吳恩達機器學習2——單變數線性回歸
監督學習作業模式
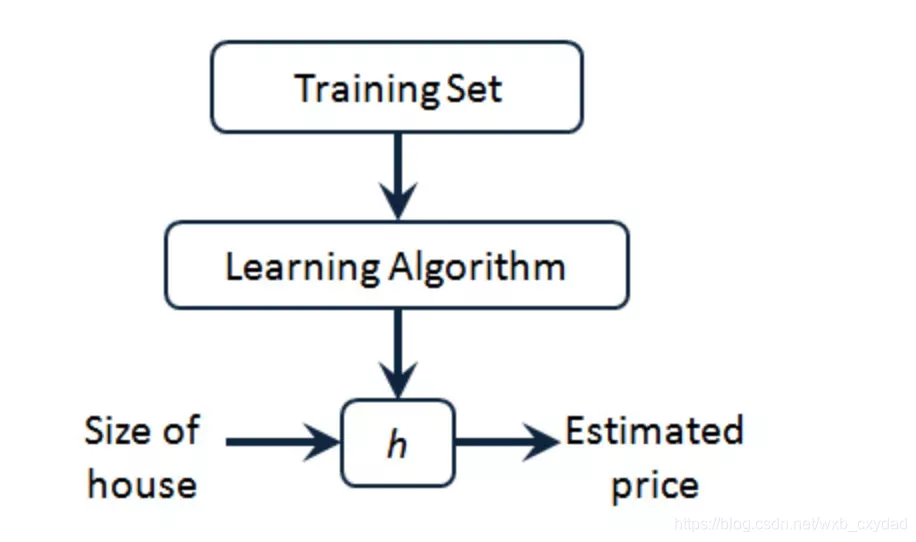
訓練集中同時給出了輸入輸出,即人為標注的“正確結果”喂給學習演算法,得到一個函式h,h
可以根據輸入的x得到一個y,因此h是x到y的一個映射,
一種可能的表達方式為:
hθ(x)=θ0+θ1x
因為只含有一個特征/輸入變數,因此這樣的問題叫作單變數線性回歸問題,
x:特征/輸入變數
上式中, θ為引數, θ 的變化才決定了輸出結果,不同以往,這里的 x 被我們視作已知(不論是資料集還是預測時的輸入),所以怎樣解得 θ以更好地擬合資料,成了求解該問題的最終問題,
2.2代價函式(cost function)
