功能描述:基于上一篇“資料檔案自動生成的實作(多模塊進階)”文章,對工程專案進行包括使用.ini檔案存盤配置引數、增加.dat檔案(二進制檔案)的方式記錄隨機生成資料、利用結構體陣列暫存隨機生成資料和呼叫程式計時函式對程式計時等功能的優化改造,
關鍵詞:.ini組態檔;結構體陣列;.dat二進制檔案;程式計時
讀者注意:本文章基于此前兩篇文章寫作,若對部分代碼有疑惑,可查看
<C語言>資料檔案自動生成的實作
<C語言>資料檔案自動生成(多模塊進階)
0 緒論
一個程式要走向實用是需要和編譯器、編譯環境脫離開的,我們的程式在編譯環境下創建,每次對程式的更改,哪怕只是某個數值的變化都需要編譯器重新編譯才能使用,這種開放式的程式給了用戶極大的權限和自由,但不恰當的操作也會導致系統崩潰,所以一般實用程式為了使用安全(或保護著作權),對外都是全封閉的,而滿足用戶對程式某些引數進行配置的需求,是通過使用組態檔來實作的,這就好比使用智能手機時,在同一套程式下,可以使用設定工具改變一些使用習慣的程序(程式的某些引數發生了變化),
1 通過.ini檔案獲取配置引數
- .ini 檔案是Initialization File的縮寫,即初始化檔案,是 windows 的系統組態檔所采用的存盤格式,統管 windows 的各項配置;
- 組態檔有很多如INI組態檔,XML組態檔,還有就是可以使用系統注冊表等, 當然INI組態檔的后綴名也不一定是 .ini ,也可以是 .cfg,.conf 或者是 .txt;
- .ini 檔案同 .txt 檔案等都使用ASCII編碼,用戶可以在記事本或寫字板對其內容進行讀寫操作;
- INI組態檔有其經典格式:包含 parameters,sections 和 comments 三個基本要素,本工程中只是最簡單的利用 .ini 檔案存盤個別數值,當作一般 .txt 檔案使用,所以在這里不作過多探究,
將 .ini 檔案獲取配置引數的程式封裝為一個函式,并單獨作為一個源檔案,
實際上這種極簡單的組態檔類似于此前說到的 cmd 命令視窗,兩者都作為一種程式內外互動的方式,若其格式不規范會造成程式無法正常運行,此前工程引入了大量程式以確保命令列引數的規范性問題,此處也應對組態檔的內容進行一定的鑒別,
具體代碼如下:
//獲取組態檔資訊給結構體初始化默認值,CONF* conf(配置引數結構體指標),char* Ini_Path(組態檔檔案名指標)
void getInfoParam(CONF* conf, char* Ini_Path)
{
char str[MAX_STR_LEN] = {0};
int flag = 0;//規范性標志位,為0時表示規范
int hang = 0;//組態檔有效行數值
FILE *fp = NULL;
fp = fopen(Ini_Path, "r");//ini檔案是用ASCII值的檔案,用"r"
if(!fp)
{
printf("打開組態檔失敗,結構體各分量已使用默認值!\n");
flag = 1;
}
else
{
while(!feof(fp))
{
fgets(str, sizeof(str), fp);
if(*str != 0 && strcmp(str, "\n") != 0)//篩除空行
{
hang++;
}
memset(str, 0, sizeof(str));//清除字串str中的資料
}
if(hang >= 8)
{
rewind(fp);//指標回到檔案打開初始位置
strcpy(conf->filesavepath, fgets(str, MAX_STR_LEN, fp));
strcpy(conf->filename, fgets(str, MAX_STR_LEN, fp));
conf->maxvalue1 = strToNumber(fgets(str, MAX_BUF, fp));
conf->minvalue1 = strToNumber(fgets(str, MAX_BUF, fp));
conf->maxvalue2 = strToNumber(fgets(str, MAX_BUF, fp));
conf->minvalue2 = strToNumber(fgets(str, MAX_BUF, fp));
conf->recordcount1 = strToNumber(fgets(str, MAX_BUF, fp));
conf->recordcount2 = strToNumber(fgets(str, MAX_BUF, fp));
if(strcmp(conf->filesavepath, "\n") == 0 || strcmp(conf->filename, "\n") == 0 || conf->maxvalue1 == 0 || conf->minvalue1 == 0 || conf->maxvalue2 == 0 || conf->minvalue2 == 0 || conf->recordcount1 == 0 || conf->recordcount2 == 0)//篩除空行賦值
