計算機視覺-深度學習影像檢測方法梳理
由于之后要轉方向啦,趁這段時間整理手中碩士研究方向的一些閱讀筆記,這是一篇關于計算機視覺的基礎知識梳理
先搞清一些小知識點
首先我們要弄清楚影像分類、目標定位、語意分割、實體分割的區別
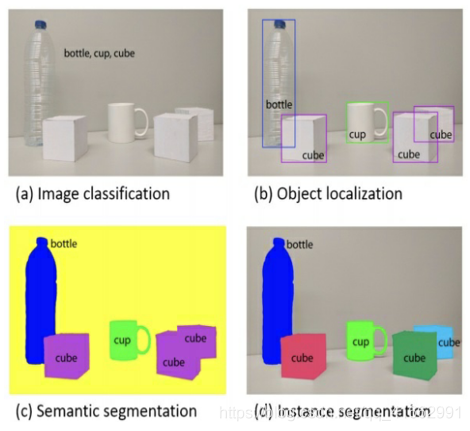
a. 影像分類 :給定一張輸入影像,影像分類任務旨在判斷該影像所屬類別;
b. 目標定位 :在影像分類的基礎上,我們還想知道影像中的目標具體在影像的什么位置,通常是以包圍盒的(bounding box)形式;
c. 語意分割 :語意分割是目標檢測更進階的任務,目標檢測只需要框出每個目標的包圍盒,語意分割需要進一步判斷影像中哪些像素屬于哪個目標;
d. 實體分割 :語意分割不區分屬于相同類別的不同實體,例如,當影像中有多只貓時,語意分割會將兩只貓整體的所有像素預測為“貓”這個類別,
其次,什么是選擇性搜索Selective Search(SS)?
在目標檢測時,為了定位到目標的具體位置,通常會把影像分成許多子塊(sub-regions / patches),然后把子塊作為輸入,送到目標識別的模型中,分子塊的最直接方法叫滑動視窗法(sliding window approach),滑動視窗的方法就是按照子塊的大小在整幅影像上窮舉所有子影像塊,和滑動視窗法相對的是另外一類基于區域(region proposal)的方法,selective search就是其中之一,至于為什么選SS,是因為相比滑窗法在不同位置和大小的窮舉,候選區域演算法將像素分配到少數的分割區域中,所以最終候選區域演算法產生的數量比滑窗法少的多,從而大大減少運行物體識別演算法的次數,同時候選區域演算法所選定的范圍天然兼顧了不同的大小和長寬比,
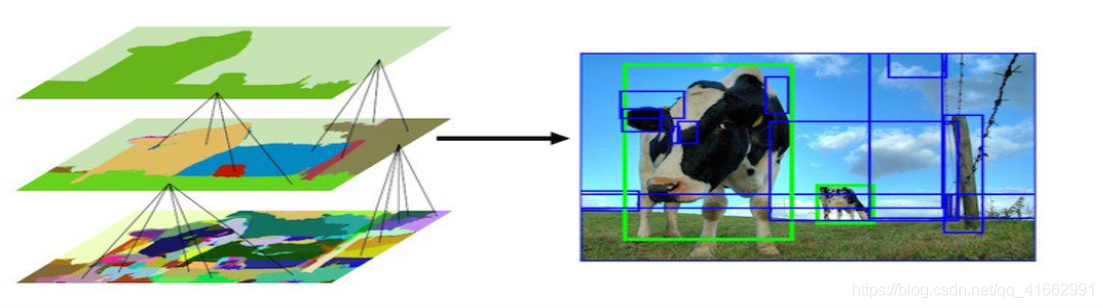
具體實作步驟和效果結合上圖食用:
1.首先將所有分割區域的外框加到候選區域串列中
2.基于相似度(顏色、紋理、大小和形狀交疊)合并一些區域
3.將合并后的分割區域作為一個整體,跳到步驟1
通過不停的迭代,候選區域串列中的區域越來越大,就通過自底向下的方法創建了越來越大的候選區域,
R-CNN
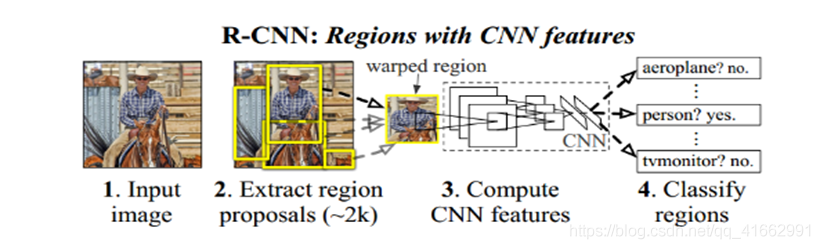
R-CNN的整個程序可以理解為Selective search+CNN+SVMs,詳細程序如下:
Step1:候選框提取
訓練階段:給定一張圖片,利用SS方法從中提取出2000個候選框,由于候選框大小不一,考慮到后續CNN要求輸入的圖片大小統一,將2000個候選框全部resize到227227解析度,
測驗階段:給定一張圖片,利用SS方法從中提取出2000個候選框,由于候選框大小不一,考慮到后續CNN要求輸入的圖片大小統一,將2000個候選框全部resize到227227解析度,
