一、 BP神經網路預測演算法簡介
說明:1.1節主要是概括和幫助理解考慮影響因素的BP神經網路演算法原理,即常規的BP模型訓練原理講解(可根據自身掌握的知識是否跳過),1.2節開始講基于歷史值影響的BP神經網路預測模型,
使用BP神經網路進行預測時,從考慮的輸入指標角度,主要有兩類模型:
1.1 受相關指標影響的BP神經網路演算法原理
如圖一所示,使用MATLAB的newff函式訓練BP時,可以看到大部分情況是三層的神經網路(即輸入層,隱含層,輸出層),這里幫助理解下神經網路原理:
1)輸入層:相當于人的五官,五官獲取外部資訊,對應神經網路模型input埠接收輸入資料的程序,
2)隱含層:對應人的大腦,大腦對五官傳遞來的資料進行分析和思考,神經網路的隱含層hidden Layer對輸入層傳來的資料x進行映射,簡單理解為一個公式hiddenLayer_output=F(w*x+b),其中,w、b叫做權重、閾值引數,F()為映射規則,也叫激活函式,hiddenLayer_output是隱含層對于傳來的資料映射的輸出值,換句話說,隱含層對于輸入的影響因素資料x進行了映射,產生了映射值,
3)輸出層:可以對應為人的四肢,大腦對五官傳來的資訊經過思考(隱含層映射)之后,再控制四肢執行動作(向外部作出回應),類似地,BP神經網路的輸出層對hiddenLayer_output再次進行映射,outputLayer_output=w *hiddenLayer_output+b,其中,w、b為權重、閾值引數,outputLayer_output是神經網路輸出層的輸出值(也叫仿真值、預測值)(理解為,人腦對外的執行動作,比如嬰兒拍打桌子),
4)梯度下降演算法:通過計算outputLayer_output和神經網路模型傳入的y值之間的偏差,使用演算法來相應調整權重和閾值等引數,這個程序,可以理解為嬰兒拍打桌子,打偏了,根據偏離的距離遠近,來調整身體使得再次揮動的胳膊不斷靠近桌子,最終打中,
再舉個例子來加深理解:
圖一所示BP神經網路,具備輸入層、隱含層和輸出層,BP是如何通過這三層結構來實作輸出層的輸出值outputLayer_output,不斷逼近給定的y值,從而訓練得到一個精準的模型的呢?
從圖中串起來的埠,可以想到一個程序:坐地鐵,將圖一想象為一條地鐵線路,王某某坐地鐵回家的一天:在input起點站上車,中途經過了很多站(hiddenLayer),然后發現坐過頭了(outputLayer對應現在的位置),那么王某某將會根據現在的位置離家(目標Target)的距離(誤差Error),回傳到中途的地鐵站(hiddenLayer)重新坐地鐵(誤差反向傳遞,使用梯度下降演算法更新w和b),如果王某某又一次發生失誤,那么將再次進行這個調整的程序,
從在嬰兒拍打桌子和王某某坐地鐵的例子中,思考問題:BP的完整訓練,需要先傳入資料給input,再經過隱含層的映射,輸出層得到BP仿真值,根據仿真值與目標值的誤差,來調整引數,使得仿真值不斷逼近目標值,比如(1)嬰兒受到了外界的干擾因素(x),從而作出反應拍桌(predict),大腦不斷的調整胳膊位置,控制四肢拍準(y、Target),(2)王某某上車點(x),過站點(predict),不斷回傳中途站來調整位置,到家(y、Target),
在這些環節中,涉及了影響因素資料x,目標值資料y(Target),根據x,y,使用BP演算法來尋求x與y之間存在的規律,實作由x來映射逼近y,這就是BP神經網路演算法的作用,再多說一句,上述講的程序,都是BP模型訓練,那么最終得到的模型雖然訓練準確,但是找到的規律(bp network)是否準確與可靠呢,于是,我們再給x1到訓練好的bp network中,得到相應的BP輸出值(預測值)predict1,通過作圖,計算Mse,Mape,R方等指標,來對比predict1和y1的接近程度,就可以知道模型是否預測準確,這是BP模型的測驗程序,即實作對資料的預測,并且對比實際值檢驗預測是否準確,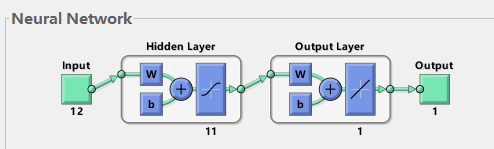
圖一 3層BP神經網路結構圖
1.2 基于歷史值影響的BP神經網路
以電力負荷預測問題為例,進行兩種模型的區分,在預測某個時間段內的電力負荷時:
一種做法,是考慮 t 時刻的氣候因素指標,比如該時刻的空氣濕度x1,溫度x2,以及節假日x3等的影響,對 t 時刻的負荷值進行預測,這是前面1.1所說的模型,
另一種做法,是認為電力負荷值的變化,與時間相關,比如認為t-1,t-2,t-3時刻的電力負荷值與t時刻的負荷值有關系,即滿足公式y(t)=F(y(t-1),y(t-2),y(t-3)),采用BP神經網路進行訓練模型時,則輸入到神經網路的影響因素值為歷史負荷值y(t-1),y(t-2),y(t-3),特別地,3叫做自回歸階數或者延遲,給到神經網路中的目標輸出值為y(t),
