1. 寫在前面
這幾天打算整理一個模擬真實情景進行廣告推薦的一個小Demon, 這個專案使用的阿里巴巴提供的一個淘寶廣告點擊率預估的資料集, 采用lambda架構,實作一個離線和在線相結合的實時推薦系統,對非搜索型別的廣告進行點擊率預測和推薦(沒有搜索詞,沒有廣告的內容特征資訊),這個感覺挺接近于工業上的那種推薦系統了,通過這個推薦系統,希望能從工程的角度了解推薦系統的流程,也順便學習一下大資料的相關技術,這次會涉及到大資料平臺上的資料處理, 離線處理業務和在線處理業務, 涉及到的技術包括大資料的各種技術,包括Hadoop,Spark(Spark SQL, Spqrk ML, Spark-Streaming), Redis,Hive,HBase,Kafka和Flume等, 機器學習的相關技術(資料預處理,模型的離線訓練和在線更新等,所以這幾天的時間借機會走一遍這個流程,這里也詳細記錄一下,方便以后回看和回練, 這次的課程是跟著B站上的一個課程走的, 講的挺詳細的,就是沒有課件和資料,得需要自己搞,并且在實戰這次的推薦系統之前,最好是有一整套的大資料環境(我已經搭建好了), 然后就可以來玩這個系統了哈哈, 現在開始 😉
今天是第一篇,先介紹一下個性化電商廣告推薦系統的資料集和基本任務,這樣能夠在宏觀上對整體的方向進行一個把握, 所以這篇文章相對會比較簡單些,具體大綱如下:
- 任務介紹(最后到底要實作個啥東西?)
- 資料集介紹
- 簡單的流程分析
- 涉及到點擊率預測的幾個相關概念
Ok, let’s go!
2. 任務介紹
本次任務是根據一個淘寶廣告展示和用戶點擊行為的一個資料集, 來做一個這樣的系統:

最后系統啟動, 我們輸入某個用戶的ID,即給定某個用戶,然后給定廣告資源位的位置(就是廣告放置的位置), 推薦系統給我們回傳該用戶比較可能點擊的10個廣告回來,
所以這個系統的功能相對來說比較簡單,就是一個單純的廣告推薦任務, 當然也不是那么簡單, 因為這里要涉及到實時推薦,所以還需要根據之前的用戶點擊結果對召回的廣告進行動態調整, 來更新最后的推薦串列, 比如第一次給328用戶推薦了上面這10個廣告, 第二次有推薦了10個, 連續五次之后發現他對某些廣告并沒有進行點擊,可能不感興趣,那第6次推薦的時候就要更新召回串列, 把該廣告去掉, 換成新的一些,然后再根據快取的用戶特征和廣告特征再進行點擊率預測, 再排序和產生推薦等, 這就是實時的一種思路了,后面會具體的介紹這個, 這里做一個初步了解, 然后明白最后這個系統在干個啥事就行了,
3. 資料集介紹
知道了這個系統干的事情,我們在看一下這次用的資料集,這次的資料集可以在這里下載,主要有四個資料檔案, 分別對應著用戶的廣告點擊行為日志, 廣告自身的特征, 用戶自身的特征和用戶的購物行為,下面一一來解釋:
3.1 原始樣本骨架raw_sample
這個是從淘寶網站中隨機抽樣了114萬用戶8天內的廣告展示/點擊日志(2600萬條記錄),構成原始的樣本骨架, 欄位說明如下:
user_id:脫敏過的用戶ID;adgroup_id:脫敏過的廣告單元ID;time_stamp:時間戳;pid:資源位;(資源展現位置,如:側邊和底部)noclk:為1代表沒有點擊;為0代表點擊;clk:為0代表沒有點擊;為1代表點擊;
