文章目錄
- 1 什么是自監督學習
- 2 訓練 BERT 的方法一:Masking Input
- 3 訓練 BERT 的方法二:Next Sentence Prediction
- 4 BERT 的應用案例決議
- 4.1 情感分析
- 4.2 詞性標記
- 4.3 自然語言推斷
- 4.4 基于資訊抽取的問答
- 5 BERT 的訓練并不容易
- 6 BERT 胚胎學
1 什么是自監督學習
-
首先我們來回憶一下監督學習,當我們做監督學習時,我們只有一個模型,這個模型的輸入是x,輸出是y,假設我們做情感分析,那就是讓機器閱讀一篇文章,而機器需要對這篇文章進行分類,是正面的還是負面的,為了對機器進行訓練,我們必須先找到大量的文章,需要對所有的文章進行label,我們需要有標簽和文章資料來訓練監督模型,
監督學習利用大量的標注資料來訓練模型,模型的預測和資料的真實標簽產生損失后進行反向傳播(計算梯度、更新引數),通過不斷的學習,最終可以獲得識別新樣本的能力,
-
有監督學習和無監督學習最主要的區別在于模型在訓練時是否需要人工標注的標簽資訊,
無監督學習不依賴任何標簽值,通過對資料內在特征的挖掘,找到樣本間的關系,比如聚類相關的任務,
-
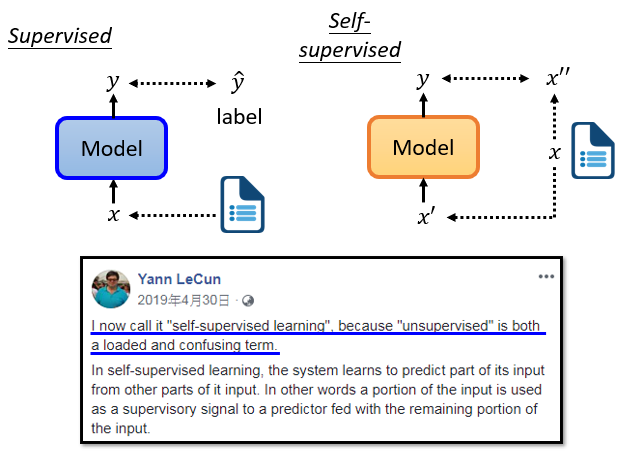
自監督學習 是用另一種方式來監督,沒有標簽,假設我們只有一堆沒有label的文章,例如,一篇文章叫x,我們把x分成兩部分,一部分叫x’,另一部分叫x’’,然后把x’輸入模型,讓它輸出y,這里的x’'充當了label的作用,但是是從原本無標簽的訓練資料中劃分出來的,所以叫做自監督學習,由于在Self-supervised學習中不使用標簽,我們可以說,Self-supervised學習也是一種無監督的學習方法,但之所以叫Self-supervised Learning,是為了讓定義更清晰,
自監督學習主要是利用輔助任務(pretext)從大規模的無監督資料中挖掘自身的監督資訊,通過這種構造的監督資訊對網路進行訓練,從而可以學習到對下游任務有價值的表征,
2 訓練 BERT 的方法一:Masking Input
下面我們直接拿BERT模型來說明自監督學習的典型訓練方法,首先,BERT是一個transformer的Encoder,里面有很多Self-Attention和Residual connection,還有Normalization等等,之前已經提到過了,
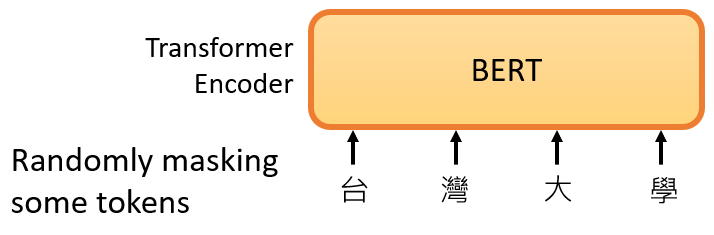
如果你已經忘記了Encoder里有哪些部件,那這里只需要記住的關鍵點是:BERT可以輸入一行向量,然后輸出另一行向量,輸出的長度與輸入的長度相同,
