深度學習入門-與學習相關的技巧
目錄
摘要
1. 引數的更新
1.1 SGD
1.2 SGD 的缺點
1.3 Momentum(動量)
1.4 AdaGrad
1.5 Adam
1.6 最優化方法的比較
1.7 基于 MNIST 資料集的更新方法的比較
2. 權重的初始值
3. Batch Normalization(批歸一化)
4. 正則化
5. 超引數的驗證
摘要
- 引數更新方法:SGD、Momentum、AdaGrad、Adam 等,
- 權重初始值的賦值方法對進行正確的學習非常重要,
- 作為權重初始值,Xavier 初始值、He 初始值等比較有效,
- 通過使用 Batch Normalization(批歸一化),可以加速學習,并且對初始值變得健壯,
- 抑制過擬合的正則化技術有:權值衰減、Dropot 等,
- 逐漸縮小 “好值” 存在的范圍是搜索超引數的一個有效方法,
1. 引數的更新
最優化(optimization):
神經網路的學習的目的是找到使損失函式的值盡可能小的引數,這是尋找最優引數的問題,解決這個問題的程序稱為最優化(optimization),
隨機梯度下降法(stochastic gradient descent):
使用引數的梯度,沿梯度方向更新引數,并重復這個步驟多次,從而逐漸靠近最優引數,這個程序稱為隨機梯度下降法(stochastic gradient descent),簡稱 SGD,
1.1 SGD
SGD 用數學式表示如下式 (5.1),
:需要更新的權重引數;
:損失函式關于
:學習率(實際上會取 0.01 或 0.001 這些事先決定好的值);
:表示用右邊的值更新左邊的值,
Python 實作 SGD:
class SGD(object):
"""隨機梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr # 學習率
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]1.2 SGD 的缺點
如果函式的形狀非均向(anisotropic),比如呈延伸狀,所有的路徑就會非常低效,SGD 低效的根本原因是,梯度的方向并沒有指向最小值的方向,
1.3 Momentum(動量)
Momentum 用數學式表示如下式 (5.2)、(5.3),
:表示了物體在梯度方向上受力,在這個力的作用下,物體的速度增加這一物理法則;
:在物體不受任何力時,該項承擔使物體逐漸減速的任務(
設定為 0.9 之類的值),對應物理上的地面摩擦力或空氣阻力;
Python 實作 Momentum:
import numpy as np
class Momentum(object):
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr*grads[key]
params[key] += self.v[key]1.4 AdaGrad
學習率衰減(learning rate decay):
隨著學習的進行,使學習率逐漸減小,
AdaGrad 用數學式表示如下式 (5.4)、(5.5),
:保存了以前的所有梯度值的平方和;
使用 RMSProp 方法改善 AdaGrad 無止境學習時更新量變為 0 的情況:
AdaGrad 會記錄過去所有梯度的平方和,因此,學習越深入,更新的幅度就越小,實際上,如果無止境地學習,更新量就會變為 0,完全不再更新,
RMSProp 方法并不是將過去所有的梯度一視同仁地相加,而是逐漸地遺忘過去的梯度,在做加法運算時將新梯度的資訊更多地反映出來,這種操作從專業上講,稱為 “指數移動平均”,呈指數函式式地減小過去的梯度的尺度,
Python 實作 AdaGrad 和 RMSProp :
import numpy as np
class AdaGrad(object):
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSProp(object):
"""RMSProp"""
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)1.5 Adam
Adam:直觀理解,就是融合了 Momentum 和 AdaGrad 的方法,可以實作引數空間的高效搜索和進行超引數的 “偏置矯正”,論文地址:http://arxiv.org/abs/1412.6980v8,
Python 實作 Adam:
import numpy as np
class Adam(object):
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr # 學習率
self.beta1 = beta1 # 一次momentum系數
self.beta2 = beta2 # 二次momentum系數
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)1.6 最優化方法的比較
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
"""優化器"""
class SGD(object):
"""隨機梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr # 學習率
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
class Momentum(object):
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr*grads[key]
params[key] += self.v[key]
class Nesterov:
"""Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSProp(object):
"""RMSProp"""
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class Adam(object):
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr # 學習率
self.beta1 = beta1 # 一次momentum系數
self.beta2 = beta2 # 二次momentum系數
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
"""優化器比較"""
def f(x, y):
return x**2 / 20.0 + y**2
def df(x, y):
return x / 10.0, 2.0 * y
init_pos = (-7.0, 2.0)
params = {}
params["x"], params["y"] = init_pos[0], init_pos[1]
grads = {}
grads["x"], grads["y"] = 0, 0
optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=0.95)
optimizers["Momentum"] = Momentum(lr=0.1)
optimizers["AdaGrad"] = AdaGrad(lr=1.5)
optimizers["Adam"] = Adam(lr=0.3)
idx = 1
for key in optimizers:
optimizer = optimizers[key]
x_history = []
y_history = []
params['x'], params['y'] = init_pos[0], init_pos[1]
for i in range(30):
x_history.append(params["x"])
y_history.append(params["y"])
grads["x"], grads["y"] = df(params["x"], params["y"])
optimizer.update(params, grads)
x = np.arange(-10, 10, 0.01)
y = np.arange(-5, 5, 0.01)
X, Y = np.meshgrid(x, y)
Z = f(X, Y)
# for simple contour line
mask = Z > 7
Z[mask] = 0
# plot
plt.subplot(2, 2, idx)
idx += 1
plt.plot(x_history, y_history, "o-", color="red")
plt.contour(X, Y, Z)
plt.ylim(-10, 10)
plt.xlim(-10, 10)
plt.plot(0, 0, "+")
# colorbar()
# spring()
plt.title(key)