Step2:特征提取(CNN)
訓練階段:提取特征的CNN模型需要預先訓練得到,訓練CNN模型時,對訓練資料標定要求比較寬松,即SS方法提取的proposal只包含部分目標區域時,我們也將該proposal標定為特定物體類別,
測驗階段:得到統一解析度227227的proposal后,帶入訓練得到的CNN模型,最后一個全連接層的輸出結果—40961維度向量即用于最終測驗的特征,
這樣做的主要原因在于,CNN訓練需要大規模的資料,如果標定要求極其嚴格(即只有完全包含目標區域且不屬于目標的區域不能超過一個小的閾值),那么用于CNN訓練的樣本數量會很少,因此,寬松標定條件下訓練得到的CNN模型只能用于特征提取
Step3:分類器(SVMs)
訓練:對于所有proposal進行嚴格的標定(當且僅當一個候選框完全包含ground truth區域且不屬于ground truth部分不超過候選框區域的5%時認為該候選框標定結果為目標,否則為背景),然后將所有proposal經過CNN處理得到的特征和SVM新標定結果輸入到SVMs分類器進行訓練得到分類器預測模型,
測驗:對于一副測驗影像,提取得到的2000個proposal經過CNN特征提取后輸入到SVM分類器預測模型中,可以給出特定類別評分結果,
結果生成:
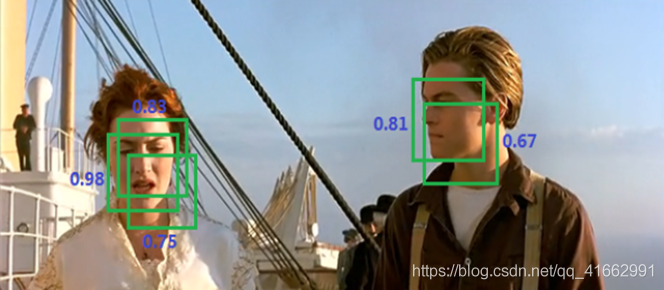
得到SVMs對于所有Proposal的評分結果,將一些分數較低的proposal去掉后,剩下的proposal中會出現候選框相交的情況,采用非極大值抑制技術,對于相交的兩個框或若干個框,找到最能代表最終檢測結果的候選框,
這里簡單說一下非極大值抑制的具體操作:基于前面的網路能為每個框給出一個score,score越大證明框越接近期待值,如圖兩個目標分別有多個選擇框,現在要去掉多余的選擇框,分別在區域選出最大框,然后去掉和這個框IOU(交并比)>0.7的框,如圖
SPP-NET
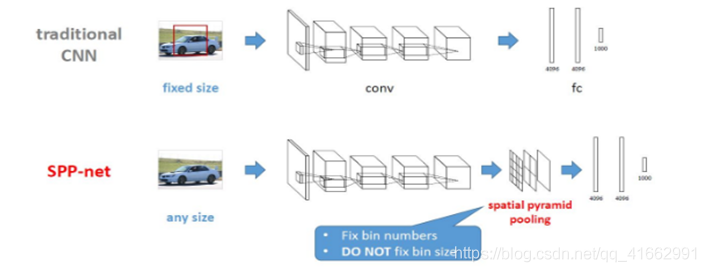
SPP-NET的特點(相比于R-CNN):
1.傳統CNN網路中,卷積層對輸入影像大小不作特別要求,但全連接層要求輸入影像具有統一尺寸大小,因此,在R-CNN中,對于SS方法提出的不同大小的proposal需要先通過Crop操作或Wrap操作將proposal區域裁剪為統一大小,然后用CNN提取proposal特征,相比之下,SPP-net在最后一個卷積層與其后的全連接層之間添加了一個SPP (spatial pyramid pooling) layer,從而避免了Crop或Warp操作,總而言之,SPP-layer適用于不同尺寸的輸入影像,通過SPP-layer對最后一個卷積層特征進行pool操作并產生固定大小feature map,進而匹配后續的全連接層,