損失函式(loss function):計算單個樣本的誤差
代價函式(cost function):計算整個訓練集所有損失函式之和的平均值

為求解最小值,引入代價函式(cost function)的概念
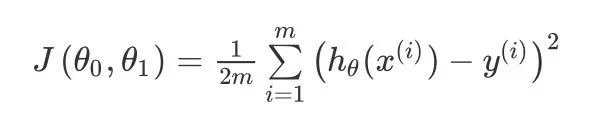
問題轉化為求解J(θ0,θ1)的最小值
系數1/2不影響結果,是為了在應用梯度下降時,平方的導數抵消1/2,便于計算,
假設θ0=0,得到的hθ(x)和J(θ1)如下
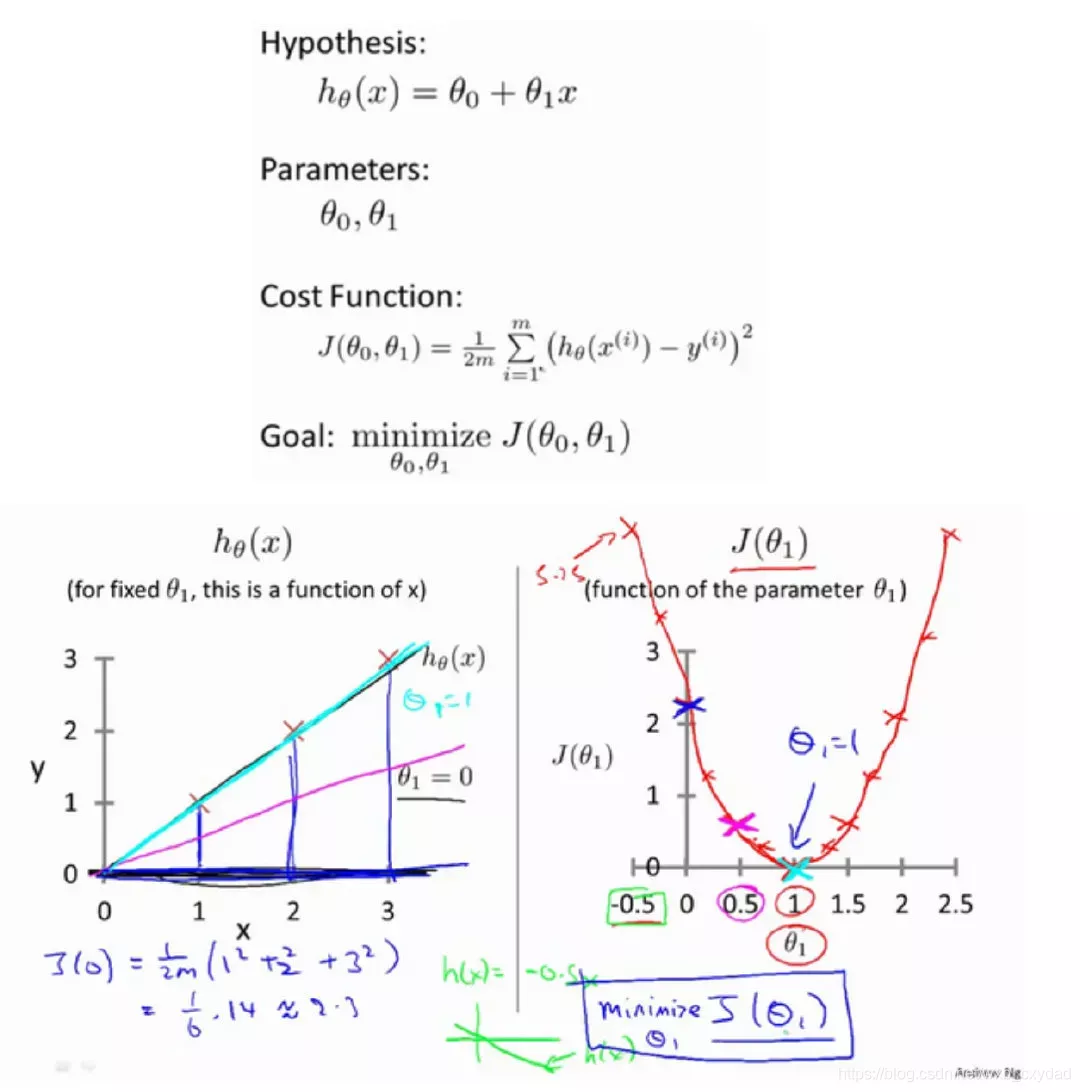
以此類推,θ≠0時
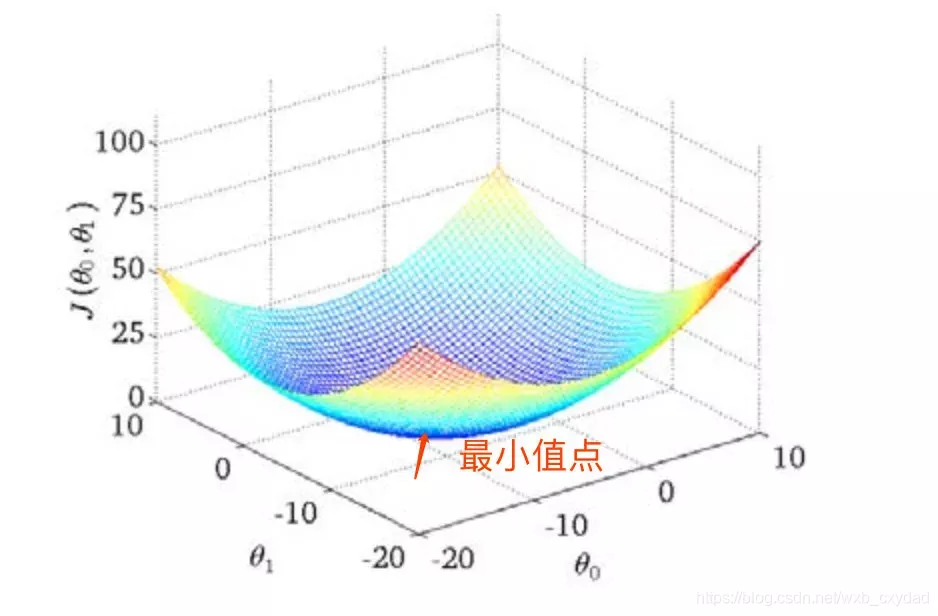
可以看出仍存在一點使J(θ0,θ1)最小.