{
printf("組態檔引數值有誤,結構體各分量已使用默認值!\n");
flag = 1;
}
else if(conf->maxvalue1 <= conf->minvalue1 || conf->maxvalue2 <= conf->minvalue2 || conf->recordcount1 <= conf->recordcount2)//篩除不正確的值關系
{
printf("組態檔引數值有誤,結構體各分量已使用默認值!\n");
flag = 1;
}
else
{
printf("組態檔配置結構體分量初始值成功!\n");
}
}
else
{
printf("組態檔引數數目不足,結構體各分量已使用默認值!\n");
flag = 1;
}
fclose(fp);
}
//組態檔出錯,結構體初始默認值
if(flag == 1)
{
strcpy(conf->filesavepath, "Lab4Data\\");
strcpy(conf->filename, "Lab4.txt");
conf->number = 0;
conf->maxvalue1 = 20;
conf->minvalue1 = 1;
conf->maxvalue2 = 100;
conf->minvalue2 = 0;
conf->recordcount1 = MAX_NUM;
conf->recordcount2 = MIN_NUM;
}
}
由代碼及注釋可以看出,為保證程式的運行,在組態檔的內容不規范時直接進行了報錯,而組態檔的錯誤區分三種情況:一是組態檔行數(引數個數)小于結構體所需引數個數,為避免空行對行數的影響,判斷時做空行篩除處理;二是組態檔在有效行數(有效引數個數)大于等于結構體所需引數個數時,給結構體成員按序賦值,為避免空行對結構體成員賦無效值,對所有結構體成員值做篩除處理;三是在滿足上述兩點情況下邏輯判斷三組 int 值的大小,最大值不可小于等于最小值,
滿足以上三點才認為組態檔內容規范正確,這極大保障了程式的安全運行,若組態檔內容不符合要求,程式設定結構體各成員使用程式內給出的初始默認值以繼續運行,
2 利用結構體陣列暫存資料
仍然使用 typedef 關鍵字定義結構體,結構體 DataItem 內部存盤的是三元組的三個資料,多個結構體組成結構體陣列,結構體陣列依次存入 conf.number 條三元組資料,
結構體定義代碼如下:
typedef struct DataItem
{
int item1; //資料記錄三元組的第一個元素
int item2; //資料記錄三元組的第二個元素
int item3; //資料記錄三元組的第三個元素
}DATAITEM;
在此前的文章中,使用的是二維陣列的方式來快取隨機生成的資料記錄,因為二維陣列只有行數不定,而列數始終為3,所以使用結構體陣列非常合適,這里優先使用結構體陣列,因為二維陣列的動態記憶體申請函式 malloc的使用和釋放都是是分為兩步進行的,而結構體陣列只需要一步即可(去掉for回圈程序),將兩者代碼作對比如下:
//二維陣列動態記憶體申請
int **a = (int**)malloc(sizeof(int*) * n); //申請n行動態記憶體分配空間
for (int i = 0; i < n; i++)
{
a[i] = (int *)malloc(sizeof(int) * 3); //申請3列動態記憶體分配空間
}
//二維陣列動態記憶體釋放
for (int i = 0; i < n; i++)
{
free(a[i]); //逐個釋放指標記憶體
}
free(a); //釋放指向指標的二級指標記憶體
//結構體陣列態動態記憶體申請
DATAITEM *s, *p;
s = (DATAITEM*)malloc(sizeof(DATAITEM) * conf.number);//申請conf.number個動態結構體陣列
p = s;
//結構體陣列態記憶體釋放
free(s);
注意到使用了兩個指標 s 和 p 指向結構體陣列,指標 s 申請了動態記憶體空間,不讓指標 s 進入到 for 回圈而使用指標 p 進入回圈,是因為指標 p 在回圈里每回圈一次執行 p++ 時,其值都會被修改,每次給指標 p 的成員賦值后都存入回圈外的指標 s 即可給結構體陣列依次賦值,
DATAITEM *s, *p;
s = (DATAITEM*)malloc(sizeof(DATAITEM) * conf.number);//申請conf.number個動態結構體陣列
p = s;
for(int i = 0; i < conf.number; i++)
{