BERT一般用于自然語言處理,用于文本場景,所以一般來說,它的輸入是一串文本,也是一串資料,當我們真正談論Self-Attention的時候,我們也說不僅文本是一種序列,而且語音也可以看作是一種序列,甚至影像也可以看作是一堆向量,所以BERT不僅用于NLP,或者用于文本,它也可以用于語音和視頻,
接下來我們需要做的是,隨機蓋住一些輸入的文字,被mask的部分是隨機決定的,例如,我們輸入100個token,在中文文本中,我們通常把一個漢字看作是一個token,當我們輸入一個句子時,其中的一些詞會被隨機mask,
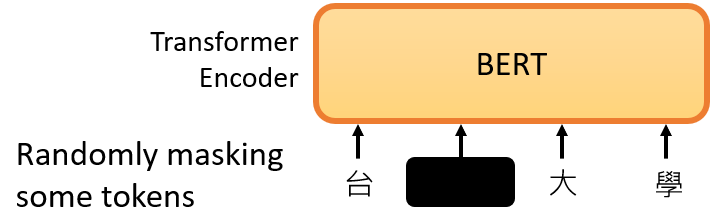
mask的具體實作有兩種方法:
-
第一種方法是,用一個特殊的符號替換句子中的一個詞,我們用 "MASK "標記來表示這個特殊符號,你可以把它看作一個新字,這個字完全是一個新詞,它不在你的字典里,這意味著mask了原文,
-
另外一種方法,隨機把某一個字換成另一個字,中文的 "灣"字被放在這里,然后你可以選擇另一個中文字來替換它,它可以變成 "一 "字,變成 "天 "字,變成 "大 "字,或者變成 "小 "字,我們只是用隨機選擇的某個字來替換它,
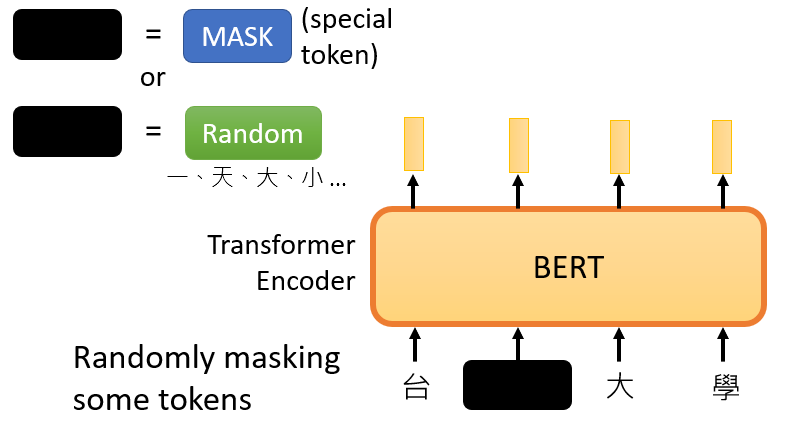
兩種方法都可以使用,使用哪種方法也是隨機決定的,因此,當BERT進行訓練時,向BERT輸入一個句子,先隨機決定哪一部分的漢字將被mask,mask后,一樣是輸入一個序列,我們把BERT的相應輸出看作是另一個序列,接下來,我們在輸入序列中尋找mask部分的相應輸出,然后,這個向量將通過一個Linear transform,所謂的Linear transform是指,輸入向量將與一個矩陣相乘,然后做softmax,輸出一個分布,
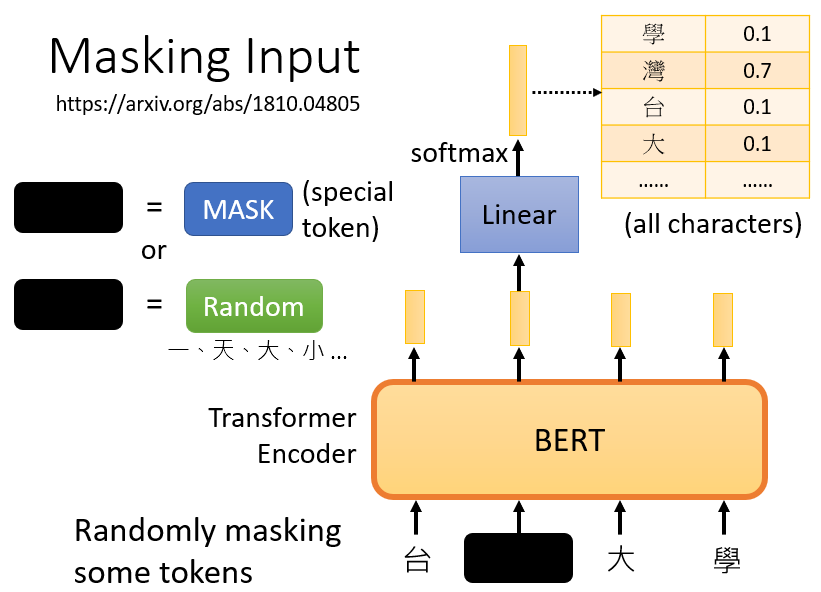
在訓練程序中,我們知道被mask的字符是什么,而BERT不知道,我們可以用一個one-hot vector來表示這個字符,我們訓練的目標就是使輸出vector和真實字符的vector之間的交叉熵損失最小,
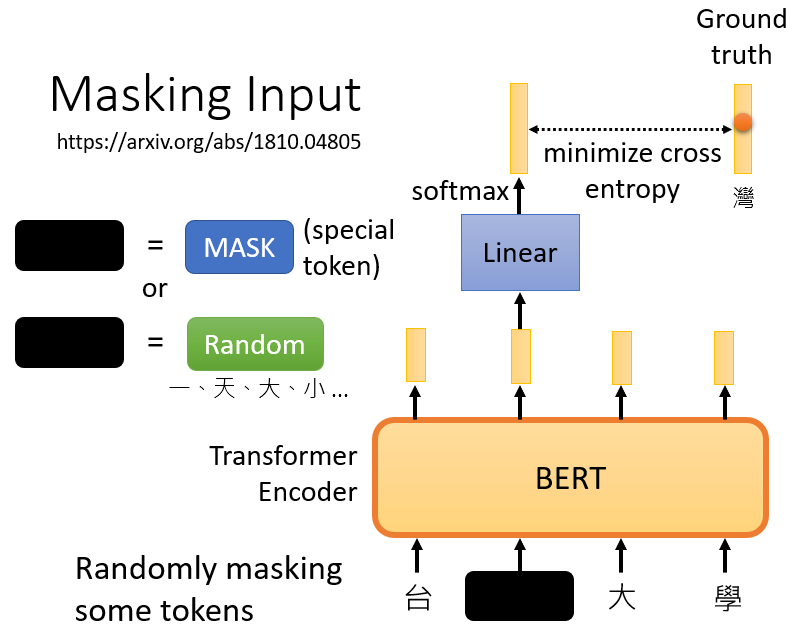
或者說得簡單一點,我們實際上是在解決一個分類問題,現在,BERT要做的是,預測什么被蓋住,在上面的例子中被掩蓋的字符,屬于 "灣"類,這就是訓練BERT的方法之一,
3 訓練 BERT 的方法二:Next Sentence Prediction
事實上,當我們訓練BERT時,除了mask之外,我們還會使用另一種方法,這種額外的方法叫做Next Sentence Prediction ,
它的意思是,我們從資料庫中拿出兩個句子,這是我們通過在互聯網上抓取和搜索檔案得到的大量句子集合,我們在這兩個句子之間添加一個特殊標記,這樣,BERT就可以知道,這兩個句子是不同的句子,因為這兩個句子之間有一個分隔符,