2.5梯度下降(gradient descent)
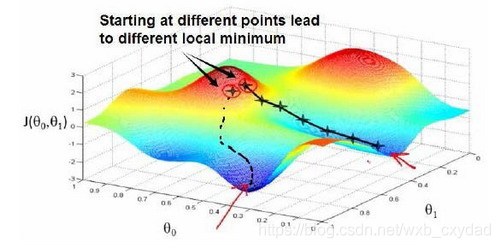
梯度下降背后的思想是:開始時,我們隨機選擇一個引陣列合(θ0,θ1,…θn)即起始點,計算代價函式,然后尋找下一個能使得代價函式下降最多的引陣列合,不斷迭代,直到找到一個區域最小值(local minimum),由于下降的情況只考慮當前引陣列合周圍的情況,所以無法確定當前的區域最小值是否就是全域最小值(global minimum),不同的初始引陣列合,可能會產生不同的區域最小值,
批量梯度下降(batch gradient descent)演算法的公式為:
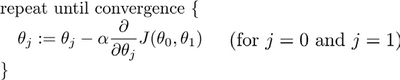
公式中,學習率α決定了引數變化的速率即“走多少距離”,而偏導這部分決定了下降到方向即“下一步往哪里走”
實作梯度下降演算法的微妙之處是,在這個運算式中,如果你要更新這個等式,你需要同時更新θ0和θ1,我的意思是在這個等式中,我們要這樣像左邊一樣更新而不是右邊,否則結果上會有出入,原因不做細究
2.6梯度下降直觀理解
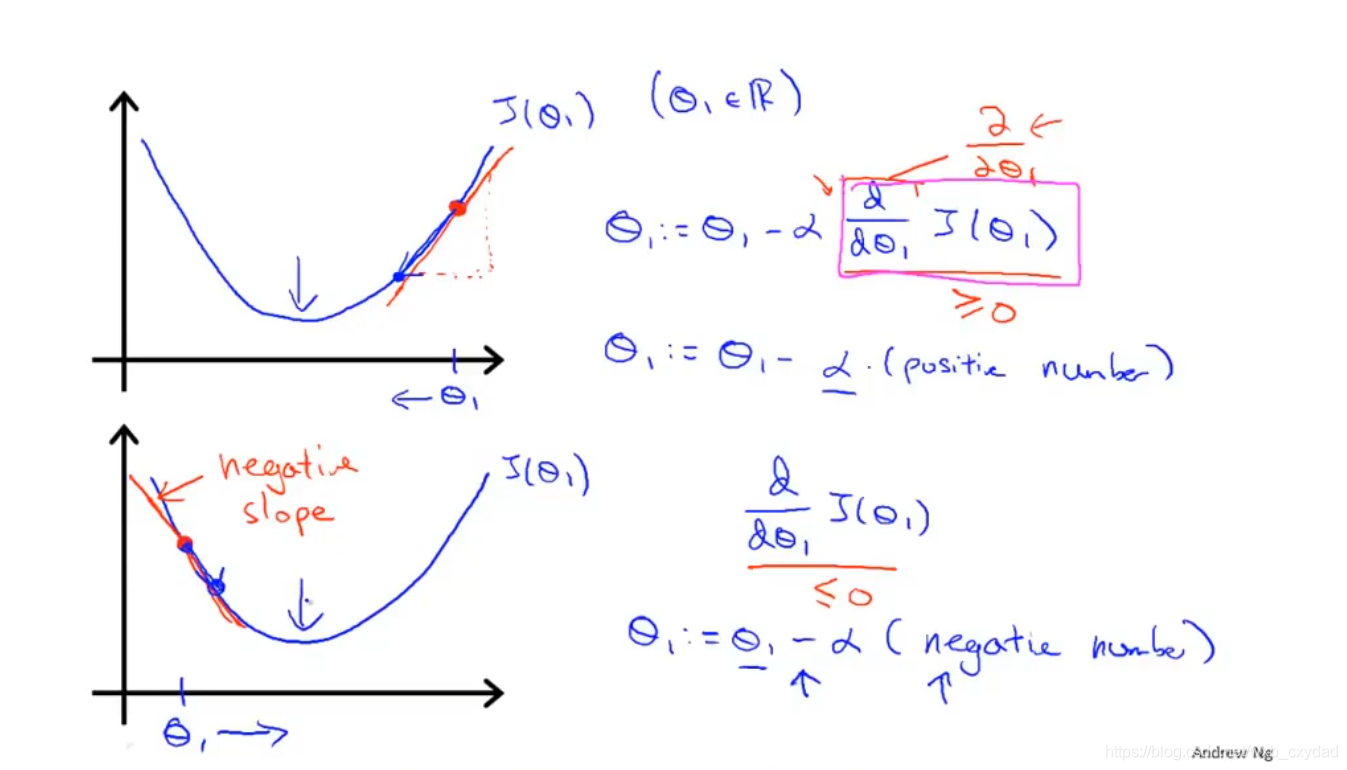
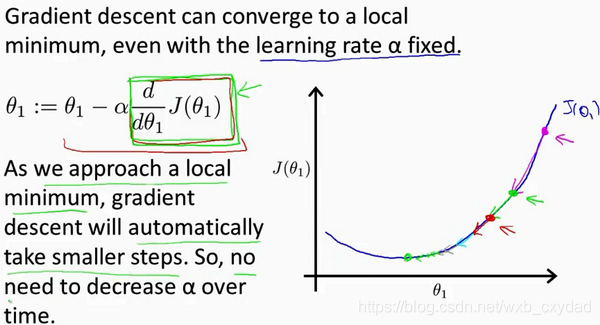
無論初始點是在左邊還是右邊,通過梯度下降法,θ1都會不斷向區域最小值移動,直到收斂,
對于學習率α,需要選擇一個合適的值才能使梯度下降法運行良好,
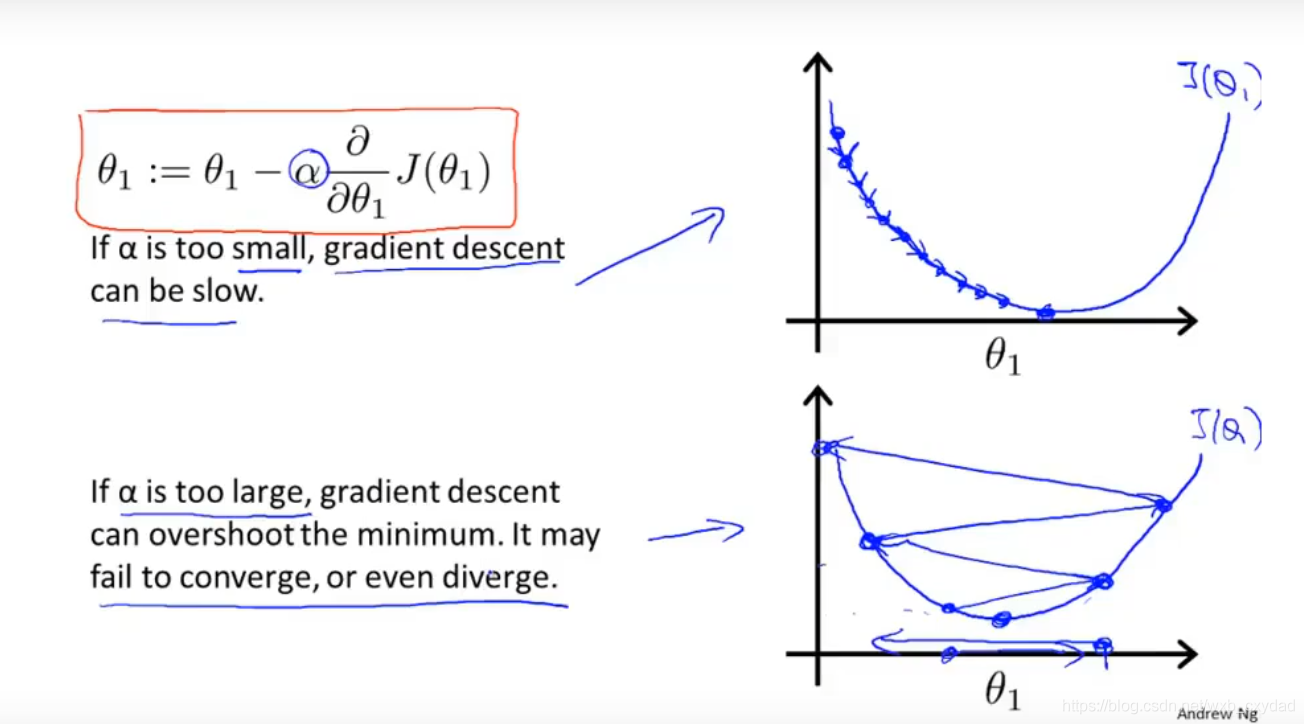
