每天日志打卡1/1
一直知道Pearl老先生很厲害,買了書一直也沒看,這次先找一篇簡單的入個門,
這篇發表于2019年的論文我一直沒找到什么筆記和評論,只能自己看看了,這篇筆記也是大概梳理一下我看到的重點和思路,
INTRODUCTION
在機器學習蓬勃發展的時候,人們期望AI獲得很大成功,但有三個障礙:魯棒性、可解釋性和因果關系的理解,作者認為,想要解決這三個問題需要在機器學習中加入因果模型的工具,
THE THREE LAYER CAUSAL HIERARCHY
接下來,作者解釋了因果的三個等級,我之前在知乎看過一篇文章,講的很詳細,
https://zhuanlan.zhihu.com/p/258562953
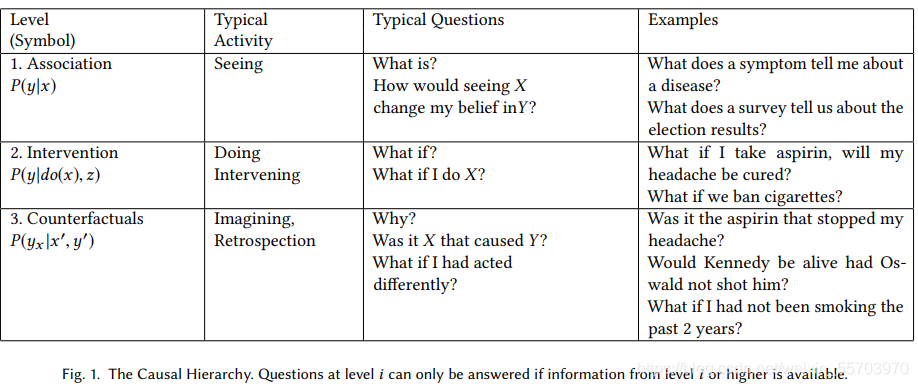
具體來說,是把因果資訊按照能回答的問題不同分成三類層次結構中的每一層都有一個特征式子,
例如,關聯層的特征是條件概率,
干預層的特征是 P(y|do(x), z) ,它表示“假設我們進行干預并將 X 的值設定為 x 并隨后觀察事件 Z =z ,事件 Y = y 的概率, 可以通過隨機試驗或使用因果貝葉斯網路進行分析來估計此類運算式,人工智能規劃者通過執行他們指定的一系列動作來獲得干預知識, 關鍵性區別在于:無論資料有多大,都不能僅從被動觀察中推斷出干預性表達,
最后,在反事實層面,我們有P(y |x′,y′) 代表“假設我們實際上觀察到 X 是 x' 并且 Y 是 y',我們想知道如果 X 是 x 的時候事件 Y = y 的概率' , 例如,Joe的實際薪水是 y′ 并且他只上過兩年大學,如果他大學畢業,他的薪水是 y 的概率,” 只有當我們擁有函式或結構方程模型或這些模型的屬性時,才能計算這些概率,
THE SEVEN TOOLS OF CAUSAL INFERENCE (OR WHAT YOU CAN DO WITH A CAUSAL MODEL THAT YOU COULD NOT DO WITHOUT?)
標題很長,其實沒那么復雜,首先作者老生常談了他的獨創model:“Structural Causal Models (SCM).”

