一、申請百度介面
-
注冊百度賬號
https://login.bce.baidu.com/ -
百度票據識別
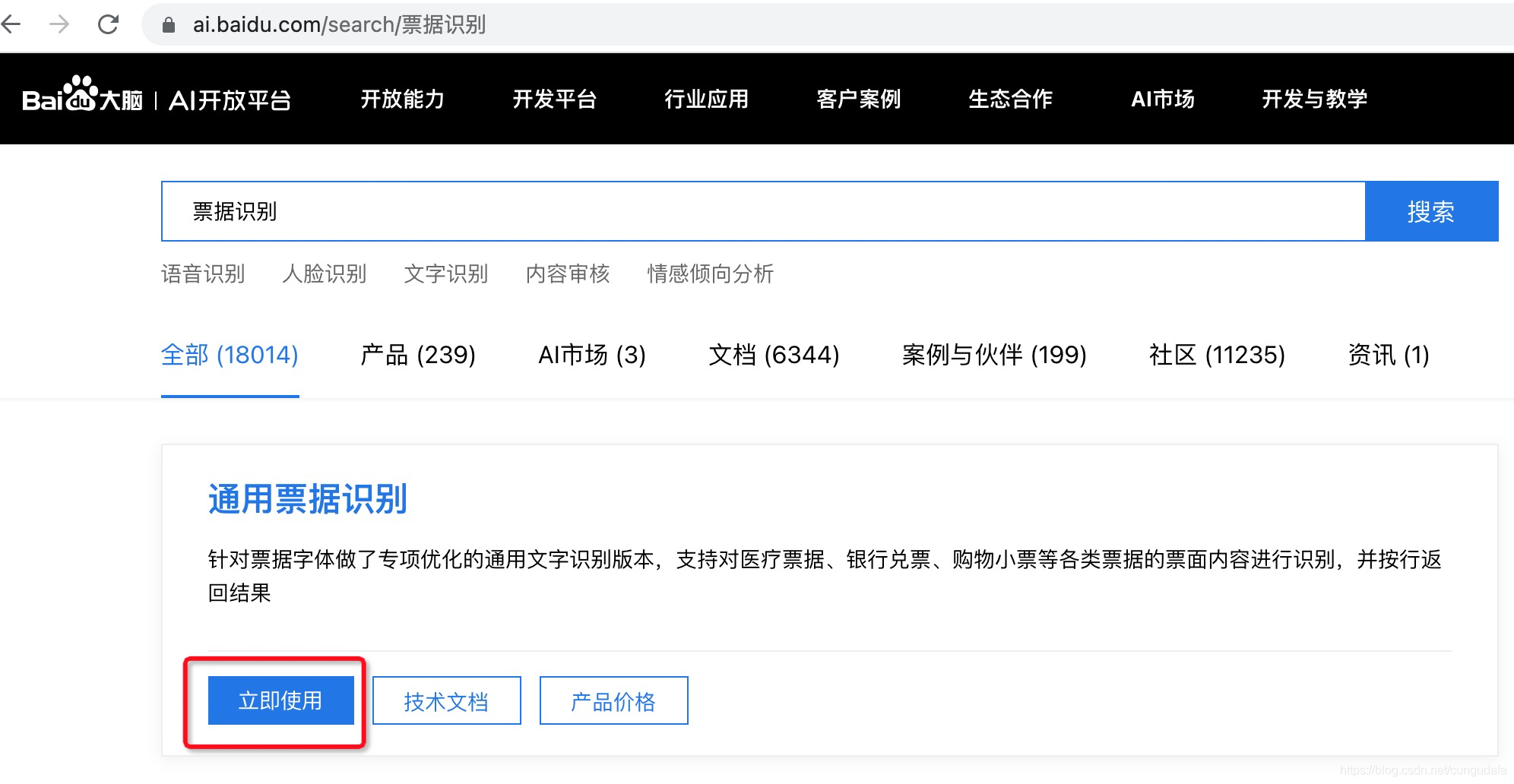
-
領取免費試用
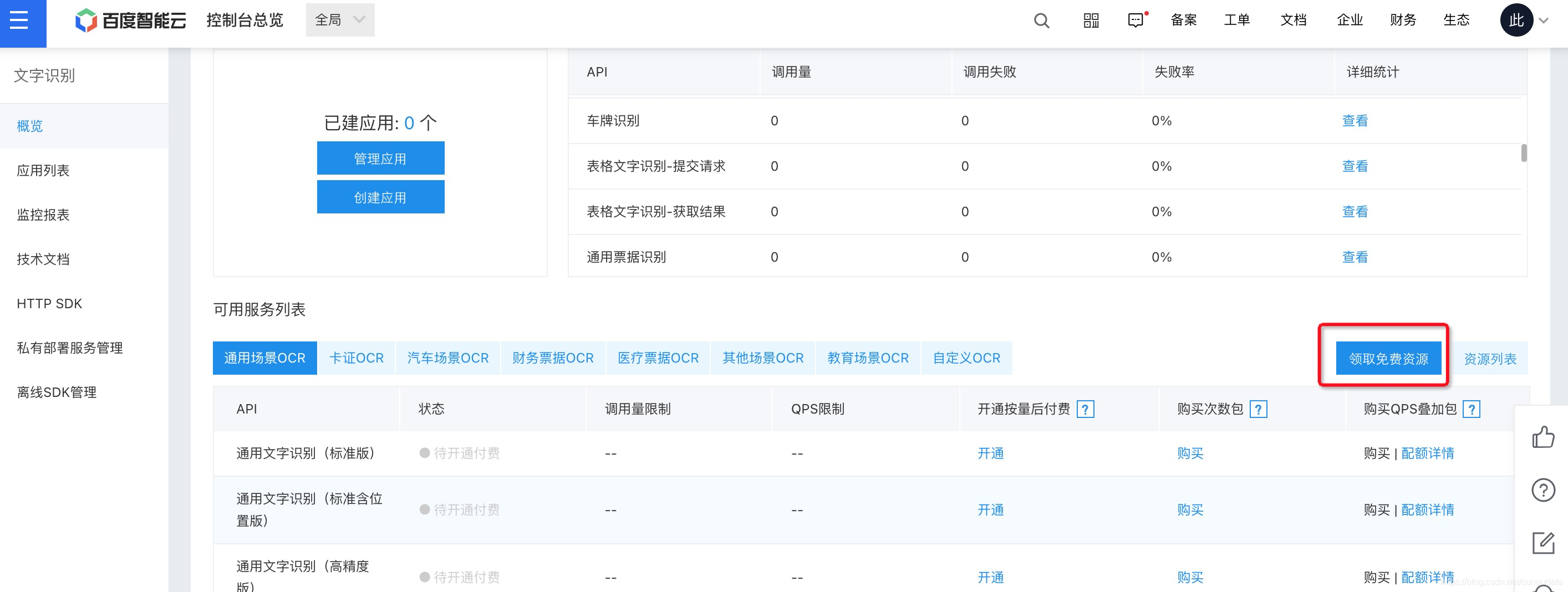
-
選擇通用文字識別,可以看到通過身份證號實名認證后可1000次/月試用,對開發者初調學習用還是很友好的,贊百度,
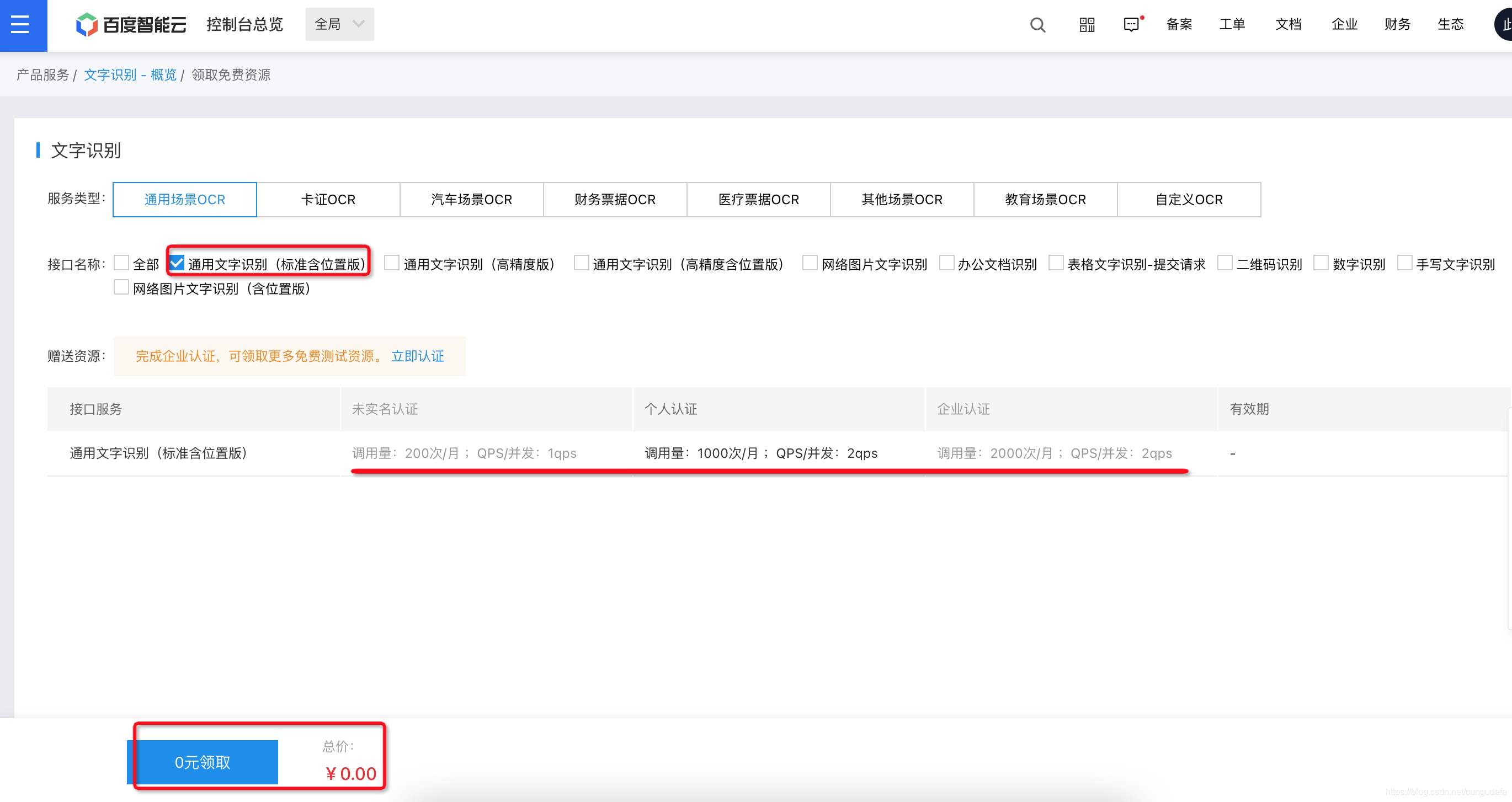
-
回到主頁可以看到我們已經申請成功了
-
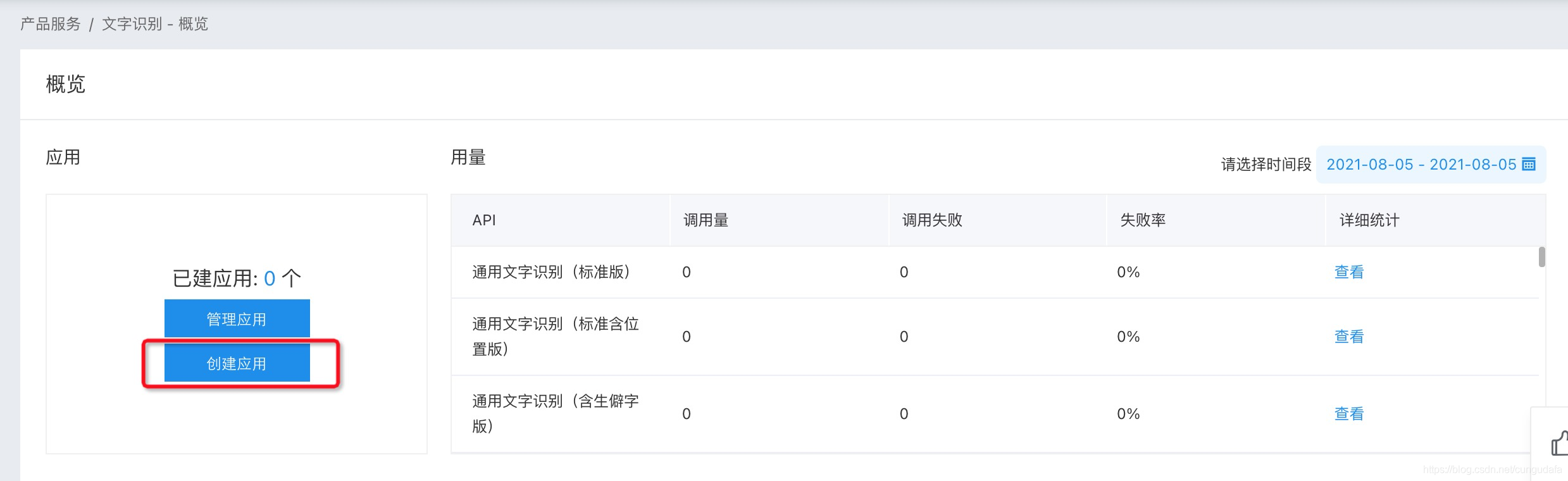
創建應用
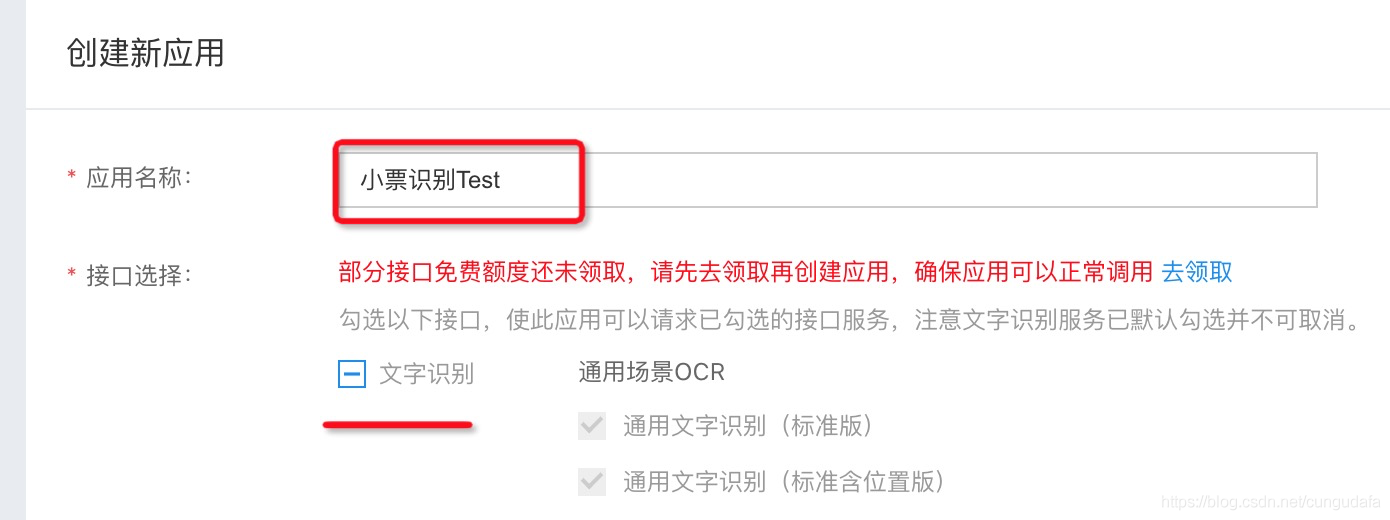
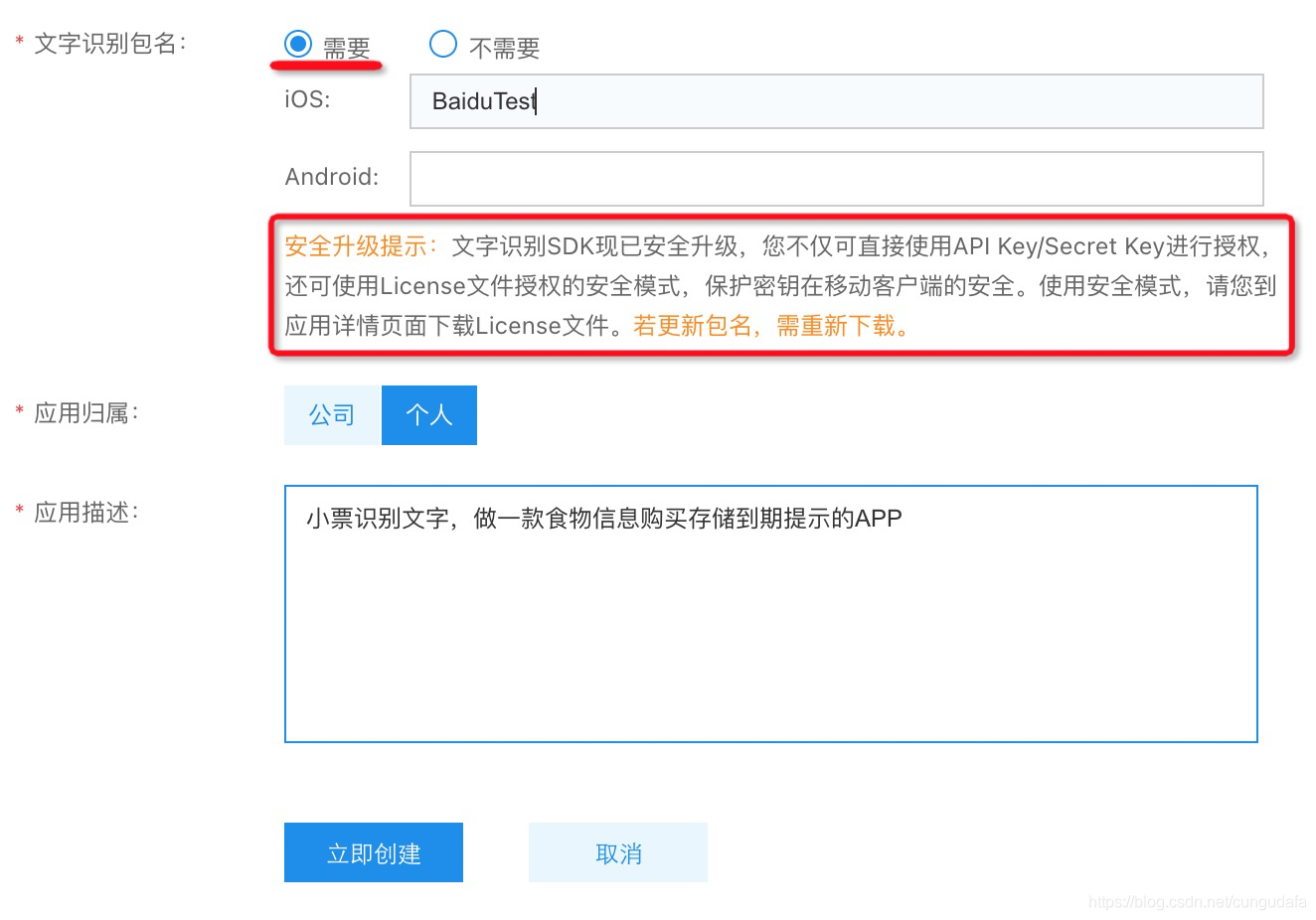