plt.xlabel("x")
plt.ylabel("y")
plt.show()
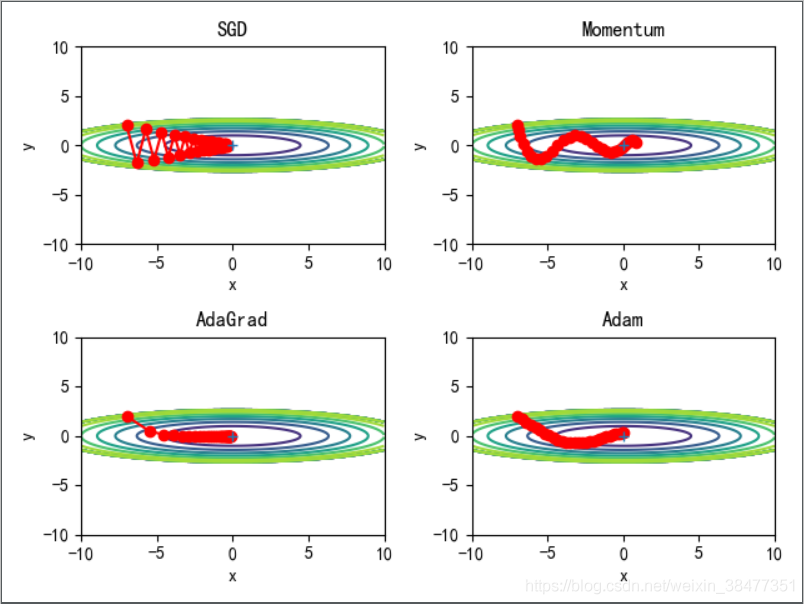
1.7 基于 MNIST 資料集的更新方法的比較
實驗:
以一個 5 層神經網路為物件,其中每層有 100 個神經元,激活函式使用 ReLU,
Python 實作:
"""基于MNIST資料集的更新方法的比較"""
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
from dataset.mnist import load_mnist
def smooth_curve(x):
"""用于使損失函式的圖形變圓滑
參考:http://glowingpython.blogspot.jp/2012/02/convolution-with-numpy.html
"""
window_len = 11
s = np.r_[x[window_len-1:0:-1], x, x[-1:-window_len:-1]]
w = np.kaiser(window_len, 2)
y = np.convolve(w/w.sum(), s, mode='valid')
return y[5:len(y)-5]
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢位對策
return np.exp(x) / np.sum(np.exp(x))
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 監督資料是one-hot-vector的情況下,轉換為正確解標簽的索引
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2 * h)
x[idx] = tmp_val # 還原值
it.iternext()
return grad
class SoftmaxWithLoss(object):
def __init__(self):
self.loss = None # 損失
self.y = None # softmax 的輸出
self.t = None # 監督資料(one-hot vector)
def forward(self, x, t):
"""
正向傳播
:param x: 輸入
:param t: 監督資料
:return:
"""
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
"""
反向傳播
:param dout: 上游傳來的導數
:return:
"""
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 監督資料是one-hot-vector的情況
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = sigmoid(x)
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
class Affine:
def __init__(self, W, b):
self.W = W # 權重引數
self.b = b # 偏置引數
self.x = None # 輸入
self.original_x_shape = None # 輸入張量的形狀
self.dW = None # 權重引數的導數
self.db = None # 偏置引數的導數
def forward(self, x):
"""
正向傳播
:param x:
:return:
"""
# 對應張量
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
out = np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
"""
反向傳播
:param dout: 上游傳來的導數
:return: 輸入的導數
"""
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
dx = dx.reshape(*self.original_x_shape) # 還原輸入資料的形狀(對應張量)
return dx
class Relu(object):
def __init__(self):
# 由True/False構成的NumPy陣列
# 正向傳播時的輸入x的元素中小于等于0的地方保存為True,其他地方(大于0的元素)保存為False
self.mask = None
def forward(self, x):
"""
正向傳播
:param x: 正向傳播時的輸入
:return:
"""
# 輸入x的元素中小于等于0的地方保存為True,其他地方(大于0的元素)保存為False
self.mask = (x <= 0)
# 輸入x的元素中小于等于0的值變換為0
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
"""
反向傳播
:param dout: 上游傳來的導數
:return:
"""
# 將從上游傳來的dout的mask中的元素為True的地方設為0
dout[self.mask] = 0
dx = dout
return dx
class MultiLayerNet:
"""全連接的多層神經網路
Parameters
----------
input_size : 輸入大小(MNIST的情況下為784)
hidden_size_list : 隱藏層的神經元數量的串列(e.g. [100, 100, 100])
output_size : 輸出大小(MNIST的情況下為10)
activation : 'relu' or 'sigmoid'
weight_init_std : 指定權重的標準差(e.g. 0.01)
指定'relu'或'he'的情況下設定“He的初始值”
指定'sigmoid'或'xavier'的情況下設定“Xavier的初始值”
weight_decay_lambda : Weight Decay(L2范數)的強度
"""
def __init__(self, input_size, hidden_size_list, output_size,
activation='relu', weight_init_std='relu', weight_decay_lambda=0):
self.input_size = input_size
self.output_size = output_size
self.hidden_size_list = hidden_size_list
self.hidden_layer_num = len(hidden_size_list)
self.weight_decay_lambda = weight_decay_lambda
self.params = {}
# 初始化權重
self.__init_weight(weight_init_std)
# 生成層
activation_layer = {'sigmoid': Sigmoid, 'relu': Relu}
self.layers = OrderedDict()
for idx in range(1, self.hidden_layer_num+1):
self.layers['Affine和Softmax層的實作' + str(idx)] = Affine(self.params['W' + str(idx)],
self.params['b' + str(idx)])
self.layers['Activation_function' + str(idx)] = activation_layer[activation]()
idx = self.hidden_layer_num + 1
self.layers['Affine和Softmax層的實作' + str(idx)] = Affine(self.params['W' + str(idx)],
self.params['b' + str(idx)])
self.last_layer = SoftmaxWithLoss()
def __init_weight(self, weight_init_std):
"""設定權重的初始值
Parameters
----------
weight_init_std : 指定權重的標準差(e.g. 0.01)
指定'relu'或'he'的情況下設定“He的初始值”
指定'sigmoid'或'xavier'的情況下設定“Xavier的初始值”
"""
all_size_list = [self.input_size] + self.hidden_size_list + [self.output_size]
for idx in range(1, len(all_size_list)):