p->item1 = random(conf.maxvalue1, conf.minvalue1);
p->item2 = random(conf.maxvalue1, conf.minvalue1);
while(p->item2 == p->item1) //取第二項值不同于第一項值
{
p->item2 = random(conf.maxvalue1, conf.minvalue1);
}
p->item3 = random(conf.maxvalue2, conf.minvalue2);
p++;
}
3 使用.dat檔案以二進制存盤數值(位元組序)
在前兩篇文章中都是使用了 .txt 檔案存盤文本檔案,使用 .dat 檔案存盤二進制檔案的操作與其是極為相似的,該工程可以同時生成這兩種格式的檔案,故將兩者程式對比如下:
//生成.txt文本檔案
FILE *fpt = NULL;
fpt = fopen(buffer,"w");
if(!fpt)
{
printf("檔案打開失敗!\n");
}
else //檔案打開/創建成功
{
start = clock();
fprintf(fpt, "%d\n", conf.number);//在檔案中列印條數資訊
//將結構體陣列s中的元素列印到檔案中
for (int i = 0; i < conf.number; i++)
{
fprintf(fpt, "%d,%d,%d", s[i].item1, s[i].item2, s[i].item3);
fprintf(fpt,"\n");
}
fclose(fpt); //關閉檔案
printf("輸出文本檔案‘%s’生成成功!\n",conf.filename);
end = clock();
printf("生成文本檔案時間:%fs\n", (double)(end - start) / CLOCKS_PER_SEC);
}
//生成.dat二進制檔案
FILE *fpd = NULL;
fpd = fopen(new_buffer,"wb");
if(!fpd)
{
printf("檔案打開失敗!\n");
}
else //檔案打開/創建成功
{
start = clock();
fwrite((char*)&conf.number, sizeof(int), 1, fpd);//在檔案中列印條數資訊
char ch[]="\n\r";
fwrite(ch, 2, 1, fpd);
//將結構體陣列s中的元素列印到檔案中
for (int i = 0; i < conf.number; i++)
{
fwrite(&s[i], sizeof(int), 3, fpd);
char ch[]="\n\r";
fwrite(ch, 2, 1, fpd);
}
fclose(fpd); //關閉檔案
printf("輸出二進制檔案‘%s’生成成功!\n", new_filename);
end = clock();
printf("生成二進制檔案時間:%fs\n", (double)(end - start) / CLOCKS_PER_SEC);
}
可以看到,首先是檔案打開/創建的方法不同,.txt 文本檔案使用"w"進行寫操作, .dat 二進制檔案使用"wb"進行寫操作,然后兩者的資料寫入函式不同,在 .txt 文本檔案中寫入資料呼叫的是 fprintf() 函式,而在 .dat 二進制檔案中寫入資料呼叫的是 fwrite() 函式,fprintf() 函式更像我們平時使用的 printf() 函式,換行操作可以直接用“\n”實作,符號寫入也可以直接寫入,而 fwrite() 函式需要單獨寫入"\n\r"這個兩位元組長度的符號才可以,因為二進制檔案的不具備直接閱讀性,所以可省略所有可視化符號的寫入,程式中的換行符亦不需要("\n"是換行符,"\r"是游標移動到行首),
對于整數的二進制存,二進制檔案有位元組序的概念,位元組序即位元組在電腦中存放時的序列與輸入(輸出)時的序列是先到的在前還是后到的在前,
常見的位元組序是小端模式(Little endian) 和 大端模式(Big endian),小端模式最符合人的思維,地址低位存盤值的低位,地址高位存盤值的高位;大端模式最直觀,地址低位存盤值的高位,地址高位存盤值的低位,把記憶體地址從左到右按照由低到高的順序寫出,把值按照通常的高位到低位的順序寫出,
對于作業系統之上的應用程式來說,位元組序實際上是由作業系統和編譯器決定的,而作業系統和編譯器所提供給應用程式的運行環境的默認位元組序一定是CPU支持的位元組序,
可以構造一個函式用來檢測這兩種常用位元組序,函式如下所示:
void test_endian()
{
uint32_t i = 0x04030201;
unsigned char* cp=(unsigned char*)&i;
if(*cp == 1)