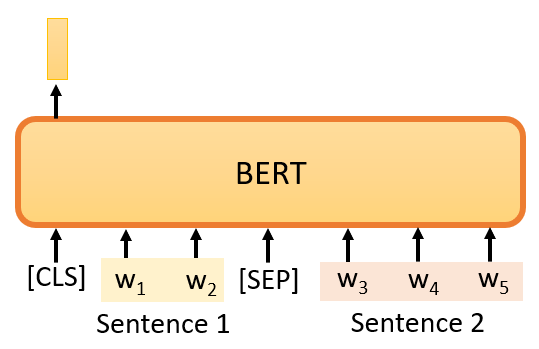
我們還將在句子的開頭添加一個特殊標記,這里我們用CLS來表示這個特殊標記,
現在,我們有一個很長的序列,包括兩個句子,由SEP標記和前面的CLS標記分開,如果我們把它傳給BERT,它應該輸出一個序列,因為輸入也是一個序列,這畢竟是Encoder的目的,
我們將只看CLS的輸出,我們將把它通過一個Linear transform,
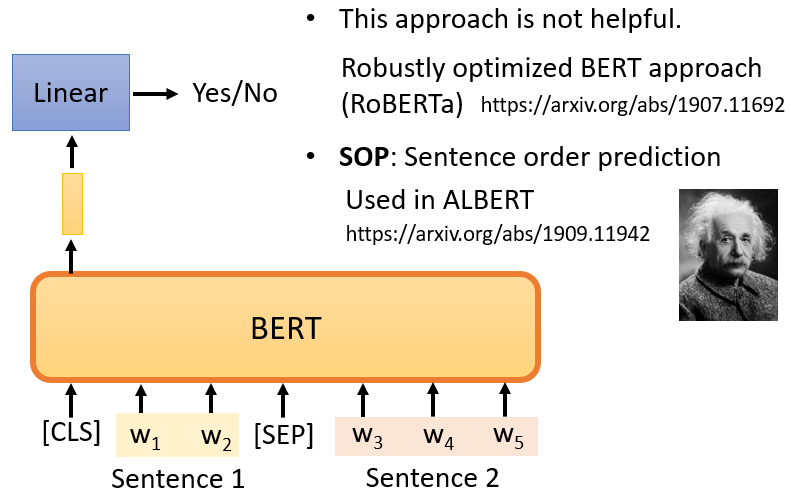
現在它必須做一個二分類問題,有兩個可能的輸出:是或不是,這個方法被稱為Next Sentence Prediction ,所以我們需要預測,第二句是否是第一句的后續句,
然而,后來的研究發現,對于BERT要做的任務來說,Next Sentence Prediction 并沒有真正的幫助,它幫助不大可能的原因之一是,Next Sentence Prediction 太簡單了,是一項容易的任務,
這個任務的典型方法是,首先隨機選擇一個句子,然后從資料庫中或隨機選擇要與前一個句子相連的句子,通常,當我們隨機選擇一個句子時,它看起來與前一個句子有很大不同,對于BERT來說,預測兩個句子是否相連并不是太難,因此,在訓練BERT完成Next Sentence Prediction 的任務時,沒有學到什么太有用的東西,
還有一種類似于Next Sentence Prediction 的方法,它看起來更有用,它被稱為Sentence order prediction,簡稱SOP,
這個方法的主要思想是,我們最初挑選的兩個句子可能是相連的,可能有兩種可能性:要么句子1在句子2后面相連,要么句子2在句子1后面相連,有兩種可能性,我們問BERT是哪一種,
也許因為這個任務更難,它似乎更有效,它被用在一個叫ALBERT的模型中,這是BERT的高級版本,
所以結合BERT訓練的兩個任務來說,BERT它學會了如何填空,BERT的神奇之處在于,在你訓練了一個填空的模型之后,它還可以用于其他任務,這些任務不一定與填空有關,也可能是完全不同的任務,但BERT仍然可以用于這些任務,這些任務是BERT實際使用的任務,它們被稱為Downstream Tasks(下游任務),

所謂的 "Downstream Tasks "是指你真正關心的任務,但是,當我們想讓BERT學習做這些任務時,我們仍然需要一些標記的資訊,
總之,BERT只是學習填空,但是,以后可以用來做各種你感興趣的Downstream Tasks ,它就像胚胎中的干細胞,它有各種無限的潛力,我們只需要給它一點資料來激發它,它就能做到很多比填空看起來更加復雜的問題,
BERT分化成各種任務的功能細胞,被稱為Fine-tune(微調),所以,我們經常聽到有人說,他對BERT進行了微調,也就是說他手上有一個BERT,他對這個BERT進行了微調,使它能夠完成某種任務,與微調相反,在微調之前產生這個BERT的程序稱為預訓練,所以,生成BERT的程序就是Self-supervised學習,但是,你也可以稱之為預訓練,