scale = weight_init_std
if str(weight_init_std).lower() in ('relu', 'he'):
scale = np.sqrt(2.0 / all_size_list[idx - 1]) # 使用ReLU的情況下推薦的初始值
elif str(weight_init_std).lower() in ('sigmoid', 'xavier'):
scale = np.sqrt(1.0 / all_size_list[idx - 1]) # 使用sigmoid的情況下推薦的初始值
self.params['W' + str(idx)] = scale * np.random.randn(all_size_list[idx-1], all_size_list[idx])
self.params['b' + str(idx)] = np.zeros(all_size_list[idx])
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""求損失函式
Parameters
----------
x : 輸入資料
t : 教師標簽
Returns
-------
損失函式的值
"""
y = self.predict(x)
weight_decay = 0
for idx in range(1, self.hidden_layer_num + 2):
W = self.params['W' + str(idx)]
weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W ** 2)
return self.last_layer.forward(y, t) + weight_decay
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
"""求梯度(數值微分)
Parameters
----------
x : 輸入資料
t : 教師標簽
Returns
-------
具有各層的梯度的字典變數
grads['W1']、grads['W2']、...是各層的權重
grads['b1']、grads['b2']、...是各層的偏置
"""
loss_W = lambda W: self.loss(x, t)
grads = {}
for idx in range(1, self.hidden_layer_num+2):
grads['W' + str(idx)] = numerical_gradient(loss_W, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_W, self.params['b' + str(idx)])
return grads
def gradient(self, x, t):
"""求梯度(誤差反向傳播法)
Parameters
----------
x : 輸入資料
t : 教師標簽
Returns
-------
具有各層的梯度的字典變數
grads['W1']、grads['W2']、...是各層的權重
grads['b1']、grads['b2']、...是各層的偏置
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 設定
grads = {}
for idx in range(1, self.hidden_layer_num+2):
grads['W' + str(idx)] = self.layers['Affine和Softmax層的實作' + str(idx)].dW + self.weight_decay_lambda * self.layers['Affine和Softmax層的實作' + str(idx)].W
grads['b' + str(idx)] = self.layers['Affine和Softmax層的實作' + str(idx)].db
return grads
class SGD(object):
"""隨機梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr # 學習率
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
class Momentum(object):
"""Momentum SGD"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
class Nesterov:
"""Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
class AdaGrad:
"""AdaGrad"""
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSProp(object):
"""RMSProp"""
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class Adam(object):
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr # 學習率
self.beta1 = beta1 # 一次momentum系數
self.beta2 = beta2 # 二次momentum系數
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
"""優化器比較"""
# 0: 讀入資料
(x_train, y_train), (x_test, y_test) = load_mnist(normalize=True)
train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000
# 1: 進行實驗的設定
optimizers = {}
optimizers["SGD"] = SGD()
optimizers["Momentum"] = Momentum()
optimizers["AdaGrad"] = AdaGrad()
optimizers["Adam"] = Adam()
networks = {}
train_loss = {}
for key in optimizers.keys():
networks[key] = MultiLayerNet(input_size=784,
hidden_size_list=[100, 100, 100, 100],
output_size=10)
train_loss[key] = []
# 2: 開始訓練
for i in range(max_iterations):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
y_batch = y_train[batch_mask]
for key in optimizers.keys():
grads = networks[key].gradient(x_batch, y_batch)
optimizers[key].update(networks[key].params, grads)
loss = networks[key].loss(x_batch, y_batch)
train_loss[key].append(loss)
if i % 100 == 0:
print(f"============itrration: {i}============")
for key in optimizers.keys():
loss = networks[key].loss(x_batch, y_batch)
print(f"{key}: {loss}")
# 3: 繪制圖形
markers = {"SGD": "o", "Momentum": "x", "AdaGrad": "s", "Adam": "D"}
x = np.arange(max_iterations)
for key in optimizers.keys():
plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)
plt.xlabel("iterations")
plt.ylabel("loss")
plt.ylim(0, 1)
plt.legend()
plt.show()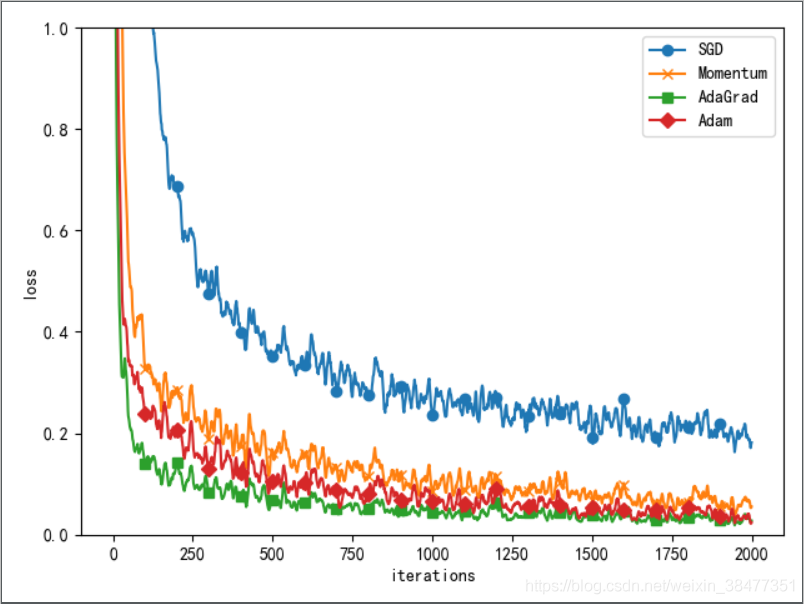
2. 權重的初始值
在神經網路的學習中,設定什么樣的權重初始值,經常關系到神經網路的學習能否成功,
2.1 可以將權重初始值設為 0 嗎
權值衰減(weight decay): 一種以減小權重引數的值為目的進行學習的方法,通過減小權重引數的值來抑制過擬合的發生,
為什么不能將權重初始值設為 0 呢?為什么不能將權重初始值設成一樣的值呢?