crop有時只能得到目標的區域,可以理解為裁剪;但wrap會改變原目標的長寬比,甚至導致影像的扭曲,即將影像裁剪到一定尺寸,根據具體需求選擇使用,
2.由于SPP-net支持不同尺寸輸入影像,因此SPP-net提取得到的影像特征具有更好的尺度不變性,降低了訓練程序中的過擬合可能性,
3.R-CNN在訓練和測驗時需要對每一個影像中每一個proposal進行一遍CNN前向特征提取,但SPP-net只需要進行一次前向CNN特征提取,即對整圖進行CNN特征提取,得到最后一個卷積層的feature map,然后采用SPP-layer根據空間對應關系得到相應proposal的特征,SPP-net速度可以比R-CNN速度快24~102倍,且準確率比R-CNN更高,
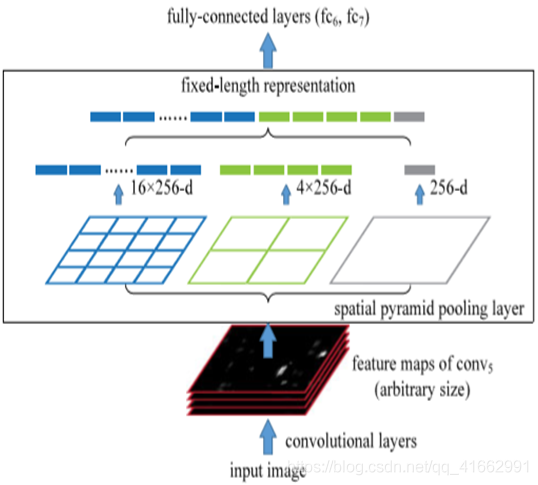
上圖為spp是如何使不同大小輸入影像在經過SPP-Layer后得到相同的特征向量長度
不難看出,SPP的關鍵實作在于通過conv5輸出的feature map寬高和SPP目標輸出bin的寬高計算spatial pyramid pooling中不同解析度Bins對應的pooling window和pool stride尺寸,
FAST-R-CNN
首先總結一下前兩個網路的缺點:
1.R-CNN和SPP-Net的訓練程序類似,分多個階段進行,實作程序復雜,
2.R-CNN和SPP-Net的時間成本和空間代價較高,SPP-Net在特征提取階段只需要對整圖做一遍前向CNN計算;RCNN在特征提取階段對每一個proposal均需要做一遍前向CNN計算,因此RCNN特征提取的時間成本很高,R-CNN和SPP-Net用于訓練SVMs分類器的特征需要提前保存在磁盤,考慮到2000個proposal的CNN特征總量還是比較大,因此造成空間代價較高,
3.R-CNN檢測速度很慢,RCNN在特征提取階段對每一個proposal均需要做一遍前向CNN計算,如果用VGG進行特征提取,處理一幅影像的所有proposal需要47s,
4.特征提取CNN的訓練和SVMs分類器的訓練在時間上是先后順序,兩者的訓練方式獨立,因此SVMs的訓練Loss無法更新SPP-Layer之前的卷積層引數,因此即使采用更深的CNN網路進行特征提取,也無法保證SVMs分類器的準確率一定能夠提升,
相對于前兩個網路,FAST-R-CNN有以下亮點:
1.Fast-R-CNN檢測效果優于R-CNN和SPP-Net;
2.訓練方式簡單,基于多任務Loss,不需要SVM訓練分類器;
3.Fast-R-CNN可以更新所有層的網路引數(采用ROI Layer將不再需要使用SVM分類器,從而可以實作整個網路端到端訓練);
4.不需要將特征快取到磁盤,
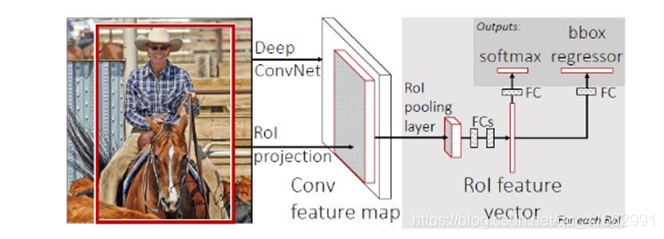