今天,為了測驗Self-supervised學習的能力,通常你會在多個任務上測驗它,因為我們剛才說,BERT就像一個胚胎干細胞,它要分化成各種任務的功能細胞,我們通常不會只在一個任務上測驗它的能力,你會讓這個BERT分化成各種任務的功能細胞,看看它在每個任務上的準確性,然后我們取其平均值,得到一個總分,這種不同任務的集合,我們可以稱之為任務集,任務集中最著名的基準被稱為GLUE,它是General Language Understanding Evaluation的縮寫,

在GLUE中,總共有9個任務,所以你實際上會得到9個模型,用于9個單獨的任務,你看看這9個任務的平均準確率,然后得到一個值,這個值代表這個Self-supervised模型的性能,
下圖是BERT在GLUE上的性能測驗結果:
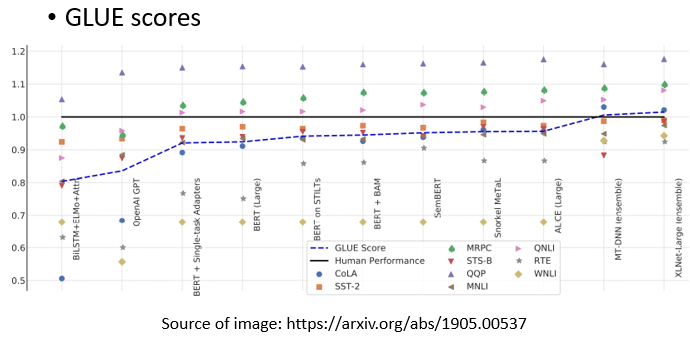
在這張圖中,橫軸表示不同的模型,這里你可以發現除了ELMO和GPT,還有很多其他的BERT,從左到右出現的模型也是按時間順序來到,可以看到BERT的GLUE得分,也就是9個任務的平均得分,確實逐年增加,
黑色的線表示人類在這個任務上的準確度,我們把這個當作1,這里每一個點代表一個任務,如果這些模型的表現比人類好,這些點的值就會大于1,如果比人類差,這些點的值就會小于1,
所以你會發現,在原來的9個任務中,只有1個任務,機器可以比人類做得更好,隨著越來越多的技術被提出,越來越多的任務可以比人類做得更好,對于那些之前看來遠不如人類的任務,它們也在逐漸追趕,
藍色曲線表示機器GLUE得分的平均值,還發現最近的一些強勢模型,例如XLNET,甚至超過了人類,當然,這只是這些資料集的結果,并不意味著機器真的在總體上超過了人類,它在這些資料集上超過了人類,這意味著這些資料集并不能代表實際的表現,而且難度也不夠大,
所以,在GLUE之后,有人做了Super GLUE,他們找到了更難的自然語言處理任務,讓機器來解決,好了!展示這幅圖的意義主要是告訴大家,有了BERT這樣的技術,機器在自然語言處理方面的能力確實又向前邁進了一步,
BERT到底是怎么用的呢?我們將給出4個關于BERT的應用案例,
4 BERT 的應用案例決議
4.1 情感分析
第一個案例是這樣的,我們假設我們的下游任務是輸入一個序列,然后輸出一個class,也就是說是一個分類問題,比如說Sentiment analysis情感分析,就是給機器一個句子,讓它判斷這個句子附帶的情感是正面的還是負面的,
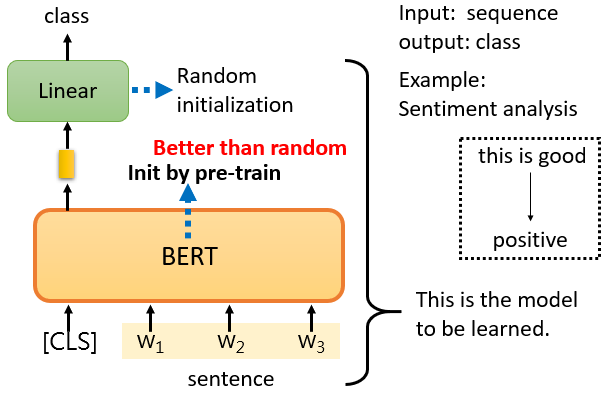
對于BERT來說,它是如何解決情感分析的問題的?