這份資料體現的是用戶對不同位置廣告點擊、沒點擊的情況, 這份資料比較重要,也是我們模型預測的基本骨架,因為我們最后的目標是給用戶推薦廣告, 而這個任務我們一般是轉成一個點擊率預測的問題,就是對于某個廣告,我們預測用戶點還是不點,這是一個二分類的問題,我們最后把點擊概率從大到小排序,靠前的一些廣告就可以推薦給用戶了, 所以單純的基于這個資料集,其實我們就可以訓練一個二分類的模型了,比如邏輯回歸,只不過這里面能利用的資訊有限,不準而已,所以才說這是原始資料的一個基本骨架,
這里面能用的特征有user_id, adgroup_id和pid,time_stamp當然也能用,可能用處不大, 目標也要清楚,就是用戶的點擊情況, 后面這兩個都體現了用戶是否點擊的情況,這里之所以給了兩個,是因為這里是真實情況的日志, 真實情況下是要同時記錄點擊和未點擊情況的, 真實場景下,一般是給用戶曝光一些廣告, 然后看看用戶是否點擊,如果用戶點擊了, 那么點擊那里是1, 未點擊是0, 但是大部分情況下用戶是不點廣告的,這時候未點擊是1, 點擊是0,如果僅用點擊情況的話,可能就不知道究竟給用戶曝光了多少廣告了(萬一再稀疏存盤,更不知道了), 所以這兩個合起來才可以標記給用戶曝光的廣告情況,當然制作label的時候,我們只用一個即可,
由于上面可以利用的用戶特征和廣告特征有限, 直接訓練模型的話很可能不準,所以還需要看看其他的資料集,
3.2 廣告基本資訊表ad_feature
本資料集涵蓋了raw_sample中全部廣告的基本資訊(約80萬條目),欄位說明如下:
adgroup_id:脫敏過的廣告ID;cate_id:脫敏過的商品類目ID;campaign_id:脫敏過的廣告計劃ID;customer_id: 脫敏過的廣告主ID;brand_id:脫敏過的品牌ID;price: 寶貝的價格
這個表體現的是每個廣告的類目(id)、品牌(id)、價格特征,其中一個廣告ID對應一個商品(寶貝),一個寶貝屬于一個類目,一個寶貝屬于一個品牌,這個就是廣告的特征了, 我們用的時候,可以根據廣告id直接拼接到骨架上面,
3.3 用戶基本資訊表user_profile
本資料集涵蓋了raw_sample中全部用戶的基本資訊(約100多萬用戶),欄位說明如下:
userid:脫敏過的用戶ID;cms_segid:微群ID;cms_group_id:cms_group_id;final_gender_code:性別 1:男,2:女;age_level:年齡層次; 1234pvalue_level:消費檔次,1:低檔,2:中檔,3:高檔;shopping_level:購物深度,1:淺層用戶,2:中度用戶,3:深度用戶occupation:是否大學生 ,1:是,0:否new_user_class_level:城市層級