SCM由三部分組成,影像模型用于表示我們知道的資訊(我們知道的關于這個世界的東西);反事實和干預邏輯幫助我們利用我們知道的東西,結構性公式把它倆結合起來,這么說有點繞給個栗子:
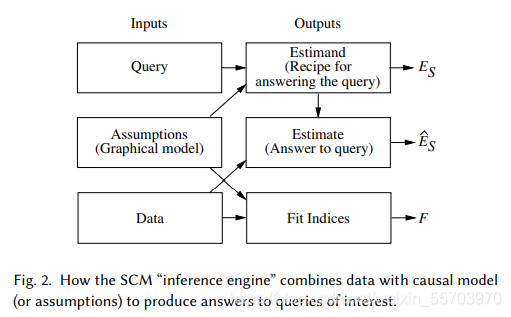
我們利用SCM建模一個干預機器,該機器接受三個輸入:假設(assumption)、查詢(query)和資料(data),并產生三個輸出:估計(estimand)、估計’(estimate)和擬合指數(fit indices), Estimand (ES) 是一個數學公式,它基于假設,提供了從任何假設資料(只要它們可用)回答查詢的方法, 接收到資料后,機器使用 Estimand 產生一個實際的對答案的估計 (ES ),以及對該答案置信度的統計估計(以反映資料集的有限大小,以及可能的測量誤差或缺失資料,)最后,引擎生成“擬合指數”衡量資料與模型傳達的假設的兼容性,
之后,作者以“吃藥”“性別”和“病愈”為例介紹了一個SCM模型,接下來,作者介紹了七種SCM框架可以完成的任務、和在完成任務中用到的tools,
1.編碼因果假設——透明度和可測驗性
一旦我們認真對待透明度和可測驗性的要求,以緊湊和可用的形式編碼假設的任務就不是一件小事,透明度使分析師能夠辨別編碼的假設是否合理(基于科學依據),或者其他假設是否合理保證,可測驗性允許我們(無論是分析師還是機器)確定編碼的假設是否與可用資料兼容,如果不兼容,則確定需要修復的假設,
圖形模型的進步使緊湊編碼(compact encoding)成為可能,它們的透明度自然源于這樣一個事實,即所有假設都以圖形形式定性編碼,反映了研究人員對該領域因果關系的看法;不需要反事實或統計依賴的判斷,因為這些可以從圖的結構中讀出,可測驗性通過稱為 d-separation 的圖形標準得到促進,該標準提供了原因和概率之間的基本聯系,它告訴我們,對于模型中任何給定的路徑模式,我們應該期望在資料中找到什么樣的依賴模式,
2.Do-calculus 和混雜控制
混淆、或兩個或多個變數存在未觀察到的原因,長期以來一直被認為是從資料中得出因果推斷的主要障礙,這個障礙已經通過稱為“后門”的圖形標準被揭開神秘面紗和“解混”, 特別是,選擇一組合適的協變數來控制混雜的任務已經簡化為一個簡單的“路障”難題,可以通過簡單的演算法進行管理 [Pearl 1993], 對于“后門”標準不成立的模型,可以使用稱為 do-calculus 的符號引擎,它在可行的情況下預測政策干預的效果,并在無法通過指定的假設確定預測時以失敗退出, [Bareinboim and Pearl 2012; Pearl 1995; Shpitser and Pearl 2008; Tian and Pearl 2002]
3.反事實的演算法化
反事實分析處理特定個人的行為,由一組不同的特征確定,例如,假設喬的薪水是 Y = y,并且他上了 X = x 年的大學,如果他再多上一年大學喬的薪水會是多少,
現代因果關系作業的最高成就之一是在圖形表示中形式化反事實推理——研究人員用來編碼科學知識的表示,每個結構方程模型決定了每個反事實句子的真值,因此,我們可以通過分析來確定句子的概率是否是可估計的,例如,經濟學家選擇了代數而不是圖形表示,被剝奪了基本的可測驗性檢測特征 [Pearl 2015b],來自實驗或觀察研究,或其組合 [Balke and Pearl 1994;珍珠 2000,第 7 章],因果論述中特別感興趣的是關于“結果的原因”的反事實問題,而不是“原因的結果”,例如,喬的游泳運動是喬死亡的必要(或充分)原因的可能性有多大 [Halpern and Pearl 2005; Pearl 2015a],
4.中介分析(Mediation Analysis)和直接和間接影響的評估
中介分析涉及將變化從原因傳遞到其結果的機制, 這種中間機制的識別對于產生解釋至關重要,必須呼叫反事實分析來促進這種識別, 反事實的圖形表示使我們能夠定義直接和間接影響,并決定何時可以從資料或實驗中估計這些影響 [Pearl 2001; Robins and Greenland 1992; VanderWeele 2015]., 可回答的典型查詢分析是:X 對 Y 的影響有多少是由變數 Z 介導的,
5.適應性、外部有效性和樣本選擇偏差