二、花授粉演算法
花朵授粉演算法( Flower Pollination Algorithm,FPA)是由英國劍橋大學學者Yang于2012年提出的,其基本思想來源于對自然界花朵自花授粉、異花授粉的模擬,是一種新的元啟發式群智能隨機優化技術 ,演算法中為了簡便計算,假設每個植物僅有一朵花,每朵花只有一個配子,我們可以認為每一個配子都是解空間中的一個候選解,
Yang通過對花朵授粉的研究,抽象出以下四大規則:
1) 生物異花授粉被考慮為演算法的全域探測行為,并由傳粉者通過Levy飛行的機制實作全域授粉;
2)非生物自花授粉被視作演算法的區域開采行為,或稱區域授粉;
3)花朵的常性可以被認為是繁衍概率,他與兩朵參與授粉花朵的相似性成正比例關系;
4)花朵的全域授粉與區域授粉通過轉換概率 p∈[0,1]進行調節, 由于物理上的鄰近性和風等因素的影響,在整個授粉活動中,轉換概率 p是一個非常重要的引數, 文獻[1]中對該引數的試驗研究認為,取 p =0.8 更利于演算法尋優,
直接上步驟(以多元函式尋優為例):
目標函式 : min g = f(x1,x2,x3,x4...........xd)
設定參量:N(候選解的個數),iter(最大迭代次數),p(轉換概率),lamda(Levy飛行引數)
初始化花朵,隨機設定一個NXd的矩陣;
計算適應度,即函式值;
獲取最優解和最優解得位置;
A回圈 1 : 1 :iter
B回圈
if rand < p
全域授粉;
else
區域授粉;
end if
更新新一代的花朵與適應度(函式變數和函式值);
B回圈end
獲取新一代的最優解與最優解位置;
A回圈end
全域更新公式:xi(t+1) = xi(t) + L(xi(t) - xbest(t)) L服從Levy分布,具體可以搜索布谷鳥演算法,
區域更新公式:xi(t+1) = xi(t) + m(xj(t) - xk(t)) m是服從在[0,1]上均勻分布的亂數,其中,xj和xk是兩個不同的個體
?三、代碼
function [mem,bestSol,bestFit,optima,FunctionCalls]=FPA(para)
% Default parameters
if nargin<1,
para=[50 0.25 500];
end
n=para(1); % Population size
p=para(2); % Probabibility switch
N_iter=para (3); % Number of iterations
phase = 1; %First state
phaseIte= [0.5,0.9,1.01]; %State vector
%Deb Function
d = 1;
Lb = 0;
Ub = 1;
optima = [.1;.3;.5;.7;.9];
% Initialize the population
for i=1:n,
Sol(i,:)=Lb+(Ub-Lb).*rand(1,d);
Fitness(i)=fitFunc(Sol(i,:)); %%Evaluate fitness function
end
% Initialice the memory
[mem,bestSol,bestFit,worstF] = memUpdate(Sol,Fitness, [], zeros(1,d), 100000000, 0, phase,d,Ub,Lb);
S = Sol;
FunctionCalls = 0;
% Main Loop
for ite = 1 : N_iter,
%For each pollen gamete, modify each position acoording
%to local or global pollination
for i = 1 : n,
% Switch probability
if rand>p,
L=Levy(d);
dS=L.*(Sol(i,:)-bestSol);
S(i,:)=Sol(i,:)+dS;
S(i,:)=simplebounds(S(i,:),Lb,Ub);
else
epsilon=rand;
% Find random flowers in the neighbourhood
JK=randperm(n);
% As they are random, the first two entries also random
% If the flower are the same or similar species, then
% they can be pollenated, otherwise, no action.