因為在誤差反向傳播中,所有的權重值都會進行相同的更新,比如,在 2 層神經網路中,假設第 1 層和第 2 層的權重為0,這樣一來,正向傳播時,因為輸入層的權重為 0,所以第 2 層的神經元全部會被傳遞相同的值,第 2 層的神經元中全部輸入相同的值,這意味著反向傳播時第 2 層的權重全部都會進行相同的更新,因此,權重被更新為相同的值,并擁有了對稱的值(重復的值),這使得神經網路擁有許多不同的權重的意義喪失了,
2.2 隱藏層的激活值的分布
實驗:
向一個 5 層神經網路(激活函式使用 sigmoid 函式)傳入隨機生成的輸入資料,用直方圖繪制各層激活值(激活函式的輸出資料)的資料分布,
實驗 1:使用標準差為 1 的高斯分布作為權重初始值
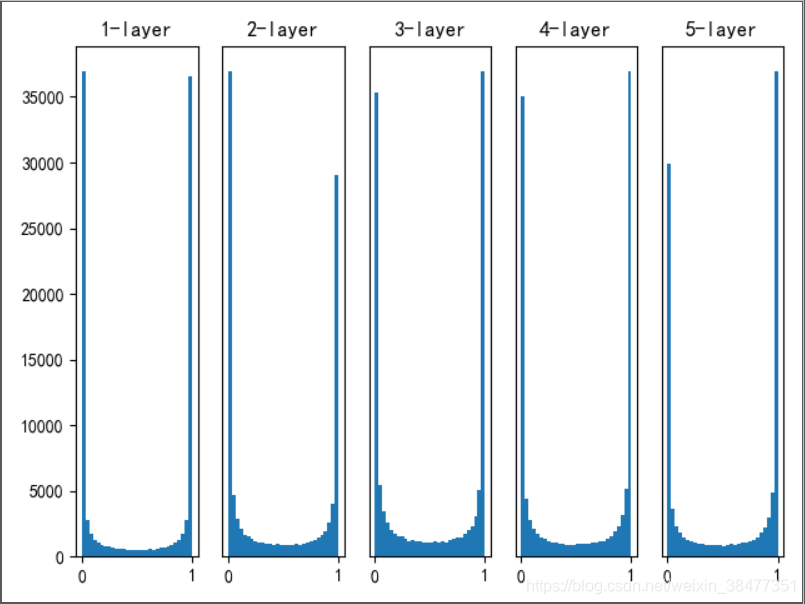
各層的激活值呈偏向 0 和 1 的分布,這里使用的 sigmoid 函式是 S 型函式,隨著輸出不斷地靠近 0(或者靠近 1),它的導數的值逐漸接近 0,
梯度消失(gradient vanishing):偏向 0 和 1 的資料分布會造成反向傳播中梯度的值不斷變小,最后消失,這個問題稱為梯度消失(gradient vanishing),
實驗 2:使用標準差為 0.01 的高斯分布作為權重初始值

各層的激活值呈集中在 0.5 附近的分布,因為不像標準差為 1 時的那樣偏向 0 和 1,所以不會發生梯度消失的問題,
激活值的分布有所偏向,說明表現力上會有很大問題,為什么這么說呢?因為如果有多個神經元都輸出幾乎相同的值,那它們就沒有存在的意義了,比如,如果 100 個神經元都輸出幾乎相同的值,那么也可以由 1 個神經元來表達基本相同的事情,因此,激活值在分布上有所偏向會出現 “表現力受限 ” 的問題,
各層的激活值的分布都要求有適當的廣度,為什么呢?
