ScanContext 論文閱讀筆記
- 1. 淺讀文章
- 2. 提出的方法
- 3. 演算法流程
- 3.1 Scan Context的創建
- (1) 與Shape Context的淵源
- (2) 為什么選擇Maximum height?
- (3) Partition a 3D scan
- (4) 給每個Bin進行賦值:Bin Encoding
- (5) Scan Context Matrix
- 3.2 Similarity Score的計算
- 3.3 Two-phase Search Algorithm
- (1) Ring Key
- (2) KD-Tree
- 4. Scan Context演算法延伸
- 4.1 ICP Initial Value中的應用
- 4.2 Future Works
- 參考文獻
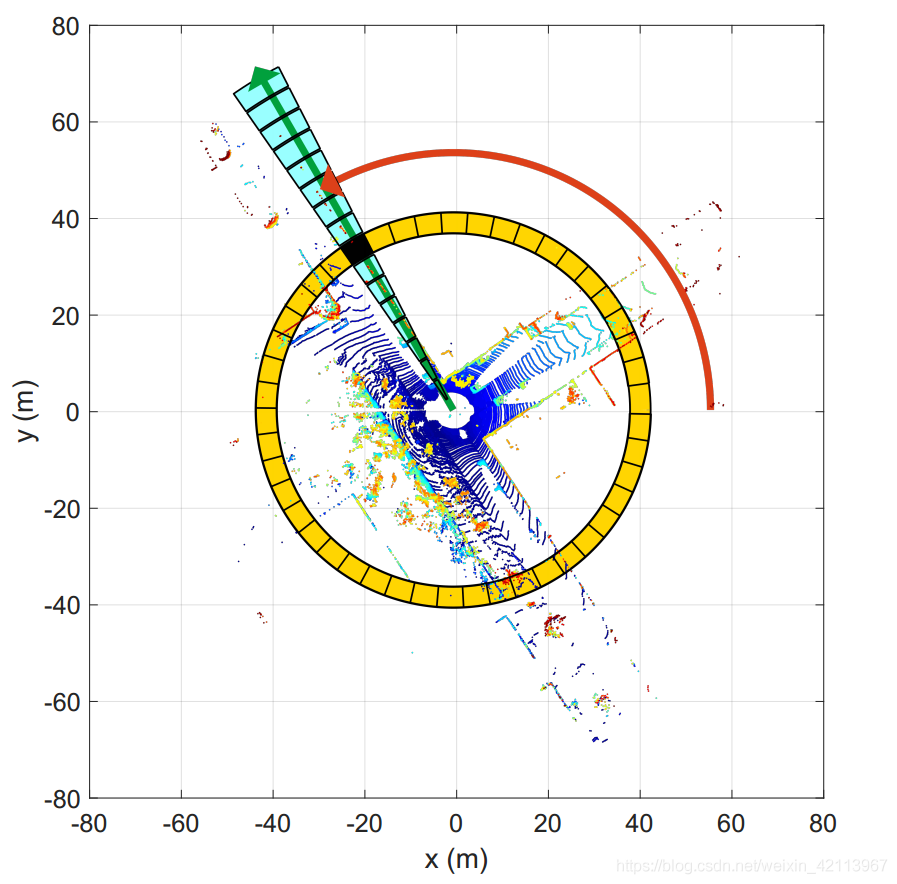

1. 淺讀文章
Scan Context,從英文字面理解就是“掃描 背景關系”,類比于我們閱讀的時候,需要理解背景關系,才能明白其意,LidarSLAM在進行回環檢測的時候,也需要將“背景關系” (之前的資料)進行比較,方才知道我們是不是又走到了之前的同一個地方(回環),
Scan Context這篇文章由韓國KAIST大學的Giseop Kim和Ayoung Kim所寫,它的主要特點是提出了Scan Context這個非直方圖的全域描述符,來幫助我們對“背景關系”(當前/之前的資料)進行更快速、有效地搜索,典型的應用就是在LiDAR SLAM中進行回環檢測和Place Recognition,
2. 提出的方法
- The representation that preserves absolute location information of a point cloud in each bin (如圖2所示)
- Efficient bin encoding function
- Two-step search algorithm
3. 演算法流程
3.1 Scan Context的創建
(1) 與Shape Context的淵源
Scan Context這個演算法其實一開始是由Shape Context [2] 所啟發的,而Shape Context是把點云的 local Keypoint 附近的點云形狀 encode 進一個影像中,Scan Context的不同在于,它不僅僅是count the number of points,而是采用了maximum height of points in each bin,
(2) 為什么選擇Maximum height?