這個表體現的是用戶群組、性別、年齡、消費購物檔次、所在城市級別等特征,這個是用戶的特征, 其中用戶的性別,年齡, 消費檔次,是否大學生等感覺都能關聯到是否點擊某廣告,可能是強特,這個也是根據用戶id直接拼到骨架上面去,這里還有一點需要說明就是由于這個是比賽的資料集, 有些資料特征人家已經清洗好了并進行了相關的LabelEncoder編碼, 省去了我們的一些作業, 但是真實場景的資料集這些東西都是沒有的,我們一般需要拿到資料后做一波資料清洗,
有了用戶畫像特征, 廣告畫像特征, 然后再基于骨架, 其實就可以訓練一個邏輯回歸這樣的模型對點擊率進行預測了,But, 真實情境中,我們的候選廣告是非常多的, 動不動就是幾百萬幾千萬的規模,如果我們對于某個用戶,直接就用邏輯回歸模型去一個個算的話, 這個計算量可是不得了,并且還有一個弊端就是這里面可能有大量的廣告壓根就和用戶扯不上邊, 我們直接這樣搞,會白白浪費時間和資源,
所以真實情況中,我們一般在精確預測之前,會加入一個召回的步驟, 就是根據用戶的一些購買行為先召回回來一些和用戶扯上邊的廣告, 這樣至少扯上邊,和用戶發生過一些關系,這樣的話,我們就可以重點考慮這樣的一些商品了, 這樣,往往能從幾百萬的規模降到幾百的規模,這時候,我們再用邏輯回歸等精排預測就可以了呀, 寫到這里突然又讓我聯想起了資訊熵和不確定性的關系了哈哈,有沒有發現和這里很像呀, 資訊的作用在于消除不確定性, 如果一開始發現不確定性很大,我們就想辦法加入更多的資訊,召回的作用原理也和這個原理很像呀,所以一般是先召回,再排序的流程,
那么對于這個任務應該如何召回呢? 哈哈, 果真,這里也提供了一個用戶的行為日志表, 這個表就記錄了和用戶的“發生過關系”的廣告資訊了,
3.4 用戶的行為日志behavior_log
本資料集涵蓋了raw_sample中全部用戶22天內的購物行為(共七億條記錄),欄位說明如下:
user:脫敏過的用戶ID;time_stamp:時間戳;btag:行為型別, 包括以下四種:
? 型別 | 說明
? pv | 瀏覽
? cart | 加入購物車
? fav | 喜歡
? buy | 購買cate_id:脫敏過的商品類目id;brand_id: 脫敏過的品牌id;
這里以user + time_stamp為key,會有很多重復的記錄;這是因為我們的不同的型別的行為資料是不同部門記錄的,在打包到一起的時候,實際上會有小的偏差(即兩個一樣的time_stamp實際上是差異比較小的兩個時間)
這份資料體現用戶對商品類目(id)、品牌(id)的瀏覽、加購物車、收藏、購買等資訊,有了這個表,其實我們就可以在排序之前,先做一些召回的作業了,只不過有兩點需要說明,
- 第一個就是這里的用戶行為型別,這里是真實的瀏覽,加入購物車,喜歡和購買這樣的記錄,而我們如果想拿這份資料召回,比如基于協同過濾的話,我們需要把這四種行為轉換成評分,這樣計算機才能認得,比如瀏覽給1分, 加入購物車2分, 依次累加這樣
- 第二點注意的就是這里進行召回的時候,并不是直接對接的廣告, 而是商品類別或者品牌, 也就是雖然我們最后預測的是廣告是否點擊, 而這里召回只能先召回與廣告相關的商品類別和品牌,然后基于這個再選擇出有相關商品的廣告作為候選廣告,所以這點要注意,
有用戶id, 又有cat_id和評分資料, 我們其實就可以利用簡單的協同過濾先做一波召回, 找到候選商品, 再映射出候選廣告, 然后在考慮精排,來一個精準預測,