學習率不需要在運行梯度下降法時進行動態改變,隨著斜率接近0,代價函式的變化幅度會越來越小,直至為0.
2.7線性回歸中的梯度下降

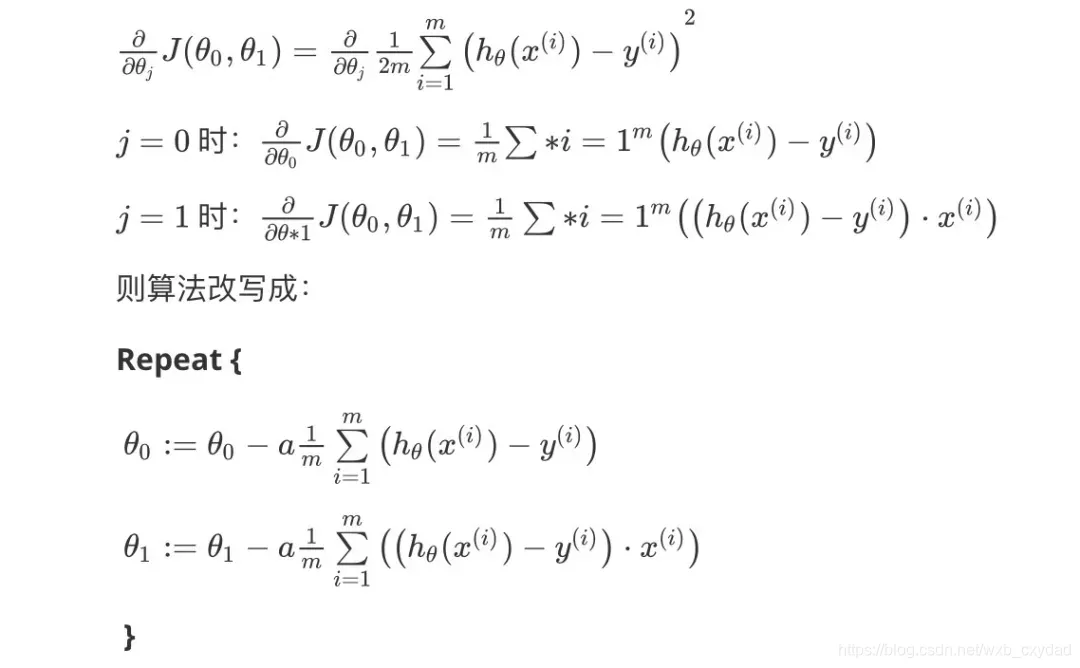
這種梯度下降的演算法稱之為批量梯度下降演算法,主要特點:
在梯度下降的每一步中,我們都用到了所有的訓練樣本
在梯度下降中,在計算微分求導項時,我們需要進行求和運算,需要對所有m個訓練樣本求和
線性回歸只有一個全域最優解,所以函式一定可以收斂到全域最小值(α不可以過大),J函式被稱為凸函式,線性回歸函式求解最小值問題屬于凸函式優化問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291410.html
標籤:AI