% Formula: x_i^{t+1}+epsilon*(x_j^t-x_k^t)
S(i,:)=S(i,:)+epsilon*(Sol(JK(1),:)-Sol(JK(2),:));
% Check if the simple limits/bounds are OK
S(i,:)=simplebounds(S(i,:),Lb,Ub);
end
Fitness(i)=fitFunc(S(i,:));
end
%Update the memory
[mem,bestSol,bestFit,worstF] = memUpdate(S,Fitness,mem,bestSol,bestFit,worstF,phase,d,Ub,Lb);
Sol = get_best_nest(S, mem, p);
FunctionCalls = FunctionCalls + n;
if ite/N_iter > phaseIte(phase)
%Next evolutionary process stage
phase = phase + 1;
[m,~]=size(mem);
%Depurate the memory for each stage
mem = cleanMemory(mem);
FunctionCalls = FunctionCalls + m;
end
end
%Plot the solutions (mem) founded by the multimodal framework
x = 0:.01:1;
y = ((sin(5.*pi.*x)).^ 6);
plot(x,y)
hold on
plot(mem(:,1),-mem(:,2),'r*');
四、仿真結果
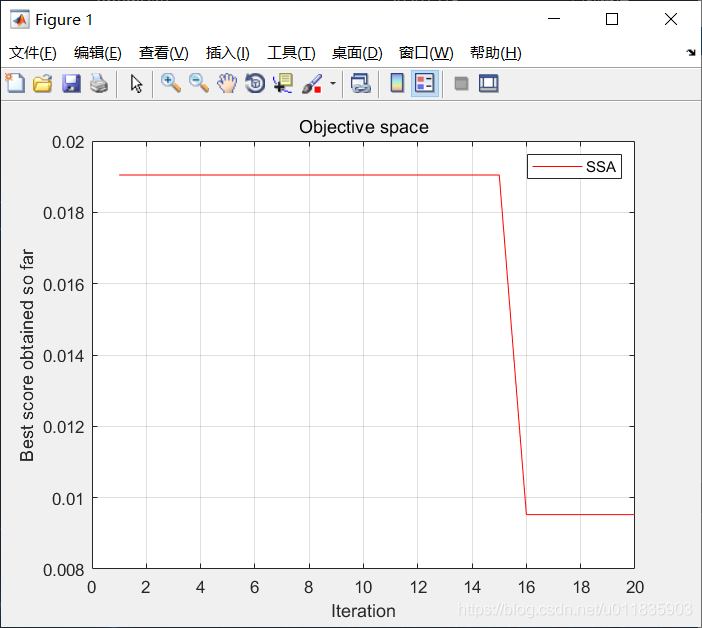
圖2花朵授粉演算法收斂曲線
測驗統計如下表所示
| 測驗結果 | 測驗集正確率 | 訓練集正確率 |
|---|---|---|
| BP神經網路 | 100% | 95% |
| FPA-BP | 100% | 99.8% |
五、參考文獻
《基于BP神經網路的寧夏水資源需求量預測》
》》 喜歡可以關注我

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291411.html
標籤:AI
下一篇:吳恩達機器學習筆記1