4. 簡單的流程分析
關于流程其實上面分析的差不多了, 這里再簡單總結一下,
首先明確我們的任務是對非搜索型別的廣告進行點擊率預測和推薦(沒有搜索詞、沒有廣告的內容特征資訊),
我們依賴的資料骨架就是用戶的點擊日志行為表,為了預測的更加準確, 再拼接上用戶和廣告的一些資訊,而由于我們的候選廣告太過龐大,所以我們還要先用到用戶購物的歷史行為資訊做召回,找一波候選廣告, 然后再進行排序,最后規律和產生推薦結果,
所以這樣就梳理出了, 推薦業務處理主要流程: 召回 ===> 排序 ===> 過濾,之前也接觸過一個新聞推薦的專案,也是采用的這種流程,感興趣的可以參考Datawhale組隊學習的第19期內容(那次重點放在了各個流程用到的主要方法上), 這次的推薦系統更加偏向工程化一些, 也就是用到了大資料平臺,用到了離線和在線相結合的推薦方式, 用一張圖來表示就是這樣:
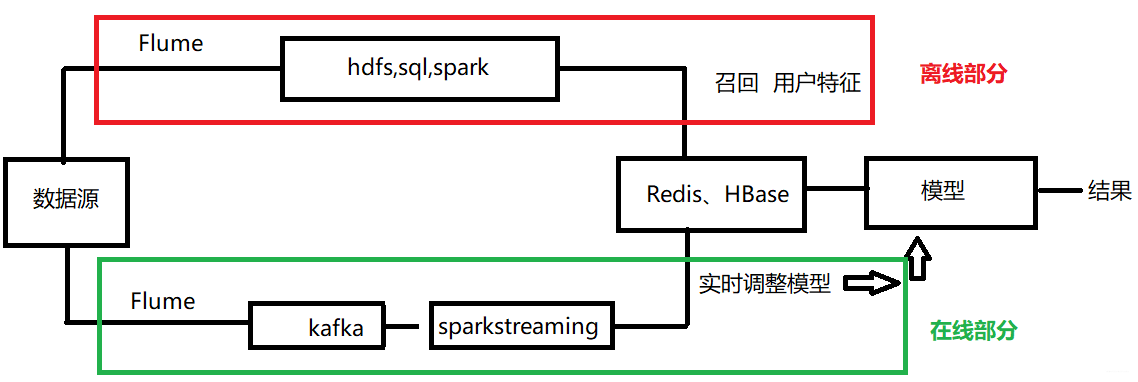
可以很清楚的看到,這次基于了大資料的框架平臺,分為了離線和在線兩部分,下面梳理一下離線處理業務流如下:
- 離線處理業務流
- raw_sample.csv ==> 歷史樣本資料
- ad_feature.csv ==> 廣告特征資料
- user_profile.csv ==> 用戶特征資料
- raw_sample.csv + ad_feature.csv + user_profile.csv ==> CTR點擊率預測模型
- behavior_log.csv ==> 評分資料 ==> user-cate/brand評分資料 ==> 協同過濾 ==> top-N cate/brand ==> 關聯廣告
- 協同過濾召回 ==> top-N cate/brand ==> 關聯對應的廣告完成召回
簡單的解釋就是先離線業務流走一遍上面的那個流程, 先處理用戶的歷史行為資料, 然后得到評分資料, 然后基于協同過濾進行召回得到候選的商品類別, 然后再去關聯廣告,得到候選的廣告,
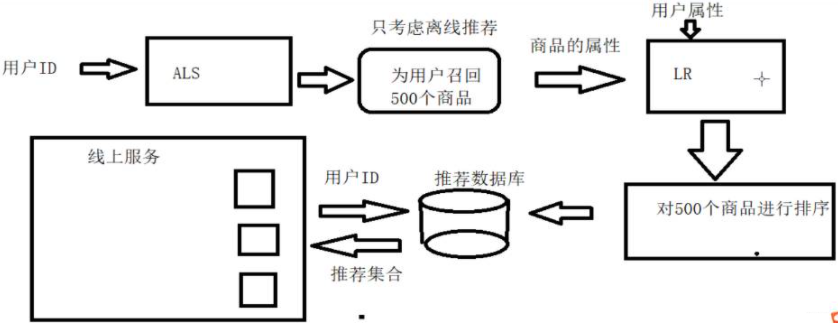
然后就是再基于點擊日志,廣告和用戶特征訓練點擊率預測的相關模型,對于候選的廣告做一個點擊率的預測,得到一個點擊概率(注意這里我們要軟概率,不能轉成0和1,畢竟對于點擊廣告來講,類別會極度不平衡), 然后根據這個點擊概率從大到小排序, 形成推薦串列(注意這個是線下的推薦串列,一成不變了)
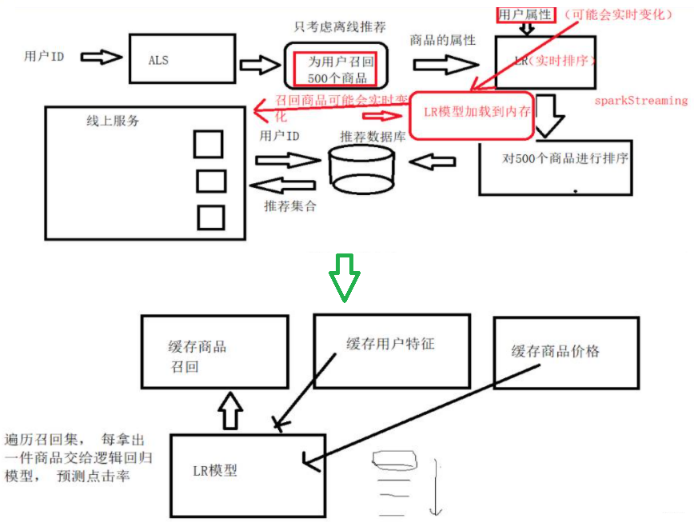
完成上面的離線之后,我們要快取用戶特征和廣告特征,然后形成在線處理業務流如下:
- 在線處理業務流
- 資料處理部分:
- 實時行為日志 ==> 實時特征 ==> 快取
- 實時行為日志 ==> 實時商品類別/品牌 ==> 實時廣告召回集 ==> 快取
- 推薦任務部分:
- CTR點擊率預測模型 + 廣告/用戶特征(快取) + 對應的召回集(快取) ==> 點擊率排序 ==> top-N 廣告推薦結果
- 資料處理部分:
這里也簡單的說一下, 如果單純的靠離線推薦的話,可能會忽略一些時效性的東西,畢竟離線推薦完畢之后存在資料庫一成不變了,沒法根據用戶的行為改變或者廣告的改變而改變推薦結果, 這樣難免會使得結果過時, 所以在線更新的思路就是基于用戶新的購買日志或者記錄來更新召回的商品類別或者品牌,然后映射出新的候選廣告,由于之前快取了廣告的特征和用戶特征, 所以基于這些又此形成新的資料對模型測驗,然后得到點擊的廣告概率,排序產生新的結果,這次的結果加入了新的資訊, 可以對推薦結果進行實時的調整,以符合用戶的興趣和品味, 這里用《數學之美》的一句話來解釋就是資訊量代表著不確定性的大小,資訊量越大,不確定性就越小,熵就越小,我們就越容易搞清楚,
好了, 這里已經把基本的業務流梳理清楚了, 下面就簡單看一下涉及到的技術了,因為是在大資料平臺上,所以用到的大部分都是大資料平臺相關技術,涉及技術:Flume、Kafka、Spark-streming\HDFS、Spark SQL、Spark ML、Redis
- Flume:日志資料收集
- Kafka:實時日志資料處理佇列
- HDFS:存盤資料
- Spark SQL:離線處理
- Spark ML:模型訓練
- Redis:快取
后期會嘗試對每個組件的理論進行整理, 這里就先用著了哈哈,在結束這篇文章之前,在了解一下與點擊率預測的幾個概念,
5. 涉及到點擊率預測的幾個相關概念
電商廣告推薦通常使用廣告點擊率(CTR–Click-Through-Rate)預測來實作, 下面看幾個概念之間的對比:
5.1 點擊率預測 VS 推薦演算法
點擊率預測需要給出精準的點擊概率,比如廣告A點擊率0.5%、廣告B的點擊率0.12%等;而推薦演算法很多時候只需要得出一個最優的次序A>B>C即可,
點擊率預測使用的演算法通常是如邏輯回歸(Logic Regression)這樣的機器學習演算法,而推薦演算法則是一些基于協同過濾推薦、基于內容的推薦等思想實作的演算法, 即使用點擊率預測, 這種方法也只是完成推薦的方式之一, 并不是唯一,
5.2 點擊率 VS 轉化率
點擊率預測是對每次廣告的點擊情況做出預測,可以判定這次為點擊或不點擊,也可以給出點擊或不點擊的概率
轉化率指的是從狀態A進入到狀態B的概率,電商的轉化率通常是指到達網站后,進而有成交記錄的用戶比率,如用戶成交量/用戶訪問量
5.3 搜索和非搜索廣告點擊率預測的區別
搜索中有很強的搜索信號-“查詢詞(Query)”,查詢詞和廣告內容的匹配程度很大程度影響了點擊概率,搜索廣告的點擊率普遍較高
非搜索廣告(例如展示廣告,資訊流廣告)的點擊率的計算很多就來源于用戶的興趣和廣告自身的特征,以及背景關系環境,通常好位置能達到百分之幾的點擊率,對于很多底部的廣告,點擊率非常低,常常是千分之幾,甚至更低
好了,關于任務資料簡介和流程就到這里了,下面我們就開始推薦業務流程的第一步:基于用戶的歷史行為資料對候選廣告進行一個召回了, 開啟我們的實戰之旅了, Rush 😉
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/249828.html
標籤:其他
上一篇:燈光 效果 調節
下一篇:安卓學習日志 — Day07