因為通過在各層間傳遞多樣性的資料,神經網路可以進行高效的學習,反過來,如果傳遞的是有所偏向的資料,就會出現梯度消失或者 “表現力受限” 的問題,導致學習可能無法順利進行,
實驗 3:使用 Xavier 初始值作為權重初始值
Xavier Glorot 等人的論文中推薦的初始值:如果前一層的節點數為 n,則初始值使用標準差為 的高斯分布,
Xavier 初始值是以激活函式是線性函式為前提推匯出來的,因為 sigmoid 函式和 tanh 函式左右對稱,且中央附近可以視作線性函式,所以適合使用 Xavier 初始值,
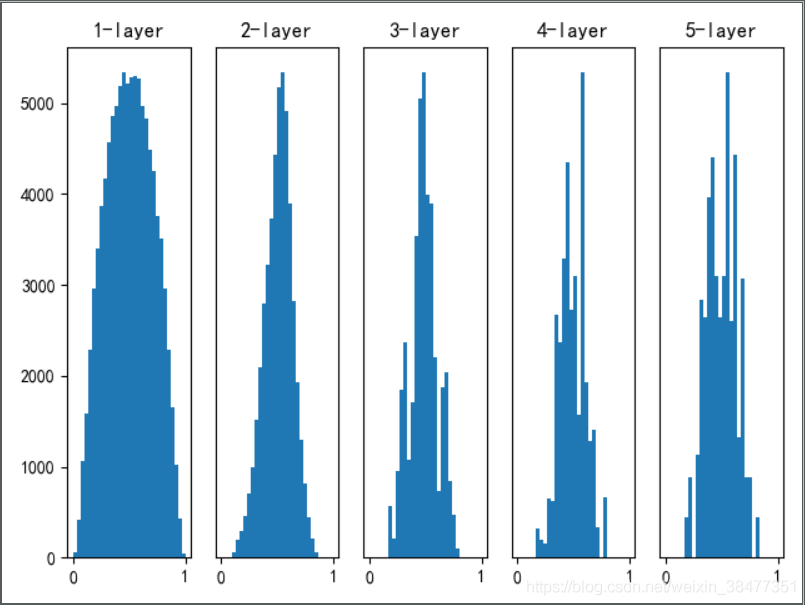
使用 Xavier 初始值后,前一層的節點數越多,要設定為目標節點的初始值的權重尺度就越小,
觀察圖 5-5 可知,越是后面的層,影像變得越歪斜,但是呈現了比之前更有廣度的分布,因為各層間傳遞的資料有了適當的廣度,所以 sigmoid 函式的表現力不受限制,有望進行高效地學習,
實驗 4:使用 Xavier 初始值作為權重初始值時使用 tanh 函式代替 sigmoid 函式
tanh 和 sigmoid 函式都是 S型曲線函式,
tanh 函式是關于原點 (0, 0) 對稱的 S 型曲線,而 sigmoid 函式是關于 (x, y) = (0, 0.5) 對稱的 S 型曲線,
用作激活函式的函式最好具有關于原點對稱的性質,
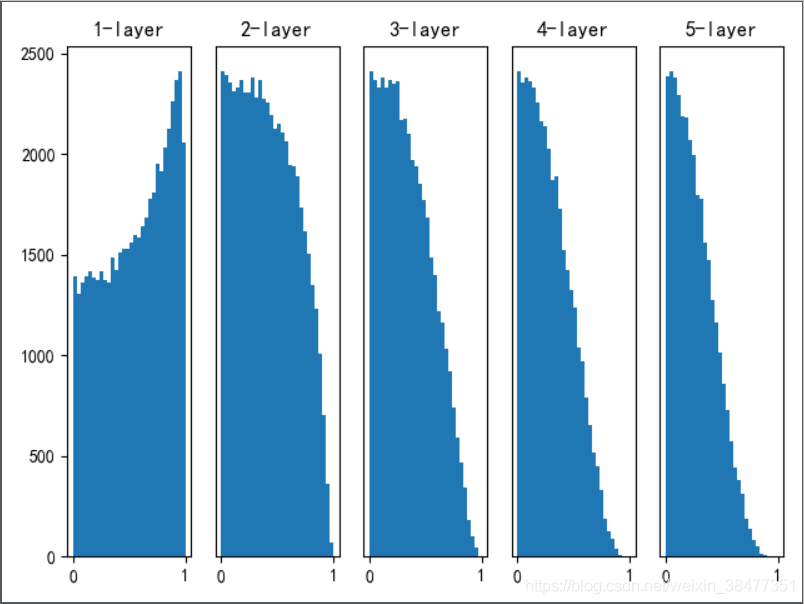
用 tanh 函式(雙曲線函式)代替 sigmoid 函式,可以改善 sigmoid 函式作為激活函式時神經網路層的激活值分布呈現出稍微歪斜的形狀的問題,
2.3 ReLU 的權重初始值
當激活函式使用 ReLU 函式時,一般推薦使用 ReLU 專用的初始值,也就是 Kaiming He 等人推薦的初始值,也稱為 “He 初始值”,
He 初始值:當前一層的節點數為 n 時,He 初始值使用標準差為 的高斯分布,
當 Xavier 初始值是 時,(直觀上)可以解釋為,因為 ReLU 的負值區域的值為 0,為了使它更有廣度,所以需要 2 倍的系數,
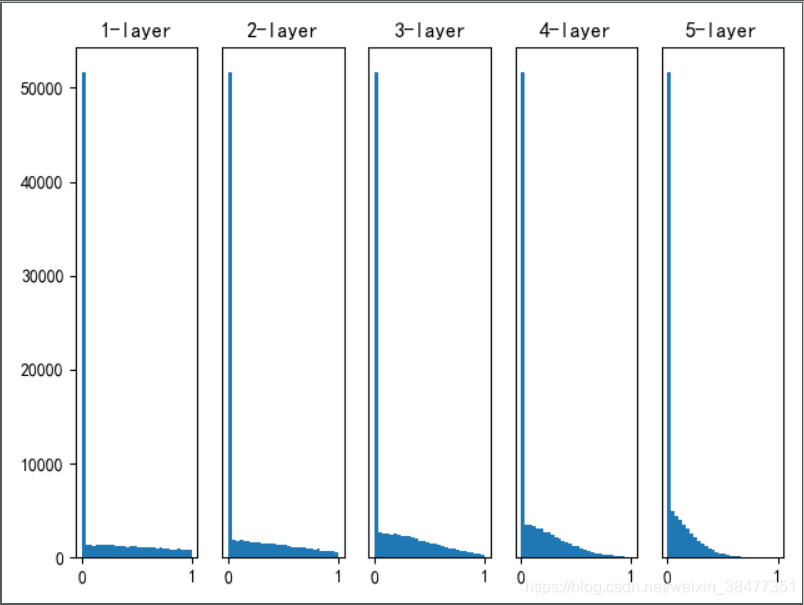
實驗 1:使用標準差為 0.01 的高斯分布作為權重初始值

各層的激活值非常小(第 1 層:0.0396;第 2 層:0.00290;第 3 層:0.000197;第 4 層:1.32e-5;第 5 層:9.46e-7),
神經網路上傳遞的是非常小的值,說明逆向傳播時權重的梯度也同樣很小,這是很嚴重的問題,實際上學習基本上沒有進展,
實驗 2:使用 Xavier 初始值作為權重初始值
隨著層的加深,偏向一點點變大,
實際上,層加深后,激活值的偏向變大,學習時會出現梯度消失的問題,
實驗 3:使用 ReLU 專用的 He 初始值作為權重初始值
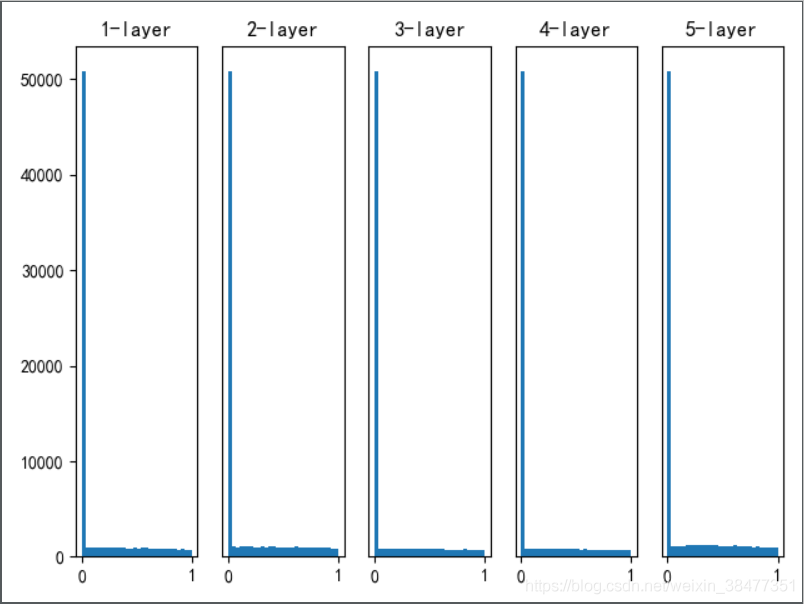
初始值為 He 初始值時,各層中分布的廣度相同,
由于即便層加深,資料的廣度也能保持不變,因此逆向傳播時,也會傳遞合適的值,
總結:當激活函式使用 ReLU 函式時,權重初始值使用 He 初始值;當激活函式為 sigmoid 函式或 tanh 函式時,權重初始值使用 Xavier 初始值,
Python 代碼:
"""隱藏層的激活值的分布"""
import numpy as np
from matplotlib import pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def ReLU(x):
return np.maximum(0, x)
def tanh(x):
return np.tanh(x)
x = np.random.randn(1000, 100) # 1000個資料
node_num = 100 # 各隱藏層的節點(神經元)數
hidden_layer_size = 5 # 隱藏層有5層
activations = {} # 激活值的結果保存在這里
for i in range(hidden_layer_size):
if i != 0:
x = activations[i - 1]
# 改變初始值進行實驗!
# w = np.random.randn(node_num, node_num) * 1
# w = np.random.randn(node_num, node_num) * 0.01
# w = np.random.randn(node_num, node_num) * np.sqrt(1.0 / node_num)
w = np.random.randn(node_num, node_num) * np.sqrt(2.0 / node_num)
a = np.dot(x, w)
# 將激活函式的種類也改變,來進行實驗!
# z = sigmoid(a)
z = ReLU(a)
# z = tanh(a)
activations[i] = z
# 繪制直方圖
for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(f"{i+1}-layer")
if i != 0: plt.yticks([], [])
plt.hist(a.flatten(), 30, range=(0, 1))
plt.show()2.4 基于 MNIST 資料集的權重初始值的比較
實驗:
使用 MNIST 資料集,構建5 層神經網路,每層有 100 個神經元,激活函式使用 ReLU 函式,基于 std=0.01、Xavier 初始值、He 初始值 進行實驗,觀察不同的權重初始值的賦值方法會在多大程度上影響神經網路的學習,
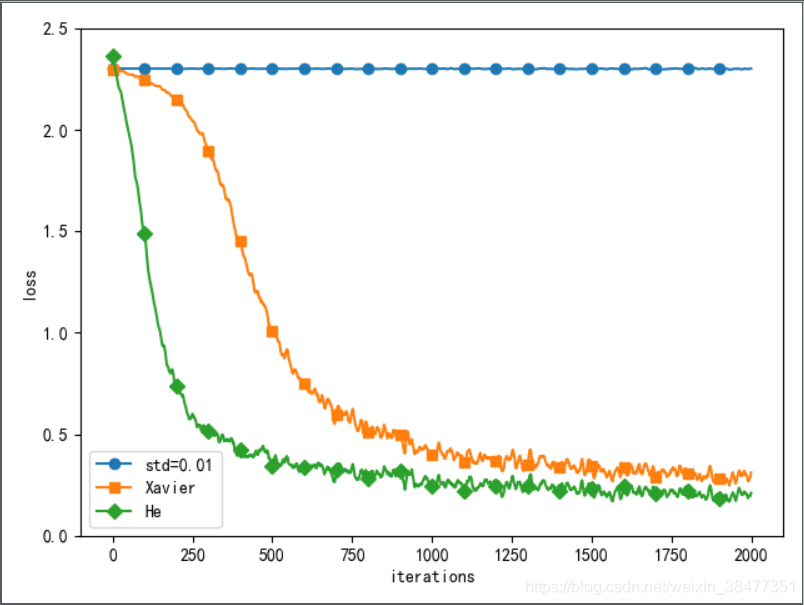
初始值為std=0.01 時,完全無法進行學習,因正向傳播中傳遞的值很小(集中在 0 附近的資料),因此逆向傳播時求到的梯度也很小,權重幾乎不進行更新,