- The reason for using the height is to efficiently summarize the vertical shape of surrounding structures.
- In addition, the maximum height says which part of the surrounding structures is visible from the sensor.
- This egocentric visibility has been a well-known concept in the urban design literature for analyzing an identity of a place
(3) Partition a 3D scan
首先,對每一次Scan進行分割:
- Nr: number of rings (黃色圈圈)
- Ns: number of sectors (淺藍色/綠色?的格子)
- Lmax: 雷達每一個射線的最遠距離
- Radial Gap between rings = L m a x N r \frac{L_{max}}{N_r} Nr?Lmax??
- Sector弧度 = 2 π N s \frac{2\pi}{N_s} Ns?2π?
- 文章中: Nr=20, Ns=60
其次,分割后的 P i j P_{ij} Pij?就是指the set of points belonging to the bin where the ith ring and jth sector overlapped,
(4) 給每個Bin進行賦值:Bin Encoding
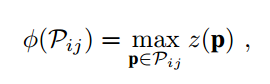
- z ( ? ) z(\cdot ) z(?) 是指point P 的Z坐標,
- 直接使用最大z坐標值 z ( p ) z(p) z(p),作為這個bin的value,
(5) Scan Context Matrix
A scan context I is finally represented as a Nr × Ns matrix as:
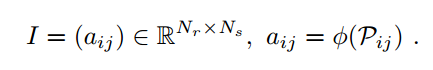
3.2 Similarity Score的計算
假設我們得到了一對Scan Context的矩陣,我們要計算他們倆( I p , I c I_p, I_c Ip?,Ic?)之間的相似度,文章中采用了columnwise (按列) 的距離計算,
- I q I_q Iq?: Query Point Cloud (簡言之,我們當前用來query的點云)
- I c I_c Ic?: Candidate Point Cloud (咱們的“資料庫”中儲存的用來匹配的candidate點云)
- c j q c^{q}_{j} cjq?: Column j of Query Point Cloud (列向量)
-
c
j
c
c^{c}_{j}
cjc?: Column j of Candidate Point Cloud (列向量)
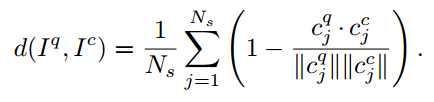
小紅薯:且慢,大師兄!
小紅薯:古希臘哲學家赫拉克利特說,“人不能兩次踏進同一條河流”,
小紅薯:這樣來比較兩個點云,而沒考慮每次不可能在exactly同一個位置和角度觀察,是不是too young, too simple了呢!
–
大師兄:恩,這是個好問題,假設咱們回到同一個地方,那有可能是沿著相反的方向回來的,那咱們的Viewpoint就發生了變化,這個Scan Context矩陣就會發生偏移!這樣就會導致Column順序發生變化,
大師兄:所幸的是,只要location是在同一個地方,不管你的方向朝著哪里,至少row order不會發生太大變化,咱們只需要關心column shift這個問題,
在文章中,上面大師兄和小紅薯對話中的問題,如下圖所示:
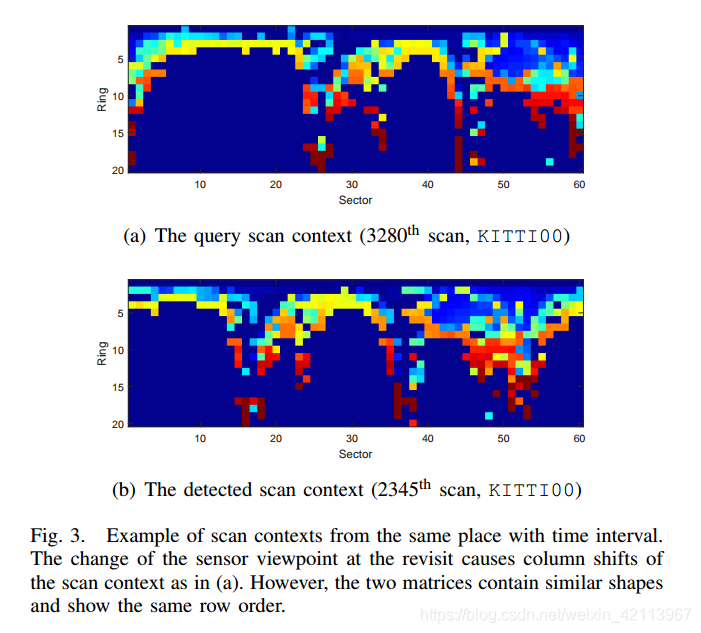
咱們可以看到在column方向發生了水平位移,但是豎著的row方向沒有變化,
為了解決這個問題,文中采用了一個“地球人都能想到的方法”,那就是不斷嘗試各種角度的column shift,注意的是,旋轉candidate point cloud有個resolution,那就是之前提到的
2
π
N
s
\frac{2\pi}{N_s}
Ns?2π?,
我們使用公式(7)進行最佳shift的選擇,找到最好的
n
?