你只要給它一個句子,也就是你想用它來判斷情緒的句子,然后把CLS標記放在這個句子的前面,在上圖的例子中,這4個輸入實際上對應著4個輸出,然后,我們**只看CLS的部分的輸出,**CLS在這里輸出一個向量,我們對它進行Linear transform,也就是將它乘以一個Linear transform的矩陣,這里省略了Softmax,
然而,在實踐中,你必須為你的下游任務提供標記資料,換句話說,BERT沒有辦法從頭開始解決情感分析問題,你仍然需要向BERT提供一些標記資料,你需要向它提供大量的句子,以及它們的正負標簽,來訓練這個BERT模型,
在訓練的時候,Linear transform和BERT模型都是利用Gradient descent來更新引數的,
- Linear transform的引數是隨機初始化的
- 而BERT的引數是由學會填空的BERT初始化的,
每次我們訓練模型的時候,我們都要初始化引數,我們利用梯度下降來更新這些引數,然后嘗試minimize loss,
例如,我們正在做情感分類,但是,我們現在有BERT,我們不必隨機初始化所有的引數,,我們唯一隨機初始化的部分是Linear這里,BERT的骨干是一個巨大的transformer的Encoder,這個網路的引數不是隨機初始化的,把學過填空的BERT引數,放到這個地方的BERT中作為引數初始化,
我們為什么要這樣做呢?為什么要用學過填空的BERT,再放到這里呢?最直觀和最簡單的原因是,它比隨機初始化新引數的網路表現更好,當你把學會填空的BERT放在這里時,它將獲得比隨機初始化BERT更好的性能,
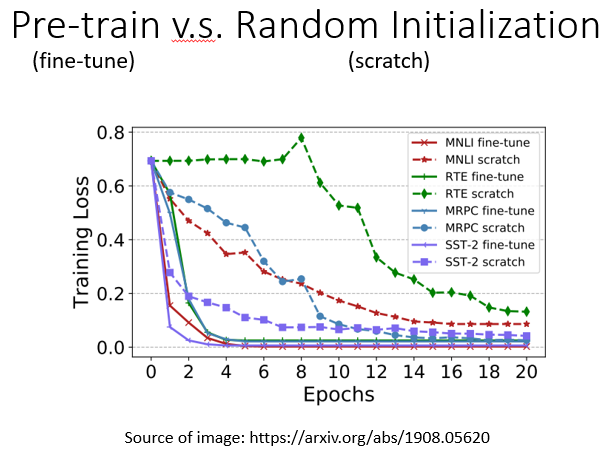
在這里有篇文章中有一個例子,橫軸是訓練周期,縱軸是訓練損失,到目前為止,大家對這種圖一定很熟悉,隨著訓練的進行,損失當然會越來越低,在這個圖中:
- fine-tune是指模型的BERT部分使用了預訓練的引數來初始化的,
- scratch表示整個模型都是隨機初始化的,
首先,在訓練網路時,scratch與用學習填空的BERT初始化的網路相比,損失下降得比較慢,最后,用隨機初始化引數的網路的損失仍然高于用學習填空的BERT初始化的引數,
- 當你進行Self-supervised學習時,你使用了大量的無標記資料,
- 另外,Downstream Tasks 需要少量的標記資料,
所謂的 "半監督 "是指,你有大量的無標簽資料和少量的有標簽資料,這種情況被稱為 “半監督”,所以使用BERT的整個程序是連續應用Pre-Train和Fine-Tune,它可以被視為一種半監督方法,
4.2 詞性標記
第二個案例是,輸入一個序列,然后輸出另一個序列,而輸入和輸出的長度是一樣的,我們在講Self-Attention的時候也舉了類似的例子, 例如POS tagging,也就是詞性標記的問題,
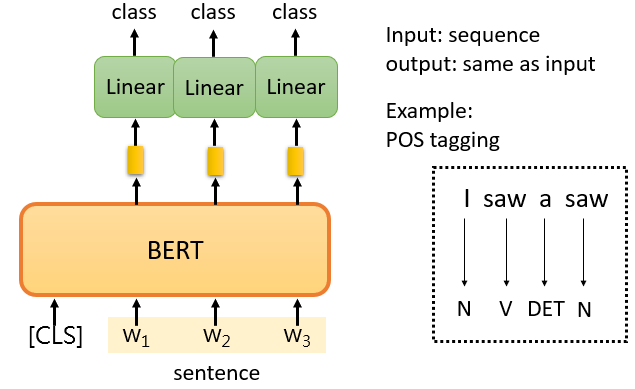
所謂的詞性標記,就是你給機器一個句子,它必須告訴你這個句子中每個詞的詞性,即使這個詞是相同的,也可能有不同的詞性,