初始值為 Xavier 初始值和 He 初始值時,學習進行的很順利,并且 He 初始值的學習進度更快一些,
Python 代碼:
"""基于 MNIST 資料集的權重初始值的比較"""
import numpy as np
from collections import OrderedDict
from matplotlib import pyplot as plt
from dataset.mnist import load_mnist
def smooth_curve(x):
"""用于使損失函式的圖形變圓滑
參考:http://glowingpython.blogspot.jp/2012/02/convolution-with-numpy.html
"""
window_len = 11
s = np.r_[x[window_len-1:0:-1], x, x[-1:-window_len:-1]]
w = np.kaiser(window_len, 2)
y = np.convolve(w/w.sum(), s, mode='valid')
return y[5:len(y)-5]
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 監督資料是one-hot-vector的情況下,轉換為正確解標簽的索引
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2 * h)
x[idx] = tmp_val # 還原值
it.iternext()
return grad
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢位對策
return np.exp(x) / np.sum(np.exp(x))
class SoftmaxWithLoss(object):
def __init__(self):
self.loss = None # 損失
self.y = None # softmax 的輸出
self.t = None # 監督資料(one-hot vector)
def forward(self, x, t):
"""
正向傳播
:param x: 輸入
:param t: 監督資料
:return:
"""
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
"""
反向傳播
:param dout: 上游傳來的導數
:return:
"""
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 監督資料是one-hot-vector的情況
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = sigmoid(x)
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
class Affine:
def __init__(self, W, b):
self.W = W # 權重引數
self.b = b # 偏置引數
self.x = None # 輸入
self.original_x_shape = None # 輸入張量的形狀
self.dW = None # 權重引數的導數
self.db = None # 偏置引數的導數
def forward(self, x):
"""
正向傳播
:param x:
:return:
"""
# 對應張量
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
out = np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
"""
反向傳播
:param dout: 上游傳來的導數
:return: 輸入的導數
"""
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
dx = dx.reshape(*self.original_x_shape) # 還原輸入資料的形狀(對應張量)
return dx
class Relu(object):
def __init__(self):
# 由True/False構成的NumPy陣列
# 正向傳播時的輸入x的元素中小于等于0的地方保存為True,其他地方(大于0的元素)保存為False
self.mask = None
def forward(self, x):
"""
正向傳播
:param x: 正向傳播時的輸入
:return:
"""
# 輸入x的元素中小于等于0的地方保存為True,其他地方(大于0的元素)保存為False
self.mask = (x <= 0)
# 輸入x的元素中小于等于0的值變換為0
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
"""
反向傳播
:param dout: 上游傳來的導數
:return:
"""
# 將從上游傳來的dout的mask中的元素為True的地方設為0
dout[self.mask] = 0
dx = dout
return dx
class MultiLayerNet:
"""全連接的多層神經網路
Parameters
----------
input_size : 輸入大小(MNIST的情況下為784)
hidden_size_list : 隱藏層的神經元數量的串列(e.g. [100, 100, 100])
output_size : 輸出大小(MNIST的情況下為10)
activation : 'relu' or 'sigmoid'
weight_init_std : 指定權重的標準差(e.g. 0.01)
指定'relu'或'he'的情況下設定“He的初始值”