n^{*}
n?后,用公式(6)進行distance計算,
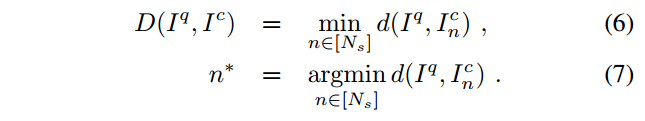
注意:這里咱們通過找最好的 n ? n^* n?,還有一個意想不到的好處,那就是可以給ICP提供一個Good initial rotation value! (就是ICP代碼中的predicted pose)
3.3 Two-phase Search Algorithm
文中提到,有三種主流的Place Recognition的Search Algorithm:
- Pairwise Similarity Scoring
- Nearest Neighbor Search搜索
- Sparse Optimization
本文中采用了pairwise scoring和nearest search來實作有效的Hierarchical Search,
(1) Ring Key
在3.2節中我們提到的公式(6)進行最短距離計算時,要先找到最佳旋轉 n ? n^* n?,計算量很大,所以在本文中提出了一種"Two-phase Search",并提出了Ring key這個Descriptor(描述子)來進行匹配搜索:
Ring key is a rotation-invariant descriptor, which is extracted from a scan context. Each row of a scan context, r, is encoded into a single real value via ring encoding function . The first element of the vector k is from the nearest circle from a sensor, and following elements are from the next rings in order as illustrated in Fig. 4
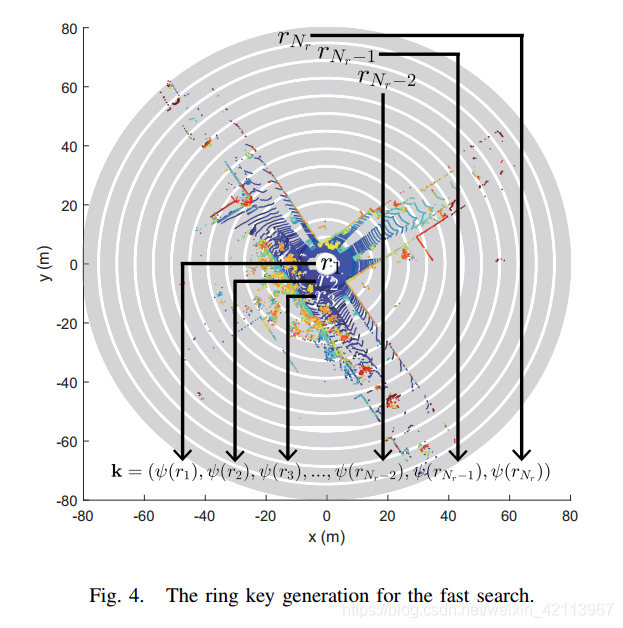
由內而外,一圈一圈的ring key通過對Scan Context Matrix的每一行row
r
r
r進行
ψ
(
?
)
\psi(\cdot)
ψ(?)的encoding就變成了一個
N
r
N_r
Nr?維度的Vector
k
\textbf{k}
k:
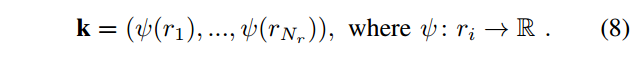
The ring encoding function
ψ
\psi
ψ is a occupancy ratio using
L
0
L_0
L0? norm:
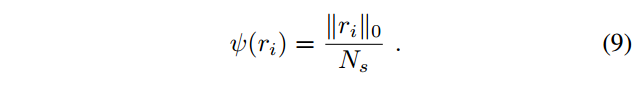
小紅薯:大師兄,這里的 ∣ ∣ r i ∣ ∣ 0 ||r_i||_0 ∣∣ri?∣∣0?是什么意思呢?