前者是通過APIkey引入授權,安全方式需要單獨配置許可證,這里僅測驗,選擇不需要,

二、根據檔案編輯API訪問
查看檔案
文字識別介面
1.在應用串列、應用詳情、可以查看到APIkey和SecretKey
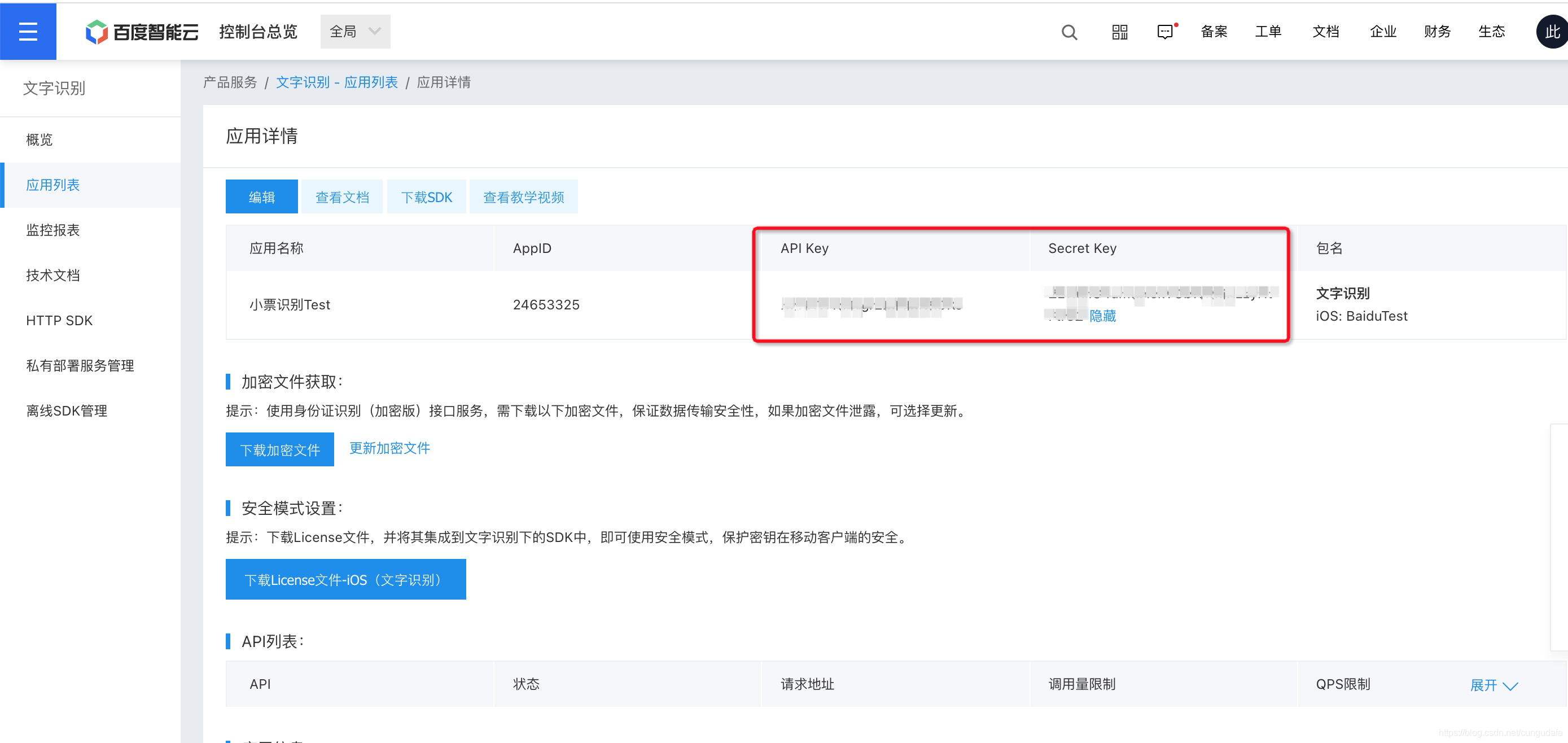
- (這里用python測驗)獲取access_token
# encoding:utf-8
import requests
# AccessKey = ''
# SecretKey = ''
# client_id 為官網獲取的AK, client_secret 為官網獲取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id='+AccessKey+'&client_secret='+SecretKey
headers = {
'Content-Type': 'application/json;charset=UTF-8'