printf("本實驗是小端位元組序(little-endian)\n");
else if(*cp == 4)
printf("本實驗是大端位元組序(big-endian)\n");
else
printf("位元組序未知\n");
}
其中 uint32_t 在標準頭檔案 stdint.h 中定義,
4 呼叫程式計時函式對程式計時
這里主要介紹C語言對程式計時的三種常用方法;
方法一:clock() 函式,函式原型:clock_t clock(void)
其中clock函式回傳從開始這個程式到呼叫的clock()函式之間的CPU時鐘計時單元(click tick)數, 回傳值型別是clock_t,其中CLOCKS_PER_SEC是一個已宏定義的常數(通常為1000),表示1秒鐘有多少個時鐘計時單元,精確值:精確到毫秒,
#include <time.h>
int main()
{
clock_t start, end;
start = clock();
/*...需要計時的代碼...*/
end = clock();
printf("time=%f\n", (double)(end - start) / CLOCKS_PER_SEC);
return0;
}
方法二:time() 函式,difftime() 函式,函式原型:time_t time(time_t, * timer),double difftime(time_t, time_t)
在C語言中用 time() 函式獲取自Unix標準時間戳(1970年1月1日0點0分0秒,GMT)到當前的秒數, difftime(t2 - t1) 要比 t2 - t1 更準確,diffime會根據機器進行轉換,精確值:精確到秒
#include <time.h>
int main()
{
time_t start, end;
start = time(NULL);
/*...需要計時的代碼...*/
end = time(NULL);
printf("time = %d秒\n", difftime(end, start));
return0;
}
方法三:gettimeofday() 函式,函式原型:int gettimeofday(struct timeval *tv, struct timezone *tz)
這個函式是 linux 系統專屬函式,可以精確到微秒,其中引數 tv 是保存獲取時間的結果型別,引數 tz 用于保存時區結果(若不使用可以傳入NULL) ,精確值:精確到微秒,
#include <time.h>
int mian()
{
struct timeval start, end;
gettimeofday(&start, NULL);
/*...需要計時的代碼...*/
gettimeofday(&end, NULL);
longtimeuse = 1000000*(end.tv_sec - start.tv_sec) + end.tv_usec-start.tv_usec;
printf("time =%f 秒\n", timeuse/1000000)
return0;
}
方法一能使用于大多作業系統,本工程也使用該函式進行程式計時,具體使用代碼在文本檔案和二進制檔案生成代碼中可以看到;
方法二統計的時間精確到秒,針對的是運行時間較長,或者有明顯的時間差的程式,可移植性好,性能穩定,在設定隨機種子已多次使用;
方法三是 linux 系統專屬使用方法,
本工程使用方法一對生成資料存入結構體、生成文本檔案、生成二進制檔案三個程序的時間進行了資訊列印,在對應程序位置可看到相應秒數,
5 測驗運行
區別于前兩篇文章,本工程在命令列引數輸入之外還有組態檔的讀入,在程式處理順序上,對命令列引數的處理滯后于對組態檔的處理,測驗分為兩部分進行:
5.1 組態檔測驗
情況1:行數為8行,有效行數為7行(中間空行),應輸出“組態檔引數數目不足……”
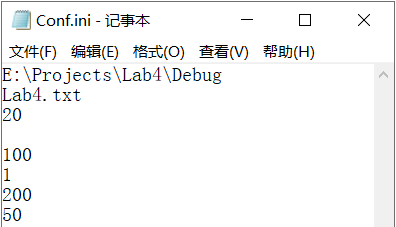
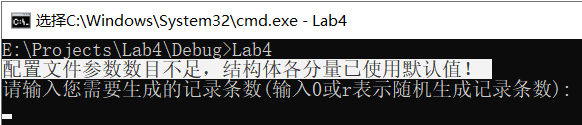
情況2:行數為8行,有效行數為7行(作結束行空行),應輸出“組態檔引數數目不足……”

以上兩情況輸出如下所示:
情況3:行數為9行,有效行數為8行(字符為“\n”),應輸出“組態檔引數值有誤……”

情況4:行數為9行,有效行數為8行(數值為0),應輸出“組態檔引數值有誤……”

情況5:行數為8行,有效行數為8行(第一組最大最小值相等),應輸出“組態檔引數值有誤……”
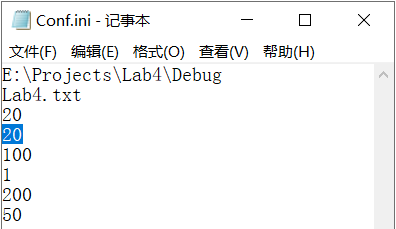
以上三情況輸出如下所示:
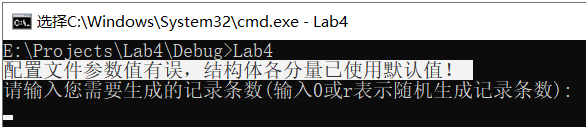
情況6:行數為8行,有效行數為8行(格式規范),應輸出“組態檔配置結構體分量初始值成功!”