你只需向BERT輸入一個句子,之后,對于這個句子中的每一個標記,它是一個中文單詞,有一個代表這個單詞的相應向量,然后,這些向量會依次通過Linear transform和Softmax層,最后,網路會預測給定單詞所屬的類別,例如,它的詞性,
當然,類別取決于你的任務,如果你的任務不同,相應的類別也會不同,接下來你要做的事情和案例1完全一樣,換句話說,你需要有一些標記的資料,這仍然是一個典型的分類問題,唯一不同的是,BERT部分,即網路的Encoder部分,其引數不是隨機初始化的,在預訓練程序中,它已經找到了不錯的引數,
當然,我們在這里展示的例子屬于自然語言處理,但是你可以把這些例子改成其他任務,例如,你可以把它們改成語音任務,或者改成計算機視覺任務,因為之前就提到了語音、文本和影像都可以表示為一排向量,
4.3 自然語言推斷
第三個案例是,模型輸入兩個句子,輸出一個類別,什么樣的任務采取這樣的輸入和輸出? 最常見的是Natural Language Inference ,它的縮寫是NLI,
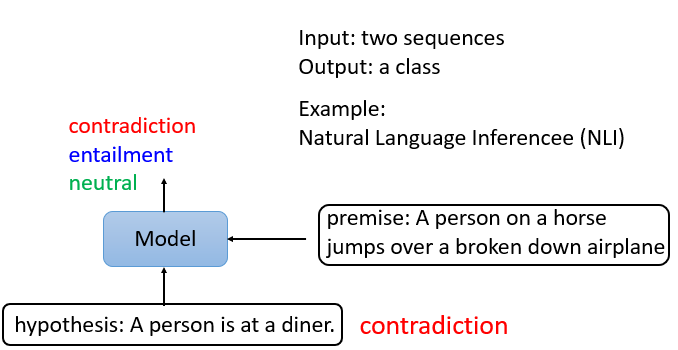
所謂NLI,機器要做的就是判斷是否有可能從前提中推斷出假設,這個前提與這個假設相矛盾嗎?或者說它們不是相矛盾的句子?在這個例子中,我們的前提是,一個人騎著馬,然后他跳過一架破飛機,這聽起來很奇怪,但這個句子實際上就是這樣的,這是一個基準語料庫中的一個例子,這里的假設是,這個人在一個餐館,所以推論說這是一個矛盾,
所以機器要做的是,把兩個句子作為輸入,并輸出這兩個句子之間的關系,這種任務很常見,它可以用在哪里呢?例如,輿情分析,給定一篇文章,下面有一個評論,這個訊息是同意這篇文章,還是反對這篇文章?該模型想要預測的是每條評論的位置,事實上,有很多應用程式接收兩個句子,并輸出一個類別,
BERT是如何解決這個問題的?你只要給它兩個句子,我們在這兩個句子之間放一個特殊的標記SEP,并在最開始放CLS標記,
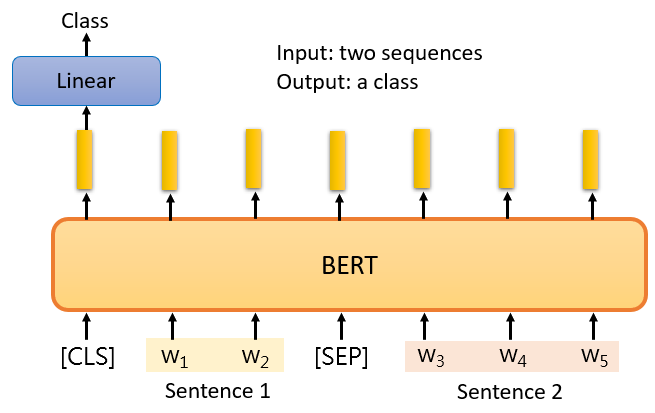
這個序列是BERT的輸入,但我們只把CLS標記作為Linear transform的輸入,它決定這兩個輸入句子的類別,對于NLI,你必須問,這兩個句子是否是矛盾的,它是用一些預先訓練好的權重來初始化的,
4.4 基于資訊抽取的問答
第四個案例是用BERT實作一個問題回答系統,也就是說,在機器讀完一篇文章后,你問它一個問題,它將給你一個答案,
但是,這里的問題和答案稍有限制,這是Extraction-based的QA,也就是說,我們假設答案必須出現在文章中,答案必須是文章中的一個片段,
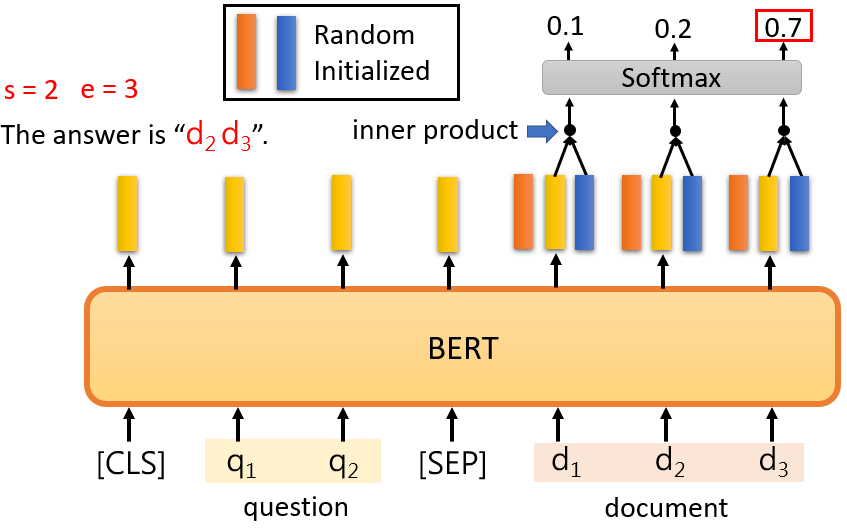
在這個任務中,一個輸入序列包含一篇文章和一個問題,文章和問題都是一個序列,對于中文來說,每個d代表一個漢字,每個q代表一個漢字,你把d和q放入QA模型中,我們希望它輸出兩個正整數s和e,根據這兩個正整數,我們可以直接從文章中截取一段,它就是這個問題的答案,

這聽起來很瘋狂,但是這是現在使用的一個相當標準的方法,舉一個具體的例子來說,這里有一個問題和一篇文章,正確答案是 “gravity”,機器如何輸出正確答案?