每項實驗研究的有效性都受到實驗和實施設定之間差異的挑戰,當環境條件發生變化時,不能期望在一種環境中訓練的機器表現良好,除非這些變化被定位和識別,這個問題及其各種表現已經被人工智能研究人員所熟知,諸如“領域適應”、“遷移學習”、“終身學習”和“可解釋人工智能”等企業[Chen and Liu 2016],只是其中的一部分,研究人員和資助機構確定的子任務,以試圖緩解魯棒性的一般問題,不幸的是,問題魯棒性的最廣泛形式需要環境的因果模型,不能在關聯級別處理,關聯不足以識別受所發生變化影響的機制 [Pearl 和 Bareinboim 2014],原因是觀察到的關聯中的表面變化并不能唯一確定導致變化的潛在機制,上面討論的 do-calculus 現在提供了一個完整的方法來克服由于環境變化引起的偏差,可以使用既用于重新調整學習政策以規避環境變化,也用于控制非代表性樣本與目標人群之間的差異 [Bareinboim and Pearl 2016],
6.從丟失的資料中恢復
缺失資料的問題困擾著實驗科學的每個分支, 受訪者不會回答問卷中的每個專案,傳感器會隨著天氣條件的惡化而發生故障,并且患者經常因未知原因退出臨床研究, 關于這個問題的豐富文獻與關聯分析的無模型范式結合在一起,因此,它嚴重限于隨機發生缺失的情況,即獨立于模型中其他變數所取的值, 使用缺失程序的因果模型,我們現在可以形式化可以從不完整資料中恢復因果關系和概率關系的條件,并且只要滿足條件,就可以對所需關系進行一致的估計 [Mohan and Pearl 2018; Mohan et al. 2013],
7.因果發現
上面描述的 d-separation 標準使我們能夠檢測和列舉給定因果模型的可測驗含義,這開啟了以溫和假設推斷與資料兼容的模型集并緊湊地表示該集的可能性,已經開發了系統搜索,在某些情況下,它可以顯著修剪兼容模型集到可以直接從該集估計因果查詢的程度[Jaber et al. 2018; Pearl 2000; Peters et al. 2017; Spirtes et al. 2000],
或者,Shimizu et al. [2006] 提出了一種基于功能分解發現因果方向性的方法 [[Peters et al. 2017],這個想法是,在具有非高斯噪聲的線性模型 X → Y 中,P(y) 是兩個非高斯分布的卷積,形象地說,比 P(x)“更高斯”, “高斯比”的關系可以給出精確的數值度量,并用于推斷某些箭頭的方向性,
Tian 和 Pearl [2002] 開發了另一種基于檢測“沖擊”的因果發現方法,或環境中自發的區域變化,其作用類似于“自然的干預”,并揭示了對這些沖擊后果的因果方向性,
結論
因果推理是人類思想不可或缺的組成部分,應該將其形式化和演算法化以實作人類水平的機器智能,文章以三級層次結構的形式解釋了實作該目標的一些障礙,并表明對 2 級和 3 級的推斷需要一個環境的因果模型,此外,文章描述已經描述了七項認知任務,這些任務需要來自這兩個推理級別的工具,并演示了如何在 SCM 框架中完成這些任務,
需要注意的是,用于完成這些任務的模型是結構性的(或概念性的),不需要承諾所涉及的特定形式的分布,另一方面,所有推論的有效性關鍵取決于假設結構的真實性,如果真實結構與假設的結構不同,并且資料對兩者的擬合程度相同,則可能會產生大量錯誤,有時可以通過敏感性分析來評估這些錯誤,同樣重要的是要記住,無模型機器學習的理論局限性不適用于預測、診斷和識別任務,其中干預和反事實扮演次要角色,
然而,規避這些限制的模型輔助方法仍然適用于不透明性、魯棒性、可解釋性和缺失資料的問題,這些問題對于機器學習任務來說是通用的,此外,鑒于因果建模對社會科學和醫學科學產生的變革性影響,一旦在資料生成模型的指導下豐富了機器學習技術,就很自然地期望類似的變革席卷機器學習技術,程序,作者希望這種共生能夠產生以用戶的母語因果關系進行交流的系統,并利用這種能力成為下一代人工智能的主導范式,
[1]Pearl, Judea. (2019). The seven tools of causal inference, with reflections on machine learning. Communications of the ACM. 62. 54-60. 10.1145/3241036.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/287853.html
標籤:AI