所謂機器學習,在形式上可近似等同于,在資料物件中通過統計或推理的方法,尋找一個有關特定輸入和預期輸出的功能函式 f(如圖 1 所示),通常,我們把輸入變數(特征)空間記作大寫的 X,而把輸出變數空間記作大寫的 Y,那么所謂的機器學習,在形式上就近似等同于 Y≈f(X),
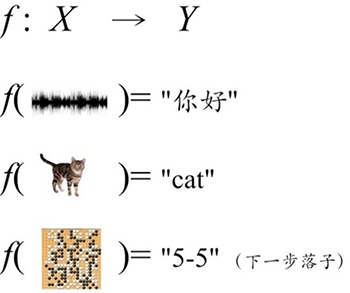
圖 1:機器學習近似于找一個好用的函式
在這樣的函式中,針對語音識別功能,如果輸入一個音頻信號,那么這個函式 f 就能輸出諸如 "你好" "How are you?" 這類識別資訊,針對圖片識別功能,如果輸入的是一張圖片,在這個函式的加工下,就能輸出(或識別出)一個或貓或狗的判定,針對下棋博弈功能,如果輸入的是一個圍棋的棋譜局勢,就能輸出這局棋的下一步“最佳”走法,
而對于具備智能互動功能的系統(比如微軟的小冰),當我們給這個函式輸入如 "How are you?" 一樣的陳述句,它就能輸出如 "I am fine, thank you." 這樣的智能回應,每個具體的輸入都是一個實體(instance),它通常由特征向量(feature vector)構成,在這里,所有特征向量存在的空間稱為特征空間(feature space),特征空間的每一個維度對應實體的一個特征,
但問題來了,這樣“好用的”函式并不那么好找,在輸入貓的圖片后,這個函式并不一定就能輸出“這是一只貓”,它可能會錯誤地輸出這是一只狗或這是一條蛇,這樣一來,我們就需要構建一個評估體系來辨別函式的好賴,當然,這中間自然需要通過訓練資料(training data)來“培養”函式的好品質,
前面我們提到,學習的核心就是改善性能,圖 2 展示了機器學習的三步走,通過訓練資料,我們把 f1 改善為 f2 的樣子,即使 f2 中仍然存在分類錯誤,但相比于 f1 的全部出錯,它的性能(分類的準確度)還是提高了,這就是學習,
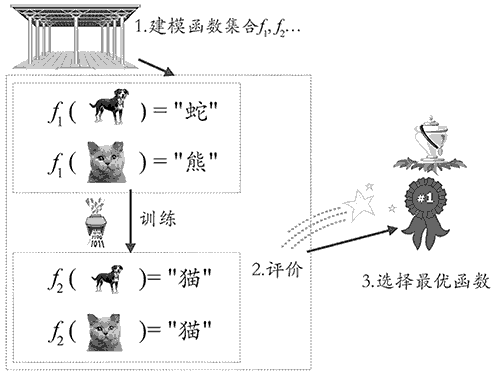
圖 2:機器學習的三步走
具體來說,機器學習要想做得好,需要走好三大步:
- 如何找到一系列的函式來實作預期功能,這是一個建模問題;
- 如何找到一系列評價標準來評價函式的好壞,這是一個評價問題;
- 如何快速找到性能最優的函式,這是一個優化問題,
習慣上,我們把具體的輸入變數、輸出變數用小寫的 x 和 y 表示,變數既可以是標量(scalar),也可以是向量(vector),除做特殊說明外,本教程所言向量均為列向量,標準的寫法如圖 3(a) 所示,但這種寫法比較占用空間,因此我們通常采用轉置的寫法,如圖 3(b) 所示,圖中的上標“T”就是轉置(Transpose)符號,
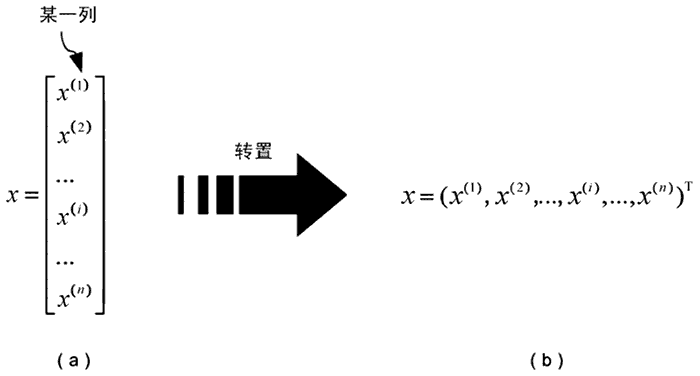
圖 3:特征向量矩陣
這里的 x(i) 表示的是輸入變數 x 的第 i 個特征,需要特別注意的是,當輸入變數有多個時,我們用 xj 表示,如此一來,xj(i) 就表示第 j 個變數的第 i 個特征,特征向量矩陣如圖 4 所示,
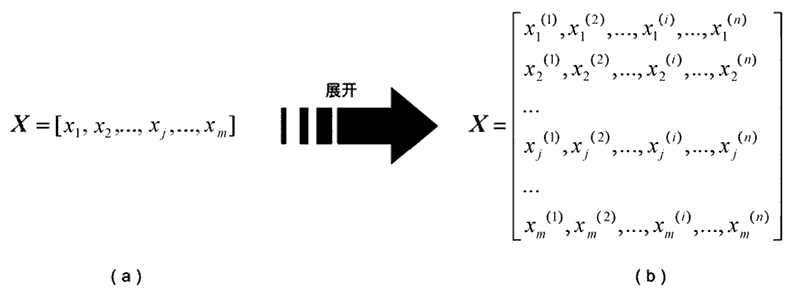
圖 4:特征向量矩陣
對于監督學習來說,所構建的模型通常在訓練資料(Training Data)集中學習,調整模型引數,然后在測驗資料(Test Data)集中進行預測驗證,
對于訓練資料,輸入信號(或變數)與輸出信號(或變數)通常是成對出現的,有時,輸出信號也被稱為“教師信號”,因為它具備指導性,可通過損失函式來“調教”模型中的引數,因此,訓練資料集通常用如下列公式所示的方式進行描來“調教”模型中的引數,因此,訓練資料集通常用如以下公式所示的方式進行描述:
T ={(x1, y1),(x2, y2),...,(xj, yj),...(xm, ym)}
輸入變數和輸出變數有不同的型別,它們既可以是連續的,也可以是離散的,通常,人們會根據輸入變數和輸出變數的不同型別,給預測任務賦予不同的名稱,比如,如果輸入變數和輸出變數均為連續變數,那么這樣的預測任務就稱為回歸(Regression),
如果輸出變數為有限的離散值,那么這樣的預測任務就稱為分類(Classification),如果輸入變數和輸出變數均為變數序列,那么這樣的預測任務就稱為標注(Tagging),我們可以認為標注是分類的一個推廣,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/251521.html
標籤:其他