大師兄:這是 L 0 L_0 L0? norm(范數)的意思,其實 L 0 L_0 L0? norm并不是一個真正的norm,它就是the total number of non-zero elements in a vector ,比如,(2,0,1,0,9)這個vector的 L 0 L_0 L0? norm就是3,因為有3個非零數,
大師兄: 這樣一來,咱們統計每一圈的row中有多少個非零數值,那這就和rotation沒啥關系啦(也就是原文中所說的rotation invariance)!這樣就能夠達到快速的search,
(2) KD-Tree
- 在得到ring key向量 k \textbf{k} k 之后,文章用了 k \textbf{k} k構建KD Tree,
- 用ring key of the query到這個KD Tree中搜索K個最相似的scan indexex(K是個heuristic number)
- 得到最相似的K個scan后,用上文中公式(6)進行Similarity Score計算
- 滿足條件的最近的candidate
c
?
c^*
c?這個位置被選為revisited place,也就是loop的地方:
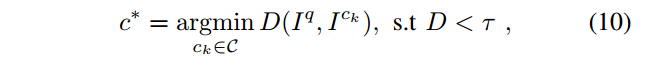
4. Scan Context演算法延伸
4.1 ICP Initial Value中的應用
由上文3.2節的公式(7)需要找到一個 n ? n^* n?旋轉,使得兩個點云之間的距離最小,這里其實也可以作為ICP的一個初始值,即predicted pose,來加快converge的程序,
文章的Experiment部分對此進行了試驗,發現用Scan Context進行ICP初始化效果確實更好:
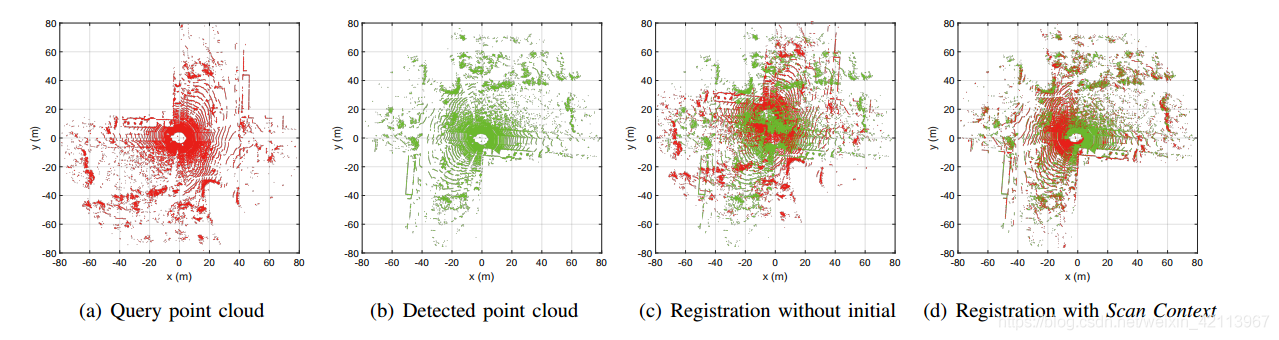
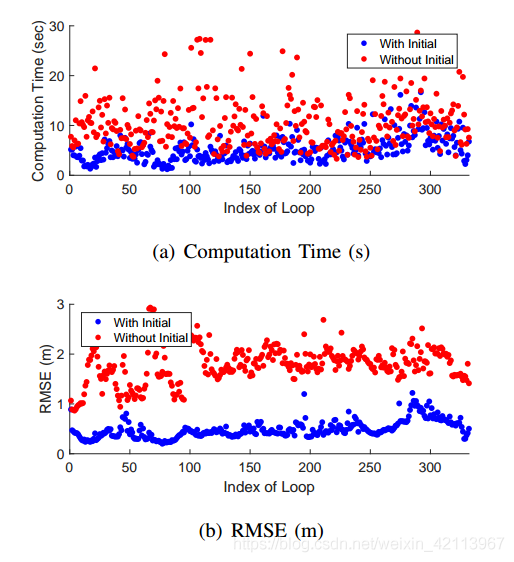
4.2 Future Works
在文章最后,作者提到可以使用更好的bin encoding function (eg., a bin’s segmantic information)來提升性能,目前咱們只是用了一個很簡單的 m a x Z ( p ) max\ Z(p) max Z(p)來找Z軸高度上的最高點,
對于有夢想的讀者,也期待你的貢獻!
參考文獻
[1] G. Kim and A. Kim, “Scan Context: Egocentric Spatial Descriptor for Place Recognition Within 3D Point Cloud Map,” 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, 2018, pp. 4802-4809, doi: 10.1109/IROS.2018.8593953.
[2] S. Belongie, J. Malik, and J. Puzicha, “Shape matching and object recognition using shape contexts,” IEEE Trans. Pattern Analysis and Machine Intell., vol. 24, no. 4, pp. 509–522, 2002.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/259978.html
標籤:AI
下一篇:華為 MPLS的資料轉發流程