具體步驟: 輸入一幅影像和Selective Search方法生成的一系列Proposals,通過一系列卷積層和Pooling層生成feature map,然后用RoI層處理最后一個卷積層得到的feature map為每一個proposal生成一個定長的特征向量roi_pool5,RoI層的輸出roi_pool5接著輸入到全連接層產生最終用于多任務學習的特征并用于計算多任務Loss,全連接輸出包括兩個分支:1.SoftMax Loss:計算K+1類的分類Loss函式;2.Regression Loss:即K+1的分類結果相應的Proposal的Bounding Box四個角點坐標值,最終將所有結果通過非極大抑制處理產生最終的目標檢測和識別結果,
這里涉及到兩個基礎知識點:
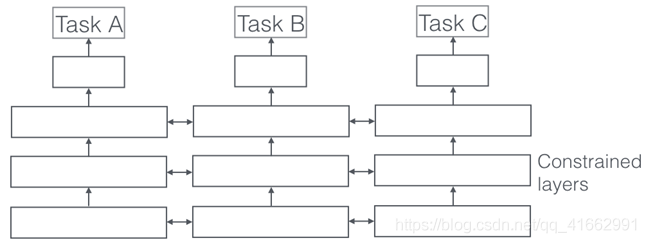
1、多任務學習(Multi-Task Learning, MTL)是一種歸納遷移機制,主要目標是利用隱含在多個相關任務的訓練信號中的特定領域資訊來提高泛化能力,多任務學習通過使用共享表示并行訓練多個任務來完成這一目標,一言以蔽之,多任務學習在學習一個問題的同時,可以通過使用共享表示來獲得其他相關問題的知識,比如,學習行走時掌握的能力可以幫助學會跑,學習識別椅子的知識可以用到識別桌子的學習,我們可以在相關的學習任務之間遷移通用的知識,如圖,歸納遷移是一種專注于將解決一個問題的知識應用到相關的問題的方法,從而提高學習的效率,FAST-R-CNN包括兩個同等水平的sub-layer兩種Loss的權重比例為1:1,
2、邊框回歸(Bounding-Box regression)
視窗:用四維向量(x,y,w,h) 來表示, 分別表示視窗的中心點坐標和寬高;
目標:尋找一種關系使得輸入原始的視窗 P 經過映射得到一個跟真實視窗 G 更接近的回歸視窗G^;
思路: (平移+尺度放縮)如圖,綠色的框表示Ground Truth, 紅色的框為Selective Search提取的Region Proposal,那么即便紅色的框被分類器識別為飛機,但是由于紅色的框定位不準(IoU<0.5), 那么這張圖相當于沒有正確的檢測出飛機, 如果我們能對紅色的框進行微調, 使得經過微調后的視窗跟Ground Truth 更接近, 這定位會更準確,Bounding-box regression 就是用來微調這個視窗的,

其實后面還有FASTER-R-CNN、YOLO、SDD網路,但是計算機視覺發展史實在太長,限于字數和時間,這篇計算機視覺梳理先寫到這里,有機會再更新…
本人碩士期間主要研究語意分割、注意力機制,了解可能不全面,有理解錯誤的歡迎大家交流指正~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292451.html
標籤:其他