以上情況輸出如下所示:
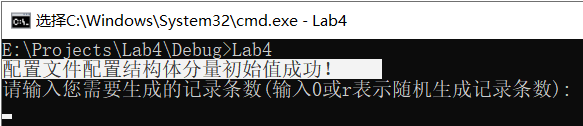
由以上6種情況可以看到,只有當有效行數大于等于8時,組態檔才會依次給結構體成員賦值,且能確保結構體的8個成員都能取到有效值(非空非0),還要在各取值區域符合大小關系時,組態檔才會配置結構體分量初始值成功,
為了使組態檔在有誤狀態下程式依然能夠繼續運行下去,當判斷到任何錯誤情況,程式都會默認使用內部設定的結構體成員初始化默認值,所以在錯誤情況列印資訊中能看到“結構體各分量已使用默認值!”的字樣,以上系列判斷措施都是對程式健壯性的增強,
5.2 命令列引數測驗
以下測驗是基于組態檔規范正確的情況下進行的,即使考慮組態檔一旦有誤,結構體各分量也會使用初始化默認值(和規范正確組態檔取同值,多一個 conf->number 的賦值無影響),
命令列引數輸入情況如下:
1.“Lab4 r . .\Debug\test1 a” 一次輸入,應:隨機生成[50, 200]間的記錄條數,路徑存在,生成資料存入“test1.txt” 和 “test1.dat”;
2.“Lab4 r . .\Debug\test2 d” 一次輸入,應:隨機生成[50, 200]間的記錄條數,路徑存在,生成資料存入“test2.dat”;
3.“Lab4 r . .\Debug\test3 t” 一次輸入,應:隨機生成[50, 200]間的記錄條數,路徑存在,生成資料存入“test3.txt”;
4.“Lab4 r . .\Debug\test4 qa” 一次輸入,應:隨機生成[50, 200]間的記錄條數,路徑存在,默認生成兩種檔案,生成資料存入“test4.txt” 和 “test4.dat”;
5.“Lab4 r . .\Debug\test5” 一次輸入,應:隨機生成[50, 200]間的記錄條數,路徑存在,生成資料存入“test5.txt” 和 “test5.dat”;
6.“Lab4 . .\Debug\test6 r a” 、“r” 依次輸入,應:隨機生成[50, 200]間的記錄條數,路徑使用當前作業目錄,生成資料存入“r.txt” 和 “r.dat”;
7.“Lab4 . .\Debug\test7 r a c” 一次輸入,應:輸入引數超限制,系統無法處理;
8.“Lab4” 、“r” 、“. .\Debug\test8”依次輸入,應:隨機生成[50, 200]間的記錄條數,路徑使用當前作業目錄,生成資料存入“test8.txt” 和 “test8.dat”;
測驗1~8結果如下四圖所示:

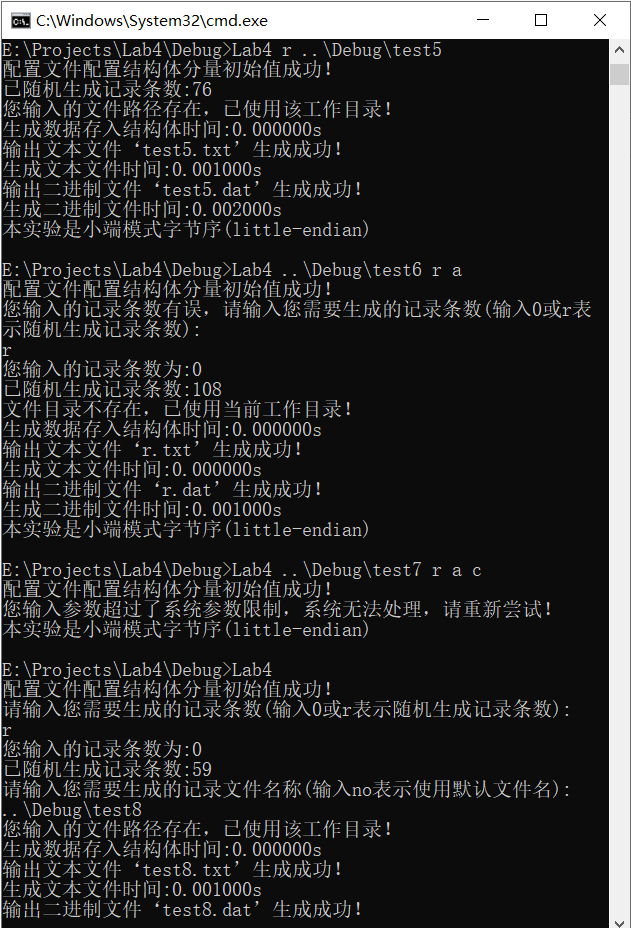
由測驗結果可見各列印資訊與邏輯推斷相同,生成的各值均在上下限范圍內(包括隨機生成條數和各元素資料數值),對于二進制檔案需要特定軟體打開,此處不進行查看,