}
access_token = ''
response = requests.get(url=host, headers=headers)
if response:
res = response.json()
access_token = res['access_token']
print(access_token)
測驗圖片:(來源于網路)

影像識別:
# encoding:utf-8
import requests
import base64
'''
通用文字識別
'''
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
# 二進制方式打開圖片檔案
f = open('/Users/wangyu/Desktop/xiaopiao.jpg', 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json())
識別結果:這里是文字識別效果也非常好,和小票拍攝清晰度也有一定關系,比較滿意,

三、小票識別
1.識別
繼續領取通用票據的識別介面測驗權限
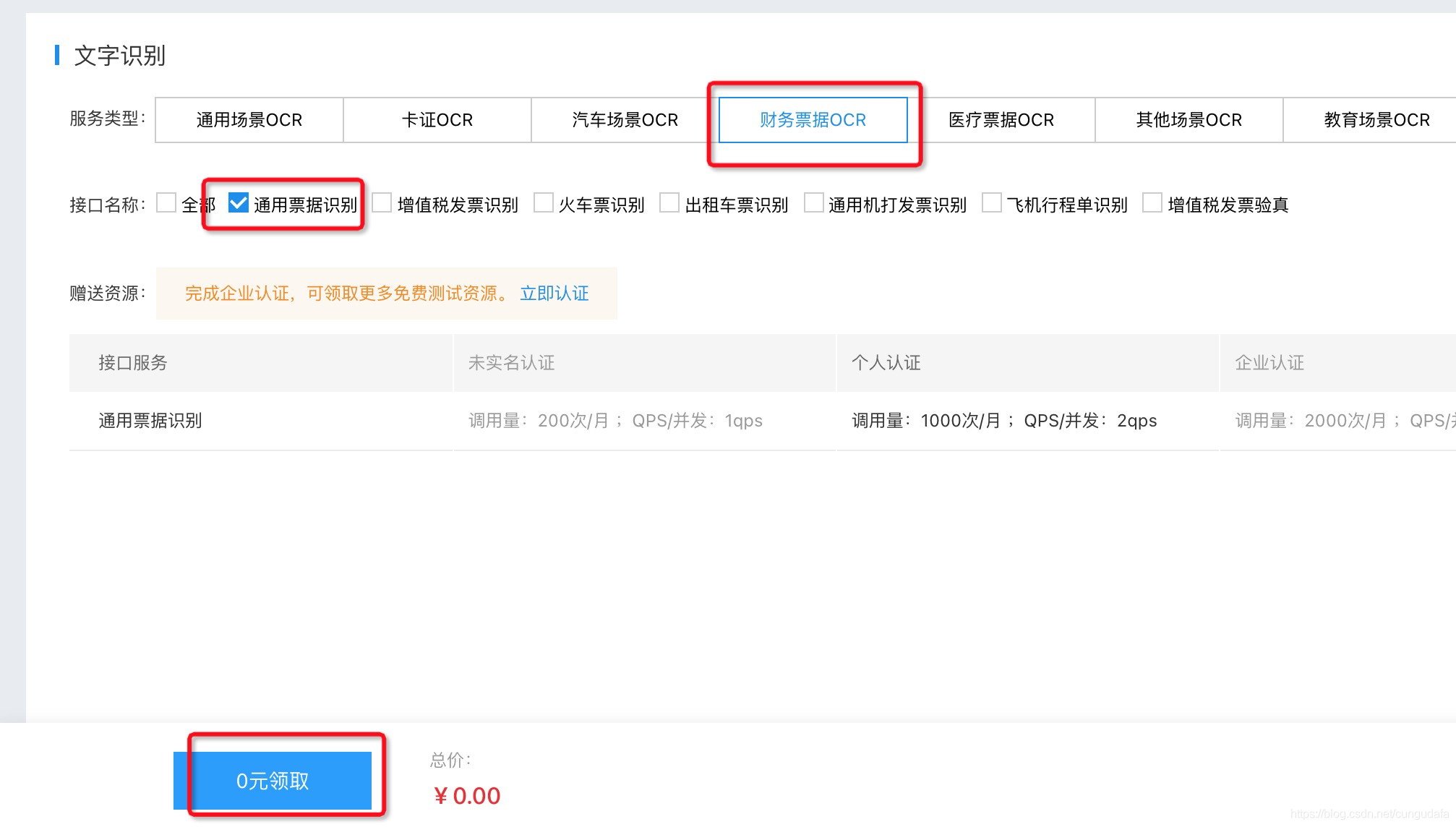
# encoding:utf-8
import requests
import base64
import json
'''
通用票據識別
'''
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/receipt"
# 二進制方式打開圖片檔案
f = open('/Users/wangyu/Desktop/xiaopiao.jpg', 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (json.dumps(response.json(),indent=1,ensure_ascii=False))