你的模型應該輸出,s等于17,e等于17,來表示gravity,因為它是整篇文章中的第17個詞,所以s等于17,e等于17,意味著輸出第17個詞作為答案,
再舉另一個例子,答案是,“within a cloud”,這是文章中的第77至79個詞,你的模型要做的是,輸出77和79這兩個正整數,那么文章中從第77個詞到第79個詞的分割應該是最終的答案,
當然,我們不是從頭開始訓練QA模型,為了訓練這個QA模型,我們使用BERT預訓練的模型,
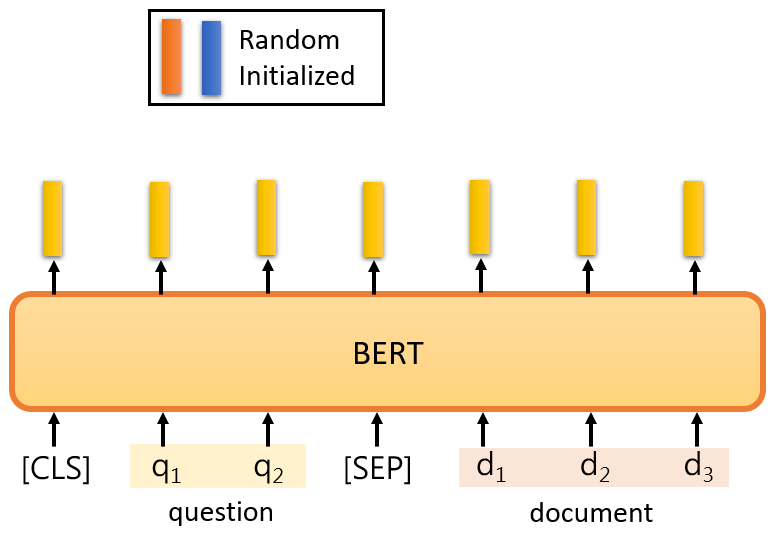
這個解決方案是這樣的,對于BERT來說,你必須向它展示一個問題,一篇文章,以及在問題和文章之間的一個特殊標記,然后我們在開頭放一個CLS標記,
在這個任務中,你唯一需要從頭訓練的只有兩個向量,"從頭訓練 "是指隨機初始化,這里我們用橙色向量和藍色向量來表示,這兩個向量的長度與BERT的輸出相同,
假設BERT的輸出是768維的向量,這兩個向量也是768維的向量,那么,如何使用這兩個向量?
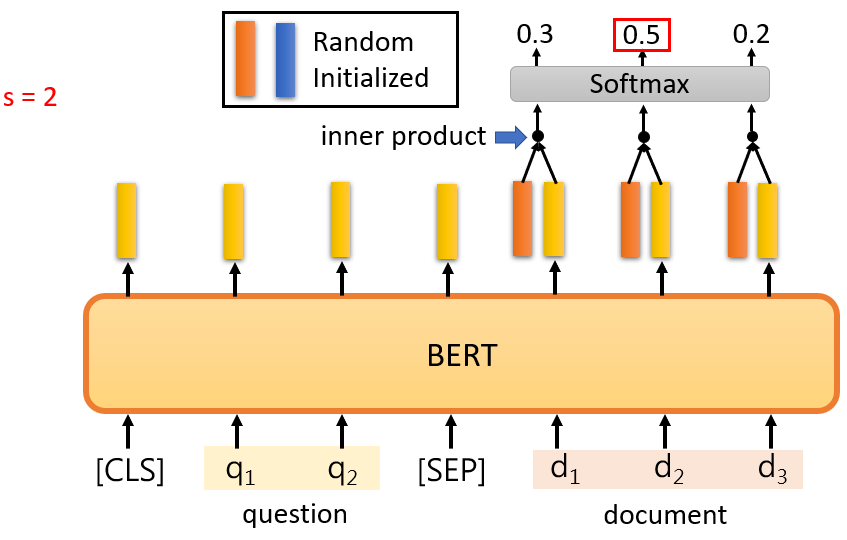
-
首先,計算這個橙色向量和那些與檔案相對應的輸出向量的內積,由于有3個代表文章的標記,它將輸出三個向量,計算這三個向量與橙色向量的內積,你將得到三個值,然后將它們通過softmax函式,你將得到另外三個值,
這個內積和attention很相似,你可以把橙色部分看成是query,黃色部分看成是key,這是一個attention,那么我們應該嘗試找到分數最大的位置,就是這里,橙色向量和d2的內積,如果這是最大值,s應該等于2,你輸出的起始位置應該是2
-
藍色部分做的是完全一樣的事情,藍色部分代表答案的終點,我們計算這個藍色向量與文章對應的黃色向量的內積,然后,我們在這里也使用softmax,最后,找到最大值,如果第三個值是最大的,e應該是3,正確答案是d2和d3,
因為答案必須在文章中,如果答案不在文章中,你就不能使用這個技巧,這就是一個QA模型需要做的,注意,這兩個向量是隨機初始化的,而BERT是通過它預先訓練的權重初始化的,
5 BERT 的訓練并不容易
BERT真的是一個非常出名的模型,它可以做任何事情,那么你可能會認為BERT在預訓練中只是做填空題,應該比較容易訓練,但是BERT的訓練并沒有想象中的那么容易,