6 工程代碼
工程專案下載鏈接:https://download.csdn.net/download/qq_41804982/17813271
本工程對各功能模塊進行了函式封裝,格式規范、注釋詳細、易于閱讀,
7 寫在后面
【相對路徑】對相對路徑的正確輸入格式做一下說明:正確格式為". .\Lab4\Debug\test.txt “,檔案C語言中單斜杠“\”一般用于轉義字符,若表示路徑中的單斜杠,最好使用“\ \”表示,更加安全,所以用”. .\ \Lab4\ \Debug\ \test.txt "更好,因為該軟體在撰寫會自動轉義輸出,為了展現時不出錯,在相同符號間添加了空格隔開,所以讀者看到的以上路徑中會有空格,在使用時請自行去除空格,
【測驗作業】到現在作者愈發意識到測驗作業的重要性,每次寫文章,測驗運行這一塊總是最耗時耗力的,測著測著就會發現有意外發生,然后又去代碼里看出錯的地方,有時錯誤比較隱蔽,還需要監視各個變數才能查找出來,這之后又重頭進行新一輪測驗,以讓讀者看到的測驗程序無誤呈現,當然,限于水平,仍有一些錯漏之處在所難免,若作者對讀者形成了誤導,敬請諒解,
8 參考資料
<C語言>資料檔案自動生成的實作https://blog.csdn.net/qq_41804982/article/details/114909367
<C語言>資料檔案自動生成(多模塊進階)https://blog.csdn.net/qq_41804982/article/details/115958867
C語言讀取.ini組態檔:
https://www.jianshu.com/p/6088c3c2488d
https://blog.csdn.net/chexlong/article/details/6818017
https://blog.csdn.net/weixin_33737134/article/details/94273057
結構體陣列:
https://bbs.csdn.net/topics/280016730
二進制檔案:
https://baike.baidu.com/item/fwrite/10942398?fr=aladdin https://blog.csdn.net/Megurine_Luka_/article/details/104451789
位元組序判斷:
https://blog.csdn.net/earbao/article/details/53668806
程式計時函式:
https://www.douban.com/group/topic/127994831/
感謝眾多網友的系列參考資料,在此向所列資料作者致謝,也向一些缺漏的作者致歉,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/280554.html
標籤:其他