列印內容:文字、文字所處的位置
 列印出words可以發現識別內容非常雞肋:
列印出words可以發現識別內容非常雞肋:

2.票體內容處理
明顯發現識別的資訊還是不夠具體,圖源網路,我們需要對小票內容分析,僅需要 票體:主題內容 即可,
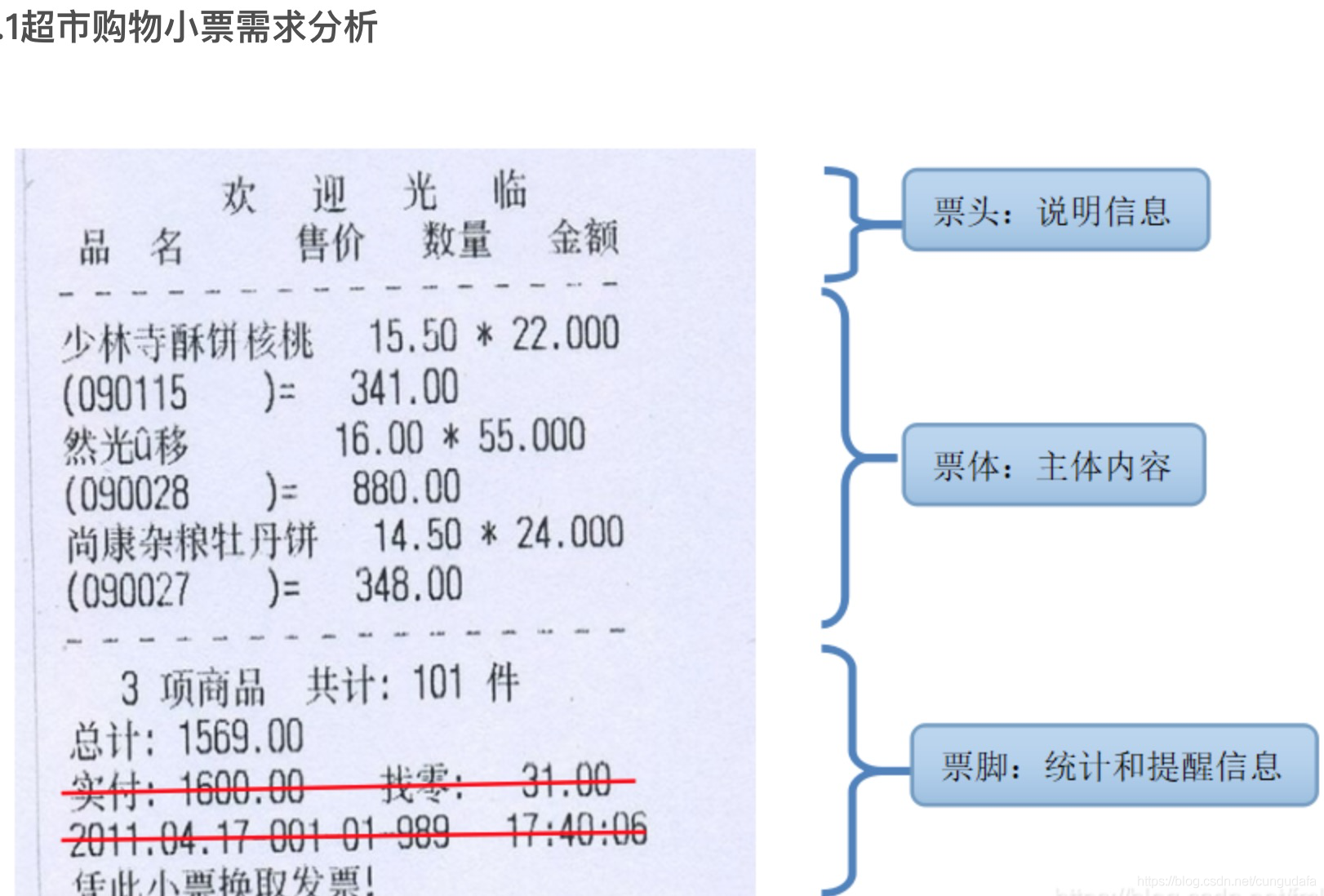
思路:既然有location位置,那么優先以位置資訊來定位頭和尾部資訊,并剔除;找到頭部關鍵字距離頂部的高度top1(如圖藍色),找到底部的關鍵字距頂部的高度top2(如圖黃色),票體的內容部分高度為:top1~top2(如圖綠色部分)

關鍵字的確定:參考多種購物小票的排版,可以發現,頭部有通用字樣識別符號:“單價、數量”,尾部有“總計、應付、合計、應收”等字樣,但是像金額、優惠的字樣不可取,上下均有出現,
