跟蹤以及捕獲跟蹤,
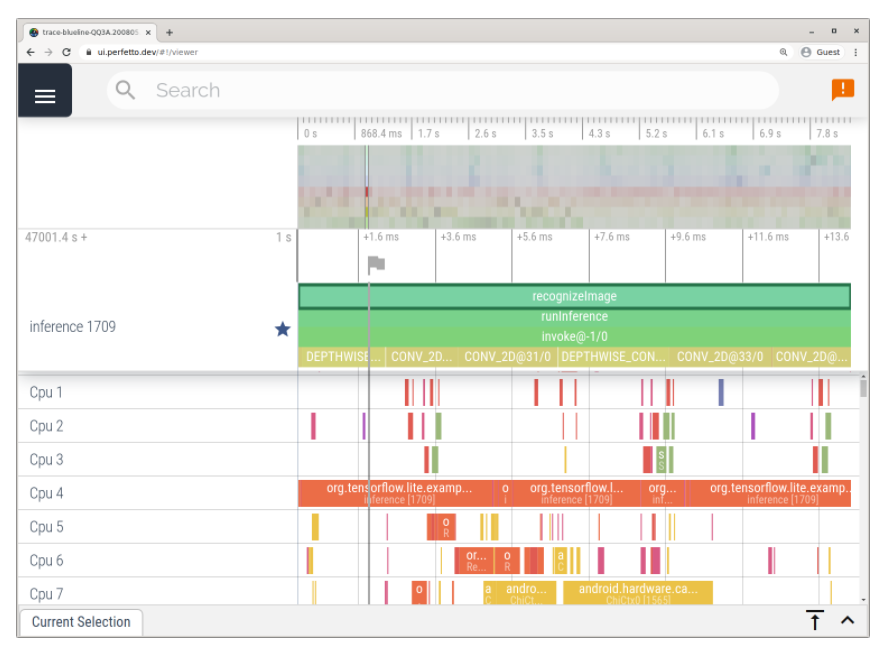
使用 Android 系統跟蹤應用進行跟蹤的示例
提供 GPU 支持的新功能
TensorFlow 2.4 可與 CUDA 11 和 cuDNN 8 一起運行,以支持最新上市的 NVIDIA Ampere GPU 架構,如需了解 CUDA 11 功能的更多資訊,請查閱此 NVIDIA 開發者博客,
此外,我們亦會默認在搭載 Ampere 的 GPU 上啟用對 TensorFloat-32 的支持,TensorFloat-32(簡稱為“TF32”)是 NVIDIA Ampere GPU 的一種數學模式,可加快令某些 float32 算子(例如矩陣乘法和卷積)在 Ampere GPU 上的運行速度,但精度降低,如需了解更多資訊,請查閱 tf.config.experimental.enable_tensor_float_32_execution 檔案,
后續步驟
請參閱版本說明了解更多資訊,如欲分享您的構建成果,請通過 Community Spotlight 計劃向我們提交您的作品,如需提供反饋,請在 GitHub上提交問題,
如果你對本文中提到的更新存在疑問,歡迎移步“問答”版塊發帖提問,你的問題有機會得到 CSDN 百大熱門技術博主、資深社區作者或者 TensorFlow 資深開發者的解答哦!同時,我們也歡迎你積極地在這個版塊里,回答其他小伙伴提出的問題,成為 CSDN 社區貢獻者,馬上開始討論吧!
想了解更多產品最新資訊?掃碼關注TensorFlow官方微信公眾號(TensorFlow_official),產品更新、課程教學、技術實踐、應用實體等精彩內容一網打盡!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/241463.html
標籤:AI