指定'sigmoid'或'xavier'的情況下設定“Xavier的初始值”
weight_decay_lambda : Weight Decay(L2范數)的強度
"""
def __init__(self, input_size, hidden_size_list, output_size,
activation='relu', weight_init_std='relu', weight_decay_lambda=0):
self.input_size = input_size
self.output_size = output_size
self.hidden_size_list = hidden_size_list
self.hidden_layer_num = len(hidden_size_list)
self.weight_decay_lambda = weight_decay_lambda
self.params = {}
# 初始化權重
self.__init_weight(weight_init_std)
# 生成層
activation_layer = {'sigmoid': Sigmoid, 'relu': Relu}
self.layers = OrderedDict()
for idx in range(1, self.hidden_layer_num+1):
self.layers['Affine和Softmax層的實作' + str(idx)] = Affine(self.params['W' + str(idx)],
self.params['b' + str(idx)])
self.layers['Activation_function' + str(idx)] = activation_layer[activation]()
idx = self.hidden_layer_num + 1
self.layers['Affine和Softmax層的實作' + str(idx)] = Affine(self.params['W' + str(idx)],
self.params['b' + str(idx)])
self.last_layer = SoftmaxWithLoss()
def __init_weight(self, weight_init_std):
"""設定權重的初始值
Parameters
----------
weight_init_std : 指定權重的標準差(e.g. 0.01)
指定'relu'或'he'的情況下設定“He的初始值”
指定'sigmoid'或'xavier'的情況下設定“Xavier的初始值”
"""
all_size_list = [self.input_size] + self.hidden_size_list + [self.output_size]
for idx in range(1, len(all_size_list)):
scale = weight_init_std
if str(weight_init_std).lower() in ('relu', 'he'):
scale = np.sqrt(2.0 / all_size_list[idx - 1]) # 使用ReLU的情況下推薦的初始值
elif str(weight_init_std).lower() in ('sigmoid', 'xavier'):
scale = np.sqrt(1.0 / all_size_list[idx - 1]) # 使用sigmoid的情況下推薦的初始值
self.params['W' + str(idx)] = scale * np.random.randn(all_size_list[idx-1], all_size_list[idx])
self.params['b' + str(idx)] = np.zeros(all_size_list[idx])
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""求損失函式
Parameters
----------
x : 輸入資料
t : 教師標簽
Returns
-------
損失函式的值
"""
y = self.predict(x)
weight_decay = 0
for idx in range(1, self.hidden_layer_num + 2):
W = self.params['W' + str(idx)]
weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W ** 2)
return self.last_layer.forward(y, t) + weight_decay
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def numerical_gradient(self, x, t):
"""求梯度(數值微分)
Parameters
----------
x : 輸入資料
t : 教師標簽
Returns
-------
具有各層的梯度的字典變數
grads['W1']、grads['W2']、...是各層的權重
grads['b1']、grads['b2']、...是各層的偏置
"""
loss_W = lambda W: self.loss(x, t)
grads = {}
for idx in range(1, self.hidden_layer_num+2):
grads['W' + str(idx)] = numerical_gradient(loss_W, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_W, self.params['b' + str(idx)])
return grads
def gradient(self, x, t):
"""求梯度(誤差反向傳播法)
Parameters