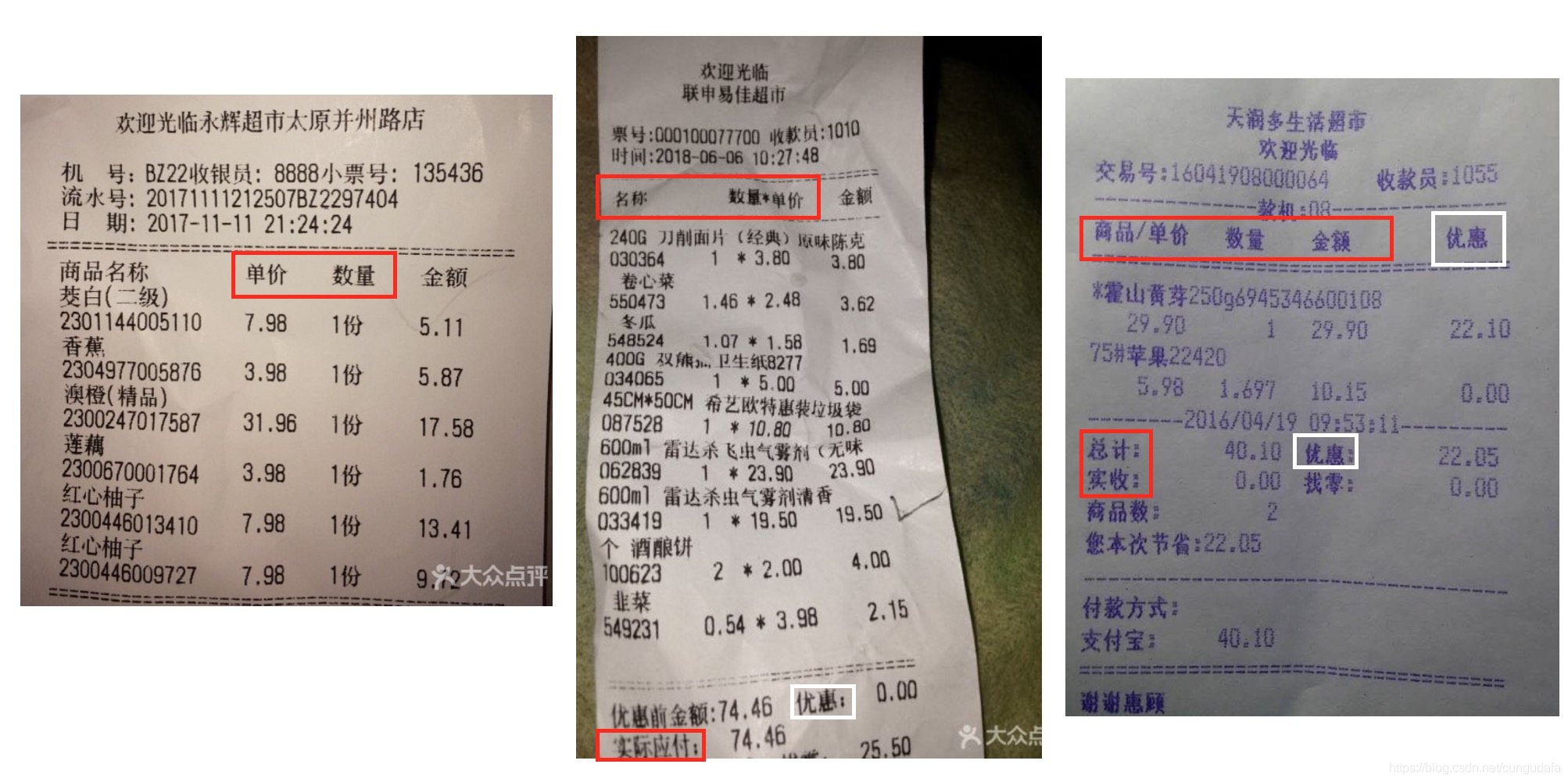
多個關鍵字去匹配,匹配到的值:頂部取最大值,底部取最小值來精確中間body的高度,我這里還剔除了長數字和英文,因為我不需要單價等細節,直接正則匹配過濾了,
def _isbody(response):
# 設計思路是找到票體主體內容的頭部和主體內容的位部關鍵字,獲取關鍵字距離頂部的坐標
begin,end = 0,999999
beginWords = ["數量","單價","售價","單位"]
endWords = ["總計","總金額","支付","應收","應付","合計"]
for idx in response['words_result']:
for i in beginWords:
if i in idx['words']:
temp = idx['location']['top']
if temp > begin:
begin = temp
for j in endWords:
if j in idx['words']:
temp2 = idx['location']['top']
if temp2 < end:
end = temp2
# print(begin,end)
# 取居于主體內容部分的中間的購買資訊
list = []
for idx in response['words_result']:
top = idx['location']['top']
if top > begin and top < end :
# 剔除數字和英文字符,保留中文
foods = re.sub('[^\u4e00-\u9fa5]', '', idx['words'])
if foods != '':
list.append(foods)
# print(list)
return list
列印出高度區間,取中間中文部分(已經非常nice了!)