首先,谷歌最早的BERT,它使用的資料規模已經很大了,它的資料中包含了30億個詞匯,30億個詞匯有多少?是《哈利波特全集》的3000倍,所以訓練資料處理起來會比較痛苦,更痛苦的是訓練程序,李老師實驗室有一個學生,也是現在的助教之一,他自己試著訓練一個ALBERT,看究竟能不能重現谷歌的結果,
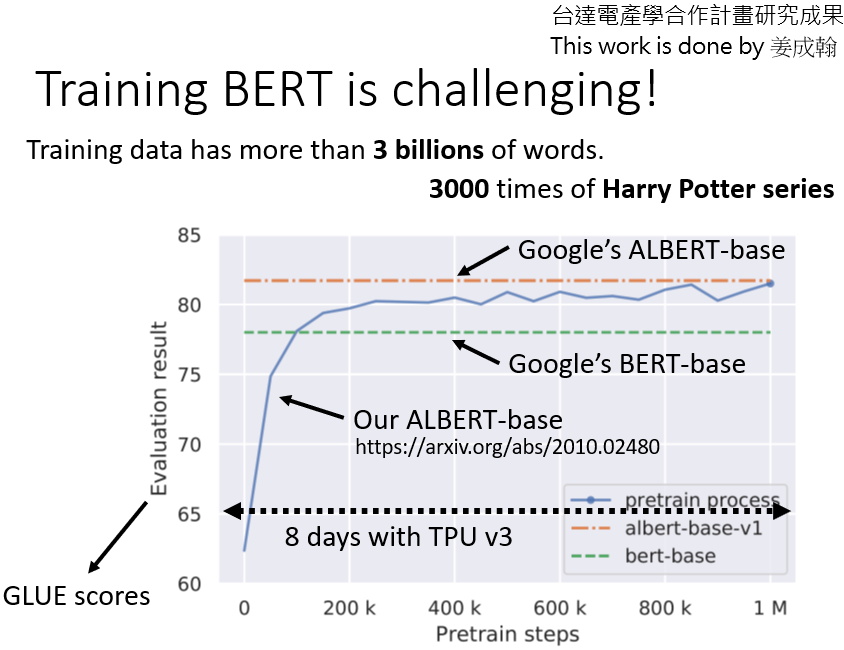
ALBERT是BERT的一個高級版本,谷歌的結果是橙色的線,藍線是我們自己訓練的ALBERT,但是我們實際訓練的不是最大版本,BERT有一個base版本和一個large版本,對于大版本,我們很難自己訓練它,所以我們嘗試用最小的版本來訓練,看它是否與谷歌的結果相同,
橫軸是訓練程序,要達到谷歌base相同的效果,引數大約有一百萬次的更新,用TPU運行了8天,如果你在Colab上做,這個至少要運行200天,你甚至可能到明年才能得到結果,
所以,你真的很難自己訓練這種BERT模型,幸運的是,當前我們的使用場景大都是在預訓練好了的模型上進行微調,來服務于我們想要完成的下游任務,但是,如果你想從頭開始訓練它,這將需要大量的時間,是十分困難的,
6 BERT 胚胎學
谷歌已經訓練了BERT,而且這些Pre-Train模型是公開的,我們自己訓練一個,結果和谷歌的BERT差不多,這有什么意義呢?
其實是想建立BERT胚胎學,“BERT胚胎學是什么意思?”
我們知道在BERT的訓練程序中需要非常大的計算資源,所以我們想知道有沒有可能,節省這些計算資源?有沒有可能讓它訓練得更快?,要知道如何讓它訓練得更快,也許我們可以從觀察它的訓練程序開始,
過去沒有人觀察過BERT的訓練程序,因為在谷歌的論文中,他們只是告訴你,我有這個BERT,然后它在各種任務中做得很好,
BERT在學習填空的程序中,學到了什么?"它在這個程序中何時學會填動詞?什么時候學會填名詞? 什么時候學會填代詞? 沒有人研究過這個問題,
所以我們自己訓練BERT后,可以觀察到BERT什么時候學會填什么詞匯,它是如何提高填空能力的? 這里放一篇論文的鏈接供大家參考,
Pretrained Language Model Embryology: The Birth of ALBERT (arxiv.org)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291409.html
標籤:AI
上一篇:機器學習課后題——支持向量機