----------
x : 輸入資料
t : 教師標簽
Returns
-------
具有各層的梯度的字典變數
grads['W1']、grads['W2']、...是各層的權重
grads['b1']、grads['b2']、...是各層的偏置
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 設定
grads = {}
for idx in range(1, self.hidden_layer_num+2):
grads['W' + str(idx)] = self.layers['Affine和Softmax層的實作' + str(idx)].dW + self.weight_decay_lambda * self.layers['Affine和Softmax層的實作' + str(idx)].W
grads['b' + str(idx)] = self.layers['Affine和Softmax層的實作' + str(idx)].db
return grads
class SGD(object):
"""隨機梯度下降法(Stochastic Gradient Descent)"""
def __init__(self, lr=0.01):
self.lr = lr # 學習率
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
# 0: 讀入資料
(x_train, y_train), (x_test, y_test) = load_mnist(normalize=True)
train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000
# 1: 進行實驗的設定
weight_init_types = {"std=0.01": 0.01, "Xavier": "sigmoid", "He": "relu"}
optimizer = SGD(lr=0.01)
networks = {}
train_loss = {}
for key, weight_type in weight_init_types.items():
networks[key] = MultiLayerNet(input_size=784,
hidden_size_list=[100, 100, 100, 100],
output_size=10,
weight_init_std=weight_type)
train_loss[key] = []
# 2: 開始訓練
for i in range(max_iterations):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
y_batch = y_train[batch_mask]
for key in weight_init_types.keys():
grads = networks[key].gradient(x_batch, y_batch)
optimizer.update(networks[key].params, grads)
loss = networks[key].loss(x_batch, y_batch)
train_loss[key].append(loss)
if i % 100 == 0:
print(f"============iteration: {i}========")
for key in weight_init_types.keys():
loss = networks[key].loss(x_batch, y_batch)
print(f"{key}: {loss}")
# 3: 繪制圖形
markers = {"std=0.01": "o", "Xavier": "s", "He": "D"}
x = np.arange(max_iterations)
for key in weight_init_types.keys():
plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)
plt.xlabel("iterations")
plt.ylabel("loss")
plt.ylim(0, 2.5)
plt.legend()
plt.show()3. Batch Normalization(批歸一化)
3.1 Batch Normalization 的演算法
Batch Normalization 的優點:
- 可以使學習快速進行(可以增大學習率),
- 不那么依賴初始值(對于初始值不用那么神經質),
- 抑制過擬合(降低 Dropout 等的必要性),
Batch Normalization 的思路:調整各層的激活值分布使其擁有適當的廣度,
使用 Batch Normalization 層的神經網路:
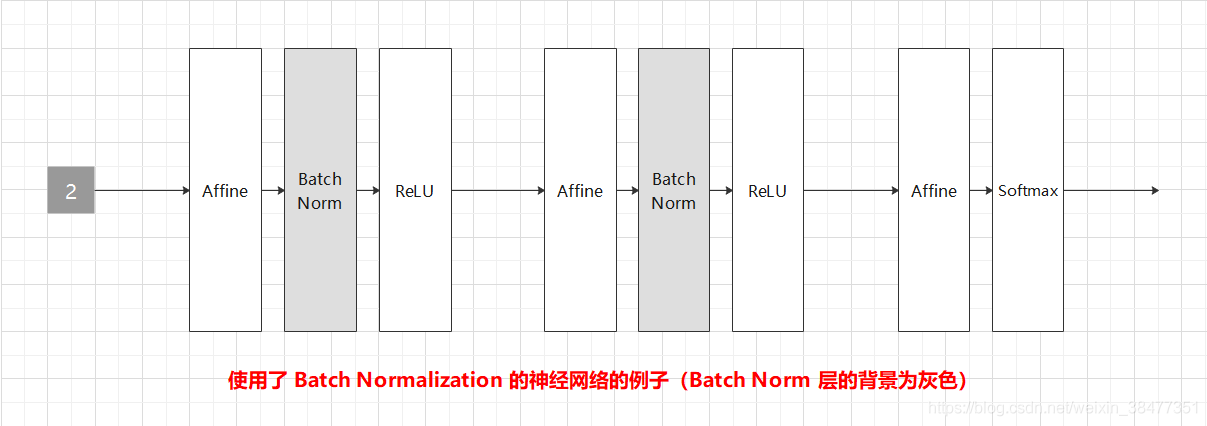
Batch Normalization,顧名思義,以進行學習時的 mini-batch 為單位,按 mini-batch 進行正規化,具體而言,就是進行使資料分布的均值為 0、方差為 1 的正規化,用數學式表示如式 (5.6),
:mini-batch 的
個輸入資料的集合
,
:均值,
:方差,
式 (5.6) 所做的是將 mini-batch 的輸入資料
變換為均值為 0、方差為 1 的資料
,
接著,Batch Normalization 層會對正規化后的資料進行縮放和平移的變換,用數學式表示如式 (5.7),
和
是引數,一開始
,
,然后再通過學習調整到合適的值,
3.2 Batch Normalization 的評估
4. 正則化
5. 超引數的驗證
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/283027.html
標籤:AI
上一篇:朋友圈里的一張組合邏輯圖