3. 物品分類
我的需求是需要找到購買的物品是屬于什么分類,那么在我已有的分類下去歸類小票的購買物資就可:

def _isWhat(words,array):
for key,value in array.items():
# print('\n'+key,end=':')
if key in words:
return key
for batching in value:
# print(batching, end=' ')
if batching in words:
return batching
return '其他'
array = {'糖果':{'棒棒糖','糖'},'蔬菜':{'青菜','瓜'},'飲料':{'果汁','可樂','橙汁','牛奶','奶茶'},'薯片':{'樂事'},'蛋糕':{'糕點',"綠豆糕"}}
resultList = []
for food in wordList:
type = _isWhat(food,array)
resultList.append({food,type})
print(resultList)
文章到這里就結束了,代碼的邏輯很簡單,需求不復雜;同理:百度的影像識別介面除了小票文字還有物體識別,好比如識別到某一類的物體,根據你的字典去歸類區分,可以應用于垃圾分類,物品存盤過期提醒,烹飪菜譜推薦等等,
四、源代碼
# encoding:utf-8
import requests
import base64
import json
import re
'''
通用票據識別
'''
def getToken(AccessKey,SecretKey):
# client_id 為官網獲取的AK, client_secret 為官網獲取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id='+AccessKey+'&client_secret='+SecretKey
headers = {
'Content-Type': 'application/json;charset=UTF-8'
}
access_token = ''
response = requests.get(url=host, headers=headers)
if response:
res = response.json()
access_token = res['access_token']
return access_token
def getResult(url,access_token):
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/receipt"
# 二進制方式打開圖片檔案
f = open(url, 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
# print (json.dumps(response.json(),indent=1,ensure_ascii=False))
return response.json()
def _isbody(response):
# 設計思路是找到票體主體內容的頭部和主體內容的位部關鍵字,獲取關鍵字距離頂部的坐標
begin,end = 0,999999
beginWords = ["數量","單價","售價","單位"]
endWords = ["總計","總金額","支付","應收","應付","合計"]
for idx in response['words_result']:
for i in beginWords:
if i in idx['words']:
temp = idx['location']['top']
if temp > begin:
begin = temp
for j in endWords:
if j in idx['words']:
temp2 = idx['location']['top']
if temp2 < end:
end = temp2
# print(begin,end)
# 取居于主體內容部分的中間的購買資訊
list = []
for idx in response['words_result']:
top = idx['location']['top']
if top > begin and top < end :
# 剔除數字和英文字符,保留中文
foods = re.sub('[^\u4e00-\u9fa5]', '', idx['words'])
if foods != '':
list.append(foods)
# print(list)
return list
def _isWhat(words,array):
for key,value in array.items():
# print('\n'+key,end=':')
if key in words:
return key
for batching in value:
# print(batching, end=' ')
if batching in words:
return batching
return '其他'
def main():
# 識別的圖片
url = '/Users/wangyu/Desktop/xiaopiao2.jpg'
# 百度賬號資訊
AccessKey = ''
SecretKey = ''
# 獲取小票識別結果
access_token = getToken(AccessKey,SecretKey)
response = getResult(url,access_token)
# 取小票識別主體,(不一定能夠涵蓋全面)
wordList = _isbody(response)
# 區分識別購買物資的類別
array = {'糖果':{'棒棒糖','糖'},'蔬菜':{'青菜','瓜'},'飲料':{'果汁','可樂','橙汁','牛奶','奶茶'},'薯片':{'樂事'},'蛋糕':{'糕點',"綠豆糕"}}
resultList = []
for food in wordList:
type = _isWhat(food,array)
resultList.append({food,type})
print(resultList)
main()
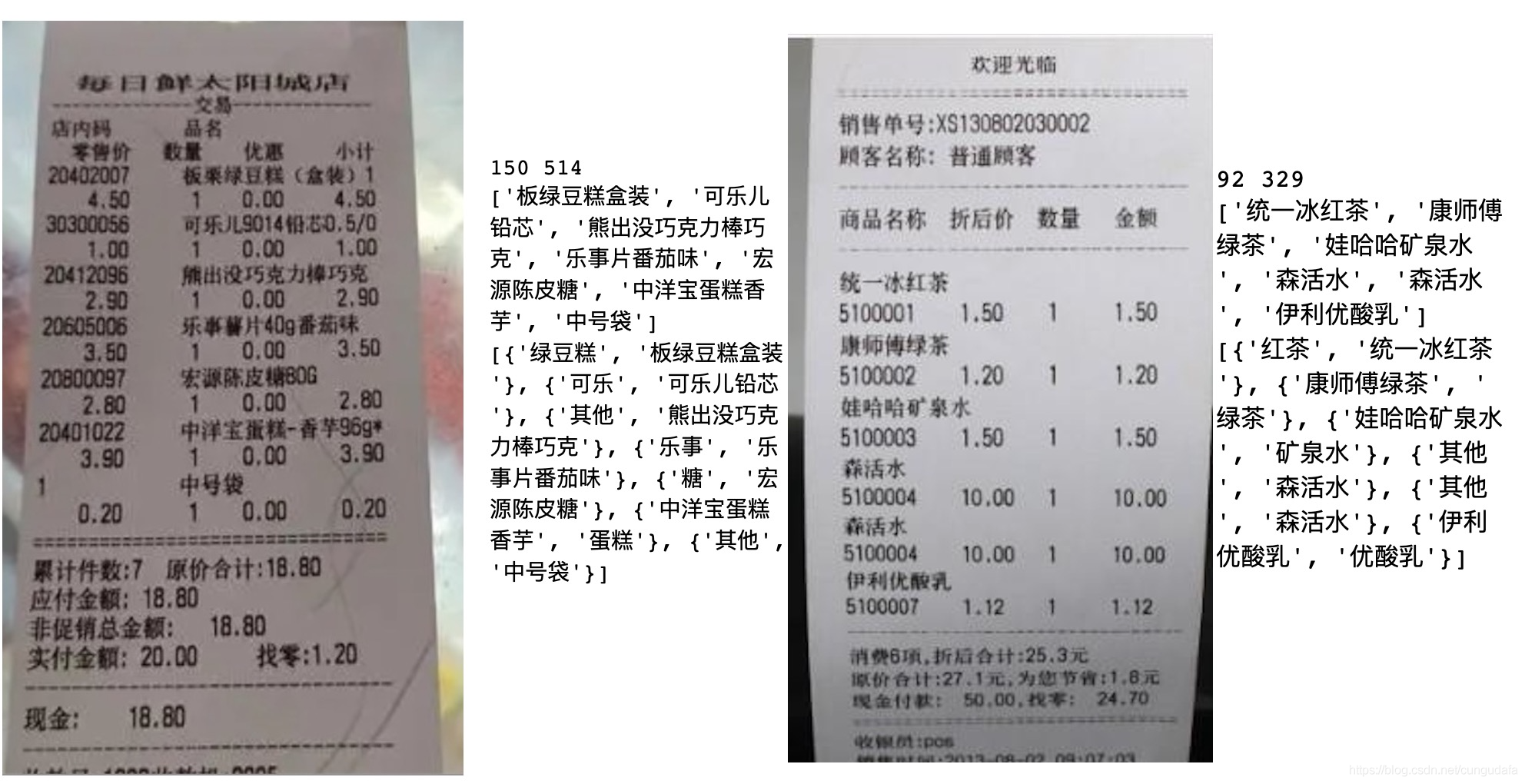
識別效果:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292